.png)


I recently tried to light the tinder for what I hoped would be a revolt — the Single Node Rebellion — but, of course, it sputtered out immediately. Truth be told, it was one of the most popular articles I’ve written about in some time, purely based on the stats.
The fact that I even sold t-shirts, tells me I have born a few acolytes into this troubled Lake House world.
Without rehashing the entire article, it’s clear that there is what I would call “cluster fatigue.” We all know it, but never talk about it … much … running SaaS Lake Houses is expensive emotionally and financially. All well and good during the peak Covid days when we had our mini dot-com bubble, but the air has gone out of that one.
Not only is it not cheap to crunch 650 GB of data on a Spark cluster —piling up DBUs, truth be told — but it’s not complicated either; they’ve made it easy to spend money. Especially when you simply don’t need a cluster anymore for *most datasets and workloads.Sure, in the days of Pandas when that was our only non-Spark option, we didn’t have a choice, but DuckDB, Polars, and Daft (also known as D.P.D. because why not) … have laid that argument to rest in a shallow grave.
Cluster fatigue is real
D.P.D. can work on LTM (larger than memory) datasets
D.P.D. is extremely fast.
Sometimes I feel like I must overcome skepticism with a little bit of show-and-tell, proof is in the pudding, as they say. If you want proof, I will provide it.
Look, it ain’t always easy, but always rewarding.
Thanks for reading Data Engineering Central! This post is public so feel free to share it.

We have two options on the table. Like Neo, you have to choose which pill to take. Ok, maybe you can take both pills, but whatever.
Distributed
Not-Distributed
Our minds have been overrun by so much marketing hype pumping into our brains, we are like Neo stuck in The Matrix. We just need some help to escape.
I’m going to shove that red pill down your throat. Open up, buttercup.
Into the breach, my friends, let’s get to it.
Thanks for reading Data Engineering Central! This post is public so feel free to share it.
Ok, so to at least simulate what would be a production-like environment, with data that is still small-ish, but approaching reality, let’s get our test setup to see if we can choke Polars and DuckDB (and Daft to keep ‘em honest), because we know Spark would have zero problems with data this size.
The steps will be simple.
Create a Delta Lake table in S3.
Fill the table with 650GB of data. (I was going to 1TB but got tired of waiting)
On a small but reasonably sized EC2 Instance run …
DuckDB
Polars
Daft
Compare all these to Spark
Next, we must somehow generate 650GB of data. What we will do is just mock up some data that could be described as social media posts, make a dict with Python, and convert it to a Daft Dataframe that can be written to a parquet file.
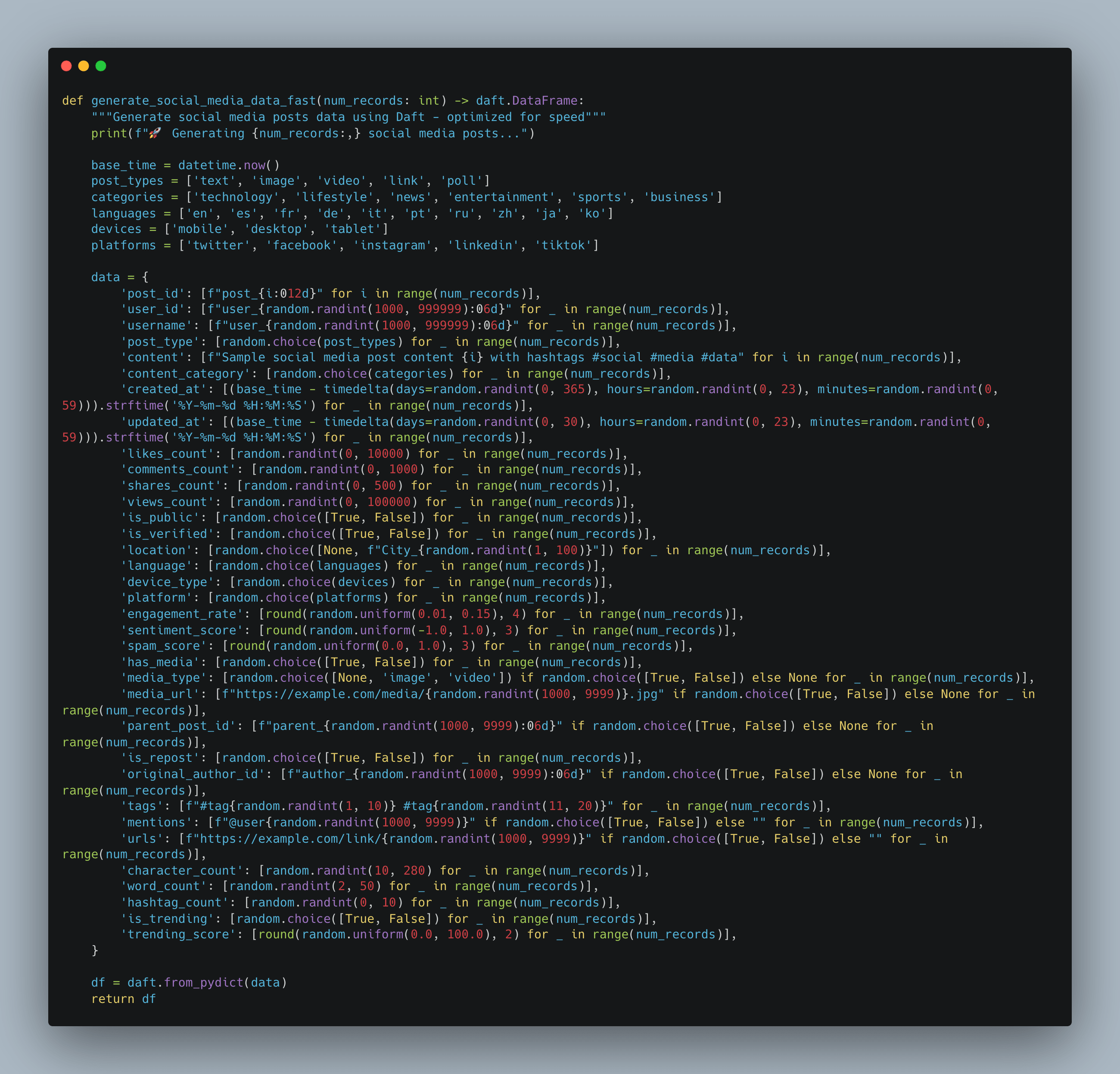
Once we have a Dataframe in Daft, we can just pump it to S3.

