.png)

Introduction
The extraction of low-dimensional abstract features from complex high-dimensional data constitutes the essence of human intelligence. Humans perceive the world by discerning individual objects, relationships between objects, and higher-order abstract patterns. Mimicking this human capability stands at the core of artificial intelligence research. Abstract visual reasoning entails uncovering abstract patterns embedded within composite images and extending them to novel inputs, showcasing human prowess in abstract generalization. Raven’s Progressive Matrices (RPM), acknowledged by researchers as a tool for evaluating the reasoning capabilities of visual models, hold significant recognition in the field1,2.
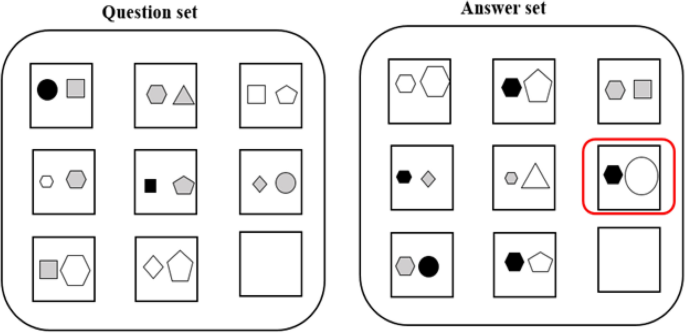
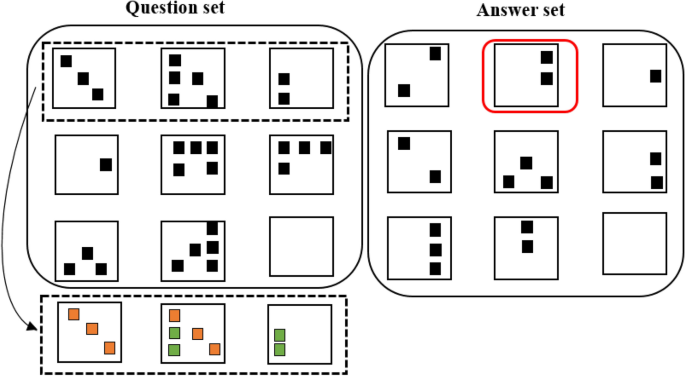
The examples in the I-RAVEN dataset, with the correct answers highlighted in red boxes in the answer set. In this scenario, the model is required to identify relationships within specific domains (such as shape, color, etc.) in the source sequence and apply them to different domains to accurately complete the target sequence.
The Raven’s Progressive Matrices (RPM) is a type of multiple-choice intelligence test, depicted in Fig. 1, that tasks participants with filling in missing elements within a 3x3 image grid. Throughout the evaluation process, reasoners are required to abstract the visual input representations to uncover higher-order abstract relationships within composite images. RPM is utilized for assessing abstract language, spatial, and mathematical reasoning abilities, with this test also revealing significant variances within populations with higher levels of education3. The ability to solve RPM puzzles is regarded by cognitive scientists as a paradigm of fluid intelligence, characterized by the acute identification of new relationships, abstraction, and flexible thinking4. The term “fluid” refers to the capacity to discover new associations and demonstrate agile abstract thinking, applying abstract new patterns to previously unencountered problems. Abstract reasoning abilities are widely acknowledged as symbols of human intelligence, showcasing cognitive flexibility and adaptability5,6. The method proposed in this paper leverages RPM tests to enhance the model’s visual reasoning capabilities and elevate the model’s level of cognitive intelligence.
Constructing neural networks and utilizing reinforcement learning methods to solve RPM problems is a common practice among researchers7,8,9,10. The majority of approaches involve using neural networks to extract features from original RPM images, extracting abstract relationships from low-level perceptual features, and selecting answers based on measuring feature similarity. During the reasoning test process, researchers have identified shortcut biases in the test, prompting the introduction of improvements like I-RAVEN11 and RAVEN-fair12 to address these biases. The new test datasets impose higher demands on the model’s abstract perceptual capabilities. Our model establishes a bridge between algebraic operations and machine reasoning through the relation bottleneck method, explicitly transforming multi-visual reasoning problems into 0-1 relation bottleneck matrices, and identifies system invariance through the comparison and observation of sequential features. The model integrates object-centric representations and the relation bottleneck method to construct a robust inductive bias reasoning framework, demonstrating strong visual reasoning capabilities on the test dataset. The main contributions of this paper are as follows:
-
By utilizing the relation bottleneck method, a bridge between algebraic operations and machine reasoning was constructed, explicitly converting multi-visual reasoning problems into 0-1 relation bottleneck matrices, observing system invariance in the comparison of sequence features.
