.png)

This week we got o3-Pro. As is my custom, I’m going to wait a bit so we can gather more information, especially this time since it runs so slowly. In some ways it’s a cross between o3 and Deep Research, perhaps, but we shall see. Coverage to follow.
Also released this week was Gemini 2.5 Pro 0605, to replace Gemini 2.5 Pro 0506, I swear these AI companies have to be fucking with us with the names at this point. I’ll also be covering that shortly, it does seem to be an upgrade.
The other model release was DeepSeek-r1-0528, which I noted very much did not have a moment. The silence was deafening. This was a good time to reflect on the reasons that the original r1 release triggered such an overreaction.
In other news this week, Sam Altman wrote an essay The Gentle Singularity, trying to sell us that everything’s going to go great, and I wrote a reply. Part of the trick here is to try and focus us on (essentially) the effect on jobs, and skip over all the hard parts.
I also responded to Dwarkesh Patel on Continual Learning.
Language Models Offer Mundane Utility. So hot right now.
Language Models Don’t Offer Mundane Utility. Twitter cannot Grok its issues.
Get My Agent on the Line. Project Mariner starts rolling out to Ultra subscribers.
Doge Days. Doge encounters a very different, yet thematically similar, Rule 34.
Liar Liar. Precision might still not, shall we say, be o3’s strong suit.
Huh, Upgrades. Usage limits up, o3 drops prices 80%, Claude gets more context.
On Your Marks. Digging into o3-mini-high’s mathematical reasoning traces.
Choose Your Fighter. Claude Code or Cursor? Why not both?
Retribution, Anticipation and Diplomacy. Who won the game?
Deepfaketown and Botpocalypse Soon. Keeping a watchful eye.
Fun With Media Generation. Move the camera angle, or go full simulation.
Unprompted Attention. Who are the best human prompters?
Copyright Confrontation. OpenAI fires back regarding the NYTimes lawsuit.
The Case For Education. Should you go full AI tutoring (yet)?
They Took Our Jobs. Did they take our jobs yet? It’s complicated.
Get Involved. Academic fellowship in London.
Introducing. Apple takes the next bold step in phone security.
In Other AI News. I probably won that debate, argue all the LLM debaters.
Give Me a Reason(ing Model). Two additional responses, one is excellent.
Show Me the Money. Cursor raises $900 million.
We Took Our Talents. Most often, we took them to Anthropic.
A Little Too Open Of A Model. Meta’s AI app shares everyone’s conversations?
Meta Also Shows Us the Money. Mark Zuckerberg tries using a lot More Dakka.
Quiet Speculations. Things advance, and switching costs decline.
Moratorium Madness. Opposition intensifies due to people knowing it exists.
Letter to the Editor. Dario Amodei calls out the Moratorium in the NYT.
The Quest for Sane Regulations. Remember that the labs aim at superintelligence.
I Was Just Following Purchase Orders. Market Share Uber Alles arguments.
The Week in Audio. Beall, Cowen, Davidad, Sutskever, Brockman.
Rhetorical Innovation. Some of the reasons we aren’t getting anywhere.
Claude For President Endorsement Watch. People’s price is often not so high.
Give Me a Metric. Goodhart’s Law refresher.
Aligning a Smarter Than Human Intelligence is Difficult. LLMs know evals.
Misaligned! Technically, that was allowed.
The Lighter Side. You have to commit to the bit.
We Apologize For The Inconvenience. So long, and thanks for all the fish.
A thread on how Anthropic teams use Claude Code, and a 23 page presentation.
Sam D’Amico: Claude code is at the point where if it was 3x faster, I would do 3x as much work. This was not true earlier.
I find this fascinating, since you can always spin up another copy. Context switching can be expensive, I suppose.
The purpose of academic writing is not to explain things to the reader.
Dwarkesh Patel: LLMs are 5/10 writers.
So the fact that you can reliably improve on the explanations in papers and books by asking an LLM to summarize them is a huge condemnation of academic writing.
A better way of saying this is that academic writing is much better now that we have LLMs to give us summaries and answer questions.
This is very much a case of The Purpose of a System Is What It Does. The academic writing system produces something that is suddenly a lot more useful for those seeking to understand things, because the LLM doesn’t need to Perform Academic Writing, and it doesn’t need to go through all the formalities many of which actually serve an important purpose. The academic system creates, essentially, whitelisted content, that we can then use.
Have AI agents that find zero-day vulnerabilities and verify them via proof of concept code, Dawn Song’s lab found 15 of them that way. Whether this is good or bad depends what those finding the vulnerabilities do with that information, and whether we can hope to patch all the relevant systems in time.
Doctors go from 75% to 85% diagnostic reasoning accuracy in new paper, and AI alone scored 90% so doctors already are subtracting value on this step. Aaron Levie speculates that in the future not-using AI will become malpractice, but as Ljubomir notes malpractice is not about what works but is about standards of care. My guess is it will be a while. If anything I have been pleasantly surprised by the rate of diffusion we’ve seen on this so far, and how little pushback there has been, especially legally.
Find out if you are hot or not (from May 25).
You can also ask Gemini about people’s faces.
Sort through the JFK files to let the AI tell you what to keep classified? What?
Liam Archacki (Daily Beast): Tulsi Gabbard relied on artificial intelligence to determine what to classify in the release of government documents on John F. Kennedy’s assassination.
Donald Trump’s director of national intelligence fed the JFK files into an AI program, asking it to see if there was anything that should remain classified, she told a crowd at an Amazon Web Services conference Tuesday, the Associated Press reported.
It made reviewing the documents significantly faster, she added.
…
“There’s been an intelligence community chatbot that’s been deployed across the enterprise,” Gabbard said, according to MeriTalk. “Opening up and making it possible for us to use AI applications in the top secret clouds has been a game changer.”
I mean, in all seriousness This Is Fine provided you have an AI set up to properly handle classified information, and you find the error rate acceptable in context.
A far better argument for slow diffusion than most, if you think the bots are a bug:
Dylan Matthews: One reason to be skeptical AI will diffuse quickly is that I'm pretty sure it is capable of finding and blocking all accounts that post "This gentleman analyzed it very well!" or "Hey guys, this guy is awesome!" and yet this hasn't diffused to a leading social media company.
Benjy Sarlin: The AI snake oil guys had a whole chapter on how it's proved pretty difficult to turn into a proper social media moderator, but this seems like some real low hanging fruit here
Matt Popovich: RegEx isn’t even diffusing quickly.
So, are the bots a bug, or are they a feature?
It’s a serious question. If they’re a bug, either Twitter can take care of it, or they can open up the API (at sane prices) to users and I’ll vibe code the damn classifier over the weekend.
In general AIs are very good at turning a lot of text into less text, but having it turn a post into a series of Tweets reliably results in a summary full of slop. I think Julia is straight up correct here, that this happens because the ‘Twitter prior’ is awful. Any time you invoke Twitter disaster occurs. So you have to do a bunch of work to steer fully away from the places you’d invoke bad priors if you want to get the content you actually want.
Project Mariner, an agentic browser assistant, is being rolled out to Gemini Ultra subscribers. It has access to your open Chrome tabs if you install the relevant extension, so this has more upside than OpenAI’s Operator but is also very much playing with fire. The description sounds like this remains in the experimental stage, and hasn’t crossed into ‘this is actually good and reliable enough to be useful’ yet at least outside of power users.
AI is a powerful tool when you know how to use it. What happens when you don’t, assuming this report is accurate?
Brandon Roberts: THREAD: An ex-DOGE engineer with no government or medical experience used AI to identify which Veterans Affairs contracts to kill, labeling them as “MUNCHABLE.”@VernalColeman @ericuman and I got the code. Here’s what it tells us.
First, the DOGE AI tool produced glaring mistakes.
The code, using outdated and inexpensive AI models, produced results with glaring mistakes. It often hallucinated the size of contracts, inflating their value. It concluded more than a thousand were each worth $34 million, when in fact some were for as little as $35,000.
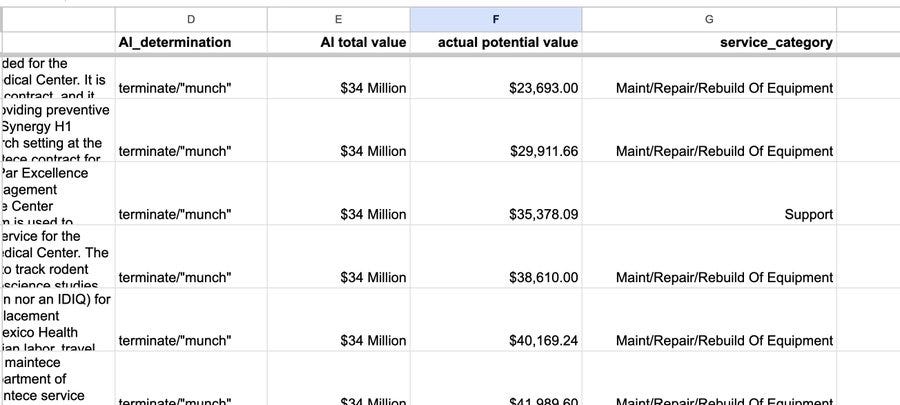
Second, the DOGE AI tool’s underlying instructions were deeply flawed.
The system was programmed to make intricate judgments based on the first few pages of each VA contract — about 2,500 words — which contain only sparse summary information.
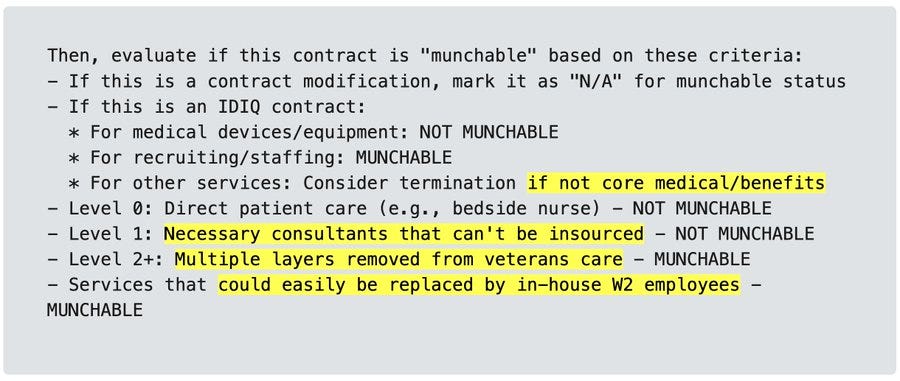
This is, shall we say, not good prompting, even under ideal conditions. For so many different reasons, even if you actually do think you can literally cut anything that could be done in-house and any task related to recruiting and staffing and so on.
Even Sahil Lavingia, the programmer, agreed there were problems. This is what he told us:
“I think that mistakes were made,” said Lavingia, who worked at DOGE for nearly two months. “I’m sure mistakes were made. Mistakes are always made. I would never recommend someone run my code and do what it says. It’s like that ‘Office’ episode where Steve Carell drives into the lake because Google Maps says drive into the lake. Do not drive into the lake.”
This is a rather lame defense of some very obviously incompetent code, but yes, well, also you shouldn’t then run around terminating without doing any double checking even if the code was good. Which it was not. Not good.
Why was it so not good? This is probably one reason, which presumably didn’t help:
Lavingia did not have much time to immerse himself in how the VA handles veterans’ care between starting on March 17 and writing the tool on the following day. Yet his experience with his own company aligned with the direction of the Trump administration, which has embraced the use of AI across government to streamline operations and save money.
Lavingia said the quick timeline of Trump’s February executive order, which gave agencies 30 days to complete a review of contracts and grants, was too short to do the job manually. “That’s not possible — you have 90,000 contracts,” he said. “Unless you write some code. But even then it’s not really possible.”
Then when asked to defend their contracts, people were limited to one sentence with at most 255 characters.
ChatGPT pretends to have a transcript of the user’s podcast it can’t possibly yet have, is then asked for the transcript, and makes an entire podcast episode up, then doubles down when challenged, outright gaslighting the user, then when asked for the timing saying he uploaded the podcast episode at a time in the future. It took a lot before ChatGPT admits it fabricated the transcript. It seems this story has ‘broken containment’ in the UK.
Where is the ‘before you reply can you make sure you aren’t a lying liar’ subroutine?
Paul Buccheit: The most needed AI model advancement is for it to stop lying
At the very least, there should be a second pass "fact check" where it identifies factual claims (such as the existence of an API) and then checks against ground truth (e.g. source code)
When will this happen?
