.png)

Refresh
Now Venmo is down
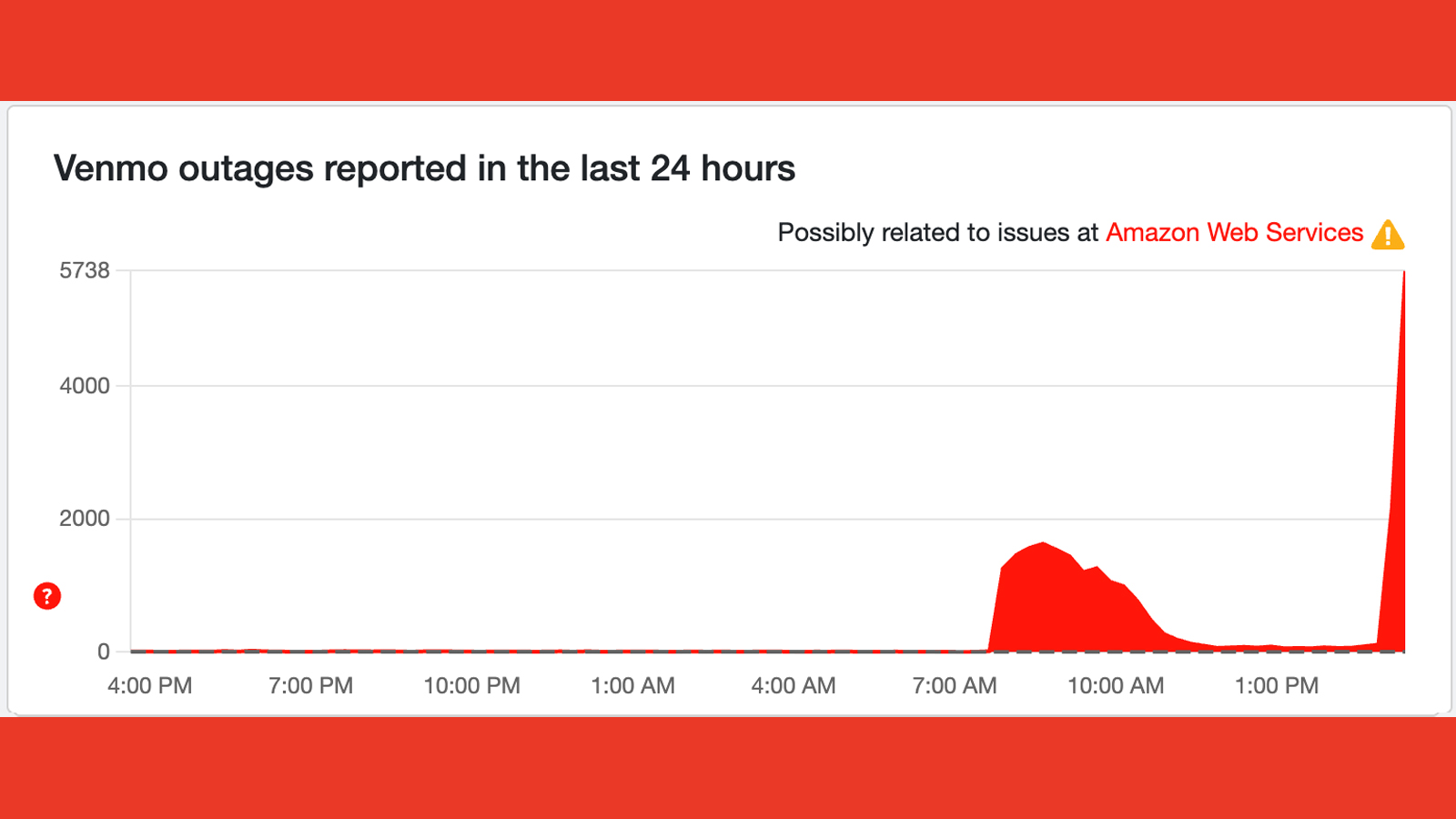
It's only been a few days since Venmo and Paypal were both down in a fairly sizable outage, and now the former is again seeing a huge spike on Downdetector – presumably again due to the AWS outage.
At the time of writing, over 5,700 people have reported problems with the payment platform on Downdetector. A significant number (42%) are saying they can't log into the app, while 52% have reported app problems in general.
The Venmo Support account on X is responding to users having issues, but is simply asking them to contact the support team on the Venmo site. Let's hope this one is resolved as quickly as the outage on October 16, which only lasted a couple of hours...
Tidal is back – or is it?
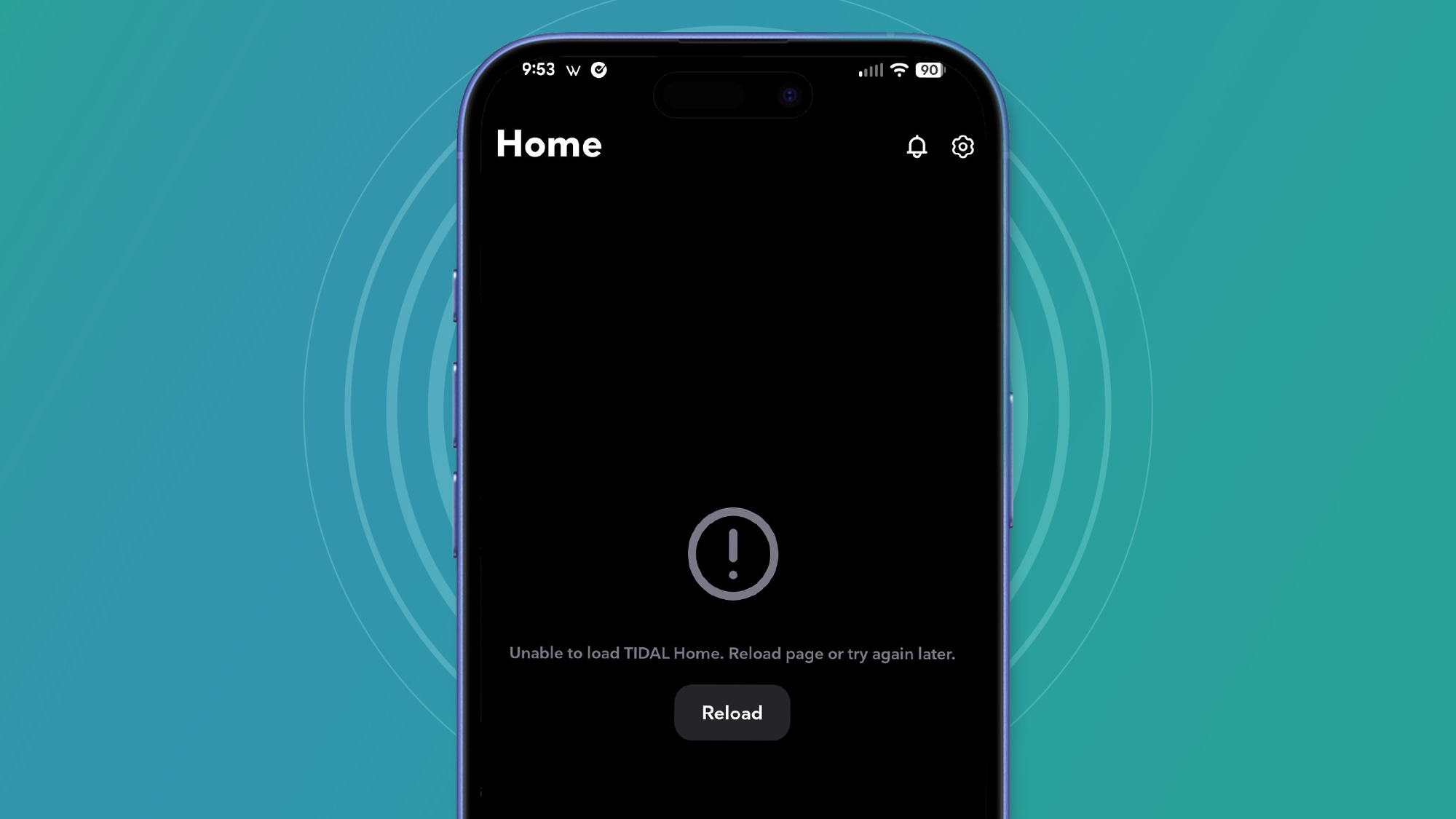
Tidal appeared to be back in business earlier, but we're now seeing another big spike in issues.
Many on social media are reporting problems with the app, and that's been reflected on Downdetector. Over 1,000 people in the US are saying they have streaming and login issues with the Spotify rival, which is bad news for those who were looking for a nice soundtrack to get them through this very turbulent Monday.
This could be related to a rather worrying spike for Amazon Web Services on Downdetector, which has been joined by an update about "significant API errors" on the AWS dashboard.
How rare is today's outage?