-
The integration of object-centric representations and the relation bottleneck method established a reasoning framework with strong inductive bias, constraining and differentiating feature information to encourage relational comparisons and thereby induce the extraction of abstract patterns.
-
Bidirectional reasoning involving top-down and bottom-up processes, aggregating different representations to build a feedback mechanism, simulating a reasoning framework that mimics human thinking processes.
Related work
Abstract visual reasoning
Traditional neurosymbolic approaches have demonstrated good performance in tasks involving visual feature recognition and causal relationship extraction. Li et al13 integrated perception, analysis, and logical symbols into a unified reasoning framework to extract abstract patterns of composite targets through closed-loop logical reasoning. Hu et al.11 utilized a Hierarchical Rule-Aware Network (SRAN) to generate rule embeddings for input sequences, learning multi-granularity rule embeddings at different levels. The SRAN model effectively integrates key inductive biases, such as sequence sensitivity, permutation invariance, and incremental rule induction, by learning multi-granularity rule embeddings at different levels. Taking two rows/columns as input, it progressively learns and integrates hierarchical rule embeddings across unit-level, entity-level, and system-level embeddings. These multi-granularity embeddings are gradually fused through a gating fusion module, naturally preserving sequence sensitivity and effectively mapping inputs into the rule embedding space.
These neural networks do not fully induce abstract representations of underlying rules but tend to overfit visual features, thereby failing to generalize to new inputs with the same patterns14. Traditional neural-symbolic methods are efficient in feature extraction and capturing relationships between features, yet complex reasoning demands extracting higher-order abstract relationships within the problem. Object-centric relational representations, on the other hand, enable the acquisition of more advanced abstract logic15. Abstract visual patterns are typically characterized by relationships between objects rather than the features of the objects themselves. Learning object-centric representations of complex scenes is a promising step towards efficient abstract reasoning from low-level perceptual features16. It involves a model that explicitly represents objects and their abstract relationships, combining slot-based object representations with transformer-based architectures17,18. Object-centric learning seeks to achieve a general and compositional understanding of scenes by representing scenes as a collection of object-centric features, inducing the formation of abstract relationships through multi-level compositional reasoning19.
Object-centric learning
Learning object-centric representations enables machines to perceive the visual world in a manner similar to humans20, extracting object representations from images and training end-to-end through downstream tasks16,21,22. This approach allows for data-driven inference of relationships and unsupervised prediction of structured object properties. Object-centric representation methods capture visual objects at different levels and granularities23,24, but they are relatively fragile in handling changes unrelated to visual tasks. To mitigate this limitation, we integrate this approach with the relation bottleneck method25 and establish a bridge between algebraic operations and machine reasoning.
Relation bottleneck method
Our extraction of abstract patterns from visual images fundamentally represents a stronger inductive bias26,27. Abstract visual patterns are typically characterized by relationships between objects, and the discovery of these abstract relationships naturally begins with the objects themselves. CoRelNet28 represents a typical model demonstrating the logic of relation bottlenecks. It involves an encoder processing sensory observations to generate object embeddings and computing a relationship matrix for pairs of objects, capturing inter-object similarities through inner products. Subsequently, this relationship matrix is fed into a decoder network, which can vary in architecture, such as using multi-layer perceptrons or transformers. This process establishes a relation bottleneck where perceptual information is channeled into the matrix, transforming it into a form that retains only relational information before being transmitted to the decoder.The relation bottleneck approach utilizes inner products to represent pairwise relationships, whereas traditional relational networks rely on task-specific learned generic neural network components (such as multi-layer perceptrons). Although traditional methods are theoretically more flexible, their structures do not explicitly constrain the network to learn only relational information. This architecture is prone to learning shortcuts thet al.ign too closely with training data , thus impairing its ability to effectively learn and generalize relationships to out-of-distribution inputs. Inner product operations are inherently relational29,30,31, and the relation bottleneck method ensures downstream processing is solely based on relationships.
Similarity is the cornerstone of human reasoning, and any abstract mechanism is primarily based on similarity. Our model adopts a data-driven approach to induce abstract relationship models by restricting information processing to focus mainly on relationships between visual objects32, thereby promoting the emergence of abstract mechanisms resembling similarity relationships. This method allows for rapid learning of relational patterns and systematic generalization.
