.png)

After months of silence followed by a few very cool blog posts, Mira Murati's very expensive AI lab, Thinking Machines, just released its first product. That product is a language model fine-tuning API called Tinker. Tinker is very different from any fine-tuning service I've seen, and as someone who spent the better part of a year working on an LLM fine-tuning, I wanted to share my initial thoughts. Despite the provocative subtitle, my reaction is positive—Tinker is unique, shows promise, and most importantly, reveals some interesting details about how frontier labs offer fine-tuning services at scale.
When I built an LLM fine-tuning service in 2023, we did it the "regular" way. Reinforcement learning wasn't mainstream yet, LoRA and QLoRA had just been introduced, and the main paradigm was supervised fine-tuning, which teaches a model to mimic pre-written responses from a training dataset. To use the service, a customer would upload a dataset, with columns like "prompt" and "response", and select a base model, like Llama-2 7B (which at the time, was considered a good model).
Our service would format this data into a "conversation", turn it into tokens, grab a GPU from Modal Labs, download the base model weights, and update the model with cross-entropy loss, teaching it to assign a higher probability to the provided responses. Sometimes, to save memory, we might use LoRA, which uses low-rank updates to modify just a fraction of the original model's weights. For heftier models, we might even use QLoRA, which stores the base model's weights as 4-bit or 8-bit numbers, trading some precision for memory.
To get good performance, it was important to ensure no computation was wasted. Over-long sequences were trimmed, short sequences could be "packed" into one batch, batch size was painstakingly selected to use as much of the GPU as possible, but not enough to go "out-of-memory" (OOM). Metrics were logged, updated in a live dashboard, and at the end, model weights were uploaded to HuggingFace, where they could be downloaded or inferenced for testing.
All in all, it was a neat product, and the first I ever built as a startup founder. It was completely unsuccessful, in no small part because it required the customer to provide good data, and no one really knew how to do that. Other folks like OpenPipe got a bit further by helping customers collect data from their OpenAI models running in production, then using that to train smaller models to save money.
That was LLM fine-tuning in 2023.
On first glance, everything about Thinking Machines' Tinker API flies in the face of conventional machine-learning practice and the lessons I learned. Tinker exposes a handful of very low-level functions to the user:
- sample: Provide a prompt and sample a completion from the current model.
- forward_backward: Send a single batch of data through a model, compute the loss and gradient.
- optim_step: Update the weights of the model based on those gradients.
These low-level primitives let you do supervised fine-tuning, much like my API did. But sample also gives you the power to do online reinforcement learning: take a completion from the current model weights, score that completion, and update the model based on whether that completion was good or bad. Supervised fine-tuning teaches the model to mimic pre-written responses; online RL improves it by scoring its own responses. This is very useful for domains where it's easier to score an AI-written answer than to write one, or where there's many good answers for a given prompt.
But this powerful, low-level API also has one (apparent) glaring issue: each training step requires sending a batch of data over the network. The number one rule of modern deep learning is that you MUST feed the GPU. Any nanosecond where the CUDA cores (and now, the tensor cores) aren't saturated, is a nanosecond wasted. So machine learning practitioners obsess over all the details to make sure nothing gets in the way of feeding tokens to the GPU: pre-downloading all the data so network overhead doesn't bottleneck training; tokenizing data offline so feeding the model isn't slowed by CPU-intensive tokenizers; writing kernels to fuse operations and reduce launch overhead; screaming at their GCP reps when they get a GPU node with bad interconnect... you get the picture.
Tinker does not let you pre-upload a dataset; you MUST (as far as I can tell) send each batch of data over the network, introducing minimum ~100ms of latency per step, and probably more, since tokenized data makes for a relatively large payload. In GPU-land, a few hundred milliseconds could be an entire forward pass, or at least a non-trivial fraction of one. A naïve observer might see this, and conclude that the good folks at Thinky have lost their Thinkers. But dear reader, if you Thinked that, maybe it is you who has another Think coming.