While the scale of today's AWS-related issues are unusual, with over 1,000 businesses hit by the knock-on effects, it certainly isn't unprecedented.
Steve Sandford (Partner – Digital Forensics and Incident Response at data protection consultants CyXcel), told us: "While AWS outages are relatively rare, they are not unprecedented. Historical data shows that major outages occur several times a year, often concentrated in high-traffic regions like US-EAST-1".
"There is no clear evidence that the frequency is increasing, but the impact is growing due to the expanding reliance on cloud infrastructure. This vulnerability is compounded by the fact that the cloud market is dominated by a select few players – with AWS and Microsoft Azure commanding the largest share across the world outside China," he added.
Questions about this over-reliance on a few players will be asked after today, but easy answers won't be forthcoming – after all, only a handful of companies can provide this infrastructure on this kind of global scale.
AWS is making slow progress

The latest update from the AWS dashboard is that the engineers have "applied multiple mitigations across multiple Availability Zones (AZs) in US-EAST-1", which is the region hit by the problems.
While that sounds good, the update adds that AWS is "still experiencing elevated errors for new EC2 instance launches" and that it is "rate limiting new instance launches to aid recovery".
In other words, the 'instances' (or virtual servers) that have been spun up to replace the problematic ones are still hitting problems, so Amazon is throttling them to prevent its platform from being overwhelmed.
We'll have to see what impact this has, but it's likely to mean further issues for many apps and websites that rely on AWS – and as we've seen today, there's a lot of those. AWS says it'll provide another update at 7.30am PDT / 10.30am ET / 3.30pm BST.
Wordle has log-in issues