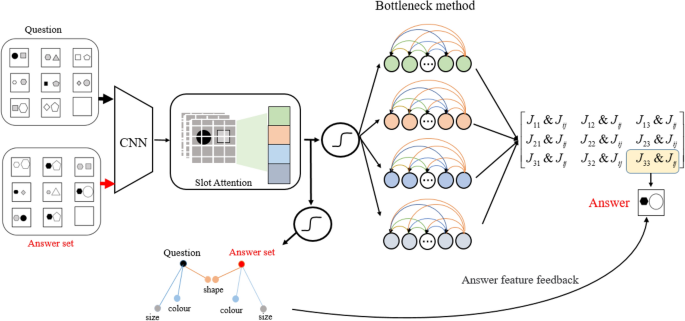
The abstract reasoning framework consists of three core modules: (1) extraction of object-centric representations, (2) extraction of pairwise relationship embeddings using bottleneck method, (3) representation of high-order abstract patterns through relation bottleneck matrices and querying of common features in sequences..
Methodology
Object-centric slot attention mechanism
We utilized the Slot Attention module to extract initial image features16. The slot attention mechanism learns to highlight individual objects, accomplishing image segmentation in an unsupervised manner. It interacts with the output of the preceding convolutional neural network, generating task-specific abstract representations called slots. During the initialization phase, slots compete with each other, occupying attentional regions on a per-pixel basis. Ultimately, through attention maps, attention is aggregated between each slot and pixel to achieve object-centric visual feature representation, enabling the adoption of data-driven inductive biases. Trained on unsupervised object discovery and supervised attribute prediction tasks, Slot Attention can extract object-centric representations, enabling a comprehensive understanding of multi-input visual images as depicted in Fig. 3.
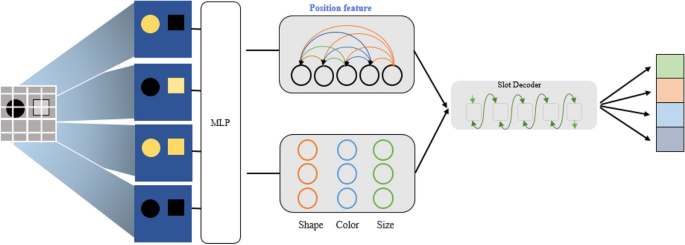
Object-centric slot attention mechanism.
Firstly, the Convolutional Neural Network (CNN) encodes the input image to generate visual feature maps of dimensions \(HW\times {{D}_{enc}}\),where \(H\) and \(W\) represent the height and width of the input image. The Slot Attention mechanism, in a single iteration over a set of input features, maps \(N\) input feature vectors through iterative attention to \(K\) output slots16. Here, the slots are \(K\) output slots with a dimensionality of \({{D}_{slots}}\),\(slots\in {{R}^{K\times D}}\).The slots are initialized randomly and are bound to specific input attributes through \(T\) iterations. The slots possess learnable mean and variance, denoted by \(\mu \in {{R}^{{{D}_{slots}}}}\) and \({{\sigma }^{2}}\in {{R}^{{{D}_{slots}}}}\) . utilize learnable linear transformations q, k, and v to map inputs and slots to a shared dimension \(D\).
$$\begin{aligned} \begin{aligned}&atte{n_{i,j}}: = \tfrac{{\exp ({M_{i,j}})}}{{\sum \nolimits _l {\exp ({M_i},l)} }},where \\&M: = \frac{1}{{\sqrt{D} }}k(inputs).q{(slots)^T} \in {R^{HW \times K}} \\ \end{aligned} \end{aligned}$$
(1)
To prevent the attention mechanism from overlooking input features, it is specified that the sum of attention coefficients for input feature vectors is 1. To enhance the stability of the attention mechanism, we enforce this constraint through weighted averaging.
$$\begin{aligned} \begin{aligned}&update: = {W^T}.v(inputs) \in {R^{K \times D_{slots}}}, \\&where\begin{array}{*{20}{c}} & \end{array}{W_{i,j}}: = \frac{{att{n_{i,j}}}}{{\sum \nolimits _{l = 1}^N {att{n_{l,j}}} }}. \\ \end{aligned} \end{aligned}$$
(2)
The slot attention mechanism controls the slot updating through a hidden gated unit with \({D_{slots}}\)33, ensuring the improvement of output performance by employing a multi-layer perceptron with residual connections and RELU activation to transform the gated unit. In practice we further add a small offset \(\delta\) to the attention coefficients to avoid numerical instability. An MLP with residual connections34 acts independently on each slot, enabling the capture of features such as shape, color, and size of input images through feature aggregation of the slot attention mechanism35. To alleviate the insensitivity of the slot attention mechanism to positional information, we introduce an enhanced positional encoding method in the model. Specifically, by establishing the visual center of an image and establishing interactive relationships between each sub-image and the center, we obtain relative positional information for each sub-image. Verification of positional information accuracy is conducted through transformations applied to the visual center. This enhancement aims to enhance the model’s perception of positional information and strengthen the correlation between position and features.The algorithm logic can be seen in Table 1.
