.png)


It's been nearly two years since we first explored "The Economics of Building ML Products in the LLM Era" - examining how LLM APIs fundamentally changed the development lifecycle from API-first prototypes to eventual custom model deployment. What we predicted then about the unsustainable nature of API pricing has only become more pronounced. While that analysis focused on the natural progression companies follow as they scale their AI products, this piece dives deeper into the economic forces that make current API pricing a temporary strategic illusion.
The LLM API market has a paradox. While companies invest billions in AI infrastructure, access to these powerful models is priced at levels that seem almost too good to be true. Just like the early days of Uber, it is a subsidized market in a strategic land-grab phase.
The LLM API market is dominated by three main players: OpenAI, Anthropic, and Google. These companies are engaged in aggressive price competition that goes beyond model capabilities. Consider the pricing variations:
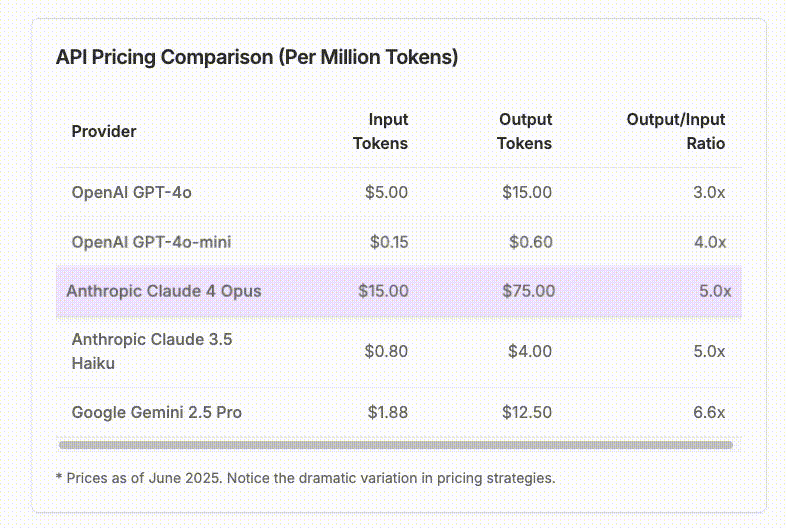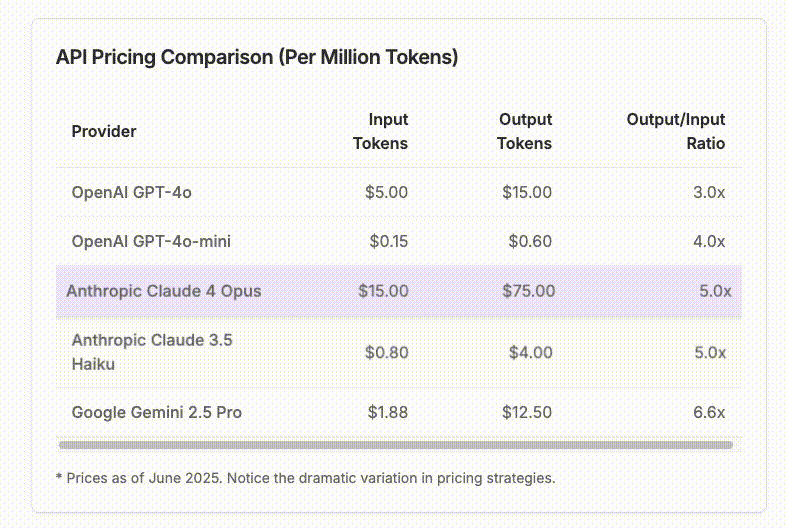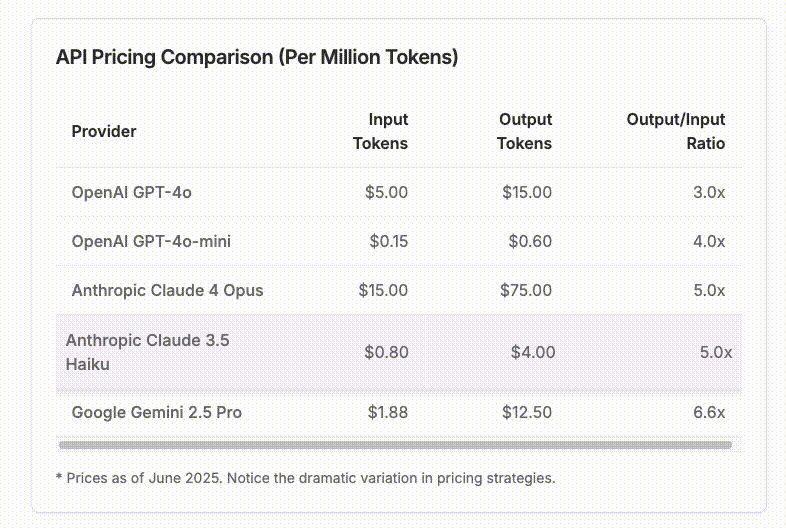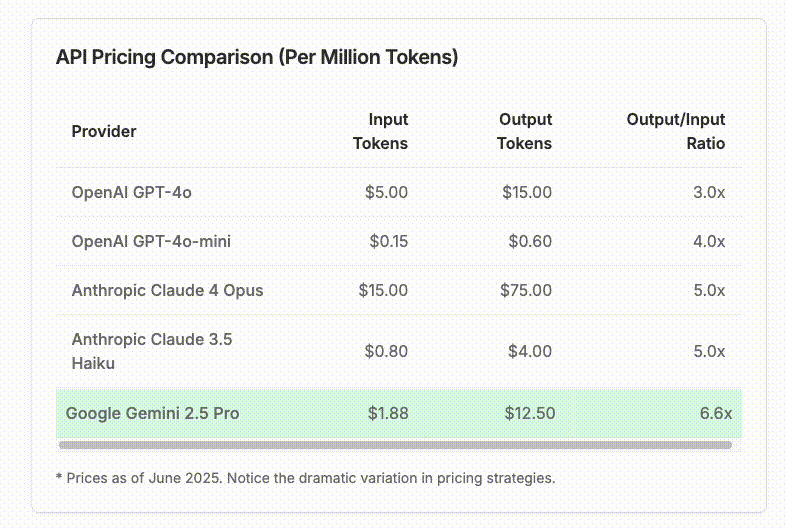
The pricing spread shows that costs aren't driving prices—strategy is.
To understand the scale of subsidization, let's examine the actual costs of running LLM inference using a bottom-up analysis.