If you were doing a fine-tuning run, and you decided to introduce 200ms of overhead into each step, it would be a bit dumb at best, and a total disaster at worst, depending on the size of the model. If you were training a sub-billion parameter model, it might slow you down by half. For a larger, slower model, it might matter less, but it would still lead to big time-slices where your GPU has nothing to do:
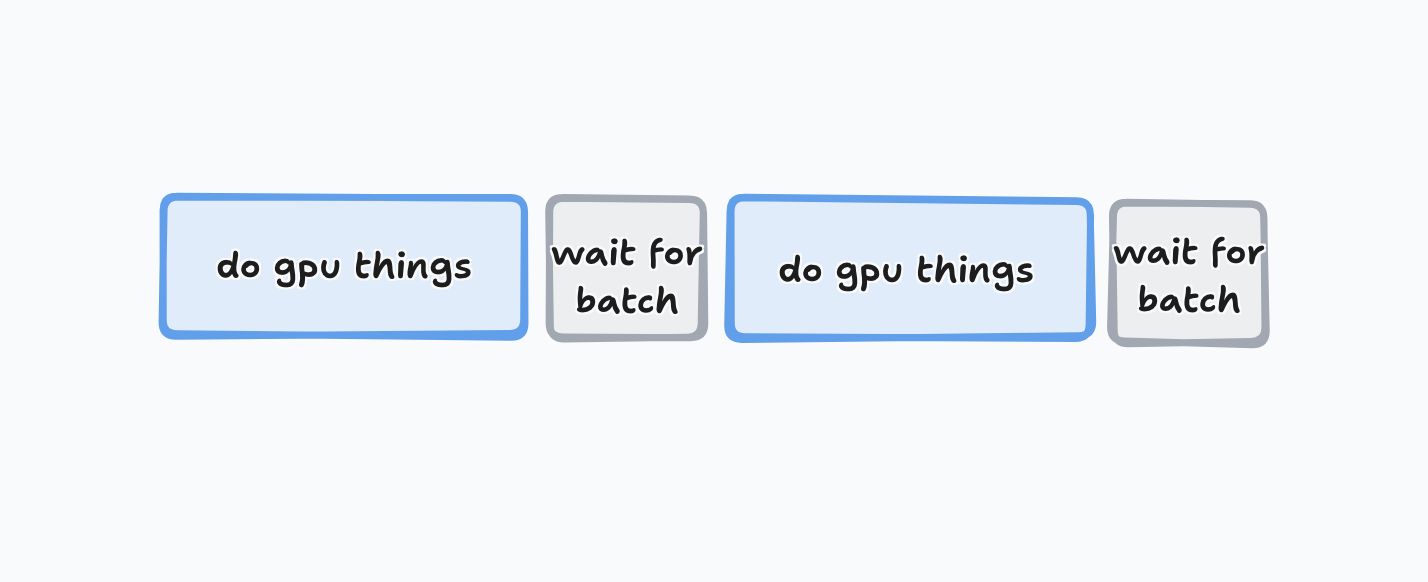
Tinker lets you queue up operations, though, so if you take advantage of async, you can queue up lots of forward_backward and optim_step operations, and end up with something more like this:
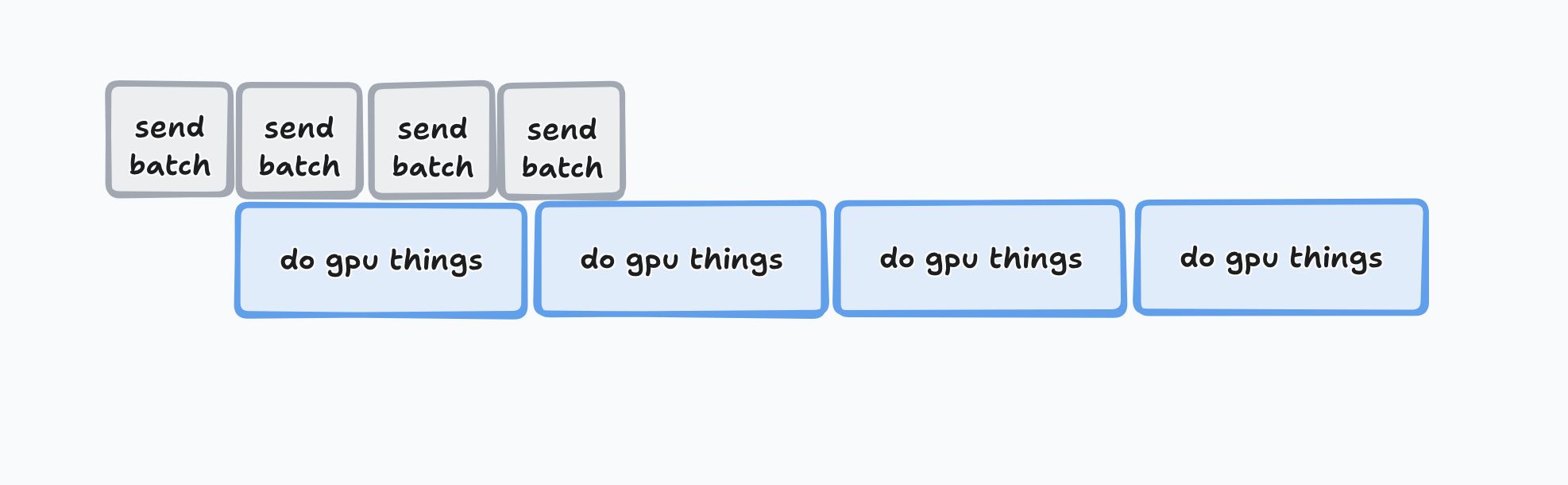
That depends on the end user using your API in a certain way to get good hardware utilization, though. And worse, it doesn't work for (online) reinforcement learning, where the completions aren't written in advance, which induces a strong serial dependency—you need the completion to score the completion, and for truly online RL, the completion must come from the most current model.