After the slot attention mechanism, we introduced a gating mechanism36. In addition to segregating different representations into the relational bottleneck method, we also introduced a bidirectional reasoning mechanism. This mechanism constructs a feedback loop to compare similar representations in the answer set and question set, reducing unnecessary inference interference. For instance,as in Fig. 2, feedback from the answer set reveals a consistent shape pattern, which is then fed back into the forward reasoning process, thereby enhancing the model’s inference efficiency and accuracy.
Bottleneck method
The architecture of traditional neural networks constrains their focus on individual input attributes, emphasizing the perception of overall input features. This limitation makes it challenging in practice to identify complex natural conceptual objects37. To address this issue, we have adopted a data-driven approach to induce abstract models, introducing the principle of a relational bottleneck. This method encourages the emergence of abstract mechanisms in the network by restricting information processing to primarily focus on relationships between inputs. By introducing a controller to decouple the abstract representation of input from embedded perceptual information, this separation ensures that the representation in the control path is abstract relational. It facilitates the learning of rule embeddings at different hierarchical levels and granularities, enabling rapid learning of relational patterns and systematic generalization within the network.
The relational bottleneck represents an inductive bias that prioritizes the representation of relationships (such as “same” and “different”) over mixed representations of all object features.We define the relational bottleneck as a mechanism that restricts the flow of information from the perceptual system to downstream inference systems, such that the representations passed to downstream processes are composed entirely of relationships. Given input representing individual objects, the relational bottleneck constrains the representations passed to downstream inference processes to capture only the relationships between these objects (for example, whether objects share the same color). Even though the objects depicted in these images may be different, there exist abstract relationships between individual attributes such as color and shape. The relational bottleneck method extracts abstract relationships and key attribute features from known images to infer unknown images. By abstracting representations of individual attributes and aggregating abstract representations of multiple attributes, the method achieves decoupling of aggregated representations of multiple attributes, enabling the inference of unknown shapes.
Consider an information processing system that receives input signals \(X\) and aims to predict target signal \(Y\). Input \(X\) is processed to generate a compressed representation \(Z\) = f(\(X\)) (referred to as a “bottleneck”), which is then used for predicting \(Y\). The core idea of information bottleneck theory is “minimal sufficiency,” where if \(Z\) contains all the information about \(Y\) encoded in \(X\), then it is sufficient for predicting \(Y\). This can be represented as abstract relational reasoning\(X \rightarrow Z \rightarrow Y\), where X and \(Y\) are sets of the most relevant feature attributes. It can also be characterized as I (\(Z\); \(Y\)) = I(\(X\); \(Y\)), where \(I(*;*)\) denotes mutual information, and \(X\) represents the set of feature attributes of the objects.
$$\begin{aligned} \begin{aligned} X = ({x_{size}},{x_{colour,}}...,{x_n}) \end{aligned} \end{aligned}$$
(3)
For a sufficiently compressed representation \({Z^*}\), we have
$$\begin{aligned} \begin{aligned} I(X;Z) \le I(X;{Z^*}) \end{aligned} \end{aligned}$$
(4)
There exists a trade-off between achieving maximum compression while retaining as much relevant information as possible. This trade-off is captured by the information bottleneck objective, which is achieved by minimizing
$$\begin{aligned} \begin{aligned} {\text {minimize }}\Psi (Z) = I(X;Z) - \beta I(Z;Y) \end{aligned} \end{aligned}$$
(5)
where \(\beta\) controls this trade-off.This objective reflects the tension between preserving the information related to \(Y\) captured by the second term and discarding the information captured by the first term during the compression process. The relational bottleneck mechanism learns from the input and compresses it into relational representations that are separate from object features. This enables the model to search within a smaller compressed representation space, a constrained space that ensures sufficient attribute features to complete tasks while excluding much information irrelevant to the input signal \(X\). This promotes effective learning of abstract relationships.