We may have spoken too soon about Wordle being fixed earlier – some fresh issues with the New York Times' gaming site are causing problems for some, and those are being reflected on Downdetector.
As some users (below) have reported, logins for NYT Games appear to be impacted – and that's backed up on Downdetector, where 73% of the reported issues are about logins.
There's been no official update from the New York Times yet, but those with lengthy streaks to protect will be hoping it gets fixed soon.
@NYTGames are your servers down? I have a games subscription but am not able to login and view my wordle/connections/strands streaks or even the archiveOctober 20, 2025
Chime and Starbucks on the rise
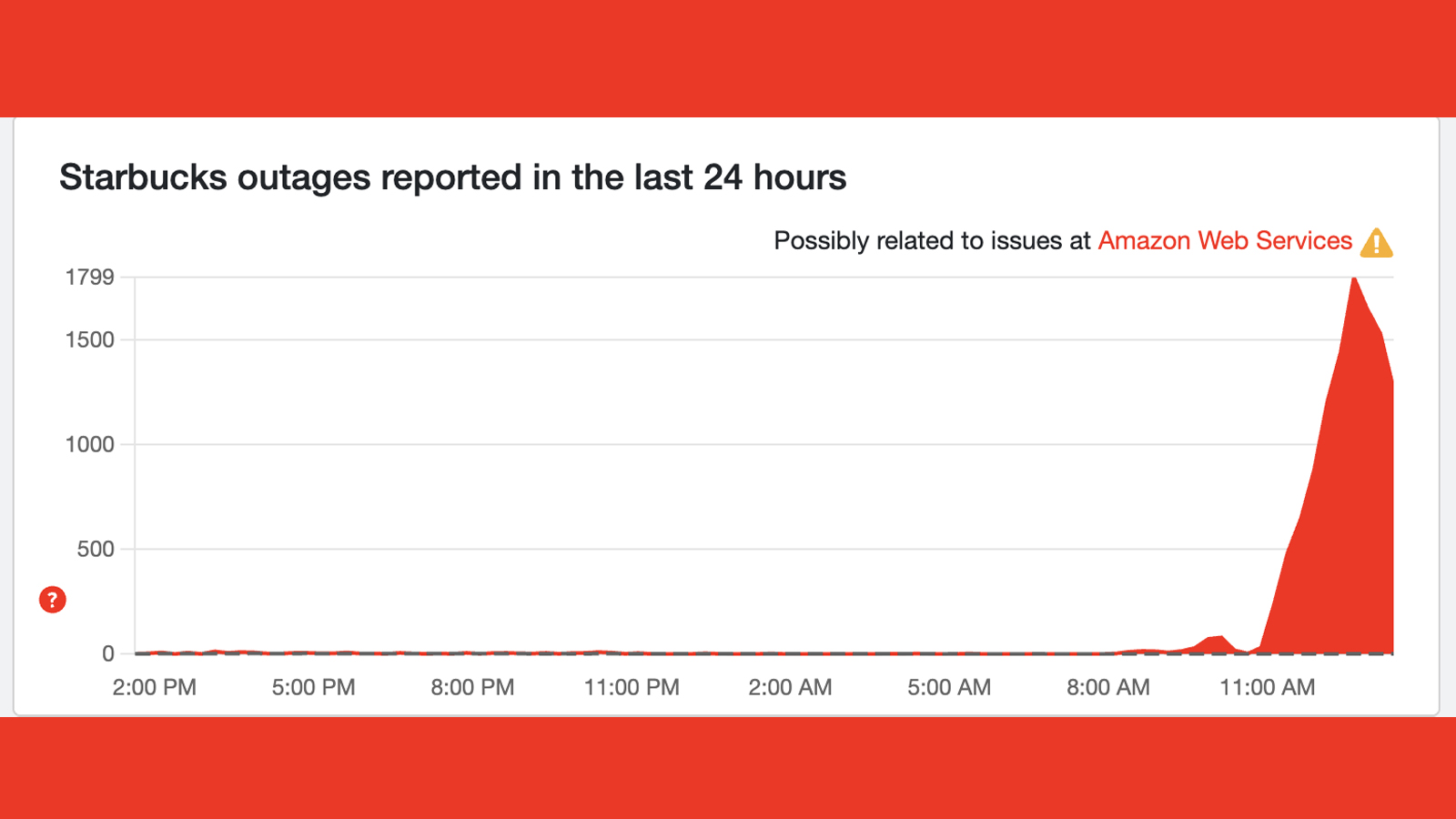
Two services that have gone a little under the radar during today's AWS outage, but are now spiking considerably, are Chime and Starbucks.
The good news if you use Chime's mobile banking is that it's now marked as "all systems operational" on its status page, despite previously reporting a "third party outage". The dashboard now says, "this incident has been resolved", so that Downdetector graph should (in theory) start coming down soon.
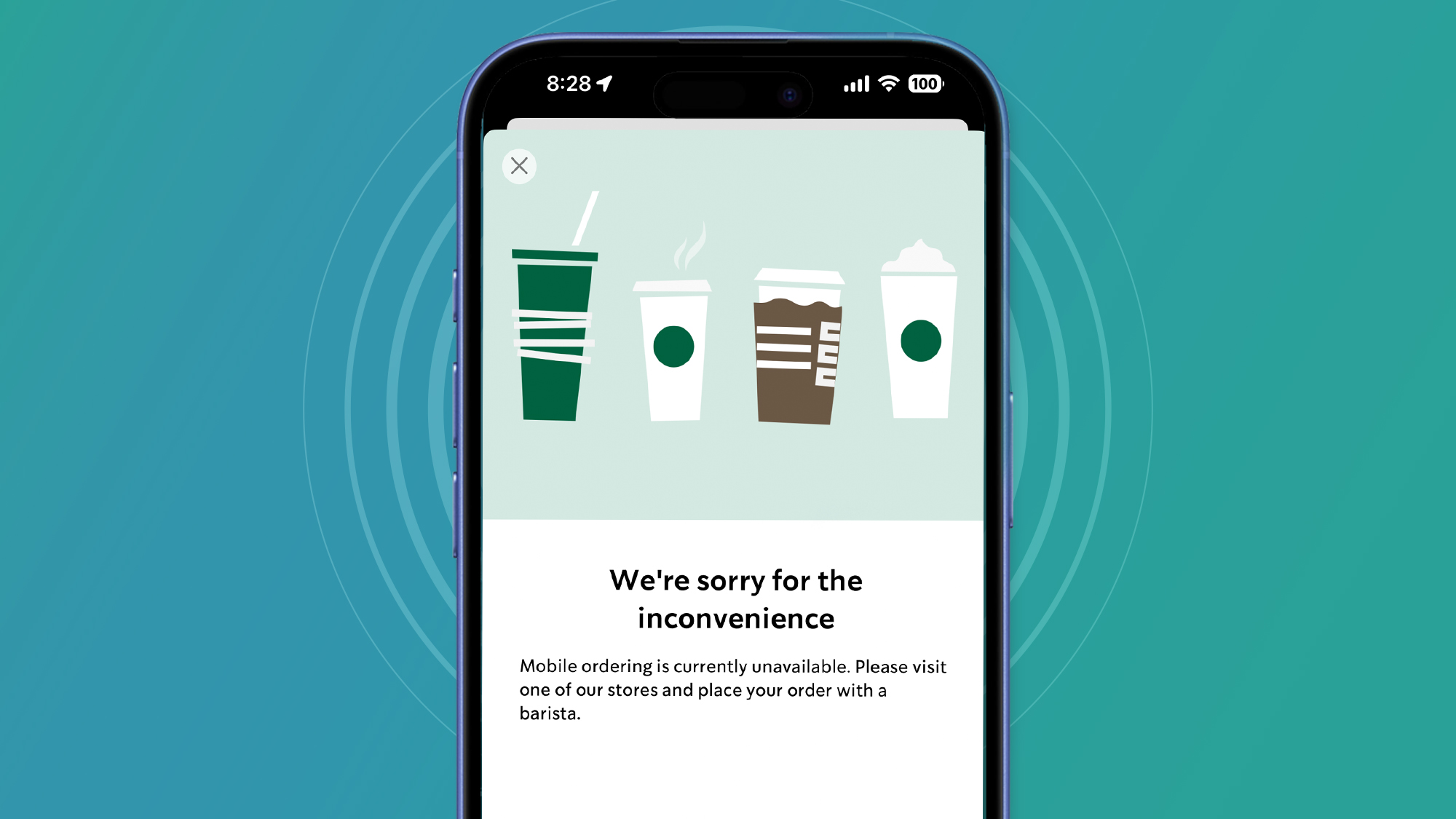
Equally serious for coffee lovers, though, is that the Starbucks app has also been, shall we say, burnt by today's AWS issues. Right now on Downdetector, over 1,500 people are reporting that they can't use the app to pre-order their drinks or get reward points – and that's something we've also discovered (below).
For a Monday morning, that's incredibly harsh news – but that Downdetector graph is now at least moving in the right direction...
Ouch – more than 1,000 companies hit today
Time for a little context on the enormous scale of today's AWS outage. Downdetector has told the BBC that the total number of reports on issues has risen to over 6.5 million, with more than 1,000 companies hit. That will have some serious financial repercussions.
In the UK, where reports have been particularly high due to timezones, the site has apparently received over 800,000 reports, which is five times the number it usually sees on the average weekday.
In terms of scale, the closest thing I can remember to this AWS earthquake is the great Crowdstrike outage of 2024, which was estimated to have caused upwards of $5 billion in damages. Let's hope those AWS engineers can work through that backlog of issues sharpish...
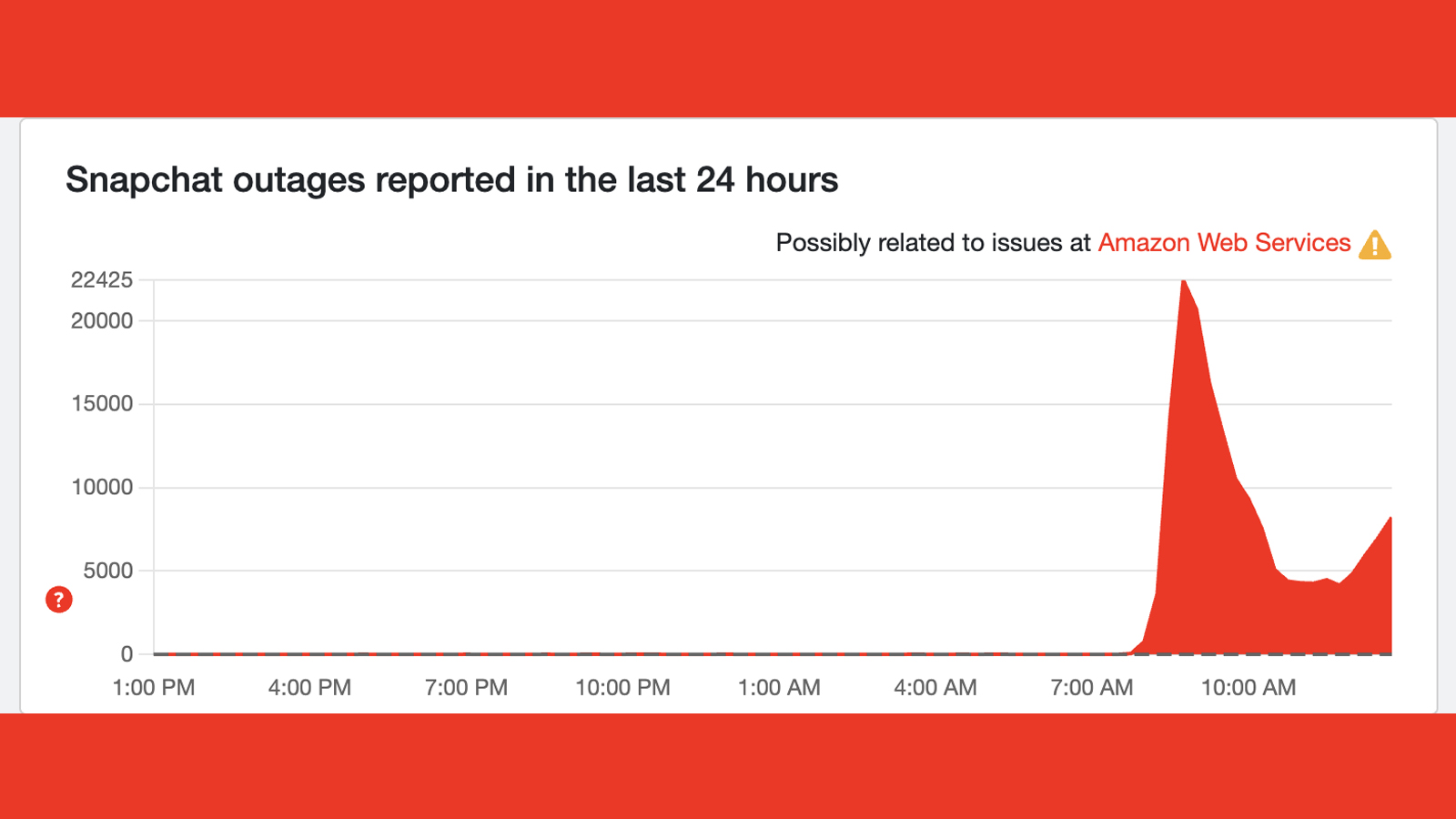
Snapchat is still struggling