Now, we just gotta do this like a million times, waiting for 650GB of data to accumulate.
Basically, at this point, I left my laptop to run all night and went to bed. To sleep troubled dreams of AWS bills.
Thanks for reading Data Engineering Central! This post is public so feel free to share it.
Next, we need to convert these Parquet files into a Delta Lake table. Easy enough on Databricks.
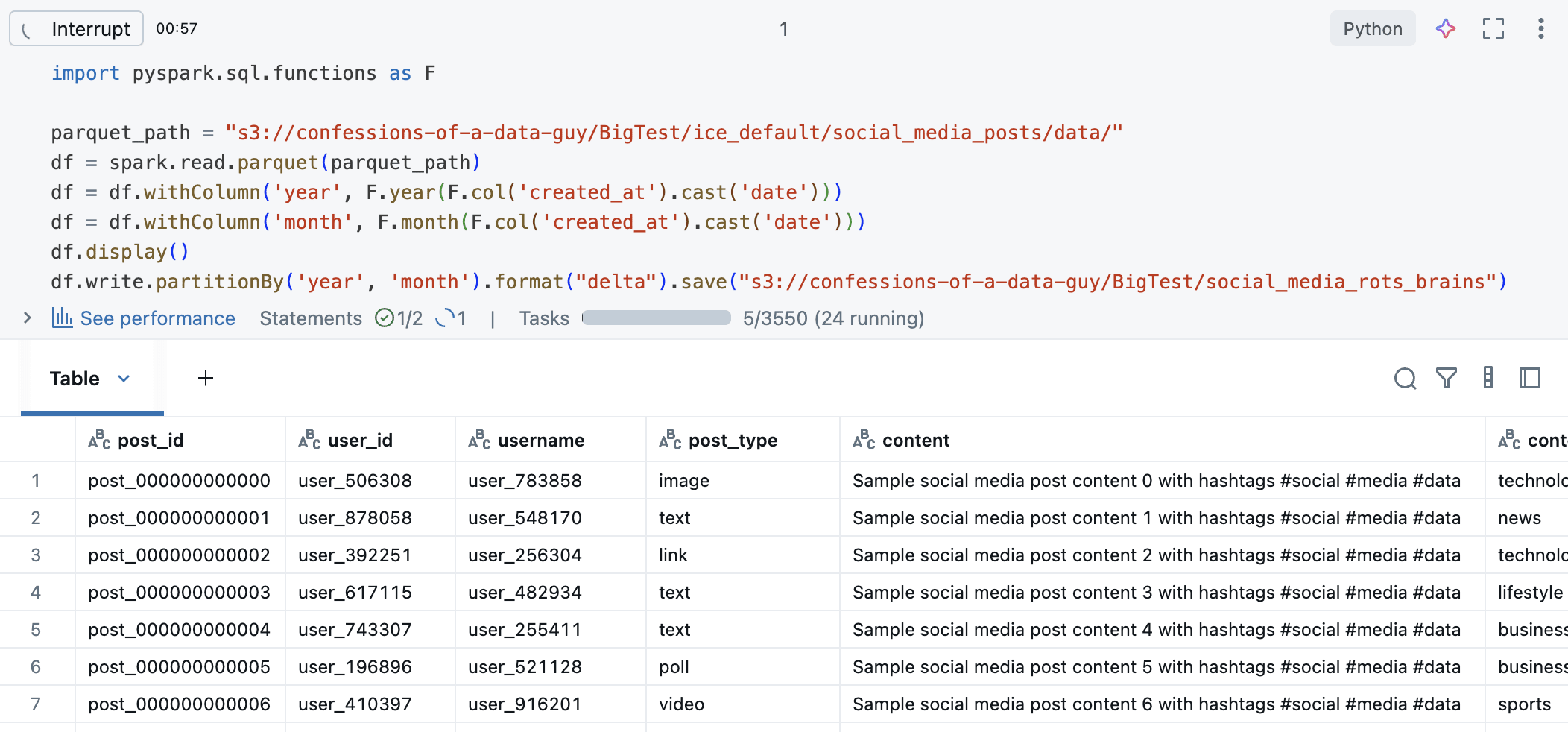
Note: I partitioned the data by year and month. We can see here we have about 650GB of data, excluding the Delta Logs.
