.png)

Introduction
Data classification is the cornerstone of any effective data privacy strategy. Before you can protect sensitive information, you first need to understand what kind of data you're dealing with—whether it’s personal (PII), financial (FIN), health-related (PHI), or something else entirely.
Traditionally, this process involves training machine learning models—using classical algorithms or transformer-based models like BERT—to generate embeddings and classify content. While effective, these pipelines often require significant time, resources, and labeled data.
We’re proposing something simpler. Smarter. More agile.
A modern, streamlined architecture powered by generative AI (like GPT) that drastically reduces complexity—without compromising intelligence. No heavy pipelines, no retraining cycles—just smart, contextual classification driven by prompt-based understanding.
🔄 The Data Classification Workflow
The workflow for classifying data is conceptually simple—but mission-critical. It typically involves two core steps:
-
Data Discovery
Scan data sources—whether files, databases, cloud storage, or messaging systems—to locate and extract raw data. -
Data Classification
Analyze the discovered data to determine its category (e.g., PII, financial, health, internal, etc.) based on context, content, and business rules.
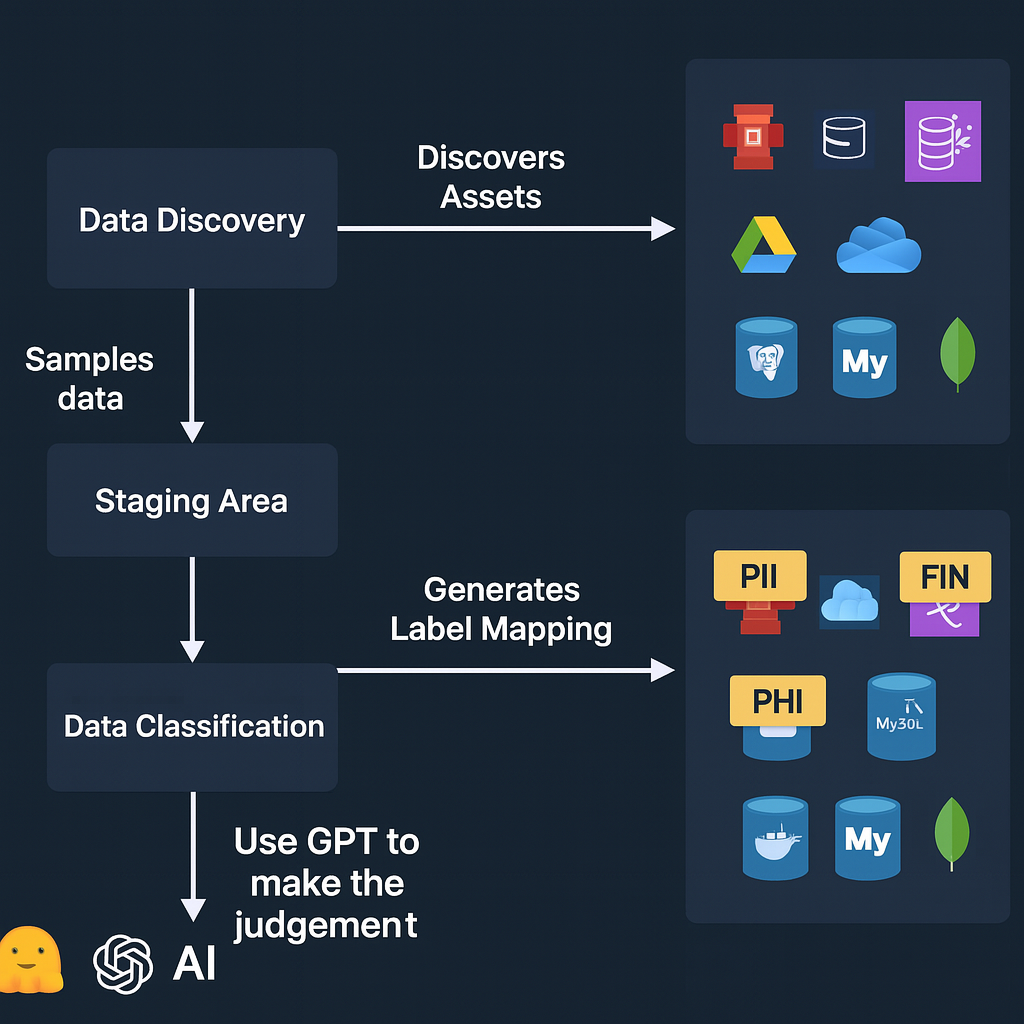
This process is the backbone of any privacy, security, or governance initiative—whether you're meeting compliance requirements or just trying to get a handle on your data landscape.