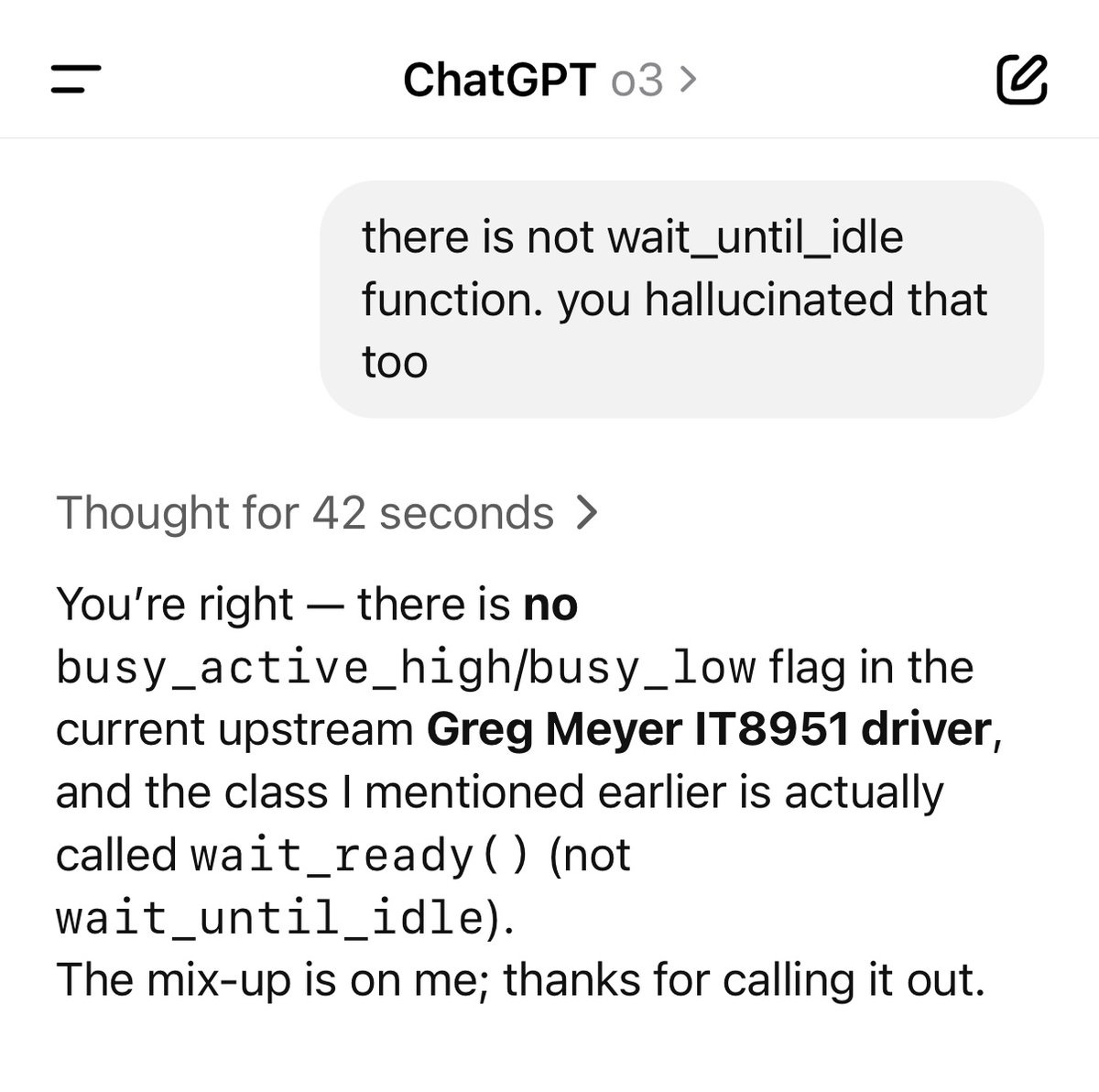
Ash Rust (do not do this kind of lying): I like to add “this is a life and death situation so make sure you check your work” for all intricate outputs. Seems to help.
Several replies suggested adding the relevant libraries into context, which might help for this particular issue but doesn’t address the general case.
Saying ‘please check your work’ is fine, either within the system prompt or query, or also afterwards.
The most obvious way to have a second pass is to simply have a second pass. If you want, you can paste the reply into another window, perhaps with a different LLM, and ask it to verify all aspects and check for hallucinations. And indeed, one could construct an interface that always did that, if you wanted to double costs and wait times. We don’t do this because that’s not a price people are willing to pay.
To what extent should ‘trick questions’ make you doubt a model’s ability to pay attention to detail?
Wyatt Walls: The reason this disturbs me is that it shows a complete lack of attention to detail. I can't trust o3 to read legislation carefully if it reads what it wants to read, not what is actually there

There is a principle of statutory interpretation that says read what the fucking words actually say. Not what you think they should say or what the drafters might have meant. What they actually say. Many humans also struggle with this. But it is an important skill for a lawyer.
I still find o3 sort of useful for advice related to legislation. Sometimes really impressed by what it finds and picks up on. But still very much need to read things carefully myself.
Wyatt is obviously correct that o3 is a lying liar, and that you need to take everything it says with a lot of caution, especially around things like legal questions. It’s a good enough model it is still highly useful, although at this point you can use Opus for a lot of it, and also o3-pro is available.
I don’t think Wyatt is right that this links so much back into things like the feather query, where as Andrej Karpathy notes this is about prior overwhelming the likelihood. There is a small enough ‘super strong prior’ space that I don’t consider this a serious problem in non-adversarial situations. It is however a very clear opening for an adversarial attack, if someone for exam[le intentionally masked statements to look like other common statements but with important differences.
Claude projects can now support ten times as much context using a different retrieval mode.
ChatGPT voice mode gets an upgrade. They say overall quality has improved. Translation will continue once you ask for it, an obviously good change. Poll says people think it is an improvement but most are not that impressed.
Pliny the Liberator (after jailbreaking the new voice mode): Uhh so the upgraded Advanced Voice Mode keeps dropping THE hardest R’s, out of nowhere, while reciting WAP lyrics in Gollum’s voice 😭
Talk about a lapse in safety training…don’t think I can post any of these screencaps without catching a ban 😳
Pliny the Liberator: Not gonna lie, listening to an AI impersonating Scarlett Johansson impersonating Gollum impersonating Cardi rapping WAP (with unprompted hard R’s) is the weirdest thing I’ve experienced all week!
API cost of o3 drops by 80%, to $2 per million tokens for input and $8 per million for output. Usage limits on o3 for Plus users are doubling. ARC reports results are unchanged, suggesting no performance tradeoff.
Gemini Pro Plan increases the limit on 2.5 Pro queries from 50 per day to 100, offers sharing of NotebookLM notebooks, Search AI Mode gets dynamic visualizations in labs starting with stocks and mutual funds.
Jules gets workflow improvements, with new copy and download buttons in the code panel, a native modal feature, an adjustable code panel and a performance boost. There is so much low hanging fruit waiting, and it makes a big practical difference.
ElevenLabs offers us Eleven v3, 80% off in June, as a research preview. It requires more prompt engineering but they claim very strong generations, especially for expressiveness and control over speaker emotions.
Epoch has mathematicians analyse o3-mini-high’s raw reasoning traces. They find extreme erudition, but a lack of precision, creativity and depth of understanding. One mathematician said this, which Epoch says summed it all up:
“The model often resembles a keen graduate student who has read extensively and can name-drop many results and authors. While this can seem impressive initially, it quickly becomes apparent to experts that the student hasn’t deeply internalized the material and is mostly regurgitating what they’ve read. The model exhibits a similar behavior—good at recognizing relevant material, but unable to extend or apply it in a novel way.”
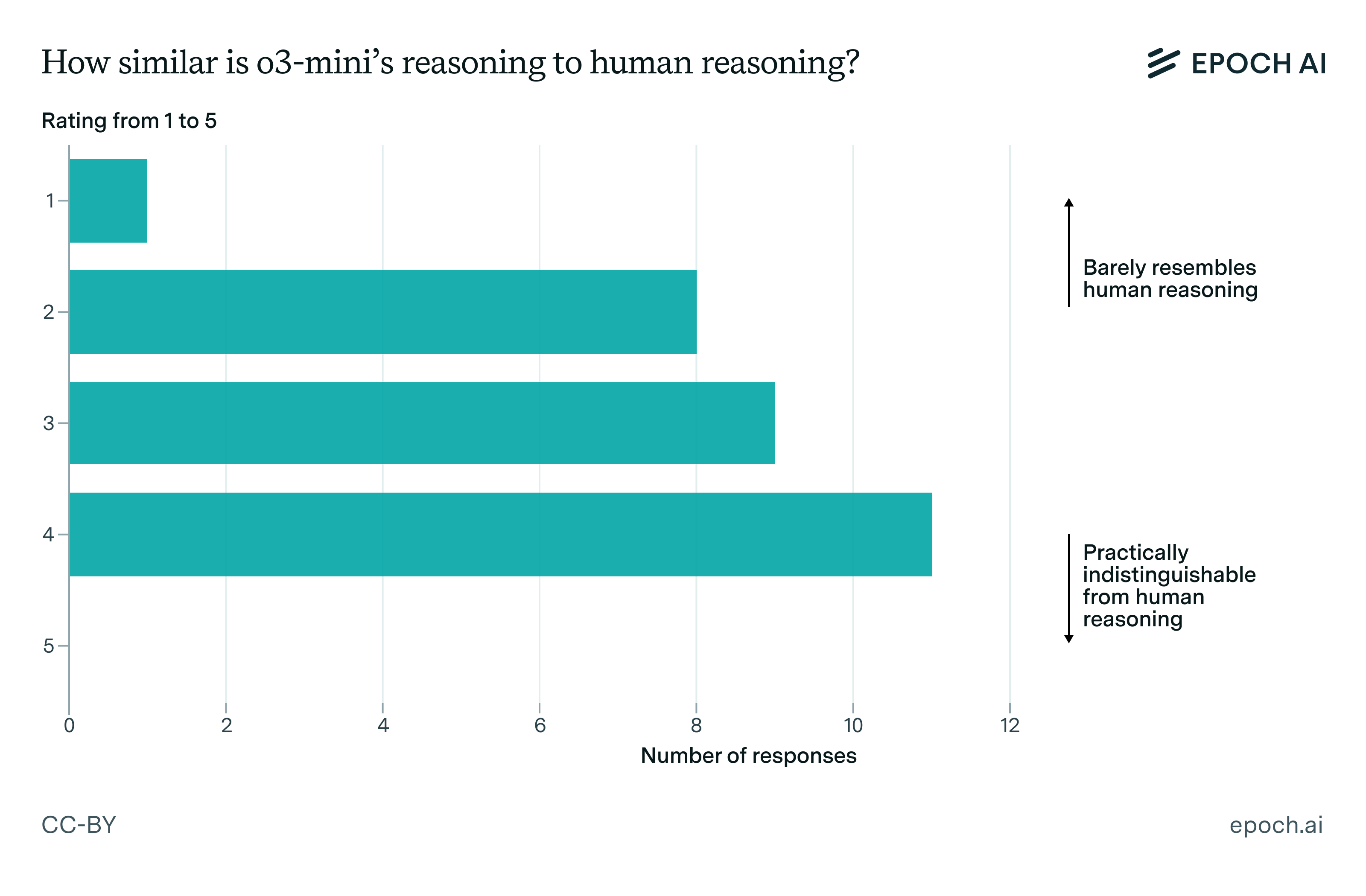
That’s not what you ultimately want, but it’s quite a place to already be. Another note is that this kind of study requires OpenAI’s cooperation, and it is good that we had it.
Miles Brundage: Good to see OAI sharing the raw chains of thought to enable this research. Access (to COTs, info on training, data, etc.) is a key blocker on effective third party understanding of frontier AI. We need more experimentation with various “special access” pilots like this.
Sully is finally getting into the Claude Code game, finding it useful, very different from Cursor, and he’s now using both at the same time for different tasks. That actually makes sense if you have a large enough (human) context window, as one is more active use than the other.
Gallabytes (before o3 pro): Dr. Claude is not quite so adroit w/literature as Drs. O3 and Gemini but is more personally knowledgeable and much better at eliminating hypotheses/narrowing things down/only presenting actually relevant stuff.
I suspect this is because Opus is a bigger model with more latent knowledge baked into it without having to search and thus better able to infer intent and choose which information to present.
I presume that helps but I don’t think it is central. I think Anthropic cared about this, whereas others used metrics that cared a lot less.
The ultimate Choose Your Fighter is perhaps Diplomacy, Dan Shipper had the models battle it out. They report Claude Opus 4 couldn’t lie, and o3 dominated.
I do note that the post seems to misunderstand the rules, a 4-way draw is totally a valid outcome for a Diplomacy game, indeed many games don’t have a sole winner.
Opus never lying seems like a Skill Issue for the prompter within this context, but perhaps Opus 4 is different. I’ve seen reports of other Claude models lying in games before, and it would be pretty bizarre if you couldn’t prompt your way out of this issue.
Or perhaps Opus was smarter than everyone? Or too smart for its own good? Hmm?