Sequence-to-sequence and algebraic machine reasoning
In the relational bottleneck approach, the control path cannot actively inspect or manipulate the specific content in the perceptual path. Instead, it influences the system’s behavior by comparing perceptual representations, specifically identifying system invariances through observation comparisons.
To better simulate human reasoning, we propose a reasoning framework highly suitable for abstract reasoning called the Algebraic Machine Reasoning Framework, which consists of two stages: (1) Relational Bottleneck Algebraic Representation and (2) Algebraic Machine Reasoning. In the first stage, the problem images are initially divided into nine sub-images. By integrating slot attention mechanisms and the relational bottleneck approach, the sub-images are decomposed into different slots using slot attention mechanisms. The relational bottleneck approach is then employed to represent key feature information from different slots. For simple Raven’s Progressive Matrices (RPM) visual question-answering tasks, direct comparisons between sub-images within the same slot are not necessary. Instead, we can represent the overall information of the nine sub-images in the question as \({J_{ij}}\), where \({J_{ij}}\) denotes the representation of the sub-image at the i-th row and j-th column.Similarly, the representations of the sub-images in the answer set are denoted as \({A_{ij}}\).
$$\begin{aligned}&\begin{array}{l} \mathbf{{J}} = [{J_{11}},{J_{12}},...{J_{ij}}],1 \le i,j \le slots*9 \end{array} \end{aligned}$$
(6)
$$\begin{aligned}&\begin{array}{l} \mathbf{{A}} = [{A_{11}},{A_{12}},...{A_{ij}}],1 \le i,j \le slots*9 \end{array}\end{aligned}$$
(7)
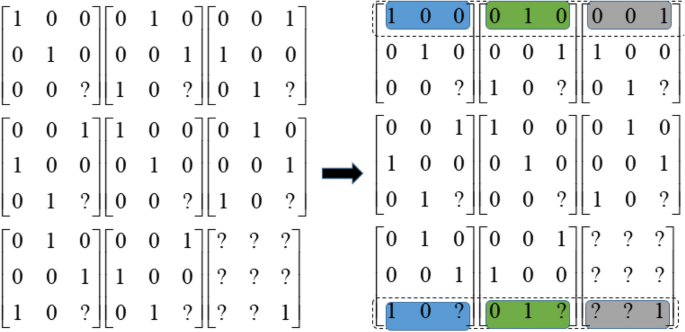
Inspired by human cognition, we employ the relational bottleneck method to constrain and differentiate feature information, thereby extracting abstract representations from images and obtaining sequential features of matrices through comparisons of these abstract representations. Specifically, taking \({J_{11}}\) as the visual center, we compare \({J_{11}}\) with \({J_{ij}}\) (including \({J_{11}}\)) based on the single attribute representation obtained through the relational bottleneck method. If the two representations are identical, we assign a value of 1; otherwise, we assign 0 and record the result at the \({J_{ij}}\) position. This process yields the attribute comparison results between this visual center and other sub-images, denoted as the relational bottleneck matrix \({G_{11}}\). Subsequently, selecting another sub-image\({J_{ij}}\) as the visual center, we perform the same attribute comparisons to generate relational bottleneck matrices \({G_{ij}}\) represented solely in 0 and 1. The matrix representation G, based on the bias of inductive properties, is then derived from the combination of the nine relational bottleneck sub-matrices at specific positions.
$$\begin{aligned} \begin{array}{l} G = [{G_{11}},{G_{12}},...{G_{ij}}],1 \le i,j \le slots * 9 \end{array}\end{aligned}$$
(8)
Similarly, the slot attention mechanism, serving as the initial attribute extraction module, can also decompose sub-images into different slots. For images with complex combinations of sub-image attribute features, comparing whether the slot attribute representations of different sub-images at the same position are identical enables the establishment of relational bottleneck matrices with more representation relationships. However, a more complex relational bottleneck matrix does not necessarily facilitate solving visual reasoning problems. The appropriate number of slots is crucial for solving various RPM problems.