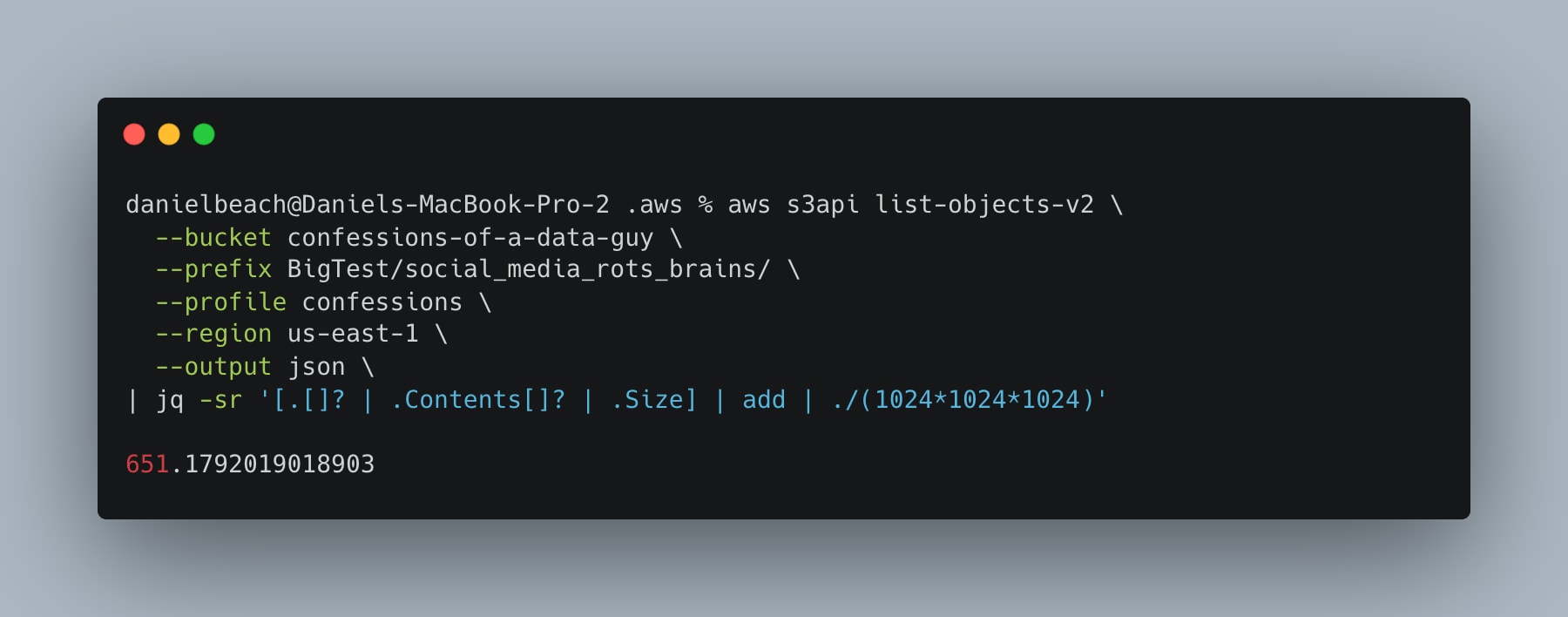
The problem is that we are/or will be on a single-node architecture with only 32GB of memory available for 650GB of data, so we need a streaming option when running queries to see if DuckDB, Polars, and Daft can handle the load.
In the real world of Lake Houses, where we could use either Delta Lake or Iceberg, if we wanted to do this in production, we would want tools that do not OOM and can work on datasets larger than memory. Again, this is what we are trying to answer, is it even remotely possible?Apparently, this is not an uncommon use case and a problem that needs to be solved. See here and below for an open Polars issue where someone has this exact problem and wants an out-of-the-box way to “stream writes to Iceberg.”
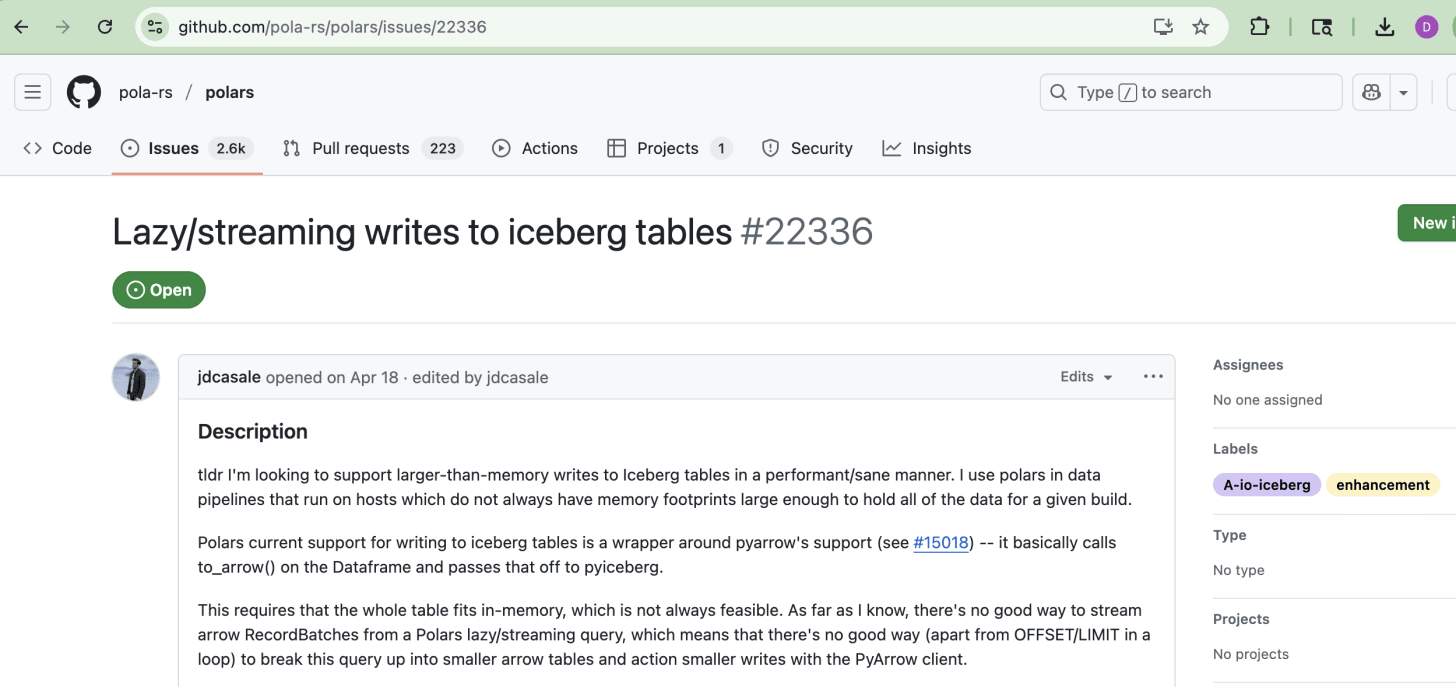
The point I’m trying to make is that we need all these new-fangled frameworks, like Polars, DuckDB, etc, to have out-of-the-box support for reading and writing to Lake House formats in a streaming manner, reducing memory pressure.

