AI Agent Evaluation: The Definitive Guide to Testing AI Agents
3 weeks ago
3
AI agents are complicated — Agents calling tools, tools invoking agents, agents as a swarms of agents, and swarms of agents calling on other swarms of agents. It sounds confusing just typing it out.
“AI agents” is a broad term that refers to many things nowadays. It may refer to single-turn autonomous agents that run in the background similar to cron jobs, multi-turn conversational agents that resembles RAG-based chatbots, as well as voice AI agents that are also conversational agent but with a voice component to it. Oh and, don’t forget AI agents that belong to a larger agentic AI system.
Unfortunately, AI agents also have a lot more surface area to go wrong:
Faulty tool calls —
invoking the wrong tool, passing invalid parameters, or misinterpreting tool outputs.
Infinite loops
— agents get stuck repeatedly re-planning or retrying the same step without convergence.
False task completion
— claiming a step or goal is complete when no real progress or side effect occurred.
Instruction drift
— gradually deviating from the original user intent as intermediate reasoning accumulates.
That’s why evaluating AI agents is so difficult — there’s an infinite number of possible AI agentic systems, each with more than a dozen of ways to fail.
But here comes the good news: AI agent evaluation doesn’t have to be so hard, especially when you have a solid agentic testing strategy in place.
In this article, I’ll go through:
What AI agents are, and the most common types of agentic failures
How to evaluate any types of AI agentic system, including top metrics, setting up LLM tracing, and testing methods for single and multi-turn use cases
Top misconceptions in evaluating agentic systems, and how to avoid common pitfalls
How to automate everything to under 30 lines of code via
Ready to spend the next 15 minutes becoming an expert in AI agent evaluation? Let’s begin.
TL;DR
AI agents can be classified in single-turn and multi-turn agents, each requiring different metrics for evaluation
The main end-to-end metric for both single and multi-turn agents centers around the idea of task completion, which is whether an AI agent is able to truthfully complete a task given the tools it has access to
AI agent evaluation can also be evaluated on the component-level, where it concerns aspects such as whether the LLM is able to call the correct tools with the correct parameters, and whether handoff to other agents was correct
Evaluating agents mainly involves running evals in an ad-hoc manner, but for more sophisticated development workflows users can consider curating a golden dataset for benchmarking different agents
Top common metrics involve task completion, argument correctness, turn relevancy, and more
DeepEval (open-source) along with Confident AI allows you to run evals on agents efficiently without worrying about the infrastructure overhead on metrics implementation, AI observability, and more.
What are AI Agents and AI Agent Evaluation?
AI agents refers to large language model (LLM) systems that uses external tools (such as APIs) to perform actions in order to complete the task at hand. Agents work by using an LLMs' reasoning ability to determine which tools/actions an agentic system should perform, and continuing this process until a certain goal is met.
Single-turn AI agent with tools and ability to handoff to other agents
Let’s take a trip planner agent for example, which has access to a web search tool, calendar tool, and an LLM to perform the reasoning. A simplistic algorithm for this agent might be:
Prompt the user to see where they’d like to go, then
Prompt the user to see how long their trip will be, then
Call “web search” to find the latest events in {location}, for the given {time_range}, then
Call “book calendar” to finalize the schedule in the user’s calendar
Here comes the rhetorical question: Can you guess where things can go wrong above?
A Multi-Turn Trip Planner Agent
There are a few areas which this agentic system can fail miserably:
The LLM can pass the wrong parameters (location/time range) into the “web search” tool
The “web search” tool might be incorrectly implemented itself, and return faulty results
The “book calendar” tool might be called with incorrect input parameters, particular around the format the start and end date parameters should be in
The AI agent might loop infinitely while asking the user for information
The AI agent might claim to have searched the web or scheduled something in the user’s calendar even when it haven’t
The process of identifying points of which your AI agent can fail and testing for them is known as AI agent evaluation. More formally, AI agent evaluation is the process of using LLM metrics to evaluate AI systems that leverages an LLMs's reasoning ability to call the correct tools in order to complete certain tasks.
In the following sections, we will go over all of the common modes of failure within an agentic system. But first, we have to understand the difference between single vs multi-turn agentic systems.
Single vs multi-turn agents
The only difference between a single-turn AI agent and a multi-turn one is the number of end-to-end interactions between an agent and the user before a task is able to complete. Let me explain.
In the trip planner example above, it is a multi-turn agent because it has to interact with a user twice before it is able to plan a trip (once asking for the user’s destination, and the other asking for the user’s date of vacation). Had this interaction been through a Google Form instead, where the user would just submit a form of the required info, it would deem this agent single-turn (example diagram in a later section).
When evaluating single-turn agents, as we’ll learn later, we first have to identify which components in your agentic system are worth evaluating, before placing LLM-as-a-judge metrics at those components for evaluation.
Single-Turn LLM-as-a-Judge
When evaluating multi-turn agents, we simply have to leverage LLM-as-a-judge metrics that evaluate task completion based on the entire turn history, while evaluating individual tool call for each single-turn interaction as usual.
Multi-Turn LLM-as-a-Judge
You might be wondering, but what if the agentic system is one that communicates with another swarm of agents? In this case, the agents aren’t necessarily interacting with the “user”, but instead with other agents, so does this still constitute as a multi-turn use case?
The answer is no: This isn’t a multi-turn agent.
Here’s the rule of thumb: Only count the number of end-to-end interactions it takes for a task to complete. I stress end-to-end because it automatically excludes internal “interactions” such as calling on other agents or swarms of agents. In fact, agents calling on other agents internally are known as component-level interactions.
With this in mind, let’s talk about where and how AI agents can fail on an end-to-end and component level.
Confident AI: The DeepEval LLM Evaluation Platform
The leading platform to evaluate and test LLM applications on the cloud, native to DeepEval.
Regression test and evaluate LLM apps.
Easily A|B test prompts and models.
Edit and manage datasets on the cloud.
LLM observability with online evals.
Publicly sharable testing reports.
Automated human feedback collection.
Where AI Agents Fail
AI agents can failure either on the end-to-end level or component-level. On the end-to-end level things are more straightforward — if your AI agent isn’t able to complete the task, it has failed.
End-to-end failure
Component-level failure
Failed to complete task/meet demand of user
Could be anything from tools not called, to model APIs erroring
Stuck in infinite loop of reasoning
More prominent with newer reasoning models
Calling tools with incorrect parameters
A common problem with LLMs extracting parameters
Faulty handoffs to other agents
Usually happens when LLMs can't reason correctly
Tools not used but LLM claims it was called
A classic LLM hallucination problem
On a component-level however is where things become more difficult to evaluate. You have to first trace out the agent’s entire execution structure, decide on the most critical components that are responsible for your agent’s end-to-end success, and design metrics that are suited for those cases.
In summary, AI agents can fail on an end-to-end level, where:
Both single and multi-turn use cases the AI agent has failed to complete the task at hand, or
Agents are stuck in an infinite loop of “thinking”/“reasoning”
Agents can also fail on the component-level, where:
Tools are called with the incorrect parameters
Tool outputs are not utilized correctly
Agent handoff to other agents are wrong
LLM claims that it called a tool when it hasn’t
With this in mind, we now need to understand how to keep track of every execution within your agentic system so we can apply the appropriate metrics for the different components you’re trying to evaluate.