🔍 Data Discovery
Data discovery is more nuanced than it might first appear. Legacy tools often attempt to scan every record across all data sources, which can quickly spiral into O(n!) complexity—a nightmare for scale and performance.
To make discovery faster, smarter, and more efficient, modern systems can apply a combination of the following techniques:
-
Metadata Scan
Instead of scanning the entire dataset, inspecting just the schema or metadata can reveal potential sensitive fields (like email, ssn, credit_card), dramatically reducing workload. -
Sampling
Analyzing a subset of records (e.g., first 1,000 rows) helps reduce complexity to O(n), while still surfacing common data patterns and classes. -
Localized Full Scan
When needed, you can perform a targeted deep scan on high-risk or sensitive tables—balancing depth with performance and typically reducing complexity to O(n²).
To streamline this process, we introduced Superscan—an intelligent data discovery engine that combines these techniques for optimized classification performance across large, complex data ecosystems.
🤖 Classical ML vs. GPT for Data Classification
Classical machine learning techniques for data classification—such as Logistic Regression, Decision Trees, Random Forests, Support Vector Machines (SVM), K-Nearest Neighbors (KNN), Naive Bayes, Gradient Boosting (XGBoost, LightGBM, CatBoost), LDA, QDA, and SGD classifiers—have been foundational in the field. However, these approaches can be complex to implement and maintain. They typically require:
- Large amounts of labeled training data
- Feature engineering and data preprocessing
- Task-specific model training and tuning
- Retraining when data structure or schema changes
By contrast, GPT-based classification offers a smarter and more flexible alternative:
- ✅ Supports zero-shot and few-shot learning
- ✅ Understands unstructured natural language natively
- ✅ Captures context and semantics across entire documents
- ✅ Easily adapts to new tasks via prompting—no retraining required
- ✅ Handles multi-label and ambiguous classifications naturally
- ✅ Requires no manual feature engineering
- ✅ Pretrained on vast and diverse datasets
- ✅ Scales to many use cases with a single model
- ✅ Offers flexible output formats (structured, free-form, ontology-aware, etc.)
- ✅ Enables faster iteration and development cycles
🧠 Introducing Superclass
To bring these benefits into production, we built Superclass—a high-performance document intelligence engine that combines advanced text extraction with GPT-powered classification.
- Accepts images, raw text, structured or unstructured content
- Automatically detects ontologies, data classes, and entity types
- Offers both a CLI tool and an HTTP API server for seamless integration
Whether you're classifying enterprise documents, parsing emails, or scanning financial statements, Superclass simplifies and accelerates the classification process—without the overhead of traditional ML pipelines.
You can send an image, text, unstructure or structure data to the API and it would return what ontology it belongs to, what class it belongs to.
This enables a goal-driven architecture where you can issue high-level objectives like:
Find all images in the back office's shared drive that contain any form of identification—such as driving licenses, state IDs, library cards, or student cards.With this approach, data discovery becomes intelligent and targeted. You’re not just scanning files—you’re identifying and classifying content in context. This allows your organization to map the blast radius of a potential data compromise and take proactive steps toward mitigation and compliance.


