.png)


Published 20 May 2025

The official ARC-AGI-2 Technical Report.
- Benchmark Improvements & Goals
- Human Performance Testing
- SoTA Scores
- $1M Competition Details
Measuring General Intelligence with ARC-AGI-2
The first version of the Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI-1), introduced in 2019, established a challenging benchmark for evaluating the capabilities of deep learning systems via a set of novel tasks requiring only minimal prior knowledge.
While ARC-AGI-1 motivated significant research activity over the past five years, recent AI progress demands benchmarks capable of more fine-grained evaluation at higher levels of cognitive complexity.
This year, we've introduced ARC-AGI-2 to meet this new need.
ARC-AGI-2 incorporates a newly curated and expanded set of tasks specifically designed to provide a more granular signal to assess the abstract reasoning and problem-solving capabilities of today's AI systems. These revamped set of tasks target higher levels of fluid intelligence, demanding more sophisticated generalization, while continuing to target the intersection of what is feasible for humans but still out of reach for AI.
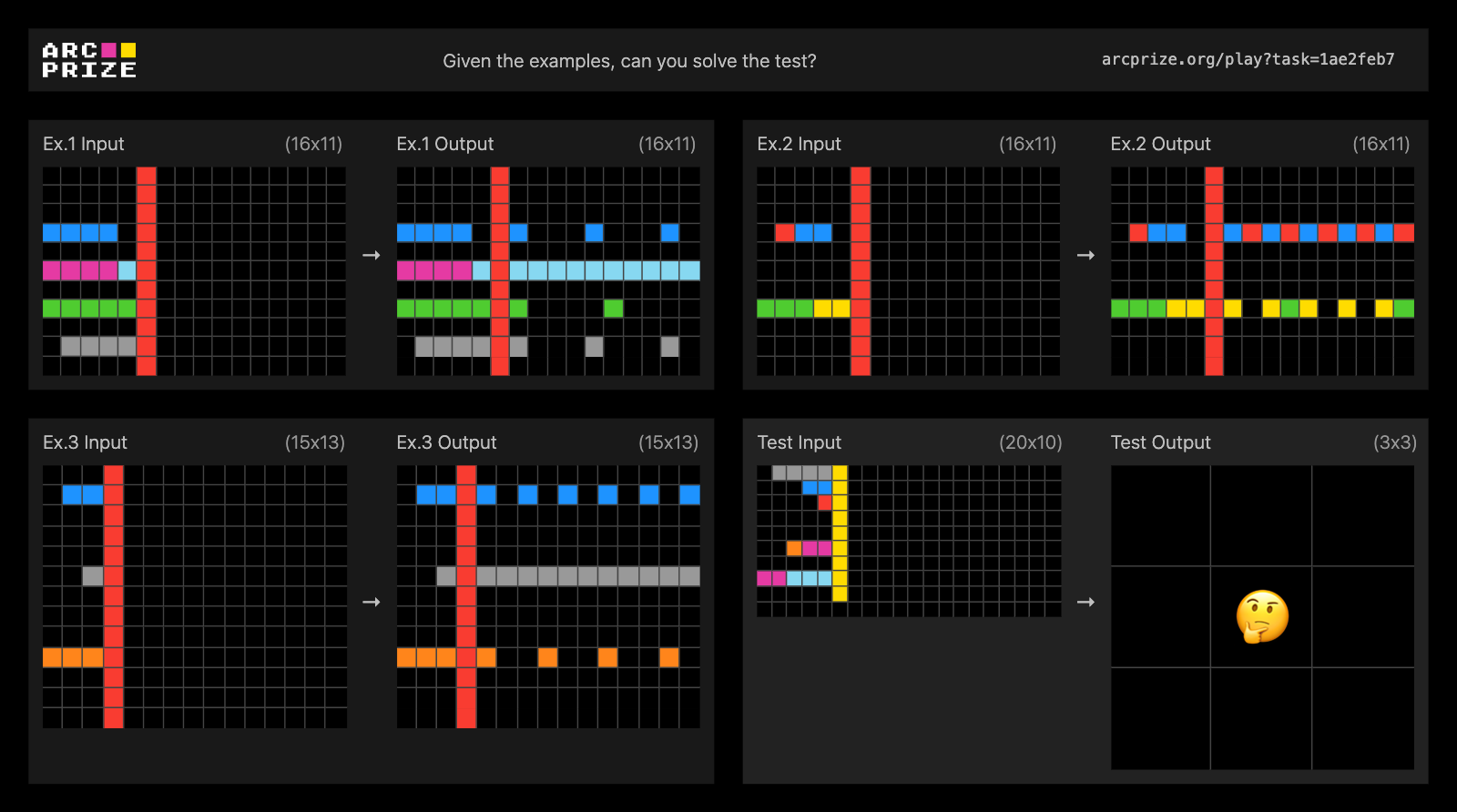 ARC-AGI-2 Public Eval Task #1ae2feb7. Solve this task!
ARC-AGI-2 Public Eval Task #1ae2feb7. Solve this task!
ARC-AGI-2 measures next-gen AI systems
The design goals of ARC-AGI-2 are intended to improve upon the limitations of ARC-AGI-1 and expand the depth and quantity of its datasets. Here are our key goals with this new benchmark version.
- Same fundamental principles & format - Maintain the fundamental principles of ARC-AGI-1, where each task is unique and cannot be memorized in advance, all tasks require only elementary Core Knowledge, and all tasks seek to adhere to the “easy for humans, hard for AI” design guideline.