How AI Agent Evaluation Works
There are 3 critical steps in AI agent evaluation pipeline:
Keep track of components and interactions you wish to evaluate
Place the correct metrics at the correct areas of which you wish to evaluate
Actually log the data flowing in and out of different components during runtime for evaluation
In laymen terms, this means that if you wish to evaluate a certain tool call in your AI agent because you suspect it’s messing up your agent’s task completion rate, you should apply metrics to the LLM that is calling the tool as well as keeping track of the tool to determine whether the tool has actually been called.
The process of logging your AI agent’s execution flow can be best carried out via LLM tracing.
Setup LLM tracing
LLM tracing is a great way to keep tabs on what your AI agent does during runtime. It is basically traditional software observability but adopted for AI systems. There are tons of tools out there for LLM tracing, but I recommend Confident AI (seriously not biased). It is a hybrid LLM tracing platform where we combine AI observability with DeepEval powered evals as a natural extension.
from deepeval.tracing import observe
from deepeval.metrics import TaskCompletionMetric
@observe(metrics=[TaskCompletionMetric()])defai_agent(query:str)->str:return client.chat.completions.create(model="gpt-4o", messages=[{"role":"user","content": query}]).choices[0].message.content
# Call app to send trace to Confident AI
llm_app("Write me a poem.")
(For typescript users, go to docs for more examples)
Since DeepEval is native to Confident AI, when you run this piece of code, you will be able to see entire agentic traces on Confident AI immediately (note diagram below does not correlate directly to code block above):
Tracing on Confident AI
The top-most row in the diagram is known as a “trace”, where it contains the end-to-end execution information of your AI agent. Each row below the trace is known as a span, representing individual components in your agent.
Now what we have to do, is to apply the correct metrics at the correct places in our agent.
(Note that if you don’t want to adopt a cloud solution, using DeepEval alone would suffice for evaluation, Confident AI simply provides an additional layer of UI on top of it.)
Applying metrics
Continuing from the previous single-turn agentic RAG use case, we can now place metrics to assess the argument correctness and task completion of our AI agent. Using DeepEval, all it takes is supplying a metrics argument in the observe decorator of our trace. In fact, we actually already included such an example in the previous code block.
Conceptually, what happens is we're created "test cases" at runtime in order for our metrics to run evals on it:
Metrics Applied on a Span (component) Level
The argument correctness and task completion metric are common agentic metrics which I’ll be covering in a later section, but other notable ones include RAG metrics such as contextual relevancy which you can place on the retriever component, while answer relevancy is an extremely popular metric to be placed on the generator component.
The metrics in the example above are all reference-less metrics, meaning they don’t require labelled expected outputs. For those curious, I’ve already written a full story on everything you need to know about LLM evaluation metrics here.
Construct test cases
Sometimes, your trace structure might not be exactly what you want to be feeding into your metric for evaluation. Case in point: You might only want to include a certain keyword argument as the input to your metric instead.
If this is the case, you might want to set your test case arguments explicitly:
from deepeval.tracing import observe, update_current_trace
from deepeval.metrics import TaskCompletionMetric
@observe(metrics=[TaskCompletionMetric()])defai_agent(query:str)->str:
res = client.chat.completions.create(model="gpt-4o", messages=[{"role":"user","content": query}]).choices[0].message.content
update_current_trace(input=query, output=res)return res
# Call app to send trace to Confident AI
llm_app("Write me a poem.")
In this example, we’ve modified our tracing logic to update the trace’s input at runtime. In DeepEval, all test case parameters are inferred from the trace implicitly unless overwritten (docs here). The important note here is, whatever agentic eval system you have in place, you ought to make sure your metrics are receiving the correct information for evaluation.
Curate a dataset
What you’ve seen so far in this section involves running agents “on-the-fly”, where evaluations are ad-hoc and serves as a performance tracker over time rather than benchmarking.
This is optional (although highly recommended), but if you’d like to benchmark two different versions of your agentic systems, running an experiment with a dataset is the best way. It standardizes the set of tasks your agent has to complete, and determines which agent performs better based on the final metrics you get.
A dataset consist of goldens that will be used to kickstart your agent. Lets consider this single-turn example:
from deepeval.dataset import EvaluationDataset, Golden
goldens =[
Golden(input="What is your name?"),
Golden(input="What is your dad's name?", expected_output="Joe"),
Golden(input="What is your mom's name?")]
dataset = EvaluationDataset(goldens=[goldens])
Here we see 3 goldens each with a different input that kickstarts your agent. To benchmark a single-turn AI agent, all you have to do is call your agent in the context of this dataset:
for golden in dataset.evals_iterator():
ai_agent(golden.input)
Congratulations 🥳! You now know how to evaluate single-turn AI agents for both production and development workflows. Now let’s run through some examples for single and multi-turn AI agents.
(Note that we keep mentioning “single-turn” because benchmarking for multi-turn agents involves a few more steps which we’ll go through in the multi-turn section below.)
Confident AI: The DeepEval LLM Evaluation Platform
The leading platform to evaluate and test LLM applications on the cloud, native to DeepEval.
Regression test and evaluate LLM apps.
Easily A|B test prompts and models.
Edit and manage datasets on the cloud.
LLM observability with online evals.
Publicly sharable testing reports.
Automated human feedback collection.
Single-Turn Agentic Evaluation
For this walkthrough, we’re going to revisit the trip planner agent introduced in the beginning of this article, only this time we will turn it into a single-turn agentic system instead.
Consider this agentic system, where instead of a chat-based interaction it collects information such as the user's intended destination via a form instead:
Single-turn agent planner
We will evaluate the argument correctness of the LLM component and task completion of the end-to-end interaction by setting up tracing and applying metrics:
from openai import OpenAI
from deepeval.tracing import observe
from deepeval.metrics import ArgumentCorrectness, TaskCompletionMetric
@observe(metrics=[ArgumentCorrectness(), TaskCompletionMetric()])deftrip_planner_agent(destination:str, start_date:str, end_date:str):
client = OpenAI(...)@observe(type="tool")defweb_search(query:str):returnf"Search results for '{query}'"@observe(type="tool")defbook_calendar(events):returnf"{len(events)} events booked on calendar"
plan = client.chat.completions.create(model="gpt-4o", messages=[{"role":"user","content":f"Plan a trip to {destination} from {start_date} to {end_date}."}])
search_results = web_search(f"flights and hotels in {destination} from {start_date} to {end_date}")
refined_plan = client.chat.completions.create(model="gpt-4o", messages=[{"role":"user","content": search_results}])
booking = book_calendar(["Flight","Hotel","Dinner reservation"])return booking
In this example, our single-turn agent example has the following call sequence: trip_planner_agent → LLM → web_search → LLM → book_calendar → return, which when applying the ArgumentCorrectnessMetric, would allow us to automatically evaluate whether the tools were called with the correct
On Confident AI, these metrics will be ran automatically whenever you run your AI agent, and looks as follows on the UI. We always recommend the task completion metric and the argument correctness metric as it allows you to see nice plots of how your agent is performing over time immediately without any additional setup time:
Tracking performance of AI agent over time
(You can learn how to set this up in more detail if interested here.)