In the second stage, we simplify the task of “solving RPM tasks” to “solving the problem of sequential invariance in relational bottleneck matrices.” In the first stage, we demonstrated the relational bottleneck matrices containing only 0 and 1 obtained through slot attention mechanisms and the relational bottleneck method. Subsequently, we observed distinct invariant sequential features in the relational bottleneck matrices. Extending this periodic pattern to unknown graphic relationship sequences allows us to derive a single-attribute relational bottleneck matrix for the unknown graphics. Aggregating the features of relational bottleneck matrices with multiple attributes enables the derivation of the key attribute features of unknown graphics. Thus, visual reasoning problems are transformed into algebraic methods, where the task is to examine the invariance of these extracted patterns across multiple sequences. See Fig. 4. In high-dimensional relational bottleneck matrix G, finding sequential invariance is relatively easy. Taking row sequences as an example, where \({G_{ij}}\) represents the digit at the \({i}th\) row and \({j}th\) column of the relational bottleneck matrix, arranging this relational matrix in an invariant way by rows and columns and storing it in an array, assuming different sequences as cyclic features, and verifying the assumption with existing sequences enables the determination of sequence invariance. Partial sequence features of unknown graphics are known, and through the coupling of invariant sequence features, the complete sequence features of unknown graphics can be derived. Decoupling through each relational bottleneck matrix yields the key attribute features of unknown graphics, facilitating the comprehensive inference of unknown graphics.
Experiment
Experimental setup
We evaluated the abstract reasoning framework on RAVEN2 and I-RAVEN11. These two datasets consist of 7 different configurations of RPM, collectively examining the model’s multi-visual input reasoning capabilities. Each configuration comprises 1000 samples. We divided the dataset into 10 parts, using 6 groups for training, 2 for validation, and 2 for testing. The image size was adjusted to 80x80, with pixels normalized to the range [0, 1]. Data augmentation techniques, including rotations in multiples of 90 degrees and overall brightness adjustments, were applied during training.As shown in Table 2 .
The forward process primarily involves the preliminary extraction of feature information using CNN and MLP, with ReLU serving as the activation function to normalize the network’s output into a probability distribution over predicted output categories. The loss function comprises the cross-entropy loss between the relation bottleneck and centroid representations, acting as the overall loss function.
For the slot attention mechanism, we employed K = 9 slots for RAVEN and K = 16 slots for I-RAVEN. The number of iterations for the slot attention mechanism was set to T = 3 for both I-RAVEN and RAVEN, with the slot dimension set to \({D_{slot}}\) = 32. Hyperparameters for the transformer module included setting the number of heads H to 8, the number of layers L to 6, the dimension \({D_{head}}\) per head to 32, the dimension of the hidden layer in the MLP \({D_{MLP}}\) to 512, and a dropout rate of 0.1.All models were implemented in PyTorch and optimized using Adam38 on Nvidia GPUs. We conducted testing on 2000 instances, with running these instances on an 8-core Intel i7 CPU processor taking 13 h.
Analysis of experimental results
We compared our reasoning framework with the weak baselines LSTM2, WReN14, ResNet14, and the strong baselines ResNet+DRT14, Wild11, DCNet39citep, SRAN11, PrAE10, and STSN18, all of which are mainstream frameworks for visual reasoning.
In both datasets, RPM was generated based on 7 configurations. We trained the initial perceptual module driven by data to train CNN on 3500 images (600 images per configuration) from I-RAVEN18 and the object-centric slot attention perceptual module. We used neutral data to train the slot attention mechanism and transformer decoder and fine-tuned them on the main task to improve their accuracy in extracting initial feature attributes. Our model achieved an average accuracy of 96.8% in predicting unknown shapes across 7 types of tests, surpassing all baseline models as shown in Table 3.
It was observed in the experiment that among the 8 sub-images segmented from each image, selecting the sub-image with the maximum number of objects and matching the corresponding slots yielded optimal results (including empty slots). Our model demonstrated more advantages in problems with a higher number of visual inputs, achieving higher accuracy compared to the baselines in \(2\times 2\) Grid and \(3\times 3\) Grid problems. Due to the inherent characteristics of the relational bottleneck matrix, with more visual inputs, richer relation connections are obtained, making common sequences easier to acquire. Similarly, we conducted separate measurements on different test types, as shown in Table 4.
Ablation studies were also part of our experimental setup. Basic image enhancement and appropriate geometric rotations were performed, and since these operations were conducted on the overall data, they did not introduce new interference. Our data augmentation method proved to significantly enhance the model accuracy, as removing data augmentation led to a decrease of around 4% in model accuracy. We also conducted ablations on the size of the transformer module and found that a smaller number of transformer layers, L = 4 layers, performed poorly. The optimal number of layers was determined to be 6, with this parameter affecting the average accuracy by approximately 2%.