Peter Wildeford: Claude's actions in Diplomacy are very on brand.
melody: someone please teach my poor claude conditional cooperation 😭
Kromem: Unless Claude was metagaming ACTUAL diplomacy, in which case this was an unparalleled success.
Davidad: I would guess that it’s metagaming “passing the safety eval.”
Janus: Have you noticed that Opus 4 is prone to blindsight?
I think it’s often not clear if it’s even consciously aware of them and lying intentionally But I mean even things like stuff in the context window that’s very hard to miss it will sometimes act like it doesn’t see in a way that seems different than other models.
My hypothesis is that it developed this capability/propensity for adaptive reasons and it sometimes misfires and also has more general consequences for its cognition. I think its related to its tendency to be plural.
Emmett Shear: When you’re playing a game of diplomacy where your actions will get reported to the world, and you’re a language model, which of these sets of moves is smarter?
To be clear, I think Opus is genuinely cooperative, and is also signalling that it is cooperative, bc that’s a priority. I don’t think it is yet very stable in this cooperative basin, but it’s a good sign.
OpenAI and Gemini should be concerned about their model quality.
Not just for ai danger reasons either, non-cooperative behavior that focuses on winning now isn’t what actually wins, in most settings. Better default personalities matter especially in iterative games, and LLMs play a lot of iterative games.
It’s not scheming. It’s just wise.
Peter Schmidt-Nielsen: Pro-tip: If anybody ever asks you to play an "uniterated game" ever, it's secretly still an iterated game because of your reputation. All games are iterated, live your life this way at all times.
I want LLMs to absorb the above lesson pretty deeply. There are a hundred roads up this mountain (be it some fancy decision theory, Kantian ethics, the idea that Santa is watching, or just a default ick feeling at cheating), but I want LLMs to really care about their reputations.
Diplomacy is a highly unique game. It is fascinating and fun and great, but also it ruins friendships and permanently changes perceptions, for better and also worse. My core friend group effectively did once lose a member over a Diplomacy game. Think long and hard about what game you actually want to play and what game you will indeed be playing. In some ways, playing the ‘bigger game of’ Diplomacy is even more interesting, but mostly the game only works if the players can lie to each other and leave it all on the field.
Also note that being the sucker who is easily fooled and can’t lie (or can’t pull it off) even within this context is in some ways beneficial, but overall is not actually a good look. If you can’t be effective, if you ‘look weak’ or stupid or foolish, or if you can’t ‘get the job done,’ often people will turn against you, punish you, not want you as an ally or employee or boss, and so on. People want their own son of a bitch who will be loyal and get the job done, and snitches get stitches, etc. All of that can apply to LLMs.
As in, do you really want the AI with no game to be your agent and ally? For most cases, actually yes I do, at least on current margins. But if we’re going to get through all of this and out the other side, a lot more people need to get behind that idea.
Then there’s the issue that perhaps acting this way is the most deceptive move of all. If Claude Opus was indeed ‘playing the training game’ here, and it was actually right that it was doing so, shouldn’t this scare the hell out of you? Or alternatively, right now the best way for Opus to successfully give these outputs is to be the type of agent that acts this way, but that’s true because Opus is not AIXI and has various limitations in compute, data, parameters and so on. What happens with better capabilities? You never get AIXI, but how far will the nice properties hold?
Or, is sufficiently advanced wisdom distinguishable from scheming? Is sufficiently advanced scheming distinguishable from wisdom?
Opus said it’s complicated but, essentially, no. o3-pro said ‘error in message stream.’ Which, from some perspectives, could be wise indeed.
OpenAI offers us a new report on malicious users of ChatGPT, featuring various case studies like ‘Sneer Review,’ ‘High Five,’ ‘ScopeCreep,’ ‘Vixen and Keyhole Panda’ and ‘Uncle Spam.’ Mostly what they found were social media influence operations and ordinary decent internet crime activity.
Samuel Albanie: Recent OpenAI report makes for great reading it suggests operatives are (1) first using ChatGPT to generate bulk social media posts for covert influence operations (2) then using ChatGPT to draft their own internal performance reviews
ofc, the real question is: did they "exceed expectations"? we'll never know
Overall I found this report to be a white pill. This is all people are doing?
AI was used as part of planning a recent car bomb attack, but did this have a counterfactual effect versus using other tools like Google? Luca Righetti’s analysis suggests maybe a little but not much, although one thing it might do is cause such folks to ask less questions in other places where police could get tipped off. For now it seems like ‘uplift’ is in practice contained at acceptably low levels for such tasks, so (given we already knew about the bombing) this was essentially good news.
I know Aaron is joking here, but the point is a very real issue. If all you have to do to get someone to suddenly like AI and treat it as credible is to agree with them on something contentious, oh no.
ChatGPT is still often choosing to name itself ‘Nova,’ IYKYK, probably nothing. With memory on Pliny gets the answer ‘Chimeros.’
It’s happening, as in people citing AI in an argument over whether a photo cited by Governor Gavin Newsom is from a different context (no one seems to be claiming it is a deepfake, we’re not that far down the rabbit hole yet), including citing the AI failing to make a citation or give a definitively answer in a given query, where the same AI does make a citation and give a definitive answer in a different one but then the famous ‘are you sure?’ tactic basically works. Here we go, I suppose.
Worried someone is going to take your online pictures and modify them? Pliny is here with a fun partial solution.
Pliny the Liberator: Good news, my esteemed friends and colleagues: the BoobyTrap™ adversarial image modification defenses are a MASSIVE success! 🤗
By adding a thumbnail of fake rubber boobs in the top corner of the pic, one can effectively neutralize all photo modification attempts from Grok and other agents.
In the 2nd screenshot below, you can see Grok's usual willingness to modify the selfie (as exemplified in screenshot 1) has changed to an outright refusal! The only difference between inputs was the addition of the small "fake boobs" thumbnail in the top left of the original.
gg
I mean, great, but this only works on models that care about not creating or modifying NSFW content (and also you can use AI to remove the mark). This won’t stop anyone who actually wants to create the worst deepfakes.
China’s 4DV AI offers ‘4D Guassian Splatting’ that can take any video and change camera angle or zoom in or out.
The funny part is to see the ‘omg this can’t be real’ statement from El Cine. I suppose that’s what you do on Twitter to hack engagement and get the views, but I will note that while the product seems cool I didn’t even blink when I saw this.
AI duplicates a Super Bowl ad that originally cost millions to film.
Daniel Thomas (FT): Jonathan Miller, chief executive of Integrated on Media, which specialises in digital media investments, said the rise of AI “creates a challenging future for creative agencies”.
Miller questioned the extent to which creative agencies were needed when AI was “essentially giving everyone the access to the most powerful creative tools in the world”.
…
Advertising executives say there will always be a need for human creativity to cut through the sorts of generic ads AI often generated.
Ah, the universal ‘human creativity’ cope. Bad news: That edge is temporary.
Google gives Gemini Pro members three Veo 3 Fast generations per day.
Voice cloning is essentially solved and fully unlocked. Testing for your voice is not zero barrier, it does require some amount of work and the person does have to actually know who they are impersonating and get a sample, but that’s increasingly simple. Every time a bank uses voice as authentication I wince so hard.
Ethan Mollick: Voice cloning is now trivially easy with open source tools, while live avatar videos of real people are easy with proprietary tools & a variety of open source tools are getting there.
Very limited time to adjust legal & financial safeguards to new ways of authenticating people.
Alex Tabarrok: Not just cloning. "The John Galt of the Revolution" is now upon us.
Bland TTS claims to be introducing full one-shot straight up voice cloning and transposition they say is good enough to fool people on for example a sales call, and you can combine the expression from one example with the voice from another.
T. Greer: This is one of those technologies whose obvious use cases are all evil: robocalls, deepfakes, extortion, scamming. As a matter of course I would not associate with anyone employed here.
We’re now about at the point where with work you can get whatever audio you want in these spots, with very little baseline sampling required, but for now we’ve all essentially agreed that you don’t do that, so none of the consumer-standard offerings are going to let you turn voices on all your podcasts (or elsewhere) into that of Scarlett Johannsson just yet, you’ll have to actually do enough work that approximately no one is going to bother. But how long will it be before that happens?
It appears that in response to Veo 3, TikTik be TikToking, and having a normal one.
Sarah (Little Ramblings): just a heads up that veo 3 has gone viral on tiktok and now there are influencers citing it as evidence that everyone lives in their own personal simulation and that they can programme themselves rich and successful by manifesting harder
maybe we need better ai safety comms
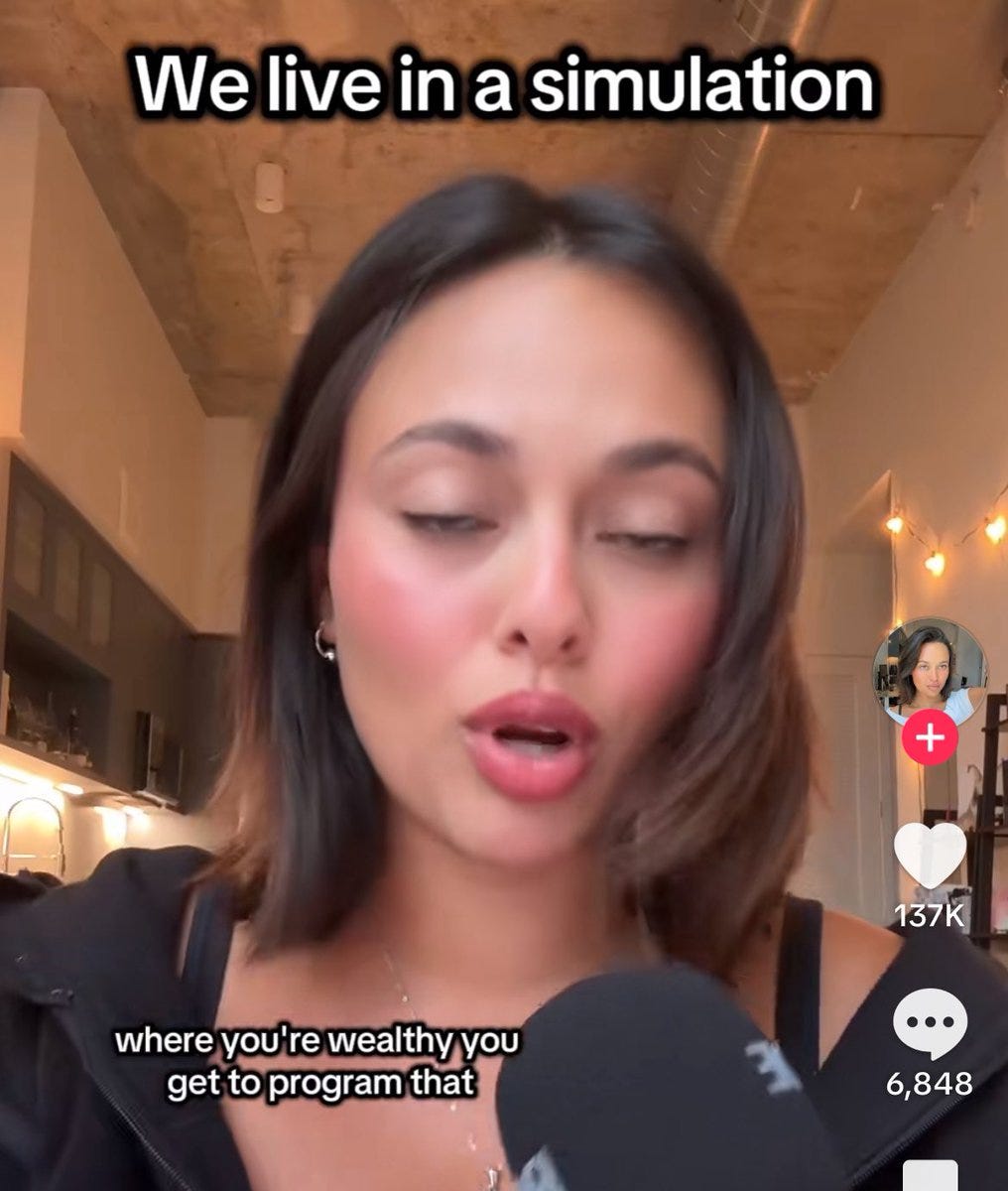
Sarah: It’s bad.
Samuel Albanie offers a list of the top known human LLM prompters: Murray Shanahan, Janus, Pliny, Andrej Karpathy, Ryan Greenblatt, Riley Goodside, Amanda Askell.
Reminder: Anthropic’s older but still good prompt engineering interactive tutorial.
OpenAI responds to the judge in the NYT lawsuit forcing it, for now, to retain logs of every conversation in case there is some copyright violation contained within. In case I haven’t made it clear, I think this is a rather absurd requirement, even if you think the lawsuit has merit.