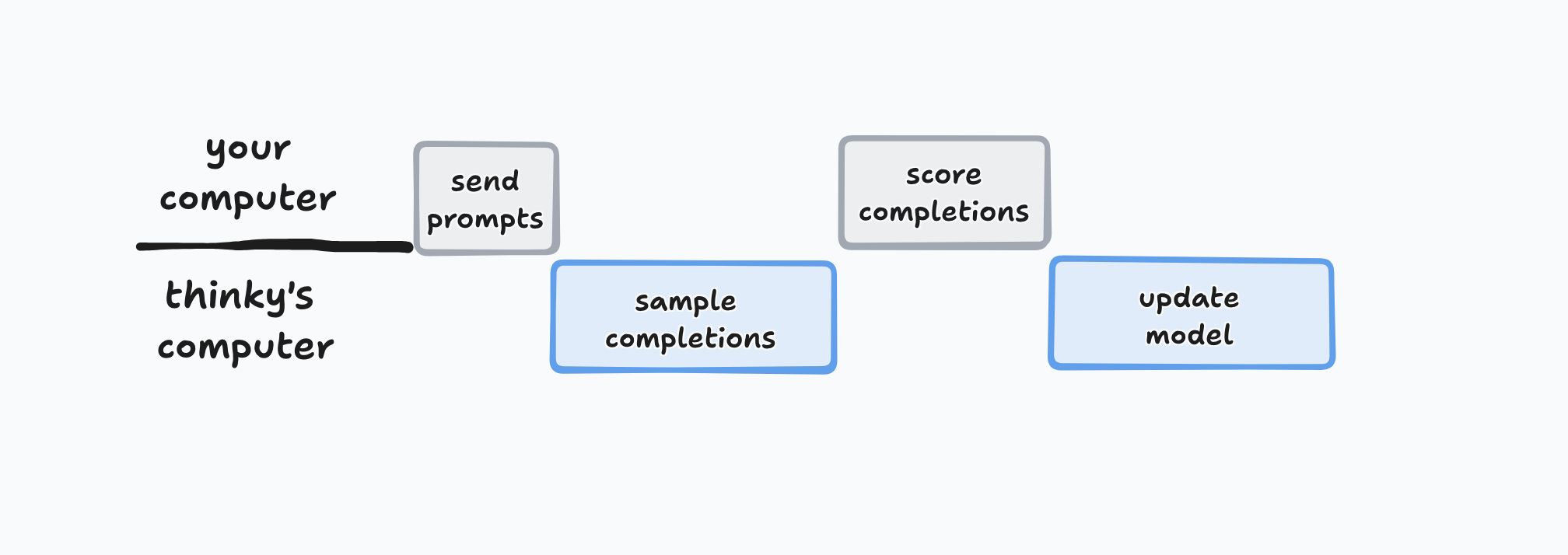
If this was all happening on one machine, the data-shuttling could be a rounding error, and the scoring could be lighting fast. Over the network (especially the dog shit Xfinity network that I have), these non-GPU steps are... non-negligible. Reinforcement learning as we know it today is already pretty damn slow, so you could just accept this and move on. But, my theory is that there's something cleverer happening. (Or there will be later, when they get around to building it.)