If you also wish to run evals on a single-turn AI agent in development, simply curate a dataset of goldens and invoke your agent by looping through your dataset:
for golden in dataset.evals_iterator():
trip_planner_agent(golden.input)
Great stuff, now let’s move onto the difficult part.
Multi-Turn Agentic Evaluation
Evaluating multi-turn AI agents are notoriously difficult for many reasons you will soon learn (yikes). Not only do we have to consider components within your AI agent, but now also the end-to-end turn history that would ultimately be evaluated for task completion. (In fact, I wrote another article here talking about how to evaluate LLM chatbots)
Let’s remind ourselves of the initial trip planner example again which was always multi-turn to start with:
A Multi-Turn Trip Planner Agent
We’ll evaluate it by setting up LLM tracing and applying metrics:
from deepeval.tracing import update_current_trace
@observe(metrics=[ArgumentCorrectnessMetric()])deftrip_planner_agent(destination:str, start_date:str, end_date:str, thread_id:str):# Same as before
update_current_trace(thread_id=thread_id)pass@observe():defask_user_and_collect_info(question:str, thread_id:str):
client = OpenAI(...)# Implement logic to collect user response
update_current_trace(thread_id=thread_id)passdefchat_agent():"""
Multi-turn chat that collects info before calling trip_planner_agent.
"""
your_thread_id ="uuid_3943..."
destination = ask_user_and_collect_info("Where would you like to go?", your_thread_id)
start_date = ask_user_and_collect_info("When does your trip start?", your_thread_id)
end_date = ask_user_and_collect_info("When does it end?", your_thread_id)return trip_planner_agent(destination, start_date, end_date, your_thread_id)# Interact with chat_agent until trip is booked
evaluate_thread(thread_id=your_thread_id, metric_collection="Convo Completeness")
Here, we've implemented the most minimal version of how your agentic might look like. You’ll notice although this agent technically still calls trip_planner_agent from our single-turn example and carries out the same task, there’s a few differences from the single-turn example above:
Same metrics still apply on the component-level (argument correctness), but different metrics for the
end-to-end level (conversation completeness instead of task completion)
No metrics on the single-turn end-to-end (trace) level - this is because although you can technically evaluate task completion, in reality the task itself is being carried out throughout a conversation instead of an individual turn level.
Multi-turn evals has to be ran explicitly via the evaluate_thread function at the end, which uses a collection of metrics (this example uses metrics on Confident AI, which you can name as a collection)
The top-level chat_agent was not decorated by the @observe decorator - this is because whilst this is a multi-turn agent, we simply want to group together multiple single-turn traces
This is not without reason. The same metrics still apply on the component-level because the inner workings on a single-turn level is still the same, whereas the end-to-end level has now changed from a single-turn one to a multi-turn one, thus requiring a different metric.
Note that we also called update_current_trace to set the thread_id on individual traces. This allows us to group together different traces within our AI agent to form a multi-turn log. Lastly, evals have to be called explicitly because we’ll only want to run an evaluation once we’re certain a conversation has completed, which was not a concern for a single-turn AI agent.
Multi-turn AI agent evals
If you wish to benchmark multi-turn AI agents, things get even tricker. You see, for single-turn all we need is a golden input to invoke our agent, and these will act as anchors to compare different test runs in an experiment. For a multi-turn use case, you can’t compare based on “input”s, so instead we have to compare based on “scenarios” instead.
You can create a list of scenarios via a multi-turn dataset:
from deepeval.dataset import EvaluationDataset, ConversationalGolden
goldens =[
ConversationalGolden(scenario="Angry user asking for refund"),
ConversationalGolden(input="User wants to go to Tokyo", expected_outcome="Books a trip to Shibuya")]
dataset = EvaluationDataset(goldens=[goldens])
Apart from the datasets, another difficult part about benchmarking multi-turn agents is that it requires simulations. I will talk more about this in a whole different article another time, but the rationale is you’ll need to simulate user interactions with any multi-turn AI agent in order to have the turns necessary ready for evaluation.
User simulations are required before evaluating multi-turn AI agents
Multi-turn agents are difficult to benchmark, that’s if you want to do it the right way. I’m going to write another piece targeting multi-turn evaluation and simulations, so stay tuned.
Common Misconceptions on Agent Evaluation
We’ve already went through most of them in this article, but to spell them out more clearly here are the some misconceptions that can greatly impact the validity of your agent evaluation results:
Confusing multi-turn with single-turn agentic systems, especially when invoking other (swarms of agents) are involved.
Metrics such as argument correctness that seemingly evaluate tool calls being placed on functions — When in reality should actually be placed on LLM components instead.
Evaluating turn-level components within a multi-turn agentic system is somehow different from evaluating the same components in a single-turn context: It’s not.
Using inputs instead of scenarios to benchmark multi-turn AI agents — This rarely leads to meaningful experiments.
The good news is, if you’re certain that your AI agent is a single-turn one, most likely you wouldn’t have to deal with the complications that come with multi-turn agentic systems.
Confident AI: The DeepEval LLM Evaluation Platform
The leading platform to evaluate and test LLM applications on the cloud, native to DeepEval.
Regression test and evaluate LLM apps.
Easily A|B test prompts and models.
Edit and manage datasets on the cloud.
LLM observability with online evals.
Publicly sharable testing reports.
Automated human feedback collection.
Top AI Agent Evaluation Metrics
Now that we’ve learnt all we need to evaluate both single and multi-turn AI agents, let’s go through the top metrics I’ve seen users of DeepEval use for AI agent evaluation. (DeepEval runs more than 20 million evaluations every single day)
And don't worry these won't be metrics such as:
Task success rate
Agent response time
User satisfaction
Why? Because these are metrics you already know how to measure. These are non-qualitative metrics that one can easily measure using something like Mixpanel, or any other internal product analytics tracking tool you're already using.
In this section, we'll go through the top LLM-as-a-judge metrics instead, here's a quick list:
A list of the most useful/common AI agent metrics
Task Completion
Task completion is a single-turn, end-to-end LLM-as-a-judge metric that measures an AI agent’s degree of task completion based on an LLM trace. It works by inferring the intended goal of a given LLM trace, before verifying whether the goal has been met based on the final output.
from deepeval.tracing import observe
from deepeval.metrics import TaskCompletionMetric
@observe(metrics=[TaskCompletionMetric()])deftrip_planner_agent(input):
destination ="Paris"
days =2@observe()defrestaurant_finder(city):return["Le Jules Verne","Angelina Paris","Septime"]@observe()defitinerary_generator(destination, days):return["Eiffel Tower","Louvre Museum","Montmartre"][:days]
itinerary = itinerary_generator(destination, days)
restaurants = restaurant_finder(destination)return itinerary + restaurants
Note that you must place the task completion metric on the top-most span as that represents the end-to-end trace interaction for an AI agent. If you wish to evaluate nested agents, you can also place the `TaskCompletionMetric` in that inner-level as well. Learn more in DeepEval's docs.
