.png)

Last week Tesla launched its Robotaxi (Supervised), based on its regular vehicle platform and accompanying Full Self-Driving (Supervised). It went as poorly as you could predict for a number of reasons but only two are relevant here:
Poverty of information due to lack of LIDAR and radar sensor input
That AI is not a technological fact but a marketing term
Around the same time, Andrej Karpathy’s +1 on context engineering over prompt engineering. Karpathy is the former R&D lead on FSD (Supervised).
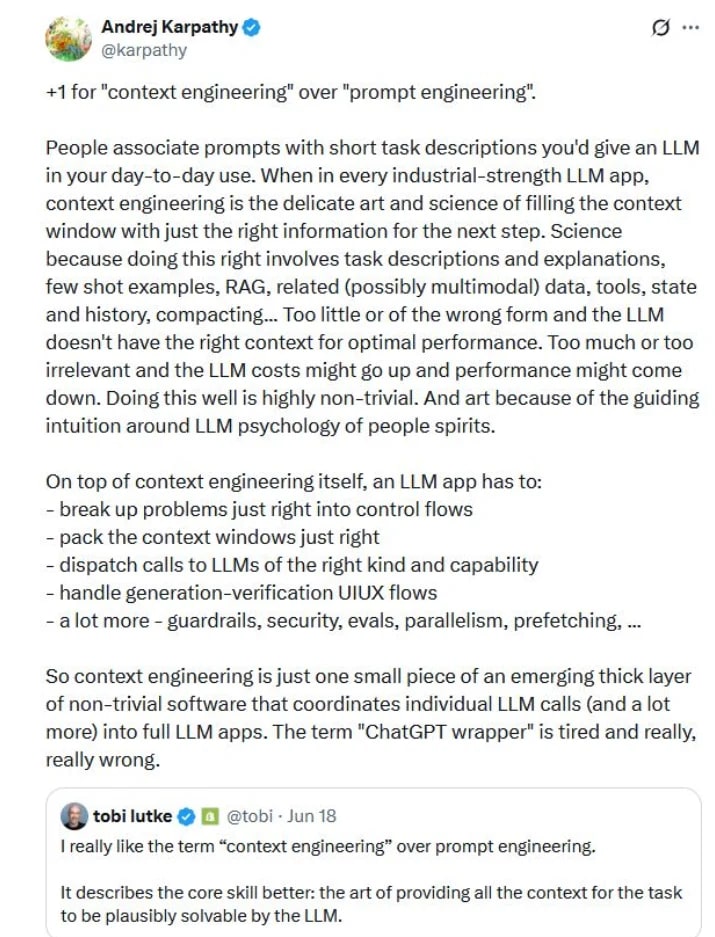
There is a related thread on Hacker News, and here are a couple of excerpted comments:
Saw this the other day and it made me think that too much effort and credence is being given to this idea of crafting the perfect environment for LLMs to thrive in. Which to me, is contrary to how powerful AI systems should function. We shouldn’t need to hold its hand so much.
Obviously we’ve got to tame the version of LLMs we’ve got now, and this kind of thinking is a step in the right direction. What I take issue with is the way this thinking is couched as a revolutionary silver bullet.
Right, an intelligent system per definition doesn’t need to be spoonfed curated sets of information.
Reminds me of first gen chatbots where the user had to put in the effort of trying to craft a phrase in a way that would garner the expected result. It's a form of user-hostility.
A more complicated form of code.
"Wow, AI will replace programming languages by allowing us to code in natural language!"
"Actually, you need to engineer the prompt to be very precise about what you want to AI to do."
"Actually, you also need to add in a bunch of "context" so it can disambiguate your intent."
"Actually English isn't a good way to express intent and requirements, so we have introduced protocols to structure your prompt, and various keywords to bring attention to specific phrases."
"Actually, these meta languages could use some more features and syntax so that we can better express intent and requirements without ambiguity."
"Actually... wait we just reinvented the idea of a programming language."
So then for code generation purposes, how is “context engineering” different now from writing technical specs? Providing the LLMs the “right amount of information” means writing specs that cover all states and edge cases. Providing the information “at the right time” means writing composable tech specs that can be interlinked with each other so that you can prompt the LLM with just the specs for the task at hand.
Alright, Hacker News pretty much wrote this essay for me, but I will continue to take this point and its implications further.
While this is progress in the practical domain of applying language models to real-world problems, it is a step backwards in their potential uses. Why, because it shows that LLMs must be handheld by humans and cannot function autonomously. There are two main forms of handholding or human supervision:
Synchronously, where we prompt a CLI or chatbot interface and verify or manipulate its return before putting it to use.
Asynchronously, in the form of code that implements RAG guardrails, examples in prompts, evals, a workflow that uses a second model to correct the output of the first, etc.
In fact, you can infer a principle that I have had in mind for some time now from this need for human supervision:
Output generated by language models through automated workflows must never be exposed directly to the end-user.
I’m certain that this phrasing can be made significantly more elegant.
Anyway, the point is that an AI that needs a human in the loop to function in real-world applications, is not intelligent. It’s just yet another evolutionary step in the journey of technology becoming gradually more capable. This has massive implications for the current transformer-model bubble—and is what will eventually cause it to burst.
There is an inherent paradox to LLMs, or lets call it “AI’ for simplicity. The more valuable the application of AI, the higher risk it carries, which is also why it cannot be implemented, because the inaccuracy of an LLM cannot be accurately calculated or fully eliminated.