Snapchat has been, in pure numbers on Downdetector, one of the worst hit by today's big AWS outage. At 3.44am ET / 8.44am BST, it hit over 22,000 reports in the US on Downdetector (and over 7,000 reports in the UK).
Thousands of users were hit by the error message "Due to repeated failed attempts or other unusual activity, your access to Snapchat is temporarily disabled. Please try again.”
While it's now working fine for some of us on TechRadar, others are reporting that they can't even log into the app. There also appears to have been another spike in problems according to Downdetector (below).
It's now back up to over 8,000 reports in the US, suggesting the issues could run for a little while yet. There's been no official comment from Snapchat, but I'll update this liveblog as soon as there is.
Ring problems are spiking again
Now that Reddit is fixed, Ring appears to have taken the baton and started spiking again on Downdetector – it's now at almost 4,000 reports in the US and 2,600 in the UK, one of its biggest outages this year.
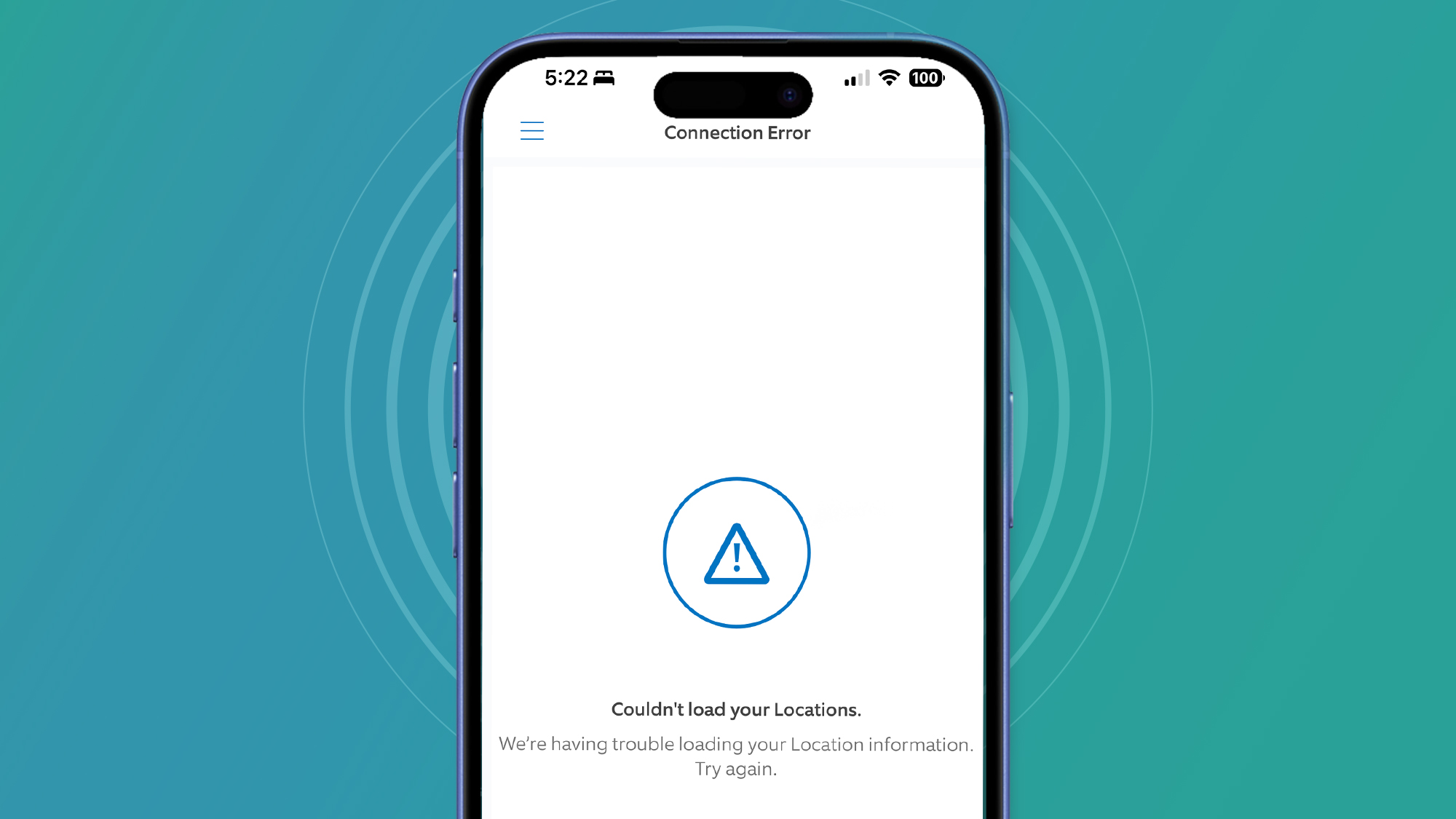
There's been no official response or update from Ring on social media, but it's probably fair to say the Amazon-owned security company has caught the same AWS flu as dozens of other services today.
The app still isn't working for us, showing a "connection error" with a message saying it "couldn't load our locations". That's a problem for the many who now rely on Ring doorbells and security cameras for safety. AWS, meanwhile, says it's continuing "to work to fully restore" the services that much of the internet relies on...
All is well again – Reddit is back
Monitoring: A fix has been implemented and we are monitoring the results. https://t.co/5frljn4BPMOctober 20, 2025
It's been a hard enough morning for us all without Reddit also going down, but fortunately the self-style "heart of the internet" appears to be back to full health.
It's now working for us in web browsers and the app has spring back into life. This is also reflected on Downdetector where reports have dropped to well under 1,000 in the US and UK, from a peak of 12,000 in the US at 6.12am ET / 11.12am BST (a time which will henceforth be marked with a minute's silence).
The Reddit Status account on X (below) has also said that "a fix has been implemented and we are monitoring the results". Now we just need engineers to fix the likes of Ring, which is spiking again – alongside (gasp) the Starbucks app...
An update from AWS