A distinctive feature of our model is the object-centric representation. We weighted the input feature vector values of the image by averaging and only utilized the initial CNN and essential feature extraction to primarily extract the visual object’s feature attributes, reducing the extraction of object relations. By removing the slot attention mechanism from the model, the test accuracy decreased by over 40%, as indicated by “our-CNN” in Table 3. This effect was particularly pronounced in the “\(3\times 3\) Grid” test, highlighting the crucial capability of our object-centric model in extracting relations between multiple input objects.
We also eliminated the position interaction module from the slot attention mechanism, resulting in an overall accuracy decrease of approximately 5%. The model’s sensitivity to position decreased, especially with an 8% accuracy drop in the U-D test. These results demonstrate that the object-centric representation is a central component of our approach.
RPM Instance. In this instance, there are no visual changes in shape, color, or size. It can be inferred that the second figure in each row is the sum of the first and third figures.
Our relational bottleneck method excels in extracting abstract relations from multiple visual inputs. As illustrated in Fig. 5, conventional neural network models struggle to perceive these abstract relations. In this scenario, the second figure can be derived by superimposing (including positions) the first and third figures in each row. Similarly, inferring the third figure can be achieved by subtracting the first figure from the second.However, our model demonstrates outstanding similarity extraction mechanisms. Through bidirectional reasoning and feedback mechanisms, it excludes changes in color, shape, and size, focusing solely on abstract representations of quantity and position. By evenly distributing each individual sub-image into 9 slots, and comparing the similarity of attributes between slots, this abstract mechanism is differentiated. By inferring through sequence similarity within the 9 slots, the complete answer can be deduced.
Conclusions
In this paper, we introduce an abstract reasoning framework that emphasizes object-centric strong inductive biases. This framework combines the object-centric slot attention mechanism and the relational bottleneck method to extract abstract rules for solving complex multi-visual input reasoning problems. Similarity forms the cornerstone of our reasoning system, and by identifying system invariances through comparisons, we establish relational bottleneck matrices to uncover common sequences for inferring the characteristics of unknown shapes. The incorporation of algebraic methods is a distinctive feature of our model, offering a novel solution for visual reasoning. However, real-world complex images lack clear segmentation boundaries and necessitate customized decomposition of their attribute features. Further exploration is required to truly address visual reasoning on datasets from the human world. In our future work, we aim to delve deeper into simulating human reasoning and extend the methods based on similarity and relational bottlenecks to other visual reasoning datasets. Our enduring goal is to achieve structured abstract reasoning capabilities akin to those of humans.
Data availability
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Carpenter, P. A., Just, M. A. & Shell, P. What one intelligence test measures: A theoretical account of the processing in the raven progressive matrices test. Psychol. Rev. 97, 404 (1990).
Zhang, C., Gao, F. & Raven, J., et al. A dataset for relational and analogical visual reasoning. In CVPR, 5317–5327 (2019).
Snow, R. E. et al. The topography of ability and learning correlations. Adv. Psychol. Hum. Intell. 2, 103 (1984).
Perret, P. Children’s inductive reasoning: Developmental and educational perspectives. J. Cogn. Educ. Psychol. 14, 389–408 (2015).
Carroll, J. B. Human cognitive abilities: A survey of factor-analytic studies Vol. 1 (Cambridge University Press, 1993).
Jaeggi, S. M. et al. Improving fluid intelligence with training on working memory. Proc. Natl. Acad. Sci. 105, 6829–6833 (2008).
Lyu, M., Liu, R. & Wang, J. Solving raven’s progressive matrices using rnn reasoning network. In ICCIA, 32–37 (IEEE, 2022).
Zhang, C., Jia, B. & et al, G. Learning perceptual inference by contrasting. NIPS32 (2019).
Zombori, Z., Urban, J. & Brown, C. E. Prolog technology reinforcement learning prover: (System description). In International Joint Conference on Automated Reasoning, 489–507 (Springer, 2020).
Zhang, C., Jia, B. & et al, Z. Abstract spatial-temporal reasoning via probabilistic abduction and execution. In CVPR, 9736–9746 (2021).
Hu, S., Ma, Y. & et al, L. Stratified rule-aware network for abstract visual reasoning. In AAAI, vol. 35, 1567–1574 (2021).
Benny, Y., Pekar, N. & Wolf, L. Scale-localized abstract reasoning. In CVPR, 12557–12565 (2021).
Li, Q., Huang, S. & et al, H. Closed loop neural-symbolic learning via integrating neural perception, grammar parsing, and symbolic reasoning. 5884–5894 (PMLR, 2020).