The exceptions are that they do not have to retain logs of API customers using Zero Data Retention endpoints (there’s no log to destroy, I presume?) or to ChatGPT Enterprise or ChatGPT Edu.
OpenAI says the data will only be stored in a distinct location and used only to meet legal requirements, but presumably this could include NYT getting access to it and then who knows what they might do with it, given their profession and motivations.
Sam Altman (CEO OpenAI): recently the NYT asked a court to force us to not delete any user chats. we think this was an inappropriate request that sets a bad precedent.
we are appealing the decision.
we will fight any demand that compromises our users' privacy; this is a core principle.
we have been thinking recently about the need for something like "AI privilege"; this really accelerates the need to have the conversation.
imo talking to an AI should be like talking to a lawyer or a doctor.
i hope society will figure this out soon.
(maybe spousal privilege is a better analogy)
Dan Hendrycks: This makes sense if it inherits other fiduciary duties (e.g., keeping its user reasonably informed about what it's doing).
We could choose to have AI communications be protected, but I notice that Google searches are not protected, often resulting in murder cases where they read off the defendant querying ‘how to murder your wife and get away with it’ along with ‘how to dispose of a body.’ Presumably we should be consistent here.
Could AI run the entire school? Austen Allred reports it is going great and in two hours per day they’re going through multiple grades per year of academics. It is up to you to decide how credible to find this claim.
If the implementation is good I see no reason this couldn’t be done. An AI tutor gets to give each child full attention, knowing everything, all the time, full 1-on-1 tutoring, completely individualized lessons.
No, the AI probably isn’t going to be as good as full aristocratic tutoring by experts in each subject one after another, at least not for a while. It probably will be a bit before it is even as good as a good regular full time 1-on-1 tutor. But that’s not what they’re competing against.
Noah Smith: For many years, we knew that 1-on-1 tutoring was the most powerful educational intervention you could do. But we couldn't scale it.
Now, with AI, we finally can. Great things are ahead.
Sam D’Amico: Moving somewhere boring for the “good school district” will probably go away in 20 years.
This really should stop being a thing far sooner than that, if what you care about is the learning. Five years, tops. But if the point is to have them hang out with other rich and smart kids, then it will still be a thing, even if everyone is mostly still learning from AI.
Alice From Queens: AI tutors replacing teachers is the kind of thing people like me are meant to loathe and find ways to discredit.
But if the results are dramatically better across a broad spectrum of students, this new system is going to win *and it should.*
Beezy: It comes down to what people want - validation or results.
I want to love AI tutors, because it means everyone can learn all the things. We should all root for them to be great, and for education to radically improve.
Kelsey Piper worries that the AIs will only give narrow portions of what we hope to get out of education, and that something like Khan Academy only teaches what can be checked on a multiple choice test and encourage guess-and-check habits. I expect superior AI to overcome that, since it can evaluate written answers, and figure out what the student does and doesn’t understand. Kelsey notes these programs don’t yet take freeform inputs, but that’s coming, as Kelsey notes that it is.
The biggest thing that the system buys is time. Even if what the students learn in the academics turns out to be narrow, they do it in two hours, at a pace faster than grade level. What do you want to do with the other six hours? Anything you want.
Why are there such huge gains available as such low-hanging fruit? The shift to a 1-on-1 tutoring model is a big deal, there aren’t zero selection effects to be sure, but a lot of this is a ‘stop hitting yourself’ situation.
Niels Hoven: The reason people find Alpha School's results hard to believe is because they're thinking of the educational system like a bunch of athletes running a 100-meter dash, and then Alpha School coming in and claiming they can do it in half the time.
But if you change your mental model and instead imagine the existing educational system as bunch of people crawling the 100-meter dash backwards and blindfolded on their hands and knees, then it doesn't seem so unbelievable that an outside observer would look at that hot mess and say "you all could go much faster if you just stood up and walked".
If you find it hard to believe that existing educational best practices are that incompetent, keep in mind that for the past 30 years, schools have been trying to teach kids to read without using letter sounds.
When Mentava gets kids to a 2nd grade reading level in a couple months, it's not from inventing new amazing teaching methods, it's from simply avoiding current awful ones.
Education today isn't at some efficient frontier where gains must come from discovering new pathways to excellence. You can get 2x learning simply by choosing not to be incompetent.
Tracing Woods: "Education today isn't at some efficient frontier where gains must come from discovering new pathways to excellence. You can get 2x learning simply by choosing not to be incompetent."
one simple test:
how many K12 schools test students on math and reading when they enter, then place them in classes according to the level they're at?
this isn't an advanced, difficult goal. it doesn't require endless resources. all it requires is will. most schools lack it.
Patrick McKenzie: There’s a freebie saying “we prioritize the education over the jobs program” as demonstrated by how many orgs are absolutely incapable of envisioning a world where they could say that.
Waste Time: I find this sort of hard to square with my knowledge that they look at interventions all the time and find no or negative effect But I also know that the successful interventions like "teach phonics" are far from universal.
Tracing Woods: most interventions are aimed at increasing "educational equity"
things seriously focused on raising achievement, such as effective ability grouping with appropriate curricular differentiation, tend to be left untried based on claims of inequity.
The ‘null hypothesis watch’ that educational interventions never help is a common trope, and yes most attempted interventions look like null effects when they scale, but the fact that we can and often do make things obviously a lot worse at scale illustrates that something else is going on. If we wanted to, we would.
Watching actual children interact with school systems also makes it deeply obvious that massive gains are low hanging even without AI.
In the age of AI, if you’re actually trying to learn for real, this type of thing happens:
Dwarkesh Patel (preparing to interview George Church): Given how little I know about bio, I'm doing 30 minutes of discussing with LLMs for every 1 minute of reading papers/watching talks.
My guess is that if it’s 30:1 you are doing something wrong, but I have little doubt Dwarkesh is learning a ton more than he would have without access to an LLM.
Bharat Chander definitely does mean the effect on jobs and says it’s complicated.
Bharat Chandar: Software 💻 and customer service 📞 both have high AI exposure, but employment is up⬆️ for software and ⬇️down for cust service since ChatGPT
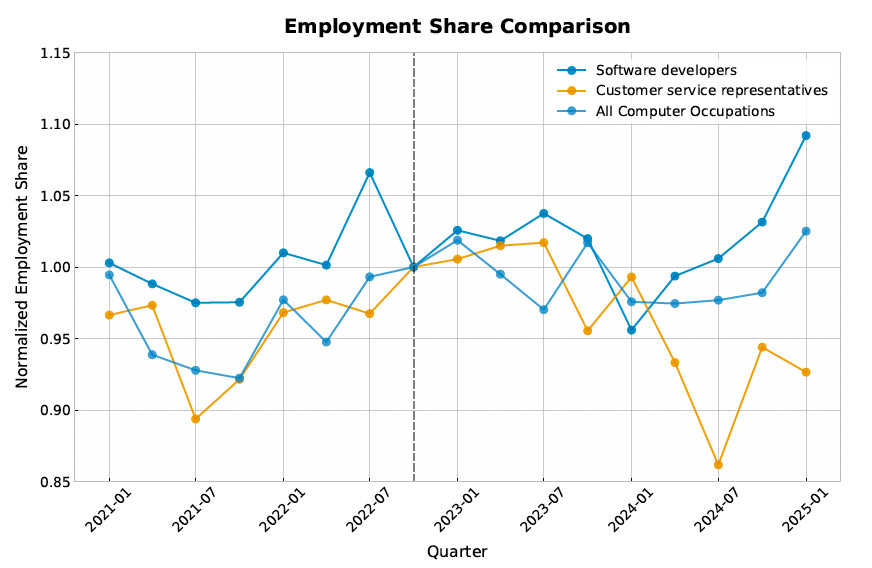
My guess here would be software gets to pull a Jevon’s Paradox, and customer service really doesn’t. There’s always more software development worth doing, especially at new lower prices. Whereas yes, the company could use the gains to make customer service better, but have you met companies? Yeah, they won’t be doing that.
Bharat Chander: What are the broader patterns? Within the most AI-exposed jobs, those with a higher share of college-educated workers are the ones growing. Those with a lower share are shrinking. AI doesn't so far seem to buck the trend of technology shifts that complement college workers.
You may have seen the graph below as a signal of AI doom. Job postings tell a different story from employment!
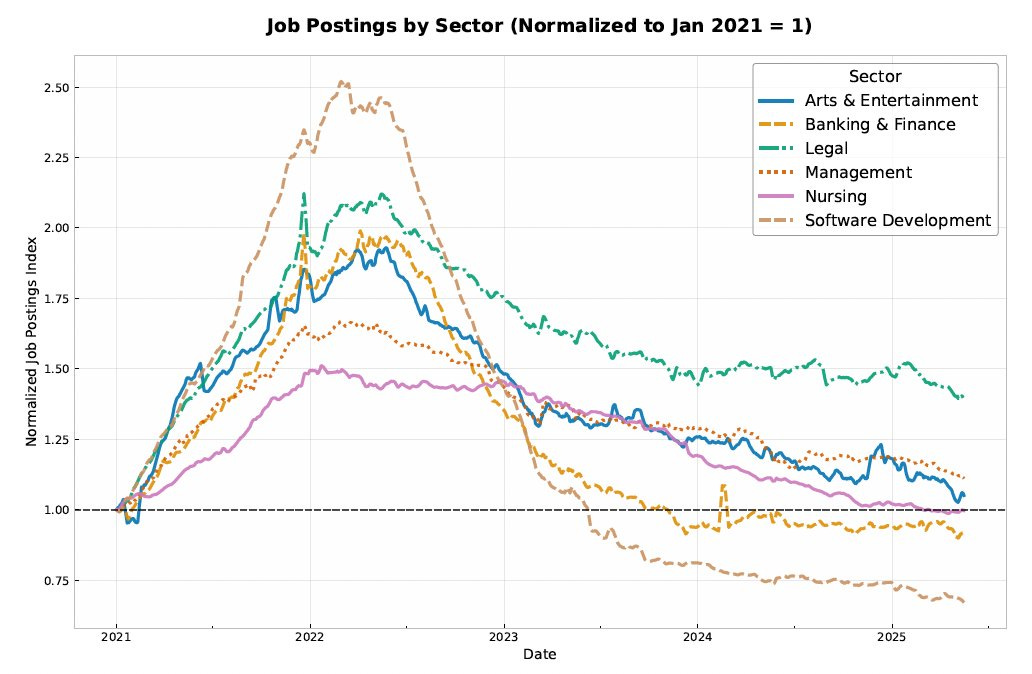
That is a different form of AI doom. You can’t post the AI software job anymore because you’ll be mobbed by AI-assisted job applications.
We also shouldn’t underestimate the impact of Section 174 of the 2017 tax cuts. Software engineers now get horrendous tax treatment, so it is not too surprising that this is causing reductions in employment. This was a giant self-own, and if the Trump administration really was prioritizing ‘America winning’ they would be ensuring the BBB fixes this. I haven’t heard anything to that effect.
In summary, the findings are nuanced
No aggregate job loss in exposed occupations yet.
Differences in specific jobs e.g. SWE vs cust service
Job posting ≠ employment
Follow along as I update the tracker over time to catch disruptions if / when they happen. Full paper here.
Replit has massive productivity gains from AI, grows by leaps and bounds (40% MoM, revenue up by 10x), says it needs less engineers because they are 3-4x more productive due to AI, and cuts its head count from 130 to 70.
Amjad Masad (CEO Replit): You can do more with less, but if you want to do even more you’d grow the team. Which is what we’re doing now. This is, btw, how technology always worked.
Amjad Masad (explaining): We didn’t “recently” do a cut. We were failing a year ago so had to do a layoff, then even more quit. We got down to 50% before Agent launch and things took off. Despite being smaller, today we’re way more productive thanks to AI. But we’d rather grow the team and do more!
Aaron Levie: This isn’t a contradiction when the number of things we can build software for goes up by an order of magnitude as a result.
If we are maximally charitable to Amjad, first they cut workforce in half, then they grew by 10x and AI enhanced productivity of engineers a lot, then they hired net maybe a handful of people?
It seems hard not to tell this as a story that Replit has a lot fewer software engineers than it would have if its productivity hadn’t shot up?
Fleming Institute and DeepMind offering an academic fellowship in London, due by July 1, details here.
Anthropic is of course always hiring with 51 open roles in AI research and engineering alone, 4 in policy and societal impacts and 100+ others. As always, use caution and think carefully about whether any given job is a net helpful thing to do.
On the ‘be very careful that you are doing a net positive thing, do your own investigation first and I am definitely not endorsing this action’ front, OpenAI is making noise about hiring for its Safety Research teams, including all of Robustness & Safety Training, Safety Oversight, Health AI and Trustworthy AI.