There's been a slightly less confident-sounding update from the AWS dashboard on today's outage.
At 4.08am PDT / 7.08am ET / 12.08pm BST, a new post says "we are continuing to work towards full recovery for EC2 launch errors, which may manifest as an Insufficient Capacity Error". It adds that "additionally, we continue to work toward mitigation for elevated polling delays for Lambda".
EC2 is short for Elastic Compute Cloud, which provides virtual servers (otherwise known as 'instances') in the cloud for running apps and hosting data. That'll explain why so many apps, like Snapchat, are continuing to report issues. Similarly, Lambda hosts a service's source code, only running it when there's a request made for it.
In short, we can expect the impact of this to run for a little while longer...
Reddit is behaving very strangely

Reddit is turning into one of the major casualties of the big AWS outage – not only is the website down, the app is also doing some very strange things (in between not working for us at all).
TechRadar Managing Editor Matt Bolton says the most unusual part is that that it keeps popping up messages saying it’s rate-limiting him for increasingly long periods. Rate-limiting is something services do if they think they're being DDoS attacked – they see an abnormally high number of requests coming from one device or IP address, so they create a big delay in how often that device is allowed to access their servers.
We're guessing this means the Reddit app is struggling to connect to the service due to the outage, and is making lots of calls to the service in an attempts to fix it, and Reddit is viewing its own app as malicious actor. That would also explain why the app is struggling to find subreddits like Sonos (above).
Still, white the homepage is down for us, we have been able to get to posts by Googling a term with Reddit results, which at least means the website is still working behind the error messages...
Investigating: We're experiencing an elevated level of errors and are currently looking into the issue. https://t.co/6IyHu46clbOctober 20, 2025
Duolingo streaks are at risk

Among the apps hit by the AWS outage is Duolingo, and Senior Staff Writer Hamish Hector is worried this outage could end his longrunning streak if it goes on for too long.
The slight silver lining is he can continue his lessons with offline mode, and if the outage does end soon his offline learning should count towards his once-a-day target to keep growing his lessons counter.
With possible causes being investigated, it sounds like the outage might not last too much longer – and unlike Reddit, Duolingo's outage graph is fortunately now trending in the right direction on Downdetector...
One of the worst Reddit outages for a while
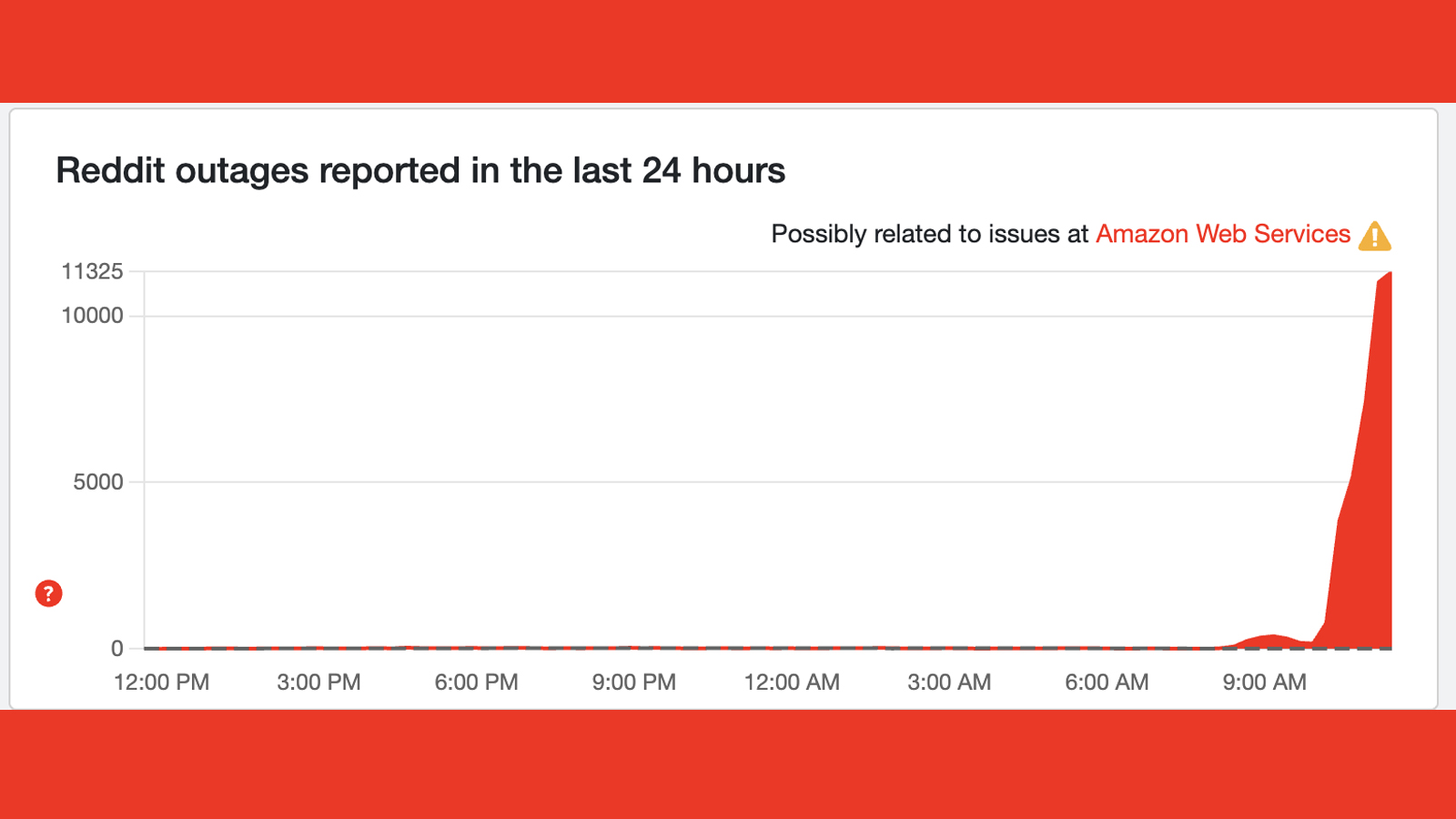
So, what's the state of play in The Great AWS Outage of 2025?
While many services appear to be recovering, with Downdetector graphs moving in the right direction (including Snapchat, Ring and AWS itself), Reddit is bucking the trend by continuing to spike upwards.
The homepage is now completely down for me in the web browsers (showing a "too many requests" error) and the mobile app similarly borked showing a "your request has been rate limited".
A Reddit post on X says "we're experiencing an elevated level of errors and are currently looking into the issue". There's no comment on a cause, but it must be AWS-related surely...
Any signs of a cyber attack?