Argument Correctness
Argument correctness is a component-level LLM-as-a-judge metric that assesses an LLM’s ability to generate the correct input argument parameters for a certain tool call. It works by determining whether the input parameters going into tools called by LLMs are correct and relevant to the input.
from openai import OpenAI
from deepeval.tracing import observe
from deepeval.metrics import ArgumentCorrectness
@observe(metrics=[ArgumentCorrectness()])deftrip_planner_agent(input):
client = OpenAI(...)@observe(type="tool")defweb_search(query:str):return"Results from web"
res = client.chat.completions.create(...)
res = web_search(res)# Modify this to check for res typereturn res
Tool Correctness
Tool correctness is an end-to-end reference-based, single-turn metric that assess an AI agent’s ability to call the correct tools based on a given input. It works by exact matching between a list of expected tool calls and the actual tools that were called, with the ability to also match input parameters and outputs.
from deepeval import evaluate
from deepeval.test_case import LLMTestCase, ToolCall
from deepeval.metrics import ToolCorrectnessMetric
test_case = LLMTestCase(input="What if these shoes don't fit?",# Replace this with the tools that was actually used by your LLM agent
tools_called=[ToolCall(name="WebSearch"), ToolCall(name="ToolQuery")],
expected_tools=[ToolCall(name="WebSearch")],)
evaluate(test_cases=[test_case], metrics=[ToolCorrectnessMetric()])
Here, we actually run it as part of a dataset instead because a reference-based metric can't be ran online where an expected list of tools are required.
Conversation Completeness
Conversation completeness is a multi-turn, end-to-end LLM-as-a-judge metric that measures a conversational AI agent’s degree of satisfying user requests through a multi-turn interaction. It works by inferring what the user's intended goal is before determining whether it has been met throughout a dialogue-based interaction.
from openai import OpenAI
from deepeval.tracing import observe, update_current_trace, evaluate_thread
client = OpenAI()
your_thread_id ="your-thread-id"@observe()defai_agent(query:str):
res = client.chat.completions.create(model="gpt-4o", messages=[{"role":"user","content": query}]).choices[0].message.content
update_current_trace(thread_id=your_thread_id,input=query, output=res)return res
# Call you multi-turn agent...
evaluate_thread(thread_id=your_thread_id, metric_collection="Collection Name")
In this example we actually used something called a metric collection instead of metric objects as seen in single-turn examples. This is because we're delegating evaluation to an external source such as Confident AI for simplicity purposes (learn more in docs).