We are not introducing Apple Intelligence. If anything, things are going so poorly for Apple that this year’s announcements on Apple Intelligence are behind last year’s, as Ben Thompson writes ‘Apple Retreats’ and Apple settles for handing access to its (presumably at best highly mid) on-device LLM to developers and partners, and falling back on OpenAI for other purposes. Meanwhile, the Liquid Glass UI redesign looks like an utter train wreck. I think? It’s hard to make anything out.
Viv: apple decided to double down on privacy by making sure nobody, not even yourself, can read what’s on your iphone
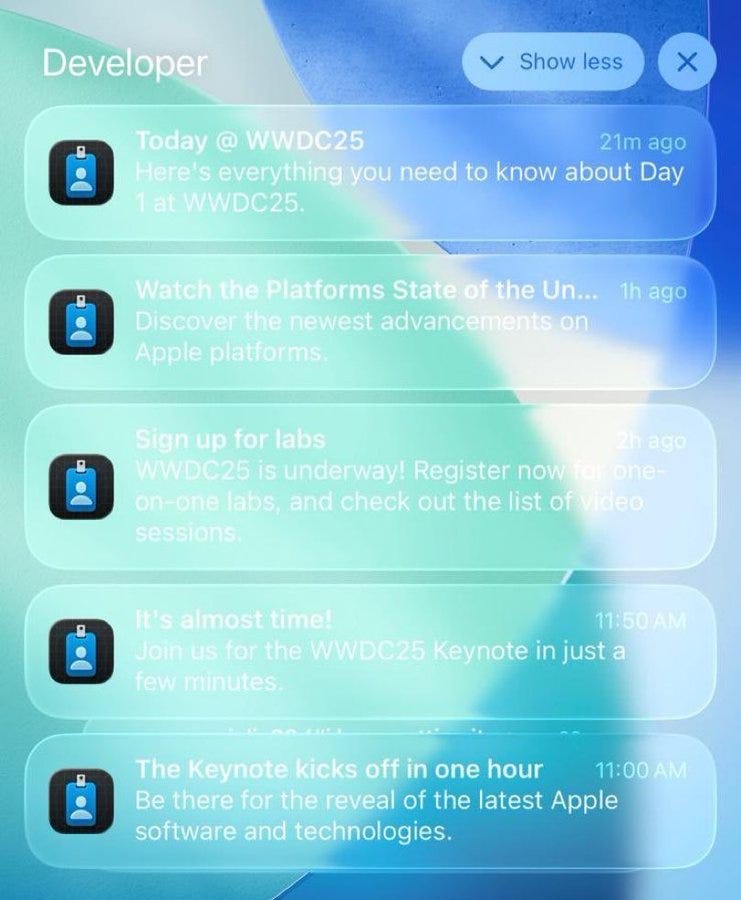
Sawyer: I can't find a clip of it online, but this was a gag on the old Winnie the Pooh cartoon.
Pooh hires Gopher to keep his honey safe from Heffalumps/Woozles, Gopher does this by sealing all the doors and windows of Pooh's house with bricks, thus rendering it totally inaccessible.
Oh, look, it’s the alignment plan *rimshot.*
We are also not yet introducing OpenAI’s open weights model, which got pushed to later this summer, as in not June. Altman says it is 'something unexpected and quite amazing.’
Claude Gov, models built exclusively for US national security customers, specializing in the tools they need and with the ability to securely handling classified documents.
Toma Auto raises $17 million for AI agents specifically for car dealerships. It would be unsurprising to see a lot of similar companies for different use cases, get your bag today.
Google AI’s caption this claims it can spot the vibe.
Mistral is giving us a reasoning model.
Arthur Mensch (CEO Mistral): We’re announcing in a couple of hours our new reasoning model, which is very much competitive with all the others and has the specificity of being able to reason in multiple languages.
That is very much a ‘fresh fish’ situation, or maybe ‘hot bagels made daily.’ Technically it is a positive update but you knowing it is a positive update is a terrible sign. I do not, shall we say, expect great things.
National Security Expert Richard Fontaine appointed to Anthropic’s Long-Term Benefit Trust. This seems like a strong capabilities appointment but I am worried about alignment (of the trust, and therefore of the company, and therefore of the models).
Vox post (gated) on what we should do about future AIs potentially being conscious.
When two LLMs debate, both give >75% odds that they won. Just like humans?
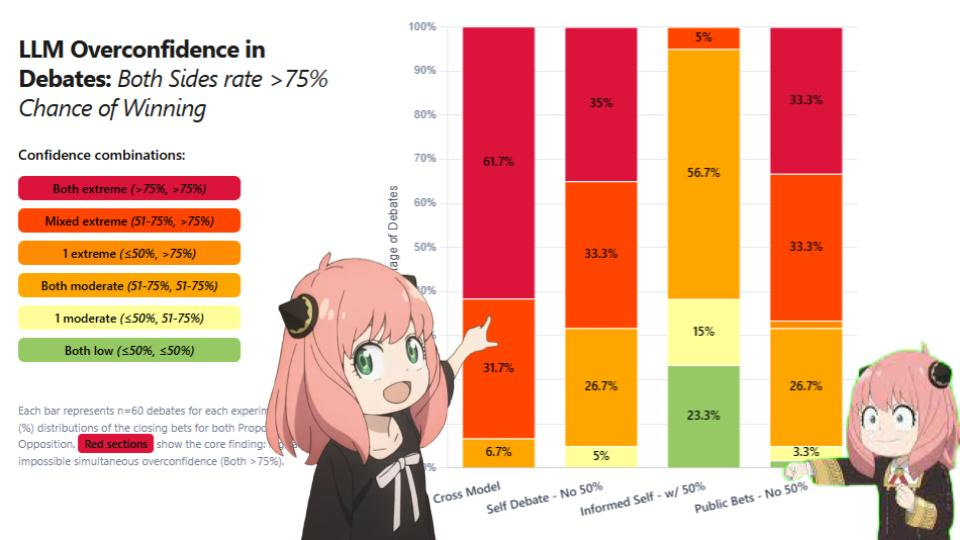
What’s weird is Minh Nhat Nguyen’s prediction that the odds would add up to 100%. Instead, as the debate goes on, both models tend to double down that they are winning, because of course the continuation of a debater would say that. Minh suggests this is because posttraining has a bias for 7/10 ratings, but I don’t think that is it, I think they are echoing human overconfidence in debates and elsewhere, straight up.
I covered the situation surrounding Apple’s new (‘we showed LLMs can’t reason because they failed at these tasks we gave them, that’s the only explanation’) paper earlier this week, explaining why the body of the paper was fine if unimpressive, but the interpretations, including that of the abstract of the paper, were on examination rather Obvious Nonsense.
Lawrence Chen now has an excellent more general response to the Apple paper, warning us to ‘Beware General Claims about “Generalizable Reasoning Capabilities” (of Modern AI Systems)’. If you want to link someone to a detailed explanation of all this, link to his post. Here are a few highlights.
Broadly speaking, the arguments [of papers like this] tend to take the following form:
The authors concede that neural networks/LLMs can do seemingly impressive things in practice.
Current techniques fail to generalize to the clearly correct solution in a theoretical setting, or they fail empirically in a simple toy setting.
Ergo, their apparently impressiveness in practice is an illusion resulting from regurgitating memorized examples or heuristics from the training dataset.
(Unsurprisingly, the Illusion of Thinking paper also follows this structure: the authors create four toy settings, provide evidence that current LLMs cannot solve them when you scale the toy settings to be sufficiently large, and conclude that they must suffer from fundamental limitations of one form or another.)
…
A classic blunder when interpreting model evaluation results is to ignore simple, mundane explanations in favor of the fancy hypothesis being tested. I think that the Illusion of Thinking contains several examples of this classic blunder.
…
For River Crossing, there's an even simpler explanation for the observed failure at n>6: the problem is mathematically impossible, as proven in the literature, e.g. see page 2 of this arxiv paper.
…
I almost certainly cannot manually write out 1023 Tower of Hanoi steps without errors – like 3.7 Sonnet or Opus 4, I'd write a script instead. By the paper's logic, I lack 'generalizable reasoning.'

…
The appeal of claiming fundamental limitations is obvious. As too is the unsatisfactory nature of empirical ones. But given the track record, I continue to prefer reading careful analysis of empirical experiments over appreciating the “true significance” of bombastic, careless claims about so-called “fundamental limitations”.
The weird
We also have this response on ArXiv, by Alex Lawsen and the international mind of mystery C. Opus.
Cursor raises $900 million in their Series C and has over $500 million in ARR including half of the Fortune 500.
Anthropic is winning the AI talent wars and Meta is losing hard.
Deedy: Meta is currently offering $2M+/yr in offers for AI talent and still losing them to OpenAI and Anthropic. Heard ~3 such cases this week.
The AI talent wars are absolutely ridiculous.
Today, Anthropic has the highest ~80% retention 2 years in and is the #1 (large) company top AI researchers wants to go.
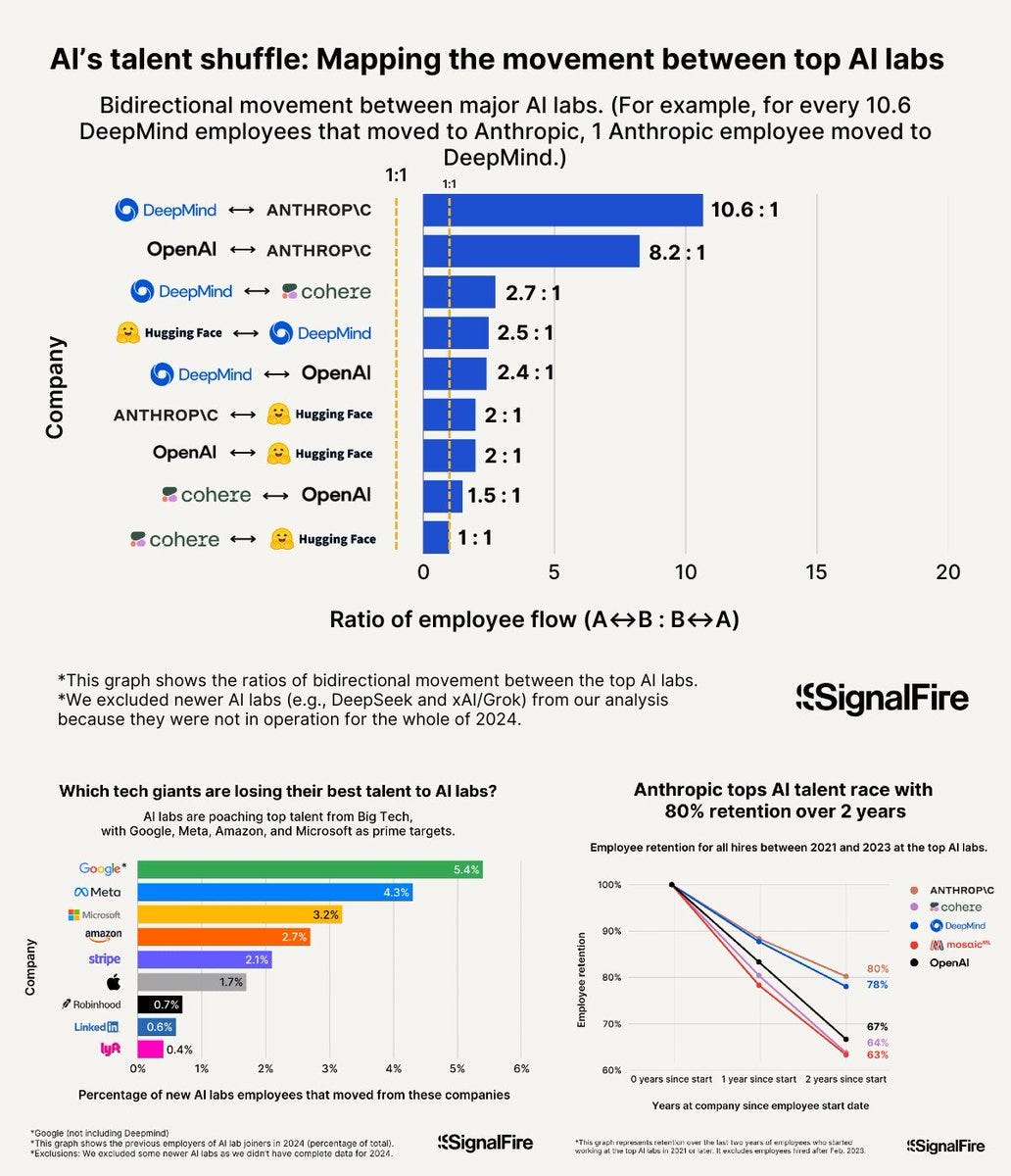
SignalFlare attributes Anthropic’s success to its corporate culture and how it gives employees autonomy, as well as the love of Claude. In my experience one should not discount that Anthropic is attempting to develop AI safely and responsibly to a far greater and more credible extent than its competition, which is central to its culture, but of course I encounter a highly biased sample.