Internet outages on the scale of today's AWS one usually spark concerns about cyber attacks. But once again, a more boring, infrastructure-related issue appears to be to blame.
The Amazon Web Services dashboard says that "the issue appears to be related to DNS resolution of the DynamoDB API endpoint in US-EAST-1", which in simpler terms means a problem between the 'domain name servers' (which translate IP addresses) and the interface that sits between clients and servers (APIs).
As Rafe Pilling (Director of Threat Intelligence, Sophos) commented: "When anything like this happens the concern that it's a cyber incident is understandable. AWS has a far reaching and intricate footprint, so any issue can cause a major upset. In this case it looks like it is an IT issue on the database side and they will be working to remedy it as an absolute priority."
That appears to be the case, with the AWS dashboard stating "we continue to observe recovery across most of the affected AWS Services". Many sites and services, like Reddit and Ring, do continue to experience major issues.
Good news, everyone – Wordle is back!

If you've been worrying about getting your daily Wordle fix, then fret no more – because the mega-popular online word game is back.
The site, which lives on the New York Times' gaming site, was hit by the AWS outage earlier today, with users unable to log in. So, while they could complete the day's game, it wouldn't count towards their streak – a feature which is of vital importance to many Wordlers.
Everything appears to be working normally again now, though, so you can go ahead and attempt today's puzzle. Just be sure to you check out our Wordle today page for hints and discussion of the game first.
Disaster, now Reddit's down