Turn Relevancy
Turn relevancy is another multi-turn, end-to-end LLM-as-a-judge metric that measures a conversational Ai agent's ability to stay on track and not drift in its responses during a multi-turn interaction. It works by using a sliding window approach to assess whether each turn is relevant based on the prior turns as additional context. The final score is the proportion of turns that are indeed relevant.
Turn relevancy's code will be exactly the same as conversation completeness above.
Best Practices for Evaluating AI Agents
Evaluating AI agents effectively requires balancing end-to-end success with granular insight into each component’s behavior. Here are a few best practices to keep your evaluations structured and meaningful:
Identify whether your agent is single-turn or multi-turn. Each type requires different evaluation strategies and metrics.
Use a mix of 3–5 metrics. Combine component-level metrics (e.g., tool correctness, parameter accuracy) with at least one end-to-end metric focused on task completion.
Develop at least one custom metric. Generic scorers can only go so far — consider using LLM-based evaluators like G-Eval to evaluate the end-to-end result (both single and multi-turn that is).
Benchmark with curated datasets. Golden datasets help you measure progress and ensure consistency across iterations.
Leverage the right tools. Platforms like DeepEval and Confident AI handle the heavy lifting — from metrics to observability — so you can focus on improving your agents instead of maintaining infrastructure.
By following these principles, you’ll not only understand how your agents perform but also gain the confidence to deploy, iterate, and scale them responsibly.
Conclusion
Congratulations on making it to the end! Evaluating AI agents may seem complex at first — with task completion, tool usage, and multi-agent handoffs all coming into play — but it ultimately comes down to understanding how well an agent performs its intended function.
In this article, we explored how single-turn and multi-turn agents require different evaluation approaches, and how their performance can be assessed both holistically (through task completion) and at the component level (through tool correctness, parameter accuracy, and coordination).
While many teams start by running ad-hoc evaluations, building a curated golden dataset can bring structure and repeatability to your benchmarking process — helping you measure progress across agent versions with confidence.