A state-of-the-art 8x NVIDIA H200 GPU server costs $400,000-$500,000. Key components include:
GPU costs: $30,000-$40,000 per H200 chip
Supporting infrastructure: High-performance CPUs, substantial RAM, networking
Operational expenses: Power (700W per GPU), cooling (30-50% overhead), data center space
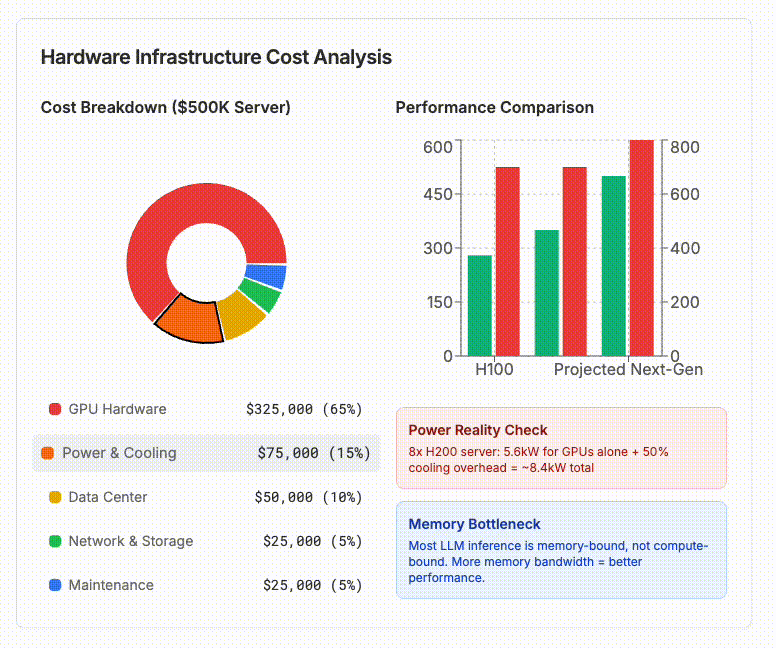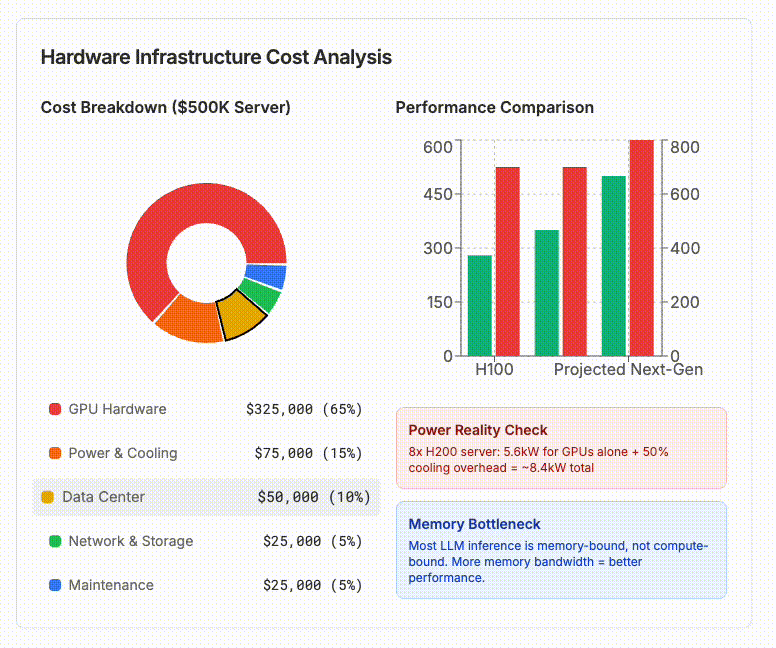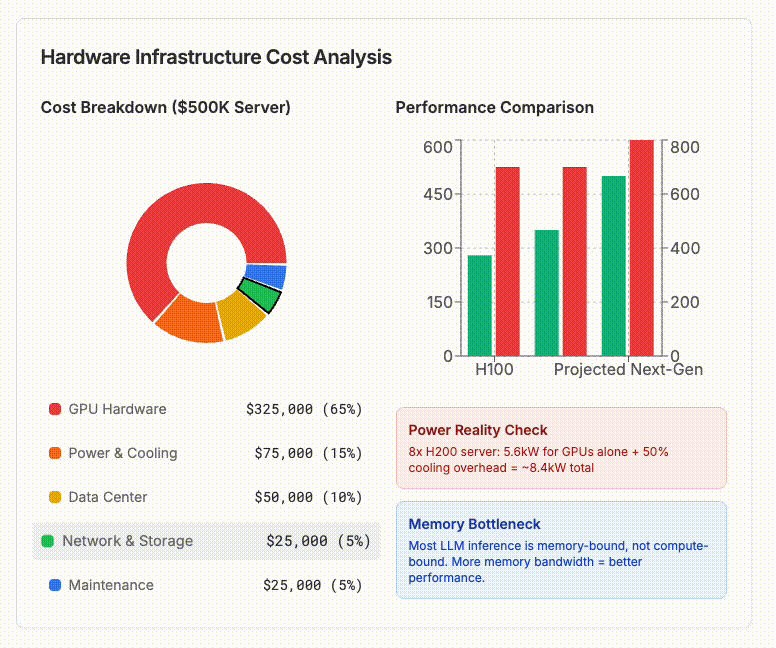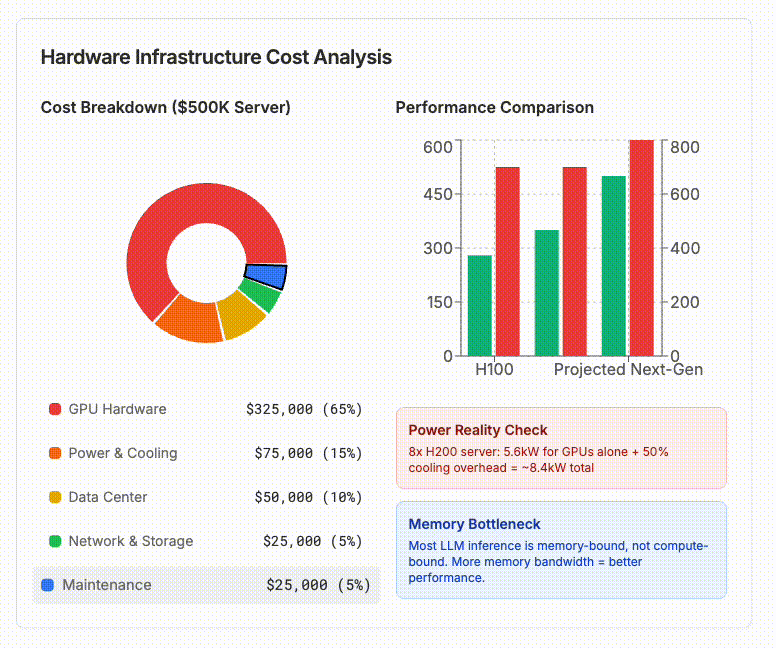
Real-world benchmarks show an NVIDIA H100 generates approximately 250-300 tokens per second for 70B parameter models under typical conditions. The newer H200, with 60% more memory bandwidth, performs better but still faces the fundamental constraint that most LLM inference is memory-bound, not compute-bound.