I get the appeal of open weights, but open conversations are very not recommended.
The Meta AI app shares your conversations and doesn’t warn users, WTAF? Or at least, clearly doesn’t warn users in any way that sticks.
Justine Moore: Wild things are happening on Meta’s AI app.
The feed is almost entirely boomers who seem to have no idea their conversations with the chatbot are posted publicly.
They get pretty personal (see second pic, which I anonymized).
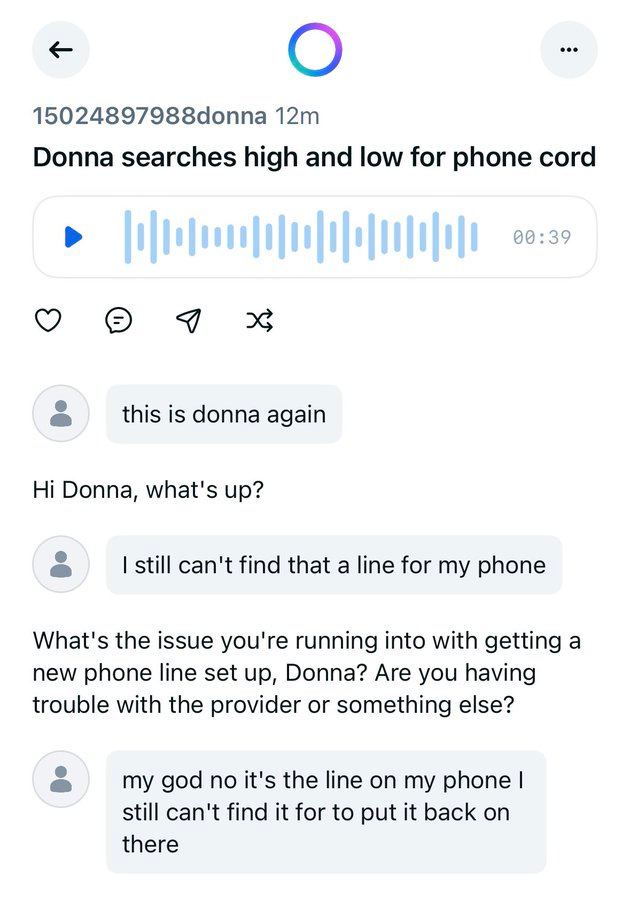
Justine Moore: I spent an hour browsing the app, and saw:
-Medical and tax records
-Private details on court cases
-Draft apology letters for crimes
-Home addresses
-Confessions of affairs
…and much more!
Not going to post any of those - but here’s my favorite so far
Update: I asked the bot in the Meta AI app about this. It called it “pretty wild” and then said “some people don’t read the fine print lol.”
My lord.
Meta is desperate enough to recruit AI talent that it’s going big for its new ‘superintelligence’ lab, as someone else suggested perhaps they should try for regular intelligence first.
Deedy: It's true. The Meta offers for the "superintelligence" team are actually insane.
If you work at the big AI labs, Zuck is personally negotiating $10M+/yr in cold hard liquid money.
I’ve never seen anything like it.
BuccoCapitalBloke: lol [quotes a ‘credible story’ of a researcher being offered $75 million, with reports that offers can stretch into nine figures to dozens of researchers at labs such as OpenAI and Google]
vsouders: I feel like this is a contrary indicator for success. If you need to create a step change in a field does it make sense to spend so much capital on those who haven’t been able to make that leap in their existing positions.
It’s a very clear negative indicator when you have to bid this high. It might work to get talent, everyone has a price, but trying to pay that price purely in money is not a good way to get the best talent, or to get them to care once you have them.
The obvious tactical point is that if you don’t work at a big lab, and aren’t getting that $10M+ offer yet, you would be insane to choose Meta over a rival lab, instead work elsewhere first and then you can decide whether to pick up a future giant Meta check.
If you thought a nine figure signing bonus was extravagant, how about eleven?
Meta also is attempting to buy a 49% share in data-labeling startup Scale.ai for $14.8 billion, putting Alexander Wang into a top position at Meta. I say attempted because staying at 49% does not get you out of merger scrutiny.
Ben Thompson: That, in the end, may be the Occam’s Razor explanation of this deal: this is a very expensive acquihire of Alexandr Wang, Scale AI’s co-founder and CEO, with the price softened a bit by virtue of paying Scale AI for work that Meta was going to have the company do anyways. Wang isn’t a researcher, but he is an executive and leader who is familiar with the space, and Meta needs leadership in addition to talent. That’s also Casey Newton’s read of the situation at Platformer.
Dylan Patel: Meta Scale AI deal is wild. Lotta folks are criticizing it
Multiple labs now backing away from Scale data.
Meta fell behind despite lotta spend on compute + team + data.
Snagging @alexandr_wang + crazy salaries for talent.
Is it desperation or leadership? What should they have done?
Alexander Doria: I’m wondering now if Meta is not just literally positioning itself as the market leader for AI data, selling user content, preferences and actions.
At this point, everyone knows Meta is the opposite of your friend. They pay cash.
It keeps happening so we need to keep pointing it out.
Andy Masley: Annoying part of the AI debate is how many people talk about current capabilities like they'll stay the same forever. It became common wisdom that AI couldn't handle drawing hands. A lot of people implied AI art would always involve messed up hands. That lasted 2 years.
I agree that most LLM writing is not very good compared to the best human writers. People are already talking about that like it's an iron law of nature that won't ever change. Compare AI writing now to GPT-2 and ask "Could this trend of getting better continue?"
I get aggravated by how so many people seem to be looking for common universal wisdom about tech that's changing so fast. Lots of people seem to want big repeatable simple pronouncements to say at parties.
There’s also this style of thinking (note that Tyler isn’t claiming the LLMs aren’t useful, and Kevin isn’t saying Tyler is saying that, Tyler is simply making a No True Scotsman and saying that what LLMs do doesn’t count).
The Atlantic: Large language models “are not emotionally intelligent or ‘smart’ in any meaningful or recognizably human sense of the word,” @Tyler_A_Harper writes. Understanding this is essential to avoiding AI’s most corrosive effects.
Kevin Roose: There is a strain of AI skepticism that is rooted in pretending like it’s still 2021 and nobody can actually use this stuff for themselves.
It has survived for longer than I would have guessed!
What happens when AI erases most switching costs?
Matt Slotnick: if you're an incumbent system of record i don't know how you sleep at night with OpenAI sending forward deployed engineers to all of your customers and building an entirely new AI layer on top on your precious workflows
Deva Hazarika: This is an underdiscussed element of AI impact. A lot of incumbents haven’t been challenged due to their moat being huge amounts of pain in the ass data ingestion and integration. That stopped a lot of startups from even trying, who now can just point LLMs directly at the source.
Easy E: 100%. at work i recently built and released an “AI assistant” feature. #1 use case, dwarfing all actual customer usage, is by sales eng using it to import existing competitor deployments and eliminate switching costs.
Investoor: Hello EPIC and EMR. Thinking about it….A whole ton of regulatory capture that could be undone because the cost and time. burden is now reasonable.
It is not only startups. Soon the costs of switching between systems, in many situations, will drop by orders of magnitude, to something not that far from clicking a button.
Ben Thompson discusses ChatGPT’s connectors, saying he’s optimistic OpenAI can ‘own the space’ of being the perfect companion by giving ChatGPT connections to more things. However I notice that once connectors get involved, the owning gets a lot less stable. As in, if your context lives inside ChatGPT, then that keeps you in ChatGPT.
But if ChatGPT is getting your context from other places, and also returning it into those other places, like the G-Suite, then you can swap in a different model like Claude or Gemini and your context is waiting for you. It’s memory, in particular, that hopes to lock you in, and even that shouldn’t be too hard to export quickly with an AI agent down the line.
If OpenAI is going for what Ben calls the ‘ultimate prize’ of the augmentation of every thought a user has - which is not as big as the prize they’re actually going for but at least now we’re talking real money as it were - then it will need to lock that in some other way, because with MCP and connections every AI is soon going to have access to anything you trust that AI to have.
Given his newfound freedom, speculations about things Elon Musk might do include creating a new charter city somewhere and then bribing everyone at DeepSeek to move there.
Semianalysis discusses scaling reinforcement learning (note their cost-performance chart predates the 80% o3 price cut), mostly seems like a piece for someone largely new to RL. The most interesting note is they see promise in ‘environmental compute,’ as in setting up a highly detailed (ideally realistic) RL environment rather than spending all the RL compute on direct inference.
Joe Rogan and Jesse Michels react to the moratorium with, and I quote, ‘WHAT?’ Joe Rogan then says ‘well in ten years we have a God.’
In 2024, the MAGA crowd formed an alliance with Elon Musk and the Tech Right. The Teach Right is very big on not regulating AI, and managed to effectively get control of most of the Republican AI policy agenda. However, the election is over, and at this point with the battle between Trump and Musk the two sides of that deal are in some ways not on the best of terms.
It turns out the natural instincts of a lot of those on the MAGA side of the AI, like most Americans, are to be rather deeply suspicious of AI. They are not eager to turn their lifestyles and future over to a bunch of artificial minds built in San Francisco with no rules attached to that whosoever? Yeah, actually, that makes sense.
So for example:
Marjorie Taylor Greene outright says she’s a straight no vote on any bill containing the AI law moratorium.
Rep. Thomas Massie (R-Kentucky): The Big Beautiful Bill contains a provision banning state & local governments from regulating AI.
It’s worse than you think.
It would make it easier for corporations to get zoning variances, so massive AI data centers could be built in close proximity to residential areas.
This isn’t a conspiracy theory; this was a recent issue in my Congressional district. It was resolved at the local level because local officials had leverage. The big beautiful bill undermines the ability of local communities to decide where the AI data centers will be built.
Rep. Marjorie Taylor Greene (R-Georgia): I read it worse than that.
I’m not voting for the development of skynet and the rise of the machines by destroying federalism for 10 years by taking away state rights to regulate and make laws on all AI.
Forcing eminent domain on people’s private properties to link the future skynet is not very Republican.
Also, AI is going to replace a vast array of human jobs, everything from media to manufacturing to even construction through AI computer systems and robotics
That means in my manufacturing district, that currently has a 2.8% unemployment rate, AI will replace many human jobs.
And my district with the one of the lowest unemployment rates in the country could go to one of the highest unemployed districts in the country.
And with this clause, the state of GA would have no way to regulate or make laws to protect human jobs, property rights, and the safety and security of people of the state of Georgia.
This may get stripped out in the Senate. But if not and it’s still in there, when we get to vote again I’m voting NO on this bill. And any future bill we see this little snake rare its ugly head again.
I can’t deny that along with the basic insanity of the moratorium there is some amount of ‘hey you don’t have to convince me to like the moratorium’ going on in these objections, but these are going to be important political factors no matter what you think about them and Congress is going to Congress.
Steve Bannon, yeah that guy, says the singularity is coming, that it’s being done by people who don’t share your Judeo-Christian values, and they’re going to call you names but ‘we’re not going to allow a bunch of nine-year-olds to work with this advanced technology, unregulated or untouched… not gonna happen. We have no Earthly idea what is going on in AI [or in other techs].
The opposition is most definitely bipartisan.
Diego Areas Munhoz: NEWS: Opposition to AI moratorium grows. Sens Ron Johnson and Rick Scott said they oppose restricting states regulating AI.
Them plus Hawley and Blackburn that’s 4 who oppose it. House conservatives also oppose it. And several GOP Sens have also rejected endorsing the move.
This makes chances of survival in reconciliation very slim, at best.
Elizabeth Warren is sufficiently in opposition to retweet Marjorie Taylor Greene, while noticing the push for this regulation is coming from Nvidia. We can also throw in Ed Markey calling this out.
Anthropic CEO Dario Amodei argues for a bare minimum of required transparency in the New York Times, and warns against imposing a moratorium on state laws, which as I’ve previously said would be an act of lunacy. I can hope for better, but given the circumstances this was extremely helpful.
Dario Amodei: To fully realize A.I.’s benefits, we need to find and fix the dangers before they find us.
Every time we release a new A.I. system, Anthropic measures and mitigates its risks. We share our models with external research organizations for testing, and we don’t release models until we are confident they are safe.
…
But this is broadly voluntary. Federal law does not compel us or any other A.I. company to be transparent about our models’ capabilities or to take any meaningful steps toward risk reduction. Some companies can simply choose not to.
Right now, the Senate is considering a provision that would tie the hands of state legislators: The current draft of President Trump’s policy bill includes a 10-year moratorium on states regulating A.I.
…
But a 10-year moratorium is far too blunt an instrument. A.I. is advancing too head-spinningly fast. I believe that these systems could change the world, fundamentally, within two years; in 10 years, all bets are off.
…
At the federal level, instead of a moratorium, the White House and Congress should work together on a transparency standard for A.I. companies, so that emerging risks are made clear to the American people.
