.png)

last updated: Jul 27, 2025
One of the tasks that I do most often is to review code. I've written a review command that asks an AI to review a code sample, and I've gotten a lot of value out of it.
I ignore most of the suggestions that the tool outputs, but it has already saved me often enough from painful errors that I wanted to share it in the hope that others might find it useful.
How to install it
- install llm and configure it to use the provider and model you'd like to use
- on a mac, brew install llm
- optionally install bat
- on a mac, brew install bat
- save the review script anywhere on your path and make it executable
How it works
The main job of the script is to generate context from a git diff and pass it to llm for code review.
If you run review with no arguments, it will:
- run git diff -U10
- the -U argument changes the amount of context given in a git diff
- any additional arguments you pass will be forwarded directly to git diff
- estimate the tokens in the output and check if that fits within the context window
- shrink the context window if necessary and re-run git diff
- if you want to manually expand the context beyond 10 lines
- you can append to the system prompt with the --context flag
- you can expand the diff context to 100 by passing -U100 or any number you prefer
- pipe the context to llm
- You can configure llm to use whichever model or AI company you prefer
- highlight the output with bat if available
- bat is great and I highly recommend using it if you don't already. brew install bat on a mac will install it
The result looks like this in my terminal:
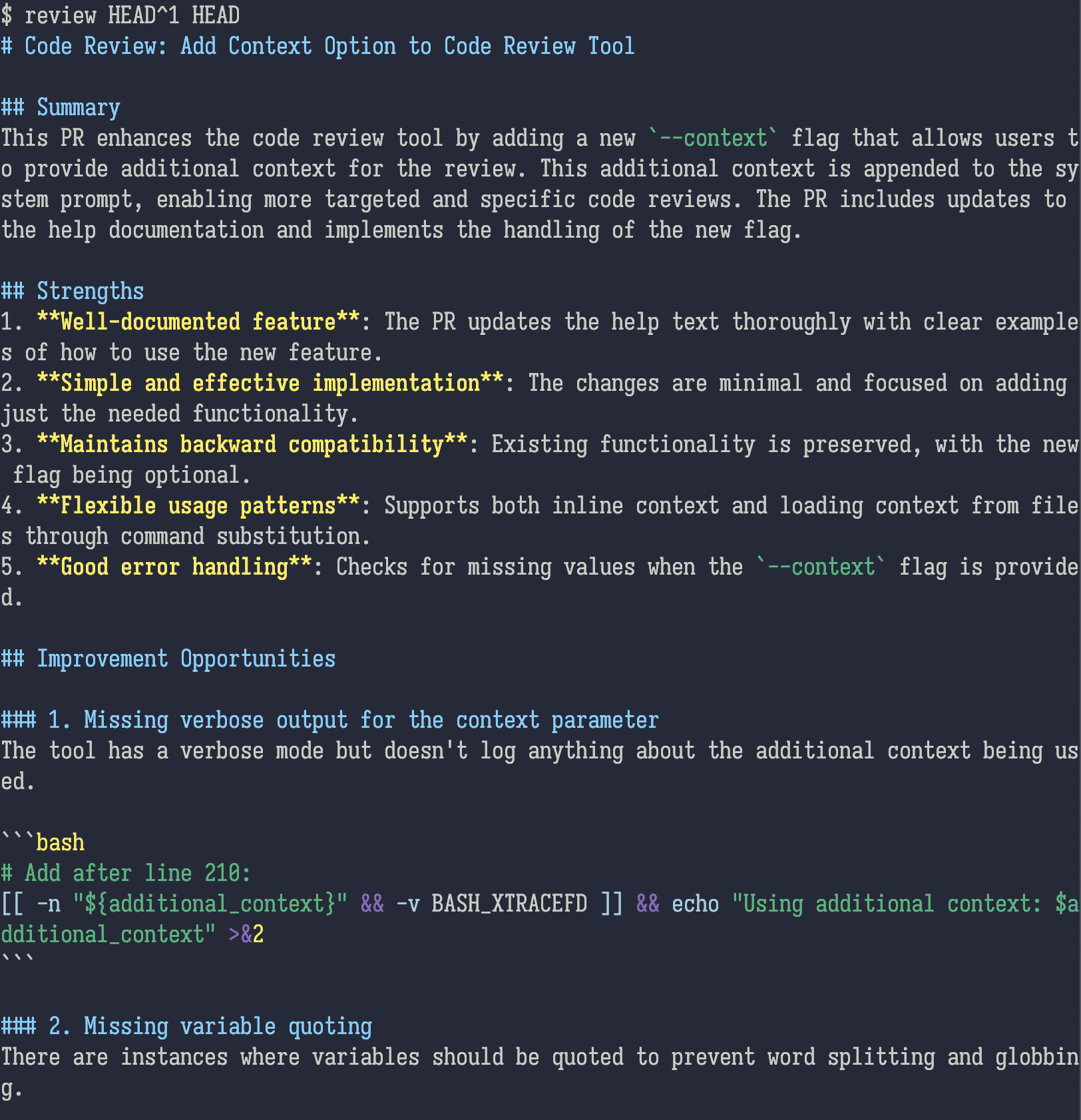
How I use it
My main use of the command is to review a PR I'm preparing before I file it. The biggest value I've gotten out of it is that it frequently catches embarrassing errors before I file a PR - misspellings, DELETEMEs I forgot to remove, and occasionally logic errors.
It also often suggests features that make sense to add before finishing the PR, or as next steps.
It is very important to use it intelligently! The LLM is just an LLM, and it also may be missing context. The screenshot above has two examples of mistaken suggestions that I read and ignored; you have to apply your own understanding and taste to its output.
Keep in mind that it is tasked via its system prompt with finding problems and making suggestions; no matter how good your code is it will try to find and suggest something.
I also use it for reviewing other people's PRs, with review origin/main origin/some-feature-branch. In these cases, I really am just using it for clues as to some things that I may need to investigate with my actual human brain. Please do not just dump llm suggestions into a PR! That's both rude and likely to be unhelpful.
How it differs
That last point brings me to why I prefer this tool to github's own copilot review tool.
- I can use my review tool in private, and evaluate its suggestions in private
- I can run it repeatedly as I change the code
- The separation of my terminal from the code review tool provides a space for me to apply critical thinking
Areas for improvement
- A lot of things are hard-coded into the script, because I'm its only user
- If you find use in it, please let me know!
- the system prompt seems to work fine, but the range of possible system prompts is so large that I'm sure it could be better