Here we have a 32GB, 16 CPU EC2 instance on AWS. This is a fairly normal size and would be considered commodity-sized hardware. Many Spark clusters are composed of these node sizes.
Once the node is running, we will use uv to set up and install the needed tooling.
Not sure if you noticed it above, but I’m using a fake social media posts dataset. What we need now is a query that reads the entire dataset and performs some work, like aggregation.
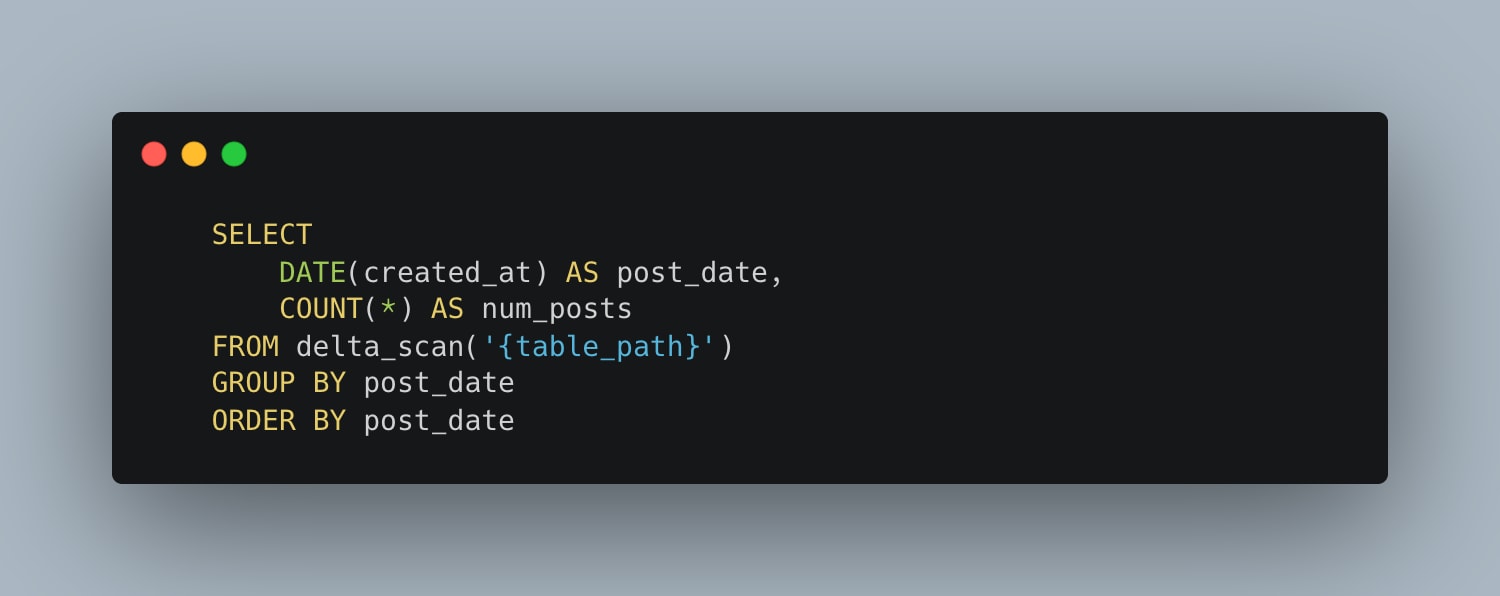
That simple query should suffice to push these single-node frameworks to the limit with 650GB and an EC2 with 32GB of RAM available. They're going to have to eat that whole dataset.
We will also run this on PySpark Databricks Single Node Cluster to get an idea of how these tools each stack against the GOAT.
You can see below that I had to downgrade to an old DBR Version when generating the Delta Table, so no Deletion Vectors would be used. DuckDB is the only one able to handle deletion vectors. A serious flaw and fragmentation in Polars.
Thanks for reading Data Engineering Central! This post is public so feel free to share it.