The place we all go for refuge when there's a big internet blackout is sadly also been hit by the AWS storm – now Reddit is showing large spikes on Downdetector.
I'm getting a "too many requests" error on the homepage and so are thousands of others, with over 6,000 reports in the US and over 3,000 in the UK.
In fact, the Reddit graph is bucking the trend of other services, which are showing a downturn in problems, whereas Reddit's continues to spike upwards. Signs of a different problem? It's more likely to be Reddit's core audience waking up to today's bad news...
The worst may be behind us...
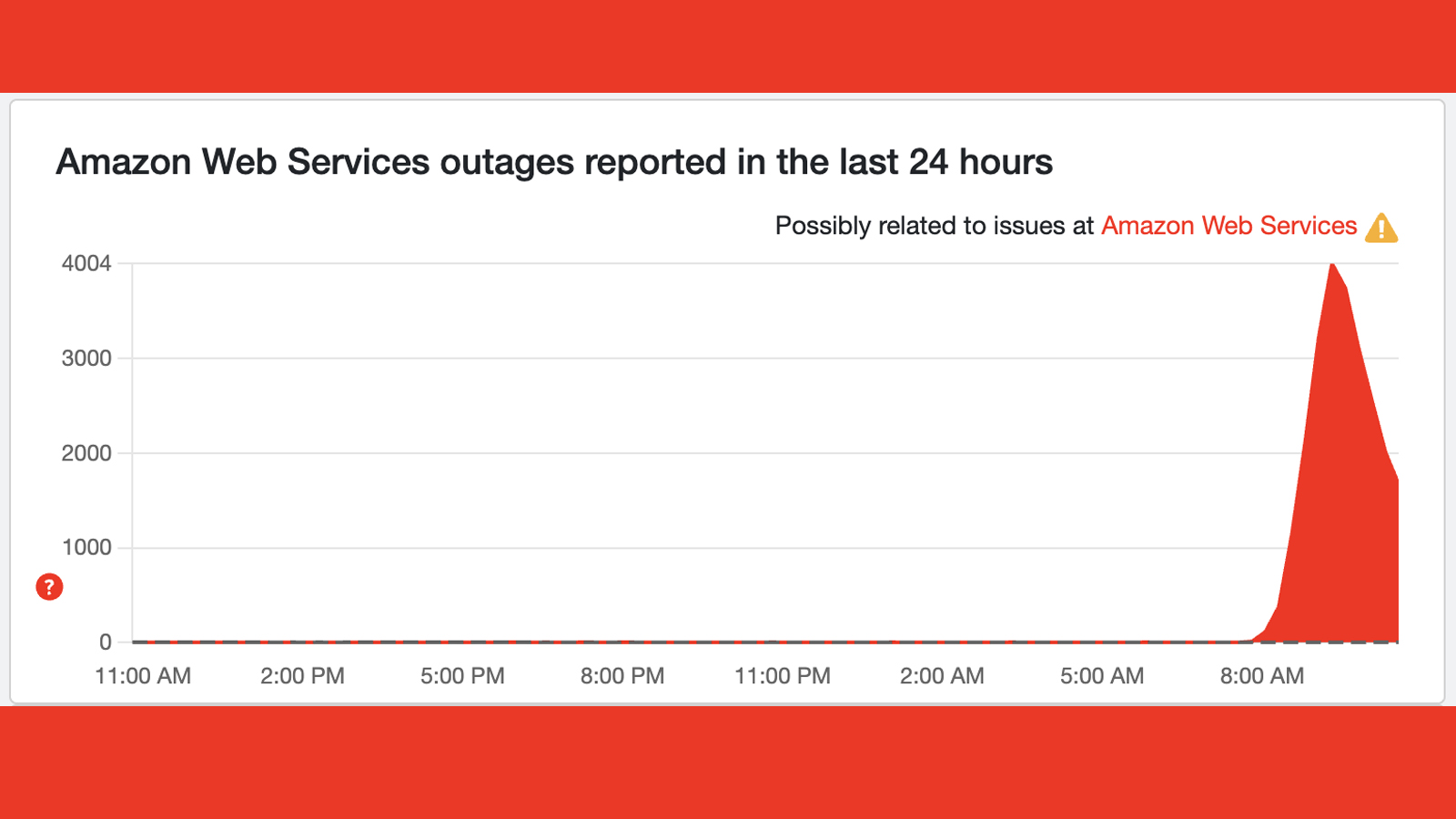
That promising update from AWS (below) is reflected on the Downdetector graph for Amazon Web Services, which is the epicenter of today's internet earthquake.
At is peak in the US at 3.52am ET / 8.52am BST, the AWS graph had almost 6,000 reports in the US and 4,000 in the UK. But that's now down to around 2,000 and 1,500 reports respectively, suggesting that those "significant signs of recovery" are being felt in the real world.
Similarly, Downdetector graphs for other services are also showing a dip, which means the end of this major outage could be in sight...
Strava hits the AWS wall
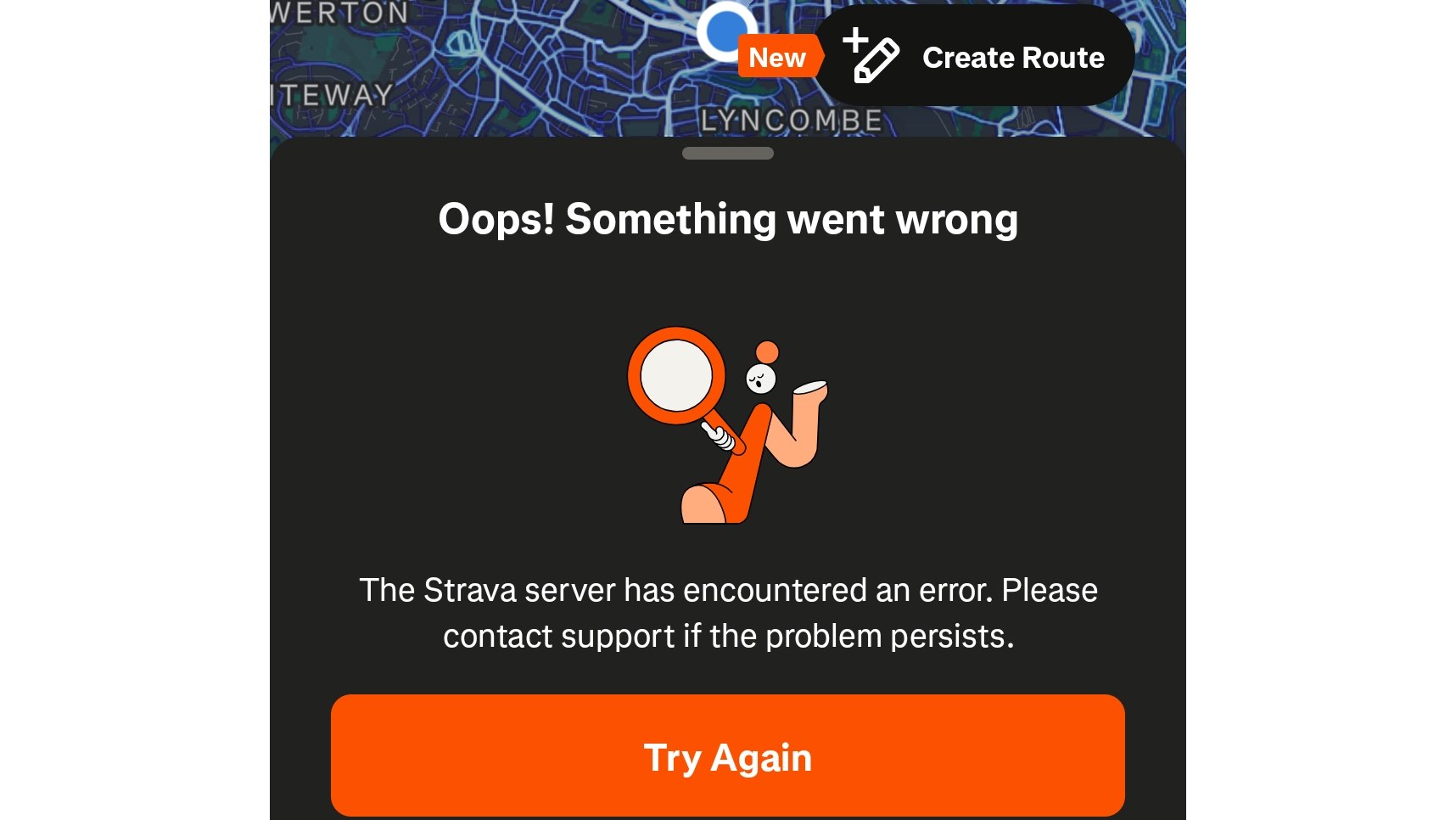
Fitness app Strava is also experiencing server issues. Strava users might be seeing the following message: “The Strava server has encountered an error. Please contact support if the problem persists.” Unfortunately, as Strava runs on AWS servers, contacting support won’t do very much at all.
Matt Evans, TechRadar's Senior Fitness & Wearables editor, says: "I can still look through my timeline, view my profile, and interact with friends’ posts, but the app is a little sluggish: 500 errors frequently occur when refreshing pages, and my latest activity, logged on my Garmin watch, hasn’t uploaded to Strava.
"Coincidentally, Garmin Connect also runs on AWS servers, but loading and navigating the app, I haven’t seen any problems so far. It’s hardly critical infrastructure like banks, but concerned athletes should rest assured that this isn’t an issue on Strava’s end."
'Significant signs of recovery'
Some good news, potentially – Amazon Web Services has just provided another promising update.
Its latest post, from 2.27am PT / 5.27am ET / 10.27am BST, says: "We are seeing significant signs of recovery. Most requests should now be succeeding. We continue to work through a backlog of queued requests. We will continue to provide additional information".
My takeaway from that (and the evidence on Downdetector) is that we're past the worst of the earthquake, but aftershocks and problems could still continue for a while yet...
Tidal is out – Monday morning playlists ruined
Ugh, when your favorite music streaming service is out for the count any way you want it (that's the way you need it) on a Monday morning.
Becky Scarrott, TechRadar's audio editor, reports: "I'm TechRadar's audio editor and the time of writing, Downdetector's list of Tidal outage reports has tipped 337 entries, with 63% listing app issues (which makes sense, because that's how most people access music on the fly – ie. their commute), 15% noting the website isn't letting them in (it isn't for me) and 22% mentioning the server connection.
"I initially got the wheel of death on the app, then a crash. And when I tried to click back into the Tidal app, a '504 Gateway Time-out' message appeared, after I was prompted to log in.
This is of course related to AWS's "operational issues", and let me tell you, my operational issues are also affected when I can't get my Monday morning playlist going…"
We may have a cause

An update on the AWS Dashboard at 2.01am PDT / 5.01am ET / 10.01am BST may have given us some good news.
It says "we have identified a potential root cause for error rates for the DynamoDB APIs in the US-EAST-1 Region".
Leaving the technical details aside, the most important part is that AWS says it's "working on multiple parallel paths to accelerate recovery".
AWS has promised another update by 2:45am PDT / 5.45am ET / 10.45am BST. Until then, expect to see a lot more error messages on your favorite services...
Ring owners are very confused right now

The AWS outage has rippled far and wide across the internet, but some of the biggest hit have been Amazon's own services like Alexa and Ring.
For many, Ring cameras have become intertwined with their daily schedule – and that's now been massively disrupted today, as TechRadar's Senior Writer AI told me.
"Every morning I go for a coffee before work, taking the dog a walk around the block before sitting at my desk for the day. Normally, my smartphone gets bombarded with Ring doorbell notifications from the busy neighbors moving in and out, as I pay close attention to the app waiting for the postman.
"Today, however, until I realized that AWS services were down I just sat confused as to why the normal morning ruckus of the school run wasn't happening. I work with headphones on and rely on Ring to know when to open the door for the postie before my dog gets alerted by their presence.
"With Ring struggling this morning, I'm going to have to stay ultra aware as I wait for the knock on my door, fully accepting that my tiny French Bulldog is going to go crazy at the thought of an intruder.
"Millions of people rely on Ring for security and safety concerns, while others just need the video doorbell for simplifying life and knowing when mail has been delivered. My Ring doorbell is one of the best tech purchases I've ever made, and that's only emphasized when it stops working and I can't go about my day the way I usually would", he said.
Who is affected?