Assessing the accuracy of LLMs is notoriously difficult. Several inherent challenges complicate evaluation:
First, the term “accuracy” is somewhat meaningless when it comes to LLMs. Anything that an LLM outputs is by definition “accurate” or “correct” from a technical point of view because it was produced by the model. The term accuracy then is not a technical or perhaps even factual term, but a sociological and cultural term, where what is right or wrong is determined by society, and even we sometimes have a hard time determining what is true or note (see: philosophy).
Instead of accuracy, we should probably talk about something like “matching” instead: does what the model output match our version of truth? This is a more consistent and correct terminology, that has clear methods for validating output: Output is accurate when it closely matches whatever we have determined is correct. However, this requires human input at some point in the workflow.
Non-determinism presents another problem in evaluation. LLMs can produce different answers to the same prompt in different runs, especially if any randomness (temperature) is used. Even when configured to be deterministic (temperature = 0), studies have found that results can vary due to underlying implementation details.
LLM practitioners commonly notice that outputs can vary for the same inputs under settings expected to be deterministic. Yet the questions of how pervasive this is, and with what impact on results, have not to our knowledge been systematically investigated. We investigate non-determinism in five LLMs configured to be deterministic when applied to eight common tasks in across 10 runs, in both zero-shot and few-shot settings. We see accuracy variations up to 15% across naturally occurring runs with a gap of best possible performance to worst possible performance up to 70%. In fact, none of the LLMs consistently delivers repeatable accuracy across all tasks, much less identical output strings.
Many applications do not have a single ground truth answer. Even tasks that have some ground truth, like summarization, can have multiple valid outputs. The lack of a clear ground truth makes evaluation subjective, often relying on human judgments or heuristic metrics. This introduces inconsistency and bias. One strategy is to define a rubric of what constitutes a good output and have humans/LLMs rate against that (for example, check if all key facts from a source are present in a summary, and no false facts).
Another strategy is pairwise comparison: given two model outputs for the same prompt, humans or another model decide which is better. This relative ranking can be easier than absolute scoring. Nonetheless, without a ground truth, evaluation becomes qualitative in part. It’s also hard to automate, which is why the LLM-as-a-judge approach has emerged, using models to simulate a “ground truth check” by reasoning about correctness in natural language.
Even then, there’s a risk of the evaluator model sharing the same blind spots as the original. Overall, when no ground truth is available, evaluating accuracy requires careful proxy metrics and acknowledgement of uncertainty.
In certain domains, what counts as correct is not black-and-white. For example, legal questions might have multiple defensible answers or strategies; medical advice might differ between two doctors’ opinions. Domain-specific criteria must be applied: e.g., in healthcare, an answer should not only have correct facts but also appropriate context and safety (an answer could be factually right but dangerously incomplete).
Consistency is another aspect; in customer service or policy domains, giving two users conflicting answers (even if each is individually plausible) can be seen as an accuracy failure from a system standpoint. Handling these ambiguities often requires input from domain experts to set evaluation standards (what is an “acceptable” answer vs a wrong one). It also ties into prompt design: providing the model with precise instructions and context to reduce ambiguity in its output.
While LLM implementations hold immense potential for transformative applications across various industries, the inherent risks associated with their unsupervised operation necessitate human oversight, thereby limiting their true potential and direct application.
Value vs. Risk
AI applications, if fully unsupervised, could offer unprecedented efficiency and access in critical domains. However, the potential for catastrophic errors in such critical, high-stakes applications is too great.... Even a minuscule error rate, like one in a million (0.000001%), becomes unacceptable when scaled to trillions of operations per day, as would be the case in core workflows across industries.
Healthcare: Unsupervised diagnostics and drug prescriptions, or even unmanned surgery, could provide widespread access to efficient healthcare. However, the risk of administering the wrong drug or dosage is too high. Or, the risk of denying care:
”More recently, health insurers have turned to AI decision-making tools that generate prior authorization decisions with little or no human review. These AI tools have been accused of producing high rates of care denial—in some cases, 16 times higher than is typical.”Smart grids: LLMs could dynamically load balance nationwide grids in real-time to better integrate intermittent renewable energy sources. But miscalculations could lead to overloads and blackouts.
Manufacturing and IoT: An LLM could adjust factory workflows for material shortages or reroute autonomous delivery drones during storms. Yet, a single misinterpretation of sensor data could cause defective products, equipment damage, or workplace accidents like a robotic arm crushing machinery.
Implications for employment and LLM employment strategies
Let’s look at the implications of the statement that LLMs must be supervised if deployed, either synchronously or asynchronously.
Synchronous supervision: Tool-use by practitioners
Designers using Figma to prototype a new experience, doctors using software to explore possible causes to observed symptoms and then diving deep to verify, lawyers searching legal cases, translators generating a first draft etc.
Productivity gains are potentially significant for tool-use, however the gains are to some extent balanced out by need to verify and correct the output.
Each practitioner gets more productive, but following Jevon’s paradox, it is more likely that this increases the demand for human translators, as more forms of content can now be translated at a lower cost per instance, increasing the size of the market for viable translations.
Asynchronous supervision: Entirely new software architectures and engineering organizations
This is the context engineering direction that Karpathy elaborated on. This requires enormous amounts of research, prototyping, testing, and iterating to build each use case one by one. The number of use cases that are technically feasible to build are significantly fewer than if your LLM was actually intelligent and capable of operating autonomously. They’re also costlier to build and maintain. A viable use case is data classification and recommendation to end users.
It is clear that we won’t need fewer software developers; we’ll need significantly more of them.
A key thing we may be forced to admit someday is that AI agents are really just expensive temporary glue that we use to build services quickly until we have cheaper hard coded functions developed once the AI agent gives us sufficient experience with the scope of the problem domain.
And it is this revelation that will set off the next AI Winter.