We are going to start with that little quacker DuckDB. You know, this tool has grown on me more and more as I've used it. I just had to replace Polars in a production Databricks environment because DuckDB was the only tool that could handle Deletion Vectors.
Everything MotherDuck touches turns to gold.
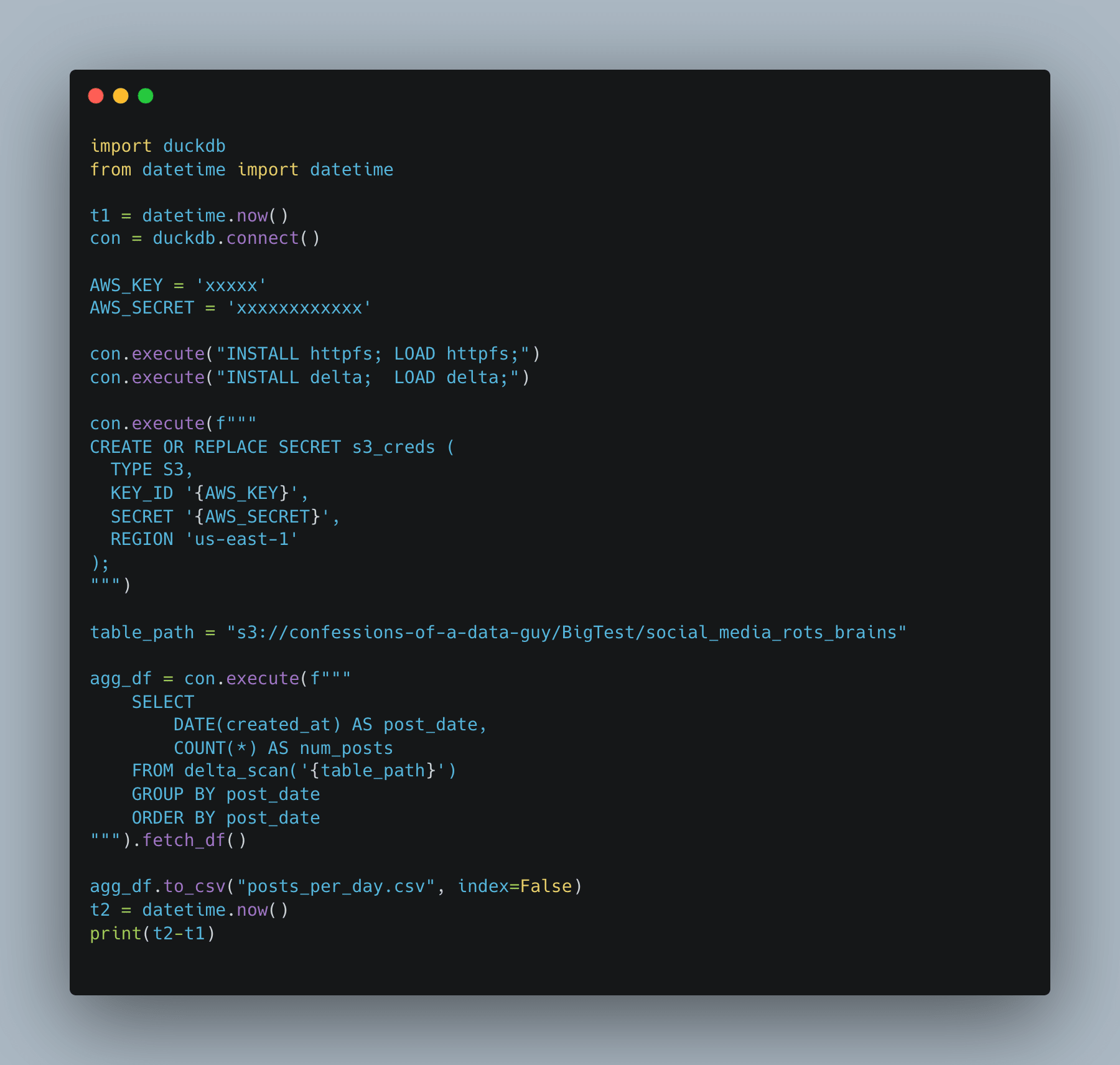
Code is simple, clean. Can DuckDB crunch 650GB of S3 Lake House data on a 32GB commodity Linux machine and come out the other side with all feathers intact?
Well, I’ll be. It worked.

16 minutes. Heck, it seems like a single node can handle 650GB of data. Didn’t even play with any settings. Indeed, using vim, I can see the local file was written out with the results.
Heck, nothing for it, onto the next!!! Single Node Rebellion is alive and well.
Well, here we go. I’ve got a bad taste in my mouth about no Deletion Vector support, which makes Polars useless in a new Lake House environment. Stinkers.
But, I will hold my disdain, and let’s see our Polars code. Nice and clean, good-looking stuff.