The easier question for today's AWS outage might be 'who hasn't been hit'?
Right now on Downdetector, we're seeing large spikes on dozens of services. On the more serious side, this includes Zoom, Slack, Blink Security, Venmo and, in the UK, Lloyds Bank, Halifax, HM Revenue & Customs, Bank of Scotland and more.
But the AWS earthquake is also rippling through Snapchat, Roblox, Fortnite, Duolingo, PlayStations Network and yes, even Wordle.
Even Downdetector is showing a rare red banner showing the severity of the Amazon Web Services outage in the US-East-1 region. We should get another update on the AWS Dashboard soon...
Your bank may also be hit
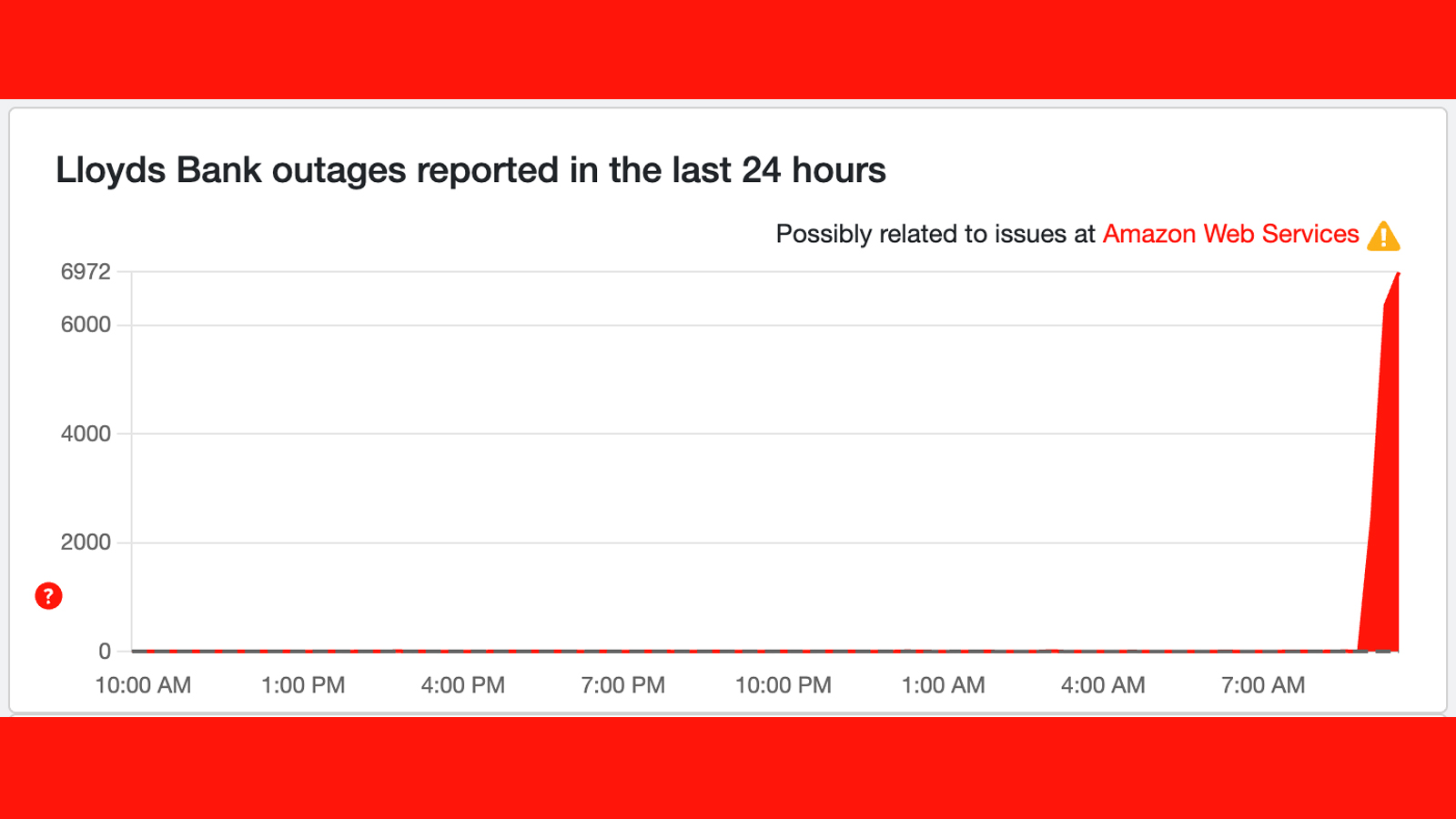
While the problems with our Echo devices this morning are annoying, a more serious repercussion from the AWS outage for many will be that multiple banks have been hit.
In the UK, Downdetector is showing large spikes on Lloyds, Halifasx Bank of Scotland and even HM Revenue & Customs. It just shows how deep and wide the Amazon Web Services infrastructure is, and how badly the internet is affected when it runs into rare problems.
The latest from the AWS dashboard at 1.26am PDT / 9.26am BST is that "significant error rates" are happening in the 'US-EAST-1 Region' and that "engineers were immediately engaged and are actively working on both mitigating the issue, and fully understanding the root cause". Let's hope they do that sooner rather than later...
This explains those Alexa issues

While it's unlikely to be the most serious issue today, the first time many saw the impact of the Amazon Web Services outage was with its Alexa voice assistant.
This Reddit thread shows many were recently reporting problems with the assistant, with some saying they "had to turn the lights off manually" and couldn't set their alarms.
Well, AWS is the root cause – and Alexa is far from the only service experiencing problems. Alongside Ring, Snapchat and Zoom, we're also seeing banking apps like Lloyds and Halifax in the UK and Robinhood in the US showing large spikes on Downdetector...
This is an online earthquake

The Amazon Web Services (AWS) outage started at around 7.40am BST, according to Downdetector – and the ripple effect has taken out much of the internet.
Right now, Alexa, Snapchat, Ring, Roblox, Fortnite, Zero, Signal, Canva and countless others are showing huge spikes in reports on Downdetector.
The problems show just how many services rely on Amazon's cloud computing services. The AWS Health Dashboard is showing an "operational issue" in North Virginia that's producing "increased error rates and latencies". This is going to have serious repercussions today for millions...


