.png)


Apple quietly dropped a new AI model on Hugging Face with an interesting twist. Instead of writing code like traditional LLMs generate text (left to right, top to bottom), it can also write out of order, and improve multiple chunks at once.
The result is faster code generation, at a performance that rivals top open-source coding models. Here’s how it works.
The nerdy bits
Here are some (overly simplified, in the name of efficiency) concepts that are important to understand before we can move on.
Autoregression
Traditionally, most LLMs have been autoregressive. This means that when you ask them something, they process your entire question, predict the first token of the answer, reprocess the entire question with the first token, predict the second token, and so on. This makes them generate text like most of us read: left to right, top to bottom.
Temperature
LLMs have a setting called temperature that controls how random the output can be. When predicting the next token, the model assigns probabilities to all possible options. A lower temperature makes it more likely to choose the most probable token, while a higher temperature gives it more freedom to pick less likely ones.
Diffusion
An alternative to autoregressive models is diffusion models, which have been more often used by image models like Stable Diffusion. In a nutshell, the model starts with a fuzzy, noisy image, and it iteratively removes the noise while keeping the user request in mind, steering it towards something that looks more and more like what the user requested.
 Diffusion model processes moving to and from data and noise. Image: NVIDIA
Diffusion model processes moving to and from data and noise. Image: NVIDIAStill with us? Great!
Lately, some large language models have looked to the diffusion architecture to generate text, and the results have been pretty promising. If you want to dive deeper into how it works, here’s a great explainer:
Why am I telling you all this? Because now you can see why diffusion-based text models can be faster than autoregressive ones, since they can basically (again, basically) iteratively refine the entire text in parallel.
This behavior is especially useful for programming, where global structure matters more than linear token prediction.
Phew! We made it. So Apple released a model?
Yes. They released an open-source model called DiffuCode-7B-cpGRPO, that builds on top of a paper called DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation, released just last month.
The paper describes a model that takes a diffusion-first approach to code generation, but with a twist:
“When the sampling temperature is increased from the default 0.2 to 1.2, DiffuCoder becomes more flexible in its token generation order, freeing itself from strict left-to-right constraints”
This means that by adjusting the temperature, it can also behave either more (or less) like an autoregressive model. In essence, Higher temperatures give it more flexibility to generate tokens out of order, while lower temperatures keep it closer to a strict left-to-right decoding.
And with an extra training step called coupled-GRPO, it learned to generate higher-quality code with fewer passes. The result? Code that’s faster to generate, globally coherent, and competitive with some of the best open-source programming models out there.
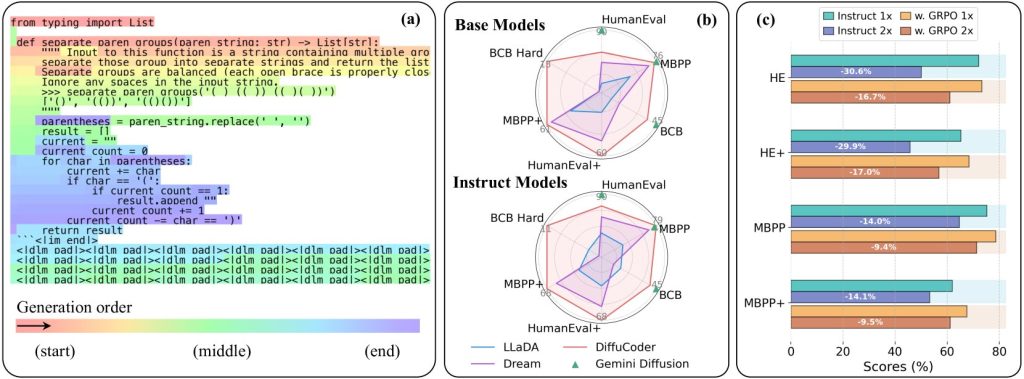 From the study: “(a) A real example of DiffuCoder-Instruct’s decoding process with sampling temperature 1.2. (b) Results on coding benchmarks. (c) When decoding steps are halved, DiffuCoder-Instruct trained with coupled-GRPO experiences a smaller performance drop, compared to Instruct itself.”
From the study: “(a) A real example of DiffuCoder-Instruct’s decoding process with sampling temperature 1.2. (b) Results on coding benchmarks. (c) When decoding steps are halved, DiffuCoder-Instruct trained with coupled-GRPO experiences a smaller performance drop, compared to Instruct itself.”Built on top of an open-source LLM by Alibaba
Even more interestingly, Apple’s model is built on top of Qwen2.5‑7B, an open-source foundation model from Alibaba. Alibaba first fine-tuned that model for better code generation (as Qwen2.5‑Coder‑7B), then Apple took it and made its own adjustments.
They turned it into a new model with a diffusion-based decoder, as described in the DiffuCoder paper, and then adjusted it again to better follow instructions. Once that was done, they trained yet another version of it using more than 20,000 carefully picked coding examples.

And all this work paid off. DiffuCoder-7B-cpGRPO got a 4.4% boost on a popular coding benchmark, and it maintained its lower dependency on generating code strictly from left to right.
Of course, there is plenty of room for improvement. Although DiffuCoder did better than many diffusion-based coding models (and that was before the 4.4% bump from DiffuCoder-7B-cpGRPO), it still doesn’t quite reach the level of GPT-4 or Gemini Diffusion.

And while some have pointed out that 7 billion parameters might be limiting, or that its diffusion-based generation still resembles a sequential process, the bigger point is this: little by little, Apple has been laying the groundwork for its generative AI efforts with some pretty interesting and novel ideas.
Whether (or if? When?) that will actually translate into real features and products for users and developers is another story.
AirPods deals on Amazon
- AirPods Pro 2, USB-C Charging: 20% off at $199
- AirPods (3rd Generation): 20% off, at $134.99
- AirPods 4, USB-C and Wireless Charging: 17% off at $148.99
- AirPods 4 USB-C Charging: 8% off at $119
- AirPods Max Wireless, USB-C Charging, Midnight: 13% off at $479.99
FTC: We use income earning auto affiliate links. More.