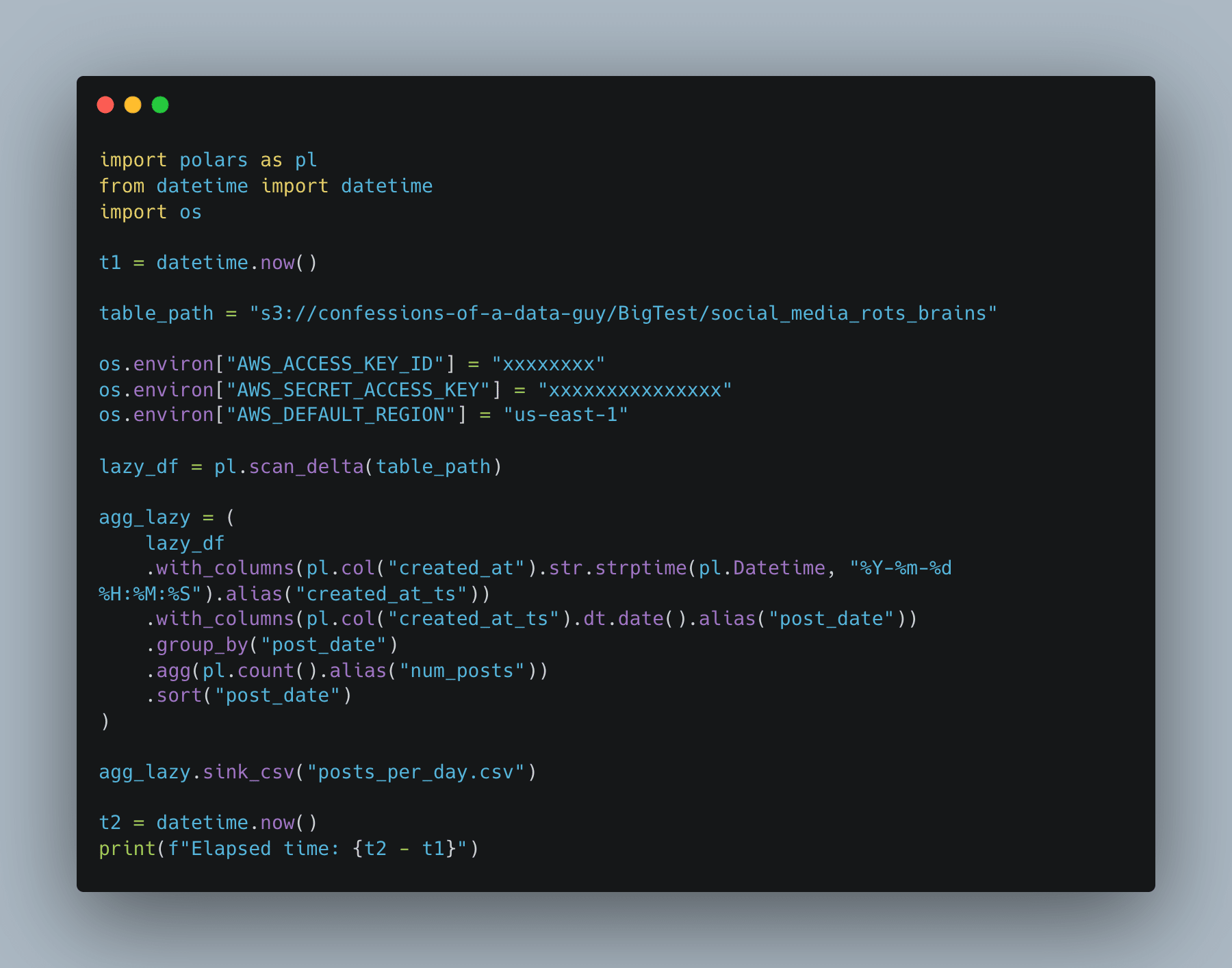
Remember, with Polars, you must use the Lazy API’s to get the job done … aka … scan and sink. If you don’t, she’ll blow a gasket.
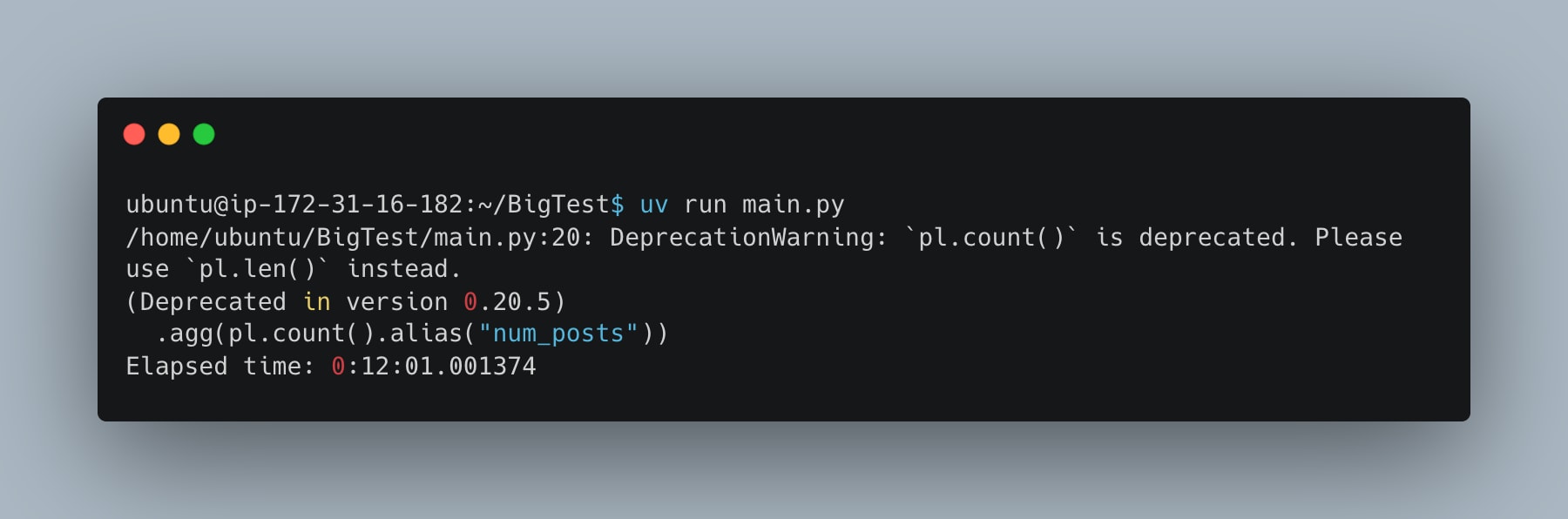
There we go, no problems, 12 minutes on the Rust GOAT. Beating out DuckDB by a few minutes. But we are all friends here, we are just proving a point, and it’s going well.