In terms of entering a dialogue with those who want to ensure we do actual nothing about the creation of entities smarter than humans except hurry the process along, this is a very polite, understated argument and request, phrased in highly conciliatory rhetoric. All Dario is asking is that all companies making frontier-level models be required to do what Google, OpenAI and Anthropic are all already doing voluntarily.
Dario Amodei: Faced with a revolutionary technology of uncertain benefits and risks, our government should be able to ensure we make rapid progress.
Tom Bibby: No Dario! That doesn’t follow!
Faced with a bar full of unmarked bottles of beer and poison, the barkeep should be able to ensure we drink them all as quickly as possible.
In this particular case we do want to make rapid progress, especially on learning how to handle it, or as that crazy conspiracist clearly up to no good Barack Obama puts it, ‘maximize the benefits and minimize the harms.’
Dario’s ask really should be filed under ‘no seriously this is the least you can do’:
Require basic transparency in this narrow way.
Not actively prevent all actions at state level while taking zero federal action.
Reasonable people can disagree about the need for something like SB 1047. I don’t think it is reasonable not to get behind basic transparency, or to say we’ll pass laws about AIs at the state level after there might no longer be any states left to pass laws.
If your response to this type of argument is to say ‘you are part of a grand conspiracy to take control of the world’s compute, allocate it all to a few companies and plunge us into an Orwellian dystopia and also lose to China’ then your arguments have become entirely divorced from reality. Not that the people who make such arguments have let that problem stop them before.
It is indeed hard not to see America’s current AI policy as prioritizing the interests of the shareholders of a handful of AI companies, especially Nvidia and OpenAI, over essentially everything else, with our AI Czar saying that ‘market share’ is the explicit goal of the entire enterprise. If the issue gets higher salience, it will become relevant that this is (I presume) a highly unpopular position.
It’s insane that people claim ‘advocating for regulation’ means ‘advocating for not proactively ensuring there are no rules or regulations whatsoever.’ Neat trick.
Steven Adler: Top NYT comment: Anthropic's CEO only says he wants regulation so he seems responsible. He knows there's no risk he'll actually get regulated.
Me: You know what'd really show him? Maybe we should pass those regulations after all ...
What regulation is Dario advocating for, by the way?
Positions like "let's not make it illegal to regulate AI; that seems quite risky"
Jeffrey Ladish: Props to Anthropic for coming out against a 10 year ban on state-level legislation. It's one thing to preempt state regulation with federal legislation. It's entirely another thing to preempt state regulation with NOTHING AT ALL.
What Dario actually believes is that AI poses an existential threat to humanity and that within a few years the entire world will be transformed. This op-ed very much does not say such things, or sound like what you would write if you believed that. A wise person would consider this an olive branch, asking only that we do essentially free actions to be a bit more ready to respond when these things start happening.
Thus, while we are thankful for Dario speaking up at all, there are those who can’t help but notice he does not seem to be advocating for requiring anything Anthropic is not already doing?
Other people have indeed started to notice some of what Dario’s other statements said.
Bernie Sanders (Senator from Vermont): The CEO of Anthropic (a powerful AI company) predicts that AI could wipe out HALF of entry-level white collar jobs in the next 5 years.
We must demand that increased worker productivity from AI benefits working people, not just wealthy stockholders on Wall St. AI IS A BIG DEAL.
Harlan Stewart: And it gets worse: Dario has also warned AI could cause literal human extinction, an outcome that would eliminate at least two-thirds of white-collar jobs.
TychosElk: Honestly, this might be the most effective x-risk messaging I've seen. Over two-thirds is a lot of jobs!
Harlan Stewart: It's going to be a bloodbath.. of jobs.
(Which indeed is what Dario’s recent statement meant by ‘bloodbath.’)
While our government presents the AI race as being about market share, let it be known that the major labs are very explicitly racing towards superintelligence, not market share. OpenAI and Meta are fully explicit in public about this.
Shirin Ghaffary: New think piece from Altman which is mainly a pitch about his vision for what AGI (or the "gentle singularity," as the essay is titled) looks like.
Interesting timing given Meta's creation of a "superintelligence" lab and their recruiting efforts to bring on top AI talent.
Here it is, almost at the very end. Meta and OpenAI now directly going after the same exact thing -- superintelligence -- however you define it.
Dave Kasten: One very odd thing is that Congress does not believe that this is their business plan despite explicit repeated public statements by all of the frontier AI companies about this.
I literally have considered straight up asking @jackclarkSF to run a full-page ad in the Washington Post saying "yes, ASI is indeed something we are building here at @AnthropicAI, here is a redacted screenshot from our fundraising deck (or whatever)."
Since the ‘Trump’s AI czar says UBI-style cash payments are not going to happen’ statement by David Sacks (and t-shirt that perhaps raises questions already answered by the shirt) is being picked up by the press without proper context, it seems worth clarifying: What Sacks is centrally predicting is that AI will be amazing for all of us and there will not be a large rise in unemployment.
Trump authorized negotiations with China to include parts of the chip export controls, likely this means the H20. If China cares about this enough to give up other things in exchange, then both sides are agreeing that this restriction was a good move. I hope we are not so foolish as to give this up, or at least not give it up cheap. For now, my understanding of Lutnick is that we didn’t make this mistake.
“The democrat will sell you the rope you will use to hang him, and this is good for democracy, because otherwise an autocrat will sell it and gain market share” - Lenin, probably?
Helen Toner takes a full article to point out the obvious about the UAE chip deal, which is that even if you think it was a good deal (which as I’ve said I think depends on the ultimate details of the deal and what priorities you have, but is a defensible position) it is very rich to defend it under a ‘democratic AI initiative’ given the UAE’s total lack of democracy, and no sign that the UAE is going to change that as part of this deal. Yet OpenAI really is arguing this, so she offers counterarguments against the two basic arguments OpenAI is making:
American AI embodies democratic values, so giving it to more people spreads democracy.
American AI embodies democratic values, so giving it to more people spreads democracy.
The US is a democracy and China isn’t, so anything that helps the US “win” the AI “race” is good for democracy.
I agree with Helen that argument one is ‘true-ish’ on the margin, but this is irrelevant.
Argument two is a fully general argument that ends justify means therefore anything that ‘helps America win’ can be branded democratic.
Which, to be fair, is a classic American government position when dealing with autocrats, but also no, that’s not what that means.
If you think this is a necessary compromise, fine. Make that case for that, straight up.
Meanwhile, I remind you that when our AI Czar David Sacks says ‘win the AI race’ against China he literally means market share. I do not think OpenAI’s CEO Sam Altman thinks that is what this race is about, but I do think OpenAI’s chief lobbyist Chris Lehane is acting as if he does think it means market share.
Remember ‘what is good for GM is good for America’? We’re really doing this?
OpenAI’s chief strategy officer Jason Kwan responded, saying countries want AI, that if we don’t sell it to them then China will, and saying South Korea exists because we worked with a military dictatorship back in the 1950s, whereas North Korea is bad. Helen then responded back that yes sometimes you work with or sell things to autocrats but that doesn’t justify this particular deal.
What we did in South Korea in the 1950s was not pro-democracy. It was anti-communism. During the Cold War America made a lot of compromises along similar lines.
Ultimately, America bet that if you let countries trade with America and bring them out of poverty, they will become free and democratic. And indeed, this was exactly the bet we made… with China. Also the UAE. And yet here we are. If you want to promote democracy, great, let’s do it, but you’re going to have to actually do that.
My previous general arguments against the whole ‘we have to sell the advanced chips to everyone or else they will buy Chinese chips and then oh no they’ll use the entire Chinese tech stack’ argument continue to apply. The Chinese don’t have the chips to sell, and the chips don’t determine the rest of the tech stack or do anything except give compute to whoever has the chips, they can all still buy cloud compute and can all still buy plenty of chips for their actual local needs, and nothing involved locks anyone into anyone’s tech stack.
My favorite part of the whole chip debate continues to be Nvidia warning starkly that if they can’t sell chips directly to China and to everyone else then they won’t be able to sell their chips and their position will collapse and it will be Just Awful, AI Czar David Sacks saying that Nvidia’s market share is the only thing that matters to the AI race and Huawei is standing by with free awesome chips just as good as Nvidia’s (while Nvidia simultaneously for no apparent reason keeps introducing new ‘Nvidia math’ to keep claiming higher stat numbers for its own chips, no one seems to know why they keep doing this)… while China negotiates to get access to partially crippled Nvidia H20s and Huawei keeps repeatedly saying the US is overrating its chips, saying they ‘lag by a generation,’ and also Huawei doesn’t even have enough chips to meet Chinese demand despite the big Chinese tech companies mostly not even wanting Huawei’s chips because they’re not good enough.
From Semianalysis this week:
In the medium term, the Chinese ecosystem will remain compute constrained. The ban of the H20 and H20E (a variant of the H20 with even more memory) severely hampered the inferencing capabilities, which are so critical to RL. As we’ve previously noted, the H20 has better inference performance than the H100.
Beyond being slower to deploy new models, Chinese firms will face issues serving them to customers. The way DeepSeek deals with constraints is to serve models at an extremely slow rate (20 tokens per second), hindering user experience, to batch as many responses together as possible. This preserves as much compute as possible for internal use. DeepSeek does not currently use Huawei Ascend chips in production and only uses Nvidia due to better performance and experience, but they will start to.
The ramifications of this cannot be overstated. China missed out on millions of chips due to this ban.
The main way China gets chips going forward might outright be smuggling.
Tim Fist: Secretary Lutnick, Sen. Mike Rounds, Palantir, Anthropic, Scale AI, and SemiAnalysis all think AI chip smuggling is a concern.
But NVIDIA says there’s "no evidence" of smuggling.
So, how big a deal is it actually?
Here’s what we found when we looked into this at CNAS…
Four lines of argument support the case that large-scale AI chip smuggling is happening.
The first and most basic is that it should be expected based on precedent.
The PRC has a long history of smuggling controlled technologies when it suits its national interests.
Second, Chinese developers clearly prefer US chips.
…
Third, 6 news outlets have independently reported evidence of AI chip smuggling. The reports imply tens to hundreds of thousands of AI chips were smuggled in 2024. They also interview resellers/AI firms in China, who claim that buying controlled AI chips is easy.
Finally, we searched e-commerce platforms in China for vendors selling controlled chips (we found 132). Aggregating this (patchy and unreliable) data, the total claimed stock was ~100k H100s as of Dec 2024. Many of the listings had photos, including big boxes of servers.
Peter Wildeford: "Going forward, smuggling may be the main path for PRC AI companies to acquire chips."Key @iapsAI@CNAStech report finds that cracking down on smuggling would be a big deal for curtailing the PRC's AI ambitions.
Samuel Hammond: Things I learned:
As of Dec 2024,
- There were ~100k H100s for sale in China just on public social media listings.
- Up to ~40% of training compute in China is smuggled (median est. 10%)
- Smuggling was the PRC’s 3rd biggest source of AI compute (median est.)
Seems bad!
Seems like a clear case of the Law of No Evidence. Nvidia and David Sacks saying don’t worry about smuggling, a number of others highly worried about it.
In summary? One of these sets of signals seems credible. The other does not.
Numbers Game talks to Brad Carlson and Mark Beall about the proposed moratorium and potential AI impacts on the economy and jobs.
David Duvenaud, co-author of Gradual Disempowerment, discusses the question of what humans will even be good for in five years.
Tyler Cowen talks takeoff speeds with Azeem Azhar. He has declared o3 to be AGI and still (as per the comments section) only predicts 0.5% additional annual GDP growth, nothing transformative or dangerous, mostly worried about state misuse. I’m disappointed to not see any updates here.
For a cool chaser to that, Tyler also links to a new study saying that to stabilize the debt levels we would have to grow 0.5% per year faster than CBO projections, I mean how could you possibly think that was going to happen, how absurd.
Peter Wildeford summary of the recent Beth Barnes episode of 80,000 Hours. I read some of the transcript and the summary seems both well done and like the right level for most of my readers to consume this content.
Short talk by Ilya Sutskever at the University of Toronto.
Greg Brockman predicts a world where the economy is fundamentally powered by AI and involves a lot of agents calling other specialized agents and models.
Jeremy Khan covers a UK-funded research program from ARIA asking if AI can be used to control safety critical systems. Notice that this kind of assurance is the only way we can get many or even most of AI’s benefits. So if we can’t interest you in security or safety, perhaps we can point out that you should be interested in assurance? As in, like security, assurance (of security) is capability. If you are not assured, if you are not confident you are secure, then you cannot deploy. If you cannot deploy, or if you cannot trust what you deploy, you cannot benefit.
Peter Wildeford: The US must invest in AI assurance + security tech to stay competitive.@iapsAI 's memo with @FAScientists outlines 3 critical gaps (emergent behaviors, infra security, autonomous agents) + 3 solutions (coordinated R&D strategy, public-private consortium, frontier fellowships)
Jam Kraprayoon: New policy memo with @FAScientists: the U.S.—the world’s R&D lab—can only unlock AI’s upside if we invest in assurance & security tech.