Using cloud hosting costs and performance assumptions:
Cloud server cost (8x H200): $42.40/hour (after 50% enterprise discount)
Effective throughput: 1,848 tokens/second
Tokens per hour: 6,652,800
Calculated cost per 1M tokens: ~$6.37
Input Token API price (GPT-4o-mini): $0.60
Estimated subsidy rate ~90%
The provider is, in effect, paying for over 90% of the cost of every token a user processes through this API.
As AI becomes more efficient and cheaper per token, total spending will likely increase dramatically. This phenomenon, known as Jevons’ Paradox, suggests that efficiency improvements lead to increased total consumption.
Amazon S3: From 2006-2016, storage prices dropped 84% (from $0.15/GB to $0.023/GB), yet AWS revenue grew from under $1 billion to over $90 billion by 2023.
Uber: Initially subsidized rides at 59% below cost to capture market share, then raised prices 92% between 2018-2021 once a higher market share was reached.
Several factors will trigger the inevitable price correction:
Market Consolidation: As competitive fields narrow, price pressure decreases
Investor Pressure: Demand for returns will force profitability over growth
Hardware Constraints: GPU supply limitations will force demand management through pricing
Customer Lock-in: High switching costs will enable price increases
A smart planning approach is to expect that overall AI-related spending will grow by 3 to 5 times within a two- to three-year period.
Create abstraction layers to route between different providers
Monitor true unit economics beyond monthly bills
Route simple tasks to cheaper models, complex reasoning to premium ones
For high-volume, predictable workloads, the total cost of ownership calculation for bringing inference in-house becomes compelling as API prices normalize.
As the market matures, we'll likely see:
Simple Price Hikes: Direct increases to heavily subsidized models
Value-Based Pricing: Multi-dimensional pricing based on performance, reliability, and capabilities
Hybrid Models: Strategic split between on-premise deployment and API usage
While we've shown you the economic reality behind those "too good to be true" API prices, Soham will teach you practical techniques to dramatically reduce your token consumption right now - before the market correction hits.
We will be leading a hands-on workshop at AgentCon titled "Token Optimization for AI Agents," where you'll learn exactly how to tackle these challenges head-on.
Register here: https://globalai.community/tickets/order/34221
As someone who's spent years analyzing the actual costs of AI operations and building tools to combat them, Soham brings both the technical depth and real-world experience to help you navigate this transition successfully.


The subsidized paradise won't last forever, but those who understand the underlying economics—and more importantly, know how to optimize for them—will thrive during the transition.
The LLM API market is in a unique historical moment where revolutionary technology is priced below cost to capture market share. Understanding this dynamic is crucial for:
Enterprises: Budget appropriately and build flexible architectures
Investors: Look beyond vanity metrics to unit economics and ecosystem moats
Developers: Prepare for eventual price normalization while taking advantage of current opportunities


![CNCF Tech Radar Report on AI Tools Adoption [pdf]](https://news.najib.digital/site/assets/img/broken.gif)