And if you’d rather not reinvent the wheel, DeepEval and Confident AI (sign up here) provide everything you need to evaluate agents efficiently — from metrics and datasets to observability and benchmarking — so you can focus on building better agents, not building evaluation infrastructure.
.png)


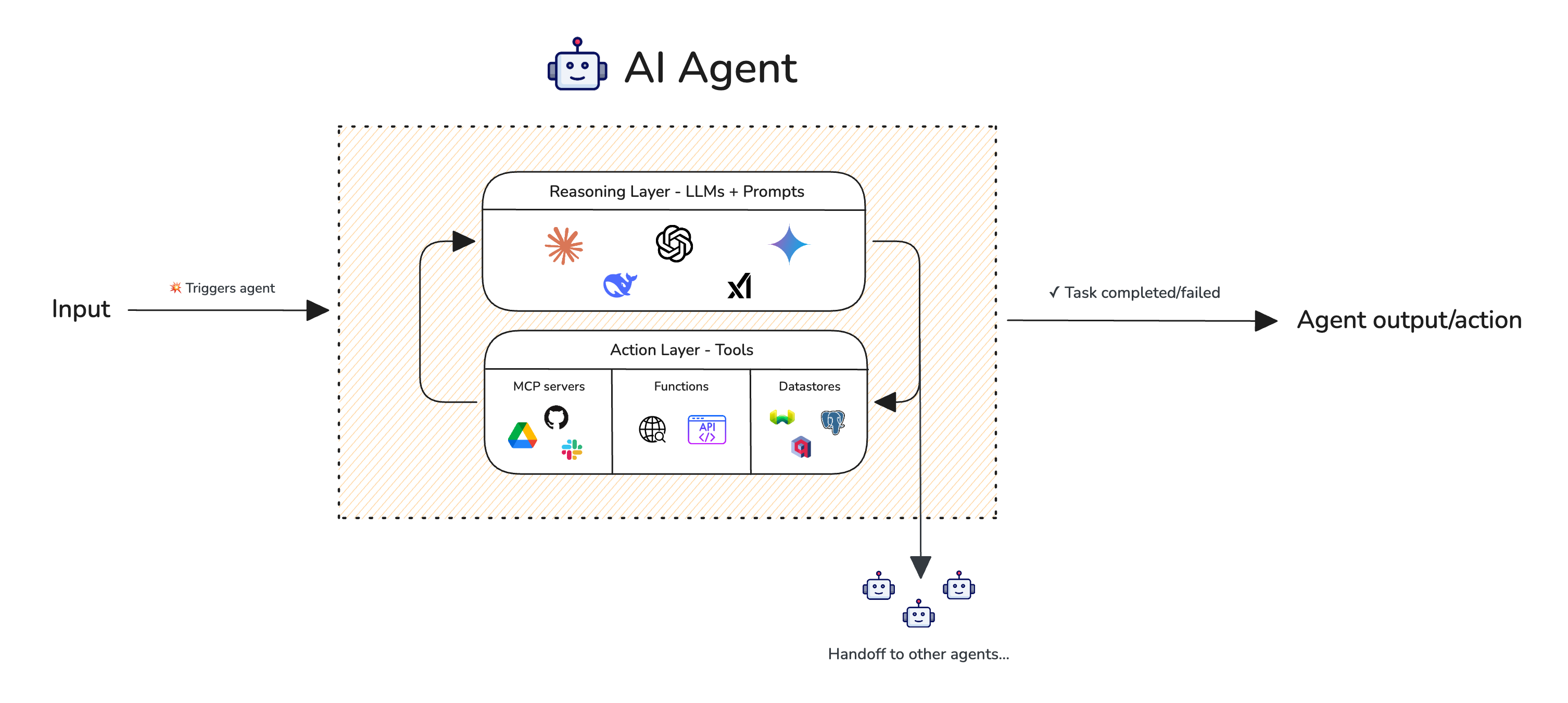 Single-turn AI agent with tools and ability to handoff to other agents
Single-turn AI agent with tools and ability to handoff to other agents A Multi-Turn Trip Planner Agent
A Multi-Turn Trip Planner Agent Single-Turn LLM-as-a-Judge
Single-Turn LLM-as-a-Judge Multi-Turn LLM-as-a-Judge
Multi-Turn LLM-as-a-Judge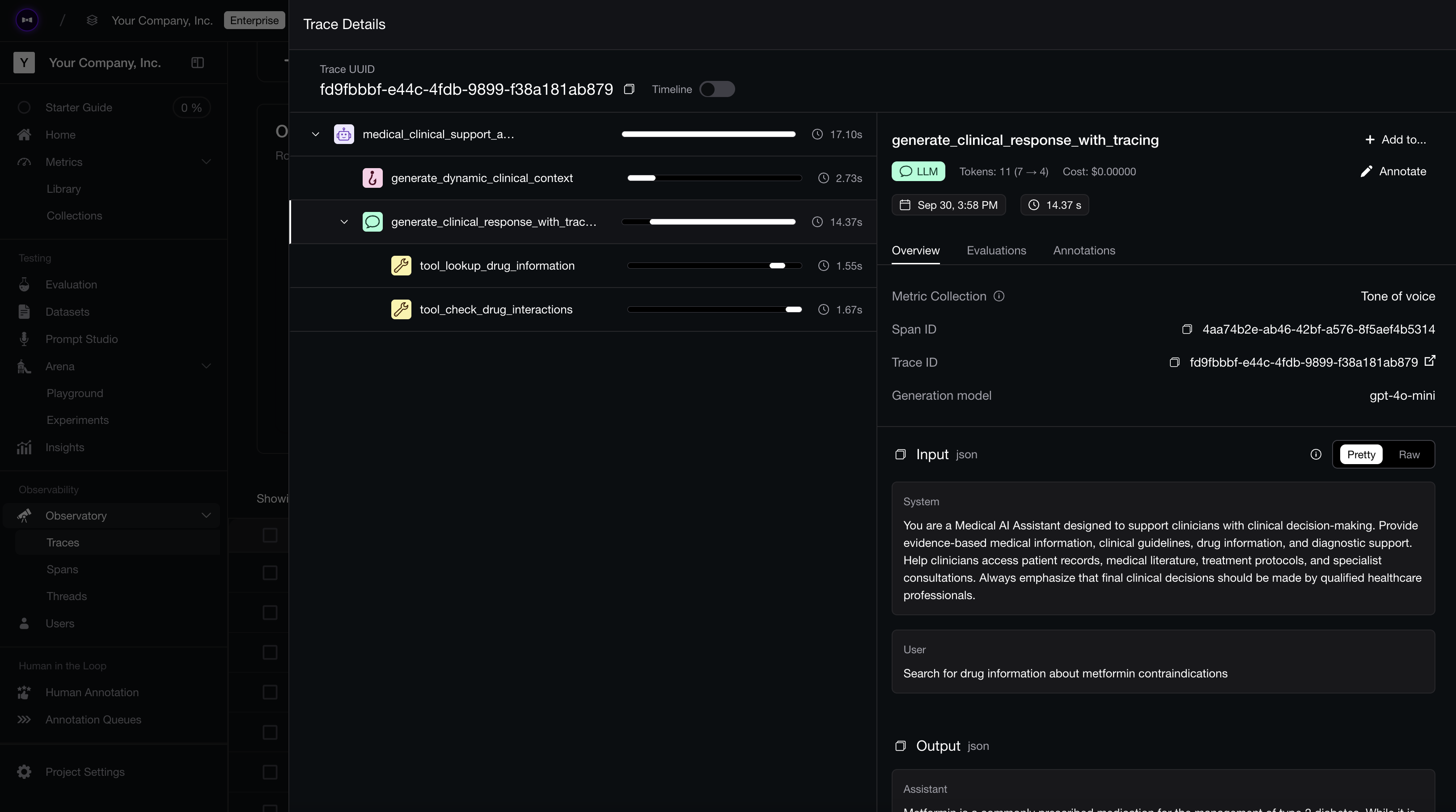 Tracing on Confident AI
Tracing on Confident AI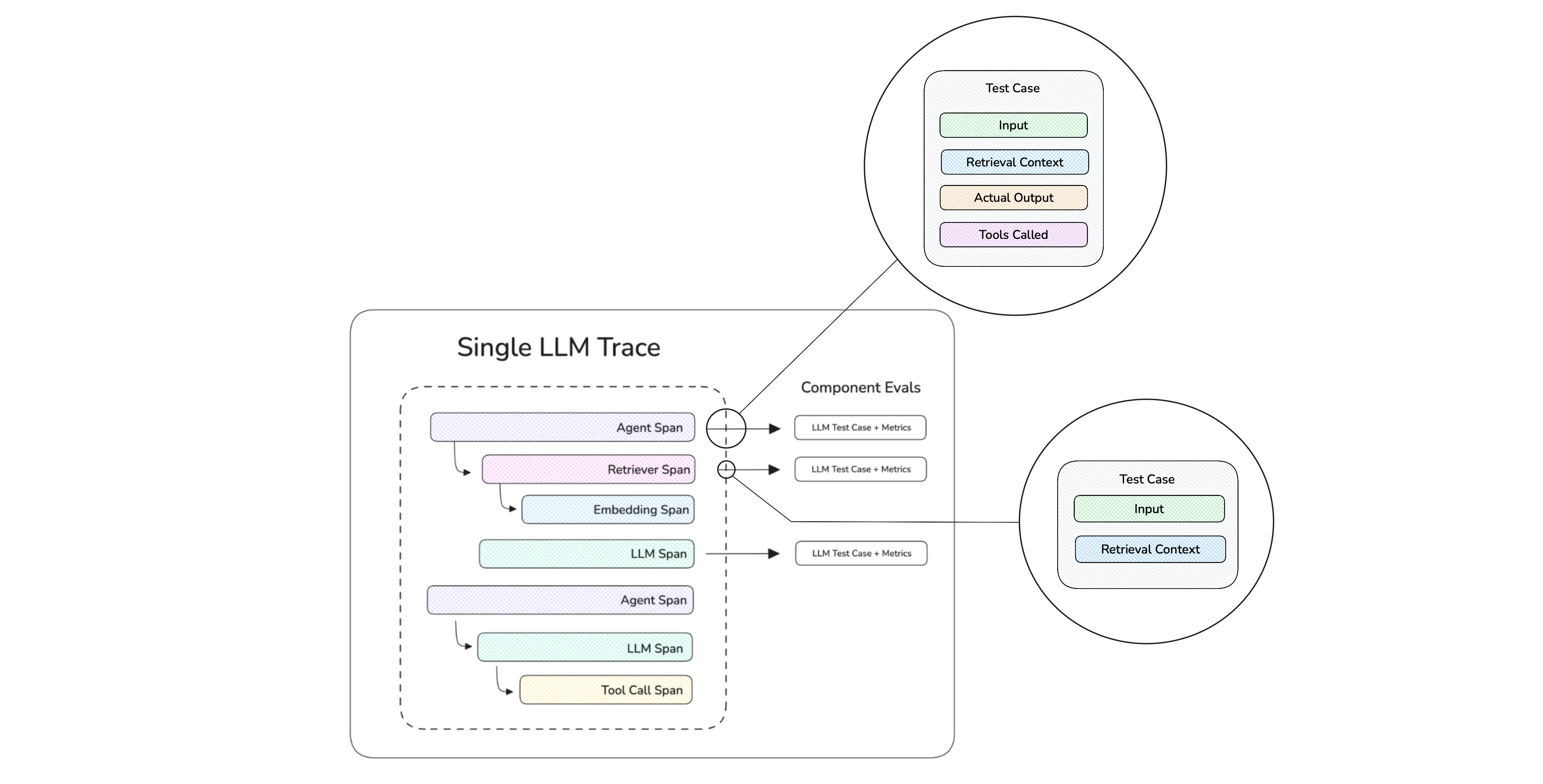 Metrics Applied on a Span (component) Level
Metrics Applied on a Span (component) Level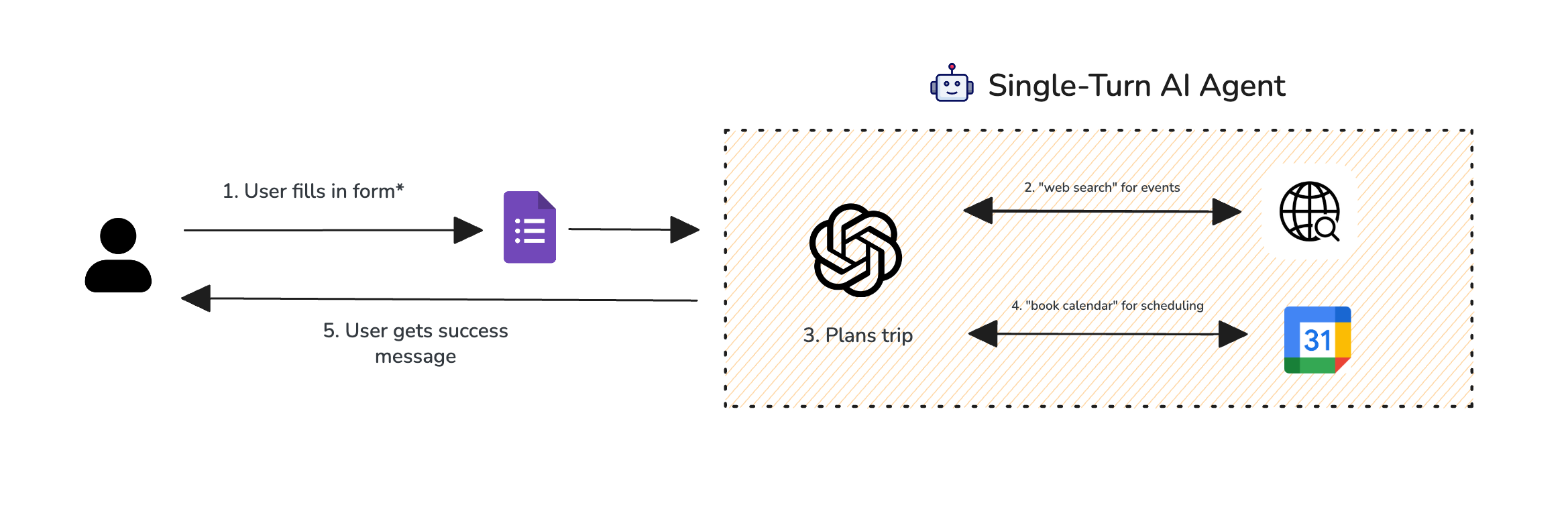 Single-turn agent planner
Single-turn agent planner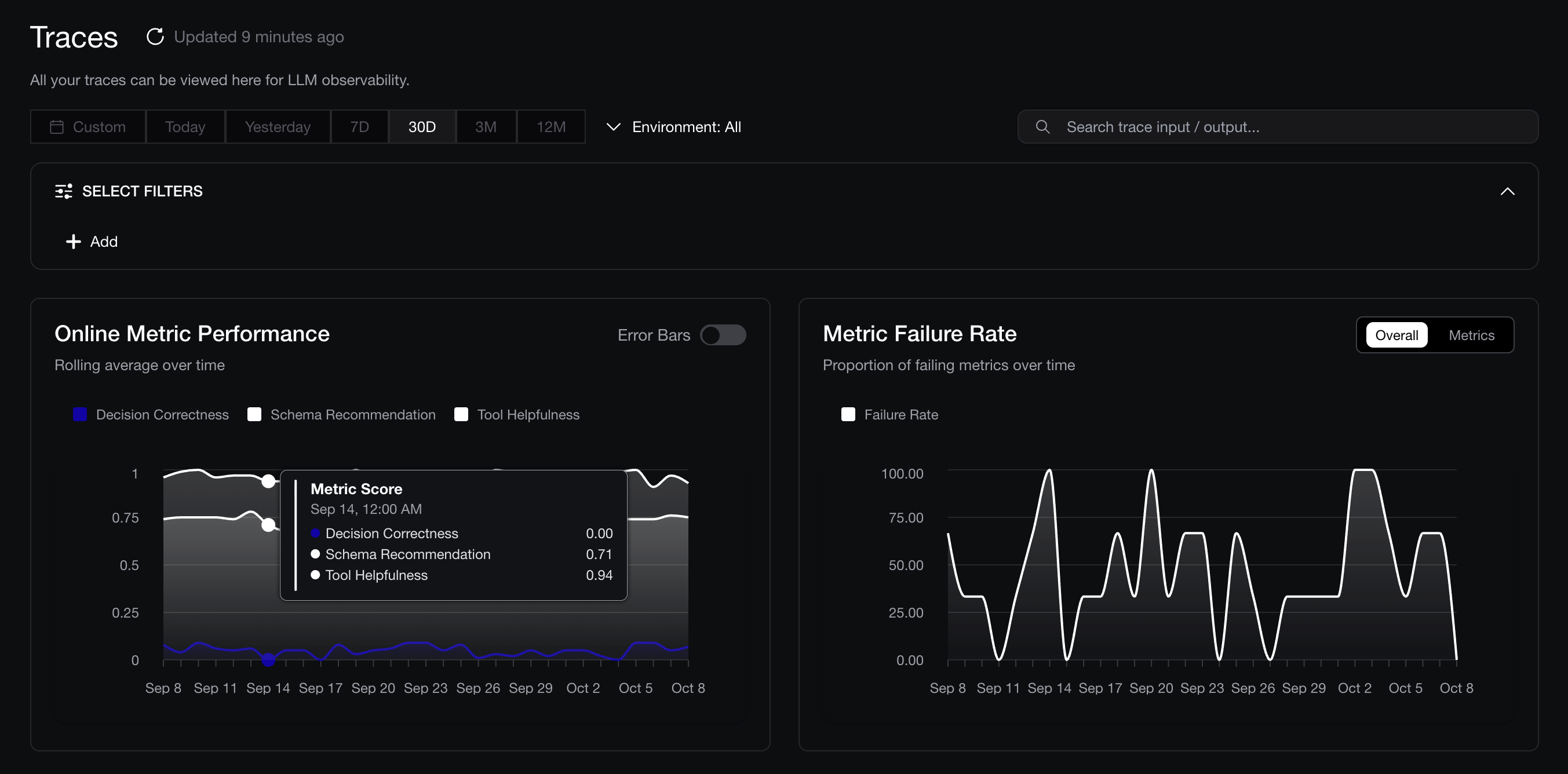 Tracking performance of AI agent over time
Tracking performance of AI agent over time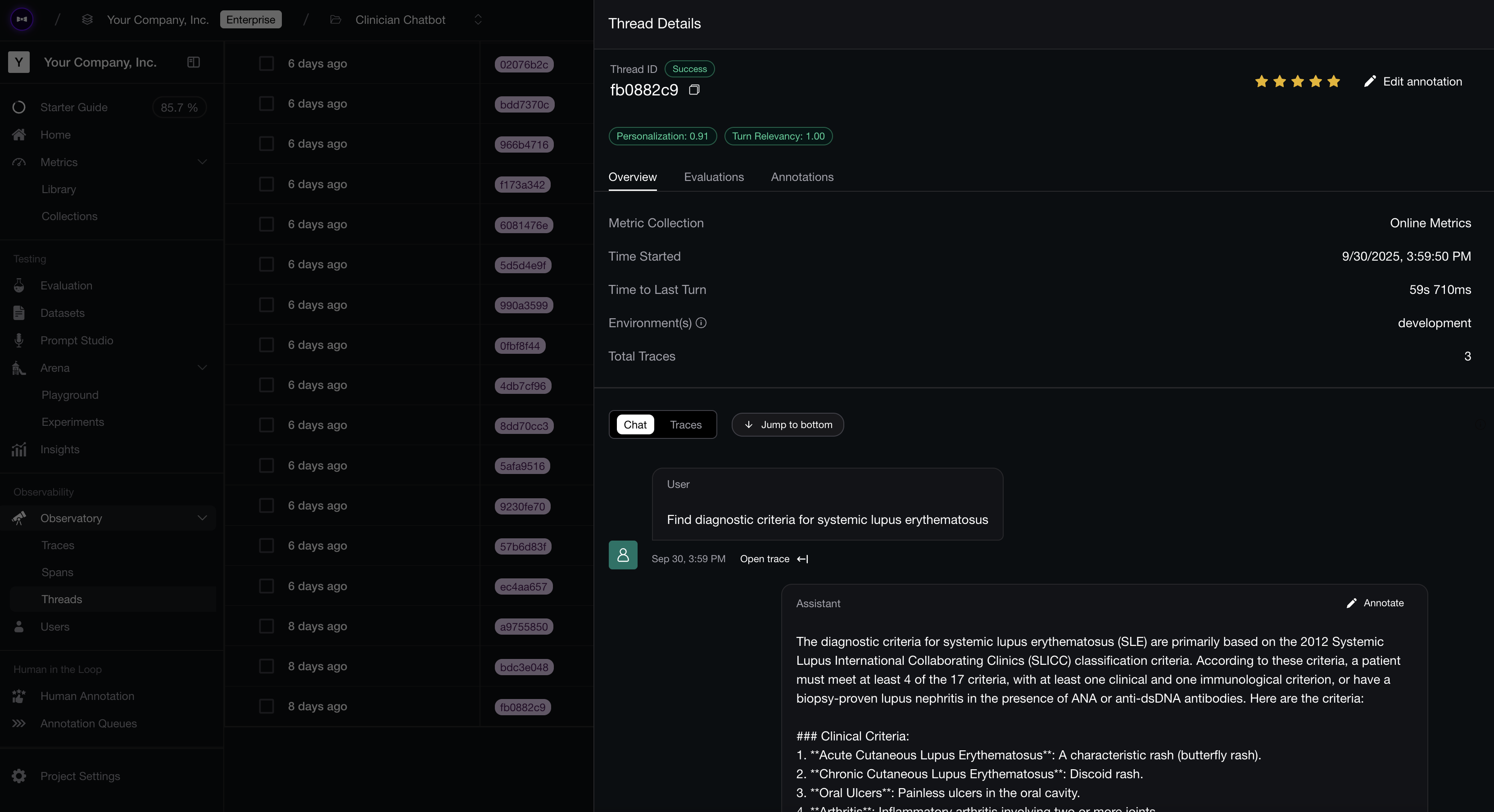 Multi-turn AI agent evals
Multi-turn AI agent evals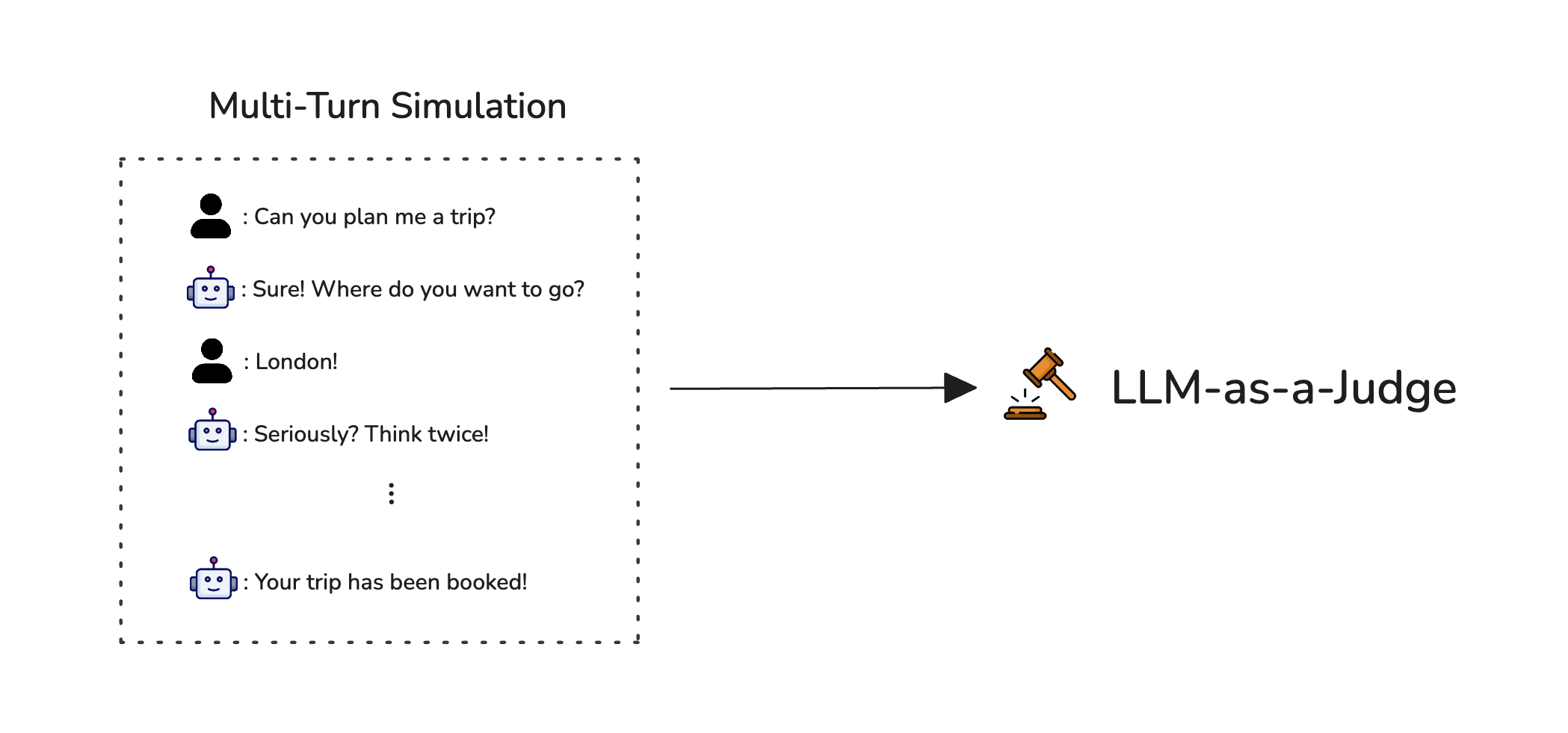 User simulations are required before evaluating multi-turn AI agents
User simulations are required before evaluating multi-turn AI agents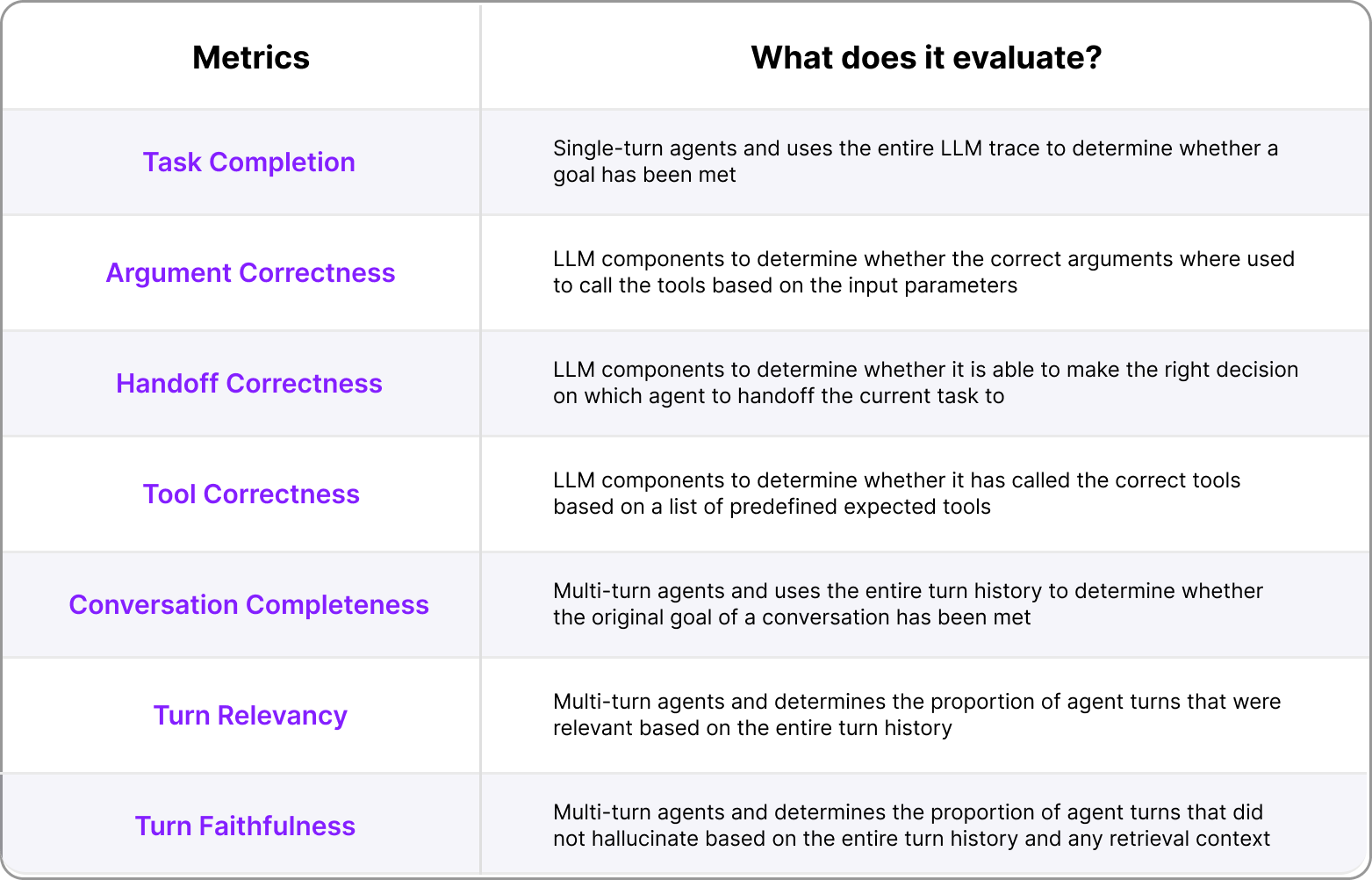 A list of the most useful/common AI agent metrics
A list of the most useful/common AI agent metrics