These single-node engines are chomping the 650GBs no problem. (I checked the results of the local file, all was well)
Thanks for reading Data Engineering Central! This post is public so feel free to share it.
One of my personal favorites is Daft, Rust-based, and it screams whenever you put it to work. Smooth and fun to use. I was recently working on some Iceberg stuff, and Daft was about the only thing that worked.
What a beaut.

Not much difference between Daft and Polars code-wise, both Rust-based. Egads, that was slow. Done put a dagger in my heart.
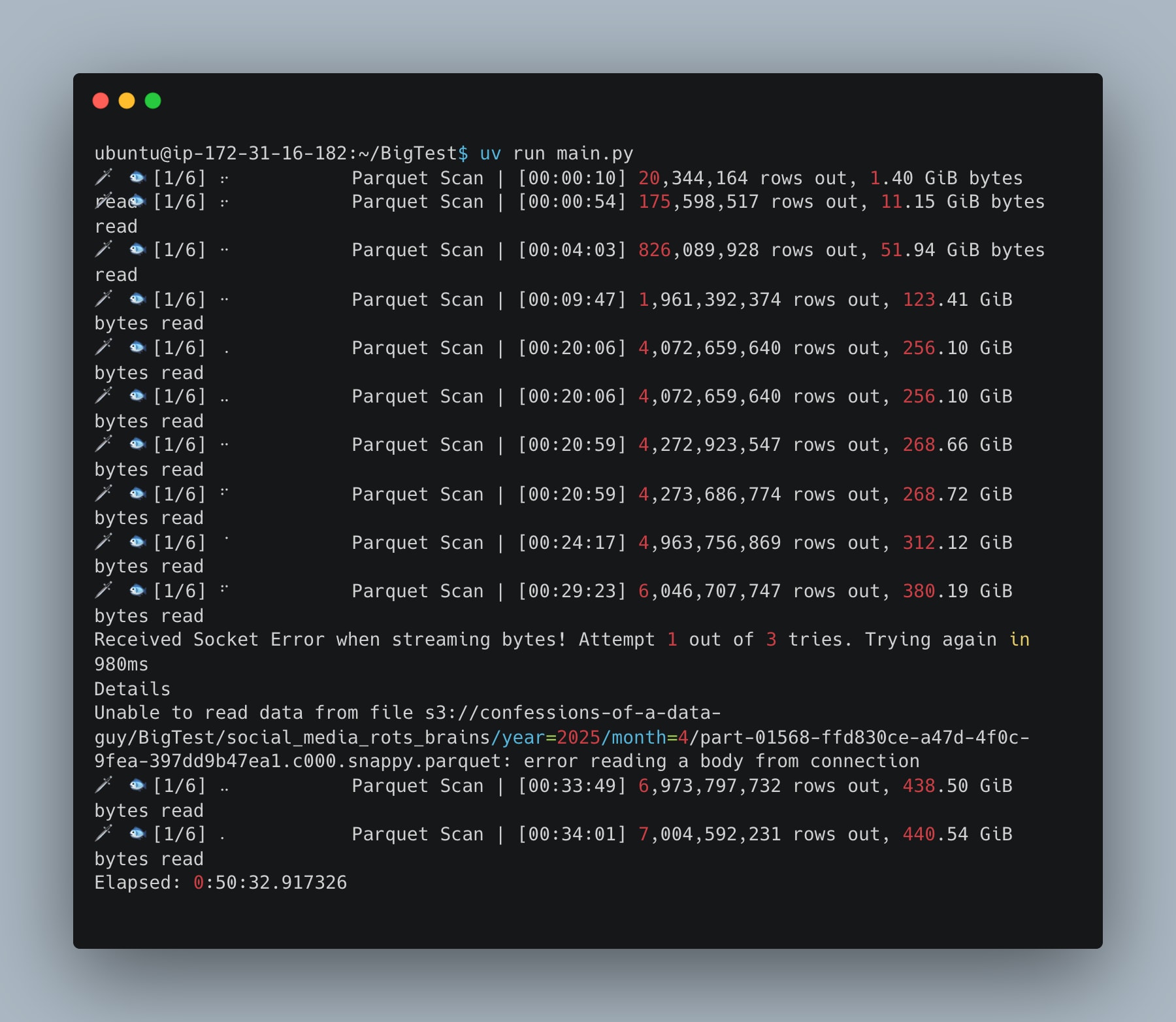
50 minutes is better than nothing, I guess. I’m no expert in Daft; I just did what I did — probably something wrong.
Ok, so this one is really our anchor point: a single-node 32GB with 4 CPUs, which matches up to our EC2 pretty well, or close enough. Aren’t you curious to see how it stacks up to the single-node buggers?
I don’t really care if it’s that much faster; one would expect it to be. The main point is: could we migrate many expensive DBUs and other distributed compute engines to the Single Node Rebellion?
