.png)

The train of thought that culminated in this project set off when my good friend (Rish) sent me a list compiled by the New York Times of the “100 Best Movies of the 21st Century”. Scrolling through the list idle mindedly, I picked out the films which I’d seen, silently agreeing with the list for including them. However, when given more thought, I started to wonder the methodology behind this ranking.
My first instinct was to turn to Letterboxd. In recent years, a film’s average Letterboxd rating has become a source of truth in some sense for me. My preconceived notions and expectations about a film are determined mostly by its average rating. Even when selecting a film to watch on lazy evenings with my flatmates, before committing to a film, we look at its reviews.
This satisfied my curiosity temporarily. I assumed that the New York Times would have considered various ratings of the film. At the very least, ranking films by their average rating is a starting point, from which an official ranking can be refined.
But then I started to think about my own practices when rating a film. The truth is, I’m pretty terrible at assigning a rating to a film after I have seen it. Even having watched and rated 234 of them (as of today) on Letterboxd. There have been numerous occasions when, upon reviewing my Letterboxd activity, I’ve noticed inconsistencies. Films that I preferred over others, which received a lower rating. In a large part, my rating of a film is influenced by its average rating: safety in numbers, herd mentality. My rating can’t be that incorrect if it’s relatively close to the average.
I suppose that on the scale of thousands of reviews, the average rating of a film is a relatively good indicator of how good it is. But on a personal level, my own ratings mean very little, at least to me. I considered how I might compile my own ranking, “The 100 Best Movies of All Time (According to Shiva)”. I realised that it would actually be very difficult.
I was reminded of an idea I had seen in The Social Network, a film which coincidentally I like very much, and placed 10th place on the NYT list1:
MARK: Yea, it’s on. I’m not gonna do the farm animals but I like the idea of comparing two people together. It gives the whole thing a very “Turing” feel since people’s ratings of the pictures will be more implicit than, say, choosing a number to represent each person’s hotness like they do on hotornot.com. The first thing we’re going to need is a lot of pictures.
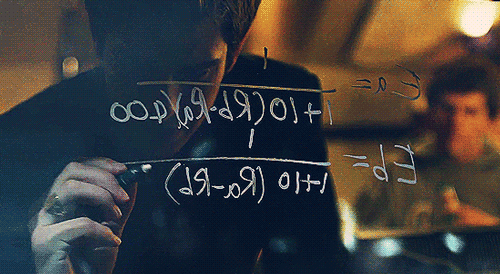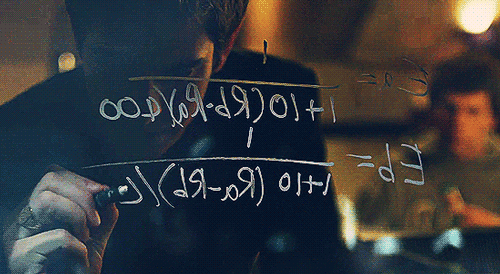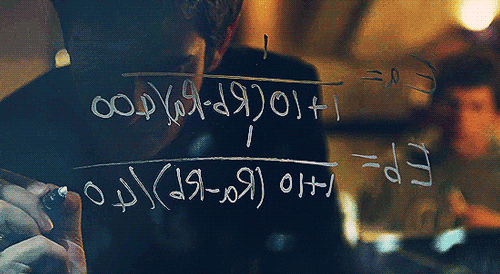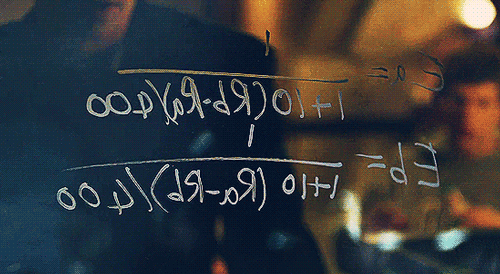
Figure 1: The creation of facemash, using an ELO ranking system, in The Social Network
In the film, Mark Zuckerberg – frustrated after breaking up with Jessica Albright – creates a website called Facemash. The site asks users to pick the more attractive person out of two photos. As people repeat this pairwise comparison, an overall ranking emerges.
Mathematically, what we usually call a “rating” is just a proxy for an underlying total ordering of films. A score like 3/5, taken in isolation, tells us very little. It only becomes meaningful when we compare it to the ratings of other films.
That got me thinking: what if we skipped the proxy altogether? Instead of assigning numbers to films, we could uncover the ordering directly through comparisons. It’s hard to give a rating that faithfully captures a film’s place in the hierarchy, but it’s much easier to choose the better of two when they’re placed side by side.