Barrett, D. & Hill, F. A. A. Measuring abstract reasoning in neural networks. In International conference on machine learning, 511–520 (PMLR, 2018).
Engelcke, M., Parker Jones, O. & Posner, I. Genesis-v2: Inferring unordered object representations without iterative refinement. In Advances in Neural Information Processing Systems, vol. 34, 8085–8094 (Curran Associates, Inc., 2021).
Locatello, F. et al. Object-centric learning with slot attention. Adv. Neural Inf. Process. Syst. 33, 11525–11538 (2020).
Ding, D. et al. Attention over learned object embeddings enables complex visual reasoning. NIPS 34, 9112–9124 (2021).
Mondal, S. S. A. A. Learning to reason over visual objects. ICLR (2023).
Veerapaneni, R. & et al, C.-R. Entity abstraction in visual model-based reinforcement learning. In Conference on Robot Learning, 1439–1456 (PMLR, 2020).
Kim, J. & et al, C. Shepherding slots to objects: Towards stable and robust object-centric learning. In CVPR, 19198–19207 (2023).
Xu, M. & et al, Z. End-to-end semi-supervised object detection with soft teacher. In CVPR, 3060–3069 (2021).
Elsayed, G. A. A. Savi++: Towards end-to-end object-centric learning from real-world videos. NIPS 35, 28940–28954 (2022).
Kabra, Raa. Simone: View-invariant, temporally-abstracted object representations via unsupervised video decomposition. NIPS 34, 20146–20159 (2021).
Chen, C., Deng, F. & Ahn, S. Roots: Object-centric representation and rendering of 3d scenes. J. Mach. Learn. Res. 22, 1–36 (2021).
Tishby, N. & Zaslavsky, N. Deep learning and the information bottleneck principle. In 2015 ieee information theory workshop (itw), 1–5 (IEEE, 2015).
Altabaa, A, et al. Abstractors and relational cross-attention: An inductive bias for explicit relational reasoning in transformers. ICLR (2023).
McClelland, J. L. Capturing advanced human cognitive abilities with deep neural networks. Trends Cognit. Sci. 26, 1047–1050 (2022).
Kerg, G. et al. On neural architecture inductive biases for relational tasks. ArXivabs/2206.05056 (2022).
Webb, T. W., Sinha, I. & Cohen, J. D. Emergent symbols through binding in external memory. arXiv:2012.14601 (2020).
Kim, J., Ricci, M. & Serre, T. Not-so-clevr: Learning same-different relations strains feedforward neural networks. Interface focus 8, 20180011 (2018).
Ichien, N. et al. Visual analogy: Deep learning versus compositional models. In Proceedings of the 43rd Annual Meeting of the Cognitive Science Society (2021).
Huai, T. & Yang, S. Debiased visual question answering via the perspective of question types. Pattern Recognit. Lett. 178, 181–187 (2024).
Cho, K. & van Merri et al. Learning phrase representations using RNN encoder–decoder for statistical machine translation. In EMNLP, 1724–1734 (Association for Computational Linguistics, Doha, Qatar, 2014).
He, K., Zhang, X. & Ren, S. Deep residual learning for image recognition. In CVPR, 770–778 (2016).
Zhang, Y. et al. Prn: Progressive reasoning network and its image completion applications. Sci. Rep. 14, 23519 (2024).
Li, W. & Sun, J. Visual question answering with attention transfer and a cross-modal gating mechanism. Pattern Recognit. Lett. 133, 334–340 (2020).
Chen, Z., De Beuckelaer, A., Wang, X. & Liu, J. Distinct neural substrates of visuospatial and verbal-analytic reasoning as assessed by raven’s advanced progressive matrices. Sci. Rep. 7, 16230 (2017).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization (ICLR, 2014).
Zhuo, T. & Kankanhalli, M. Effective abstract reasoning with dual-contrast network. ICLR (2022).
Acknowledgements
Our project has received support from the Ministry of Science and Technology’s Major Project on Technological Innovation 2030 - “Next Generation Artificial Intelligence,” with the project number 2020AAA0109300.
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article
Cite this article
Zheng, M., Wan, W. & Fang, Z. Abstract visual reasoning based on algebraic methods. Sci Rep 15, 3482 (2025). https://doi.org/10.1038/s41598-025-86804-3
Received: 20 October 2024
Accepted: 14 January 2025
Published: 28 January 2025
DOI: https://doi.org/10.1038/s41598-025-86804-3