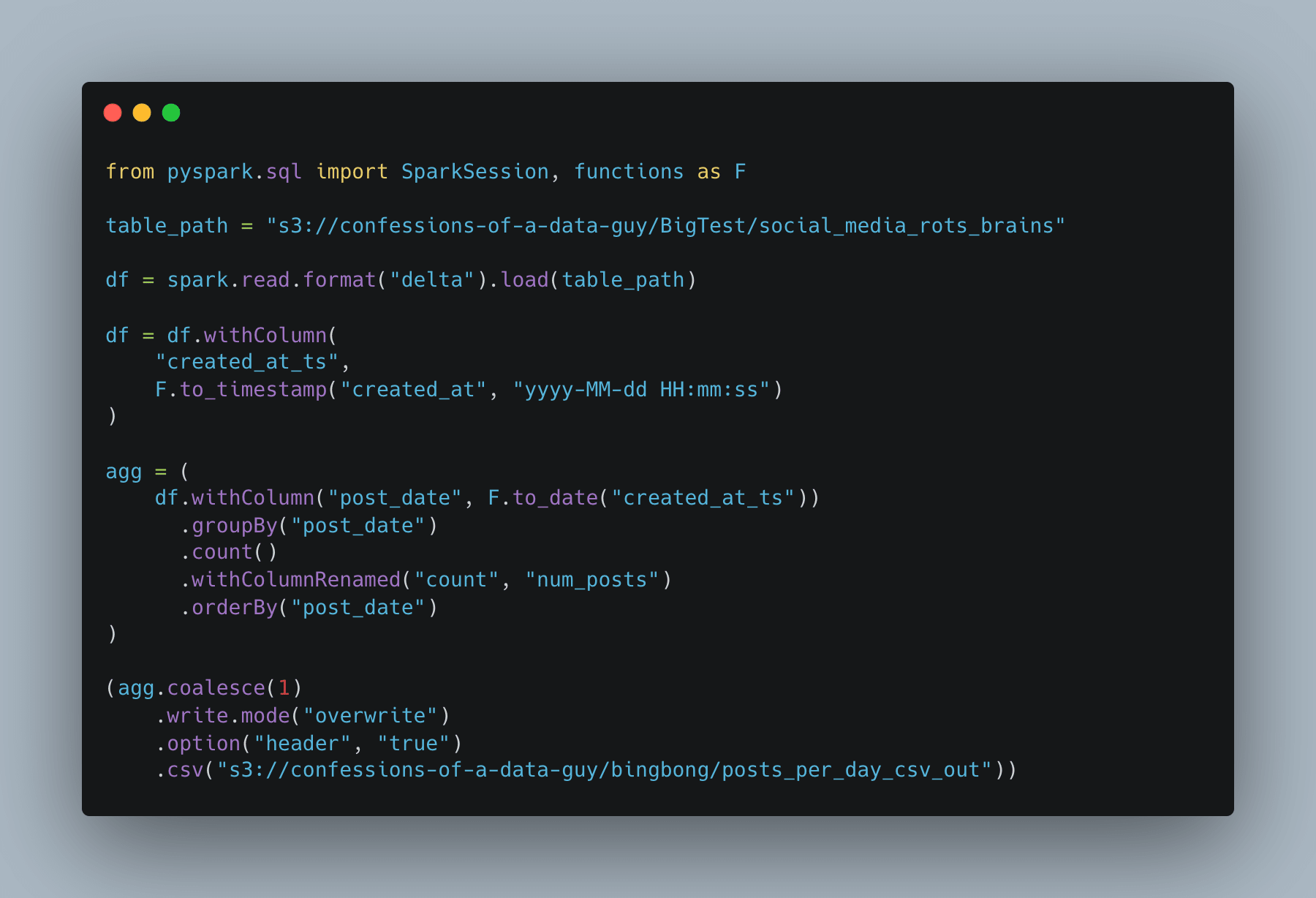
Dang, over an hour.

Of course, PySpark is most apt to have troubles without tuning, but we will let the ragers rage. I mean, we all know that the spark.conf.set(”spark.sql.shuffle.partitions”, “16”) should be that instead of 200. But whatever.
We are simply making a point that single-node glory can do the job just as well.
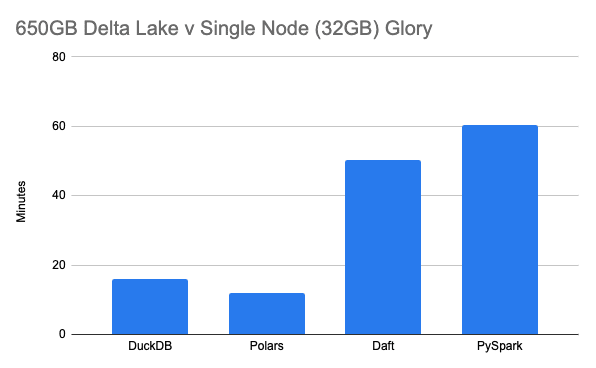
Of course, this was not some scientific TCP benchmark; it’s not like those are fair either half the time. We were not so much concerned about who’s the fastest as much as whether these single-node tools can handle large Lake House datasets on small memory footprints without giving up the ghost.
That we proved.
Single-node frameworks can handle large datasets
Single-node frameworks can integrate into the Lake House
They can give reasonable runtimes on cheap hardware
The code is easy and uncomplicated
Truly, we have not been thinking outside the box with the Modern Lake House architecture. Just because Pandas failed us doesn’t mean distributed computing is our only option.
Thanks for reading Data Engineering Central! This post is public so feel free to share it.