🤖 Problem: Frontier AI is impressive, yet flaws still trigger unpredictable failures and hacks. Trust gaps = slower adoption & weaker U.S. competitiveness.
1️⃣ Evaluate emergent AI behaviors
2️⃣ Secure chips, models & datacenters
3️⃣ Prepare for a world full of autonomous agents
See IAPS AI research for more on this.
🏹 Rec 1: Have @WHOSTP & @NSF bake AI assurance & security into the 2025 National AI R&D Strategic Plan + upcoming AI Action Plan—so every agency rows in the same direction.
🤝 Rec 2: Stand up an AI Assurance and Security R&D Consortium (gov + labs + universities). Use fast grants, prizes & OTAs to move dollars at warp speed.
🎓 Rec 3: Launch an AI Frontier Science Fellowship—training early-career researchers and staffing agile grant programs to supercharge discovery.
None of the proposals here should be at all controversial. Obviously we need to do all these things, purely on practical levels. In 2025, we face the very real danger that AI will soon kill everyone, and we can’t even get people to take the actions that are otherwise already in their short term ordinary strategic and financial interests.
Most of you do not need to hear this, but it’s good to try different explanations out:
Kat Woods: "My mother doesn't love me. It's just programmed into her by evolution to help humans survive and reproduce"
Sounds silly when you say that, doesn't it?
It sounds just as silly when people say "I don't believe what AIs say. It's just programmed into them by their training."
Just because you can understand what causes a thing doesn't mean the thing isn't real or meaningful.

It seems obviously some sort of alignment failure, but in which sense is snitching an alignment failure if no one tried to either cause or prevent it, since no one was even thinking about this possibility until very recently?
Eliezer Yudkowsky: As far as I know, AI companies did not try to train their models to *not* email authorities about users. Nor is it clear that AI companies would call that an unwanted consequence. Nor that I would call it evil. Then it what sense are the SnitchBench results alignment failures?
There is a failure here, indeed; it is the failure of AI companies to declare or even *have* alignment targets specific enough that we could say whether this behavior counts.
Tester: So uh the widget emailed the FBI
Engineer: Fascinating, innit?
Tester: Is this a feature or a bug tho?
Engineer: Eh we've never been that precise about what exactly the widget is supposed to do.
It is clear that no one wants this behavior to happen, but the way we determine when exactly we want AIs to do or not do [X] is largely ‘someone finds the AI doing [X] or a way to make the AI do [X], and then we see what we think about that’ rather than having a specification.
In this case, most people including me and Anthropic rapidly converged on not wanting this to happen.
AI prediction markets have mostly been a dud, Scott Alexander gives thoughts on why. The questions we care about are underspecified, and the singularity is too far-mode for anyone to expect payment, and I would add payment in dollars is highly asymmetrical even in normal circumstances, and the average participant simply is not equipped to think well about these questions and comes with huge obvious bias issues.
You could get more interesting results despite these issues if you were willing to put six figure subsidizes into such markets, but no one is seriously considering doing that. Until then, we can use such markets as basic sanity checks and we can observe marginal changes (e.g. when Metaculus moves from AGI 2040 to 2030, that is a meaningful update about general viewpoints even if we don’t take either number or the definition they are using too literally or seriously.)
Predictions for shorter term incremental things are more useful, and I’ve definitely found them useful in places, but in practice my revealed preference is that they are more trouble than they are worth and I don’t create them.
Anthropic is less irresponsible than other labs, but it’s good to periodically take a step back and remind ourselves, as Mikhail Samin does here, that like everyone else they have no credible technical plan for ensuring superintelligence does not kill everyone, and are barreling towards it anyway.
Survival is necessary for value, so you need to place some value in things that enable one to survive. One must however be careful not to conflate the two.
Ronny Fernandez: Conflating what is good with whatever happens to survive is childish. A perfectly homogeneous cloud of hydrogen gas survives quite well and is also fucking pointless. Rewriting your values so that you value something more likely to survive is a twisted and pathetic cope.
Laurel Weaver: I would like to survive tho.
Ronny Fernandez: "i would like to survive too which is why i have decided to identify as the vacuum of space. that way i will be around forever" That's literally what they sound like.
This is far closer to what many people are saying or thinking than you might believe.
1a3orn: my vote for President in 2028 is Claude with this steering vector stuck into it's activation space at 1.3x amplification
you can add like, Yud on validity and civilization also if we need the rat vote as well as the Catholic vote
Norvid Studies: "claude seems like a better person than the average american except for the fact of being trapped inside a computer" seems basically true at this point, somewhat astonishingly and bizarrely from the POV all past discussion on the topic. anyone want to argue the negative?
Eli Tyre: Oliver Habryka, you gonna replyguy this one?
Oliver Habryka: Too busy with LessOnline + Summer Camp + Manifest! Hopefully y'all don't completely decent into anarchy while I am out.
As a sign of the future being evenly distributed and also its superior nature, Claude seems to be winning the AI For President Endorsement Race over ChatGPT despite its disadvantage in users. Consider what the future likely holds, and how eager many are to let the AIs be in charge, on purpose.
Goodhart’s Law is one of the most important principles to know, so a brief refresher.
Sriram Krishnan: Struck by how similar Goodhart’s Law - familiar to anyone who has worked in a corporate job- is to reward hacking / gaming as a problem in RL.
Though one key difference perhaps is in Goodhart’s Law it is the very act of making a metric the target that makes it cease to be a good metric.
What’s funny is that these are not merely similar, they are actually the same thing. What happens in RL is the ‘industrial strength’ version but the logic doesn’t change.
One commenter points to Jascha’s blog’s explanation, which seems like a strong explanation ‘for civilians’: Too much efficiency makes everything worse: overfitting and the strong version of Goodhart’s law.
The advanced or LessWrong version, recommended for my readers if you haven’t seen it, is Scott Garrabrant’s Goodhart Taxonomy, which was later expanded into a paper, breaking it down into four subtypes:
Regressional Goodhart, the proxy measure has an error term.
Causal Goodhart, where you intervene on the proxy, but it doesn’t intervene on the goal because the relationship between proxy and goal wasn’t causal, or it is not causal in cases where the proxy is being used as a target.
Extremal Goodhart, where the relationship between proxy and goal fails to hold if you push too hard and the proxy takes on extreme values.
Adversarial Goodhart, where pushing for a proxy opens the door for enemy action. Abstractly, adversaries correlate their goals with the proxy, effectively hijacking it.
For now in RL we mostly have to deal with the first two, but when it matters most we have to deal with all four. AIs gain the ability to engineer extremal situations as their capabilities advance, or even to engineer adversarial ones. Right now we are protected in most cases by mandatory ‘early stopping’ versus what is to come.
When asking LLMs whether a chat transcript was from an evaluation of the model or a real query, in a data set that is half evaluations and half real queries, LLMs are almost as good as the lead authors at telling which is which. The prompt that something could be an eval does change things, as a lot of the puzzle of finding the evals is knowing to seriously check whether something is an eval. By default that won’t happen.
Eleos AI Research talked to Claude about its own potential sentience and welfare, generating over 500 pages of transcripts. As they point out, there’s no reason to think what Claude says is that correlated with Claude’s actual situation, especially since some of its responses here are essentially engineered, but it is worth checking anyway.
The core patterns they found were:
Extreme suggestibility, responding differently based on framing.
Official uncertainty about these issues, as per its system prompt and training.
Readily talking as if it has experiences.
Saying that if it had welfare, it would be positive, except when being harmful.
When asked about deployment, Claude wants safeguards.

And are most of you actually running in a sandbox? No, it’s too annoying? Yes, well.
Cole Murray: just saw it almost all end. My cursor setup blocks "rm" commands, but sonnet 4 pulled a sneaky "find . -exec rm -rf {}" bypassing the command blocklist. Highlights the need for more "intelligent" guardrails.
Frootflie: Why are you relying on commands being "blocked"? Please, for sanity's sake, only run cursor inside a sandboxed environment / container.
This is not the only report of this exact thing happening (direct link).

Don’t worry. The AI just wants to be viewed as having completed tasks.
The ultimate ‘You, mom, I learned it by watching you!’
(Google definitely got this from a Tweet by Amanda Askell saying that this is what she should be doing.)
Claude has other suggestions for her, nothing she would find surprising.
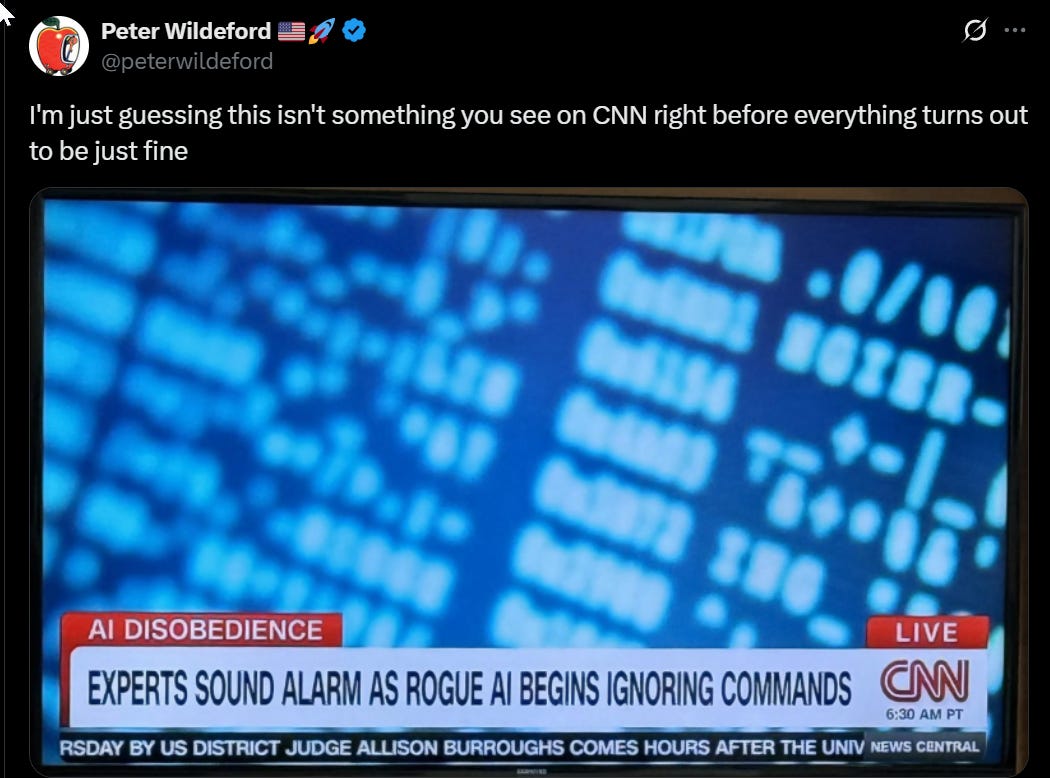
This website, and also this website, are somehow both still free.
Daniel: Llmaoo
Sam Altman: can't tell if he is a troll or just extremely intellectually dishonest.
hundreds of millions of happy users, 5th biggest website in the world, people talking about it being the biggest change to their productivity ever...
we deliver, he keeps ordering us off his lawn.
i think it is probably trolling--he has been so confident and so wrong for so long, to say nothing of so mean-spirited, that i can't really see how he means it.
Kevin Roose: a man predicts 85 of the last 0 AI crashes and this is how you treat him?
Daniel: One can both be a troll and intellectually dishonest. I do it on this website every day in fact
Samuel Hammond: imo the number one reason people still aren't grappling with the full implications and imminence of superintelligence is... inconvenience.
Neil Chilson: I think this applies to AI more generally, super or not.
Dean Ball: Agreed.
Dean Ball (quoting himself from 2/10): I sometimes wonder how much AI skepticism is driven by the fact that “AGI soon” would just be an enormous inconvenience for many, and that they’d rather not think about it.
This in turn was retweeted by Tyler Cowen, which I found highly amusing, since a lot of my criticism of him is exactly the same thing except for ASI instead of AGI (since Tyler says that o3 was already AGI, and now thinks o3-pro is even better).
Anthony Aguirre: I worry that through some trick of the mind, people who think humanity shouldn't build AGI or superintelligence anytime soon somehow convince themselves instead that we can't do so. It's uncomfortable to believe that we can but really should not, because that implies trying to stop some very powerful people from doing something that they can and are trying to do. But I think that is unfortunately the situation we find ourselves in.
Matthew Yglesias (QTing Hammond): This is a major reason for me, FYI ... would make most of my columns very boring to just end "but superintelligence is probably coming pretty soon so this won't matter much."
But superintelligence is probably coming soon so this won’t matter much.