As such, the idea for Filmsmash was born.
Building Filmsmash
The idea for Filmsmash was in place. At a high level, I wanted users to be able to rank their favourite movies, by pairwise comparison. To get a list of movies that a user had seen, we turn to Letterboxd.
Letterboxd API (and Workaround)
Unfortunately, obtaining API keys for Letterboxd is difficult. However, Letterboxd does allow users to download a dump of their data in a CSV format. Good enough, I suppose. In my head I pictured users downloading a dump of their Letterboxd data, giving it to Filmsmash, which then ran on the films they’ve seen to formulate a ranking.
TUI
I’ve always found good terminal based user interfaces to be extremely satisfying. I decided that it would be fun to try building one for Filmsmash. After some research into which libraries provided good support for building TUIs, I settled on Ratatui, a Rust library for making TUIs.
Ranking Algorithm
While Mark Zuckerberg used an Elo-based system to rank candidates on Facemash, I think a simple merge sort approach is a better fit for our app. In Facemash, the same pairings could appear multiple times, and different people might give different answers – so a single vote isn’t conclusive proof of which option is better. That’s why a probabilistic system like Elo made sense there. In our case, though, we’re assuming a single user with consistent preferences: if you say you prefer Film A over Film B once, you’ll always prefer it. The crucial difference is uncertainty – Facemash had it, but for us, each comparison is definitive.
The downside to this approach is that we can’t stop after an arbitrary number of comparisons, the merge sort algorithm must complete. I wondered if this would require too many comparisons to be feasible. The merge sort algorithm requires \(n \log n\) comparisons. I have 234 films that I’ve seen. This means to rank the films I’ve watched, it would take \(234 \times \log(234)\) comparisons, so around 1842 comparisons. If I average one comparison a second, it would take about thirty minutes. Good enough. A fun way to kill time when exceedingly bored.
Film Metadata
I mentioned earlier that we obtain the films a user has seen by inspecting their Letterboxd data dump. Inspecting the CSVs that are generated by Letterboxd, I realised that they were pretty limited, containing only the essential information like a film’s name and the year it was released. While this is sufficient, I thought that our TUI might look a bit more fleshed out if it included some metadata like the the director, or the plot. Luckily there are other APIs which handle this, like OMDB. The API only allows one film to be queried in one call, so in order to make our TUI feel quick, it required careful use of Rust’s async / await constructs, as well as some basic caching of fetched data.
The Finished Product
Putting this all together, it worked out quite nicely. It was actually quite a fun way to kill time, while I was stuck on a long bus journey.

Figure 2: Filmsmash in action!
You can find the source code and try out Filmsmash from here.
My Top Ten
Using Filmsmash, I was able to rank definitively my top ten films of all time.
YiYi – (2000) Edward Yang

Perfect Days – (2023) Wim Wenders

Oldboy – (2003) Park Chan-Wook

La Haine – (1995) Mathieu Kassovitz

Fallen Angels – (1995) Wong Kar-Wai

The Handmaiden – (2016) Park Chan-Wook

Burning – (2018) Lee Chang-Dong

Eternal Sunshine of The Spotless Mind – (2004) Michel Gondry

Lady Bird – (2017) Greta Gerwig

Before Sunset (2004), Richard Linklater