You see, this API is not for 1 person to train 1 model on 1 dataset. In that case, adding network latency is a pure loss. Once scaled, though, Tinker will have lots of people training lots of models on lots of datasets. Ordinarily, multi-tenancy is out of the question, because you can't just swap 1 model out for another (that takes seconds to minutes). But with LoRA, you can! LoRA adapters are 10-100MB, and can be swapped with sub-second latency. That means, with enough users, it could look like this:
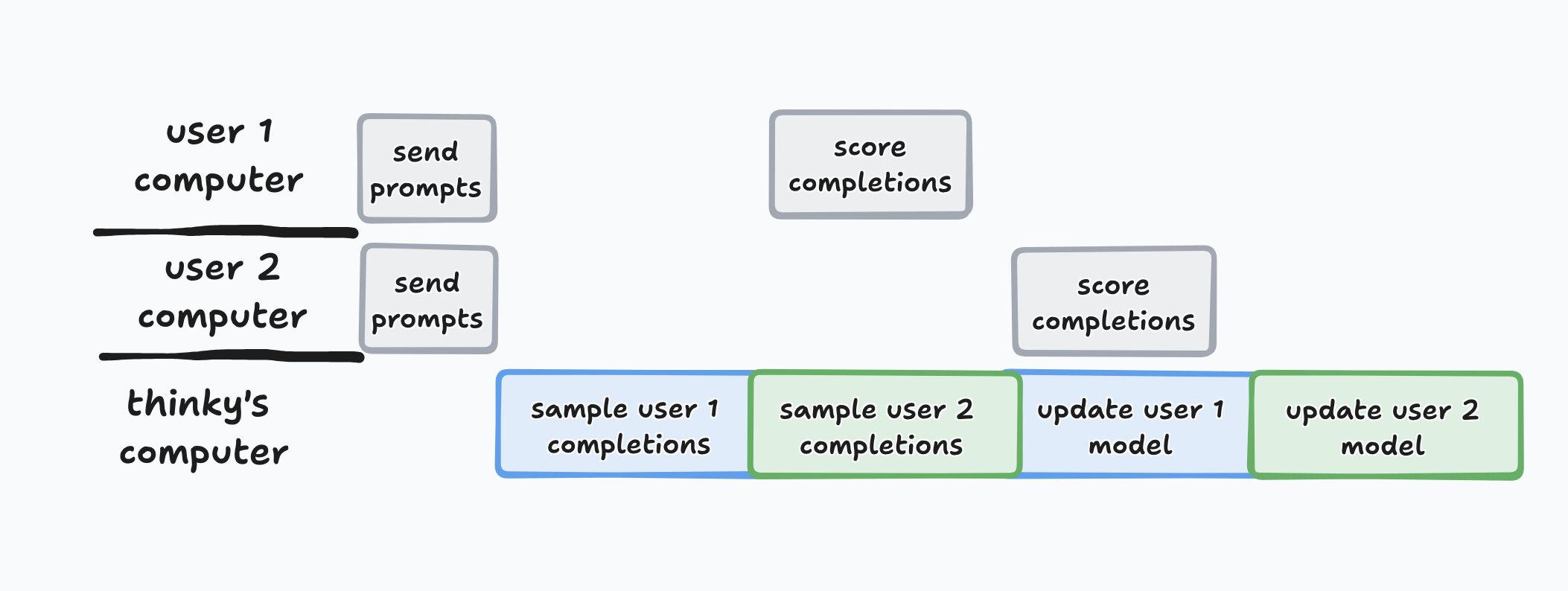
This ONLY works because (1) Thinky is using a small, standard set of open-source models, so they can have a warm pool for each model ready to go; and (2) Thinky is using LoRA, which lets them use ANY worker with the right base model for ANY user's sample or forward_backward request (optim_step doesn't require a base model at all).
I have no idea if they're actually doing this, but (to me) it's the only thing that makes sense. If I'm right, then full fine-tuning, when they offer it, should be much more expensive, or perhaps only offered to enterprise customers who are either bringing their own GPUs (which they are free to waste as they please). If I'm wrong, someone should yell at me and tell me I'm stupid!
I wanted to write about the Tinker API because it made me think about the question, "How would you set up a fine-tuning API in 2025, if you were smart?" I think what they're doing makes a lot of sense, especially if they believe that LoRA can produce results on par with full fine-tuning for common tasks (they do). It also sheds light on what might be happening inside other labs. It's quite obvious that OpenAI is using LoRA or something like it, because there's no other way to serve hundreds of thousands of custom models on demand with ~0 latency. LoRA lets different models share inference compute. But I hadn't considered the possibility that training runs could share compute too.
I'm also excited about this release because it has the potential to give everyone something closer to what frontier lab employees have: stable, mature infrastructure for RL and fine-tuning experiments. If you've talked to a lab employee, you know their stack is so mature that most employees don't touch a training loop. They make a JSONL or tweak some settings, click a button that launches an experiment on a giant cluster, and watch the lines go up. HuggingFace is nice, but I wouldn't call it "stable" or "mature." Thinking Machines could make it possible for anyone to be an AI researcher. That would be neat!