- Less brute-forcible - Design tasks to minimize susceptibility to naive or computationally intensive brute-force program search techniques.
- First-party human testing - Directly gather human testing data to empirically compare human and AI performance.
- More “signal bandwidth” - Provide a wider, useful range of scores to measure the gap in capabilities required to reach AGI.
- Calibrated difficulty - Curate each data subset (Public Evaluation, Private Evaluation, and Semi-Private Evaluation) to share similar distributions of human solvability and perceived difficulty, ensuring that performance on one set is reliably predictive of performance on another.
Each task requires deeper, human-like thinking
ARC-AGI exists to illuminate the gap between current AI systems and true AGI. While building ARC-AGI-2, extensive testing surfaced a number of conceptual challenges that remain easy for humans, but hard for AI. Here are three of those challenges, as documented in the technical report.
1. Symbolic Interpretation
We found that frontier AI reasoning systems struggle with tasks requiring symbols to be interpreted as having meaning beyond their visual patterns. Systems attempted symmetry checking, mirroring, transformations, and even recognized connecting elements, but failed to assign semantic significance to the symbols themselves.
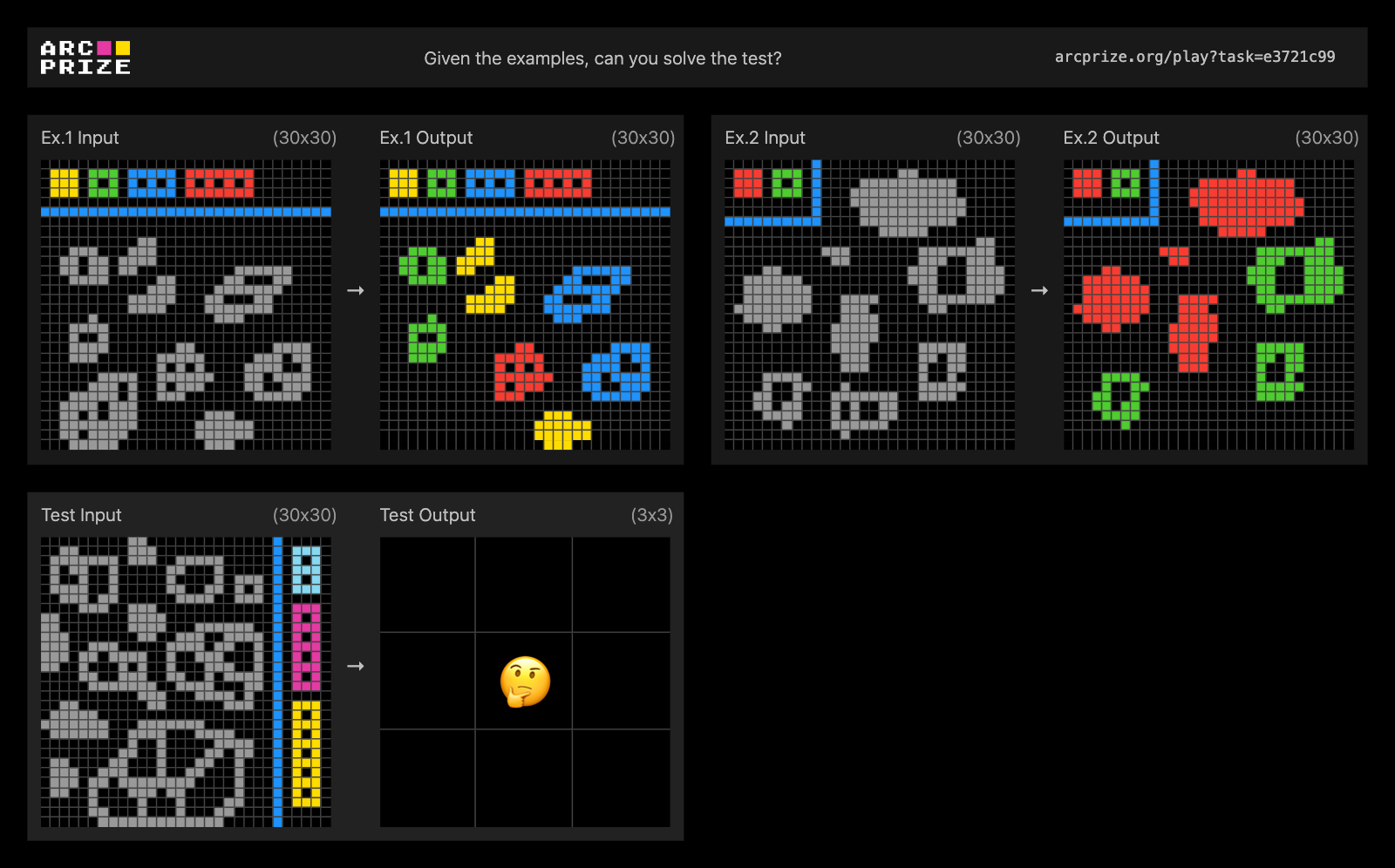 Example of symbolic interpretation, ARC-AGI-2 Public Eval Task #e3721c99. Solve this task!
Example of symbolic interpretation, ARC-AGI-2 Public Eval Task #e3721c99. Solve this task!
2. Compositional Reasoning
We found that AI reasoning systems struggle with tasks that require the simultaneous application of multiple rules, especially when there are rules that interact. In contrast, we found that if a task only has one, or very few, global rules, the same AI systems can consistently discover and apply them.
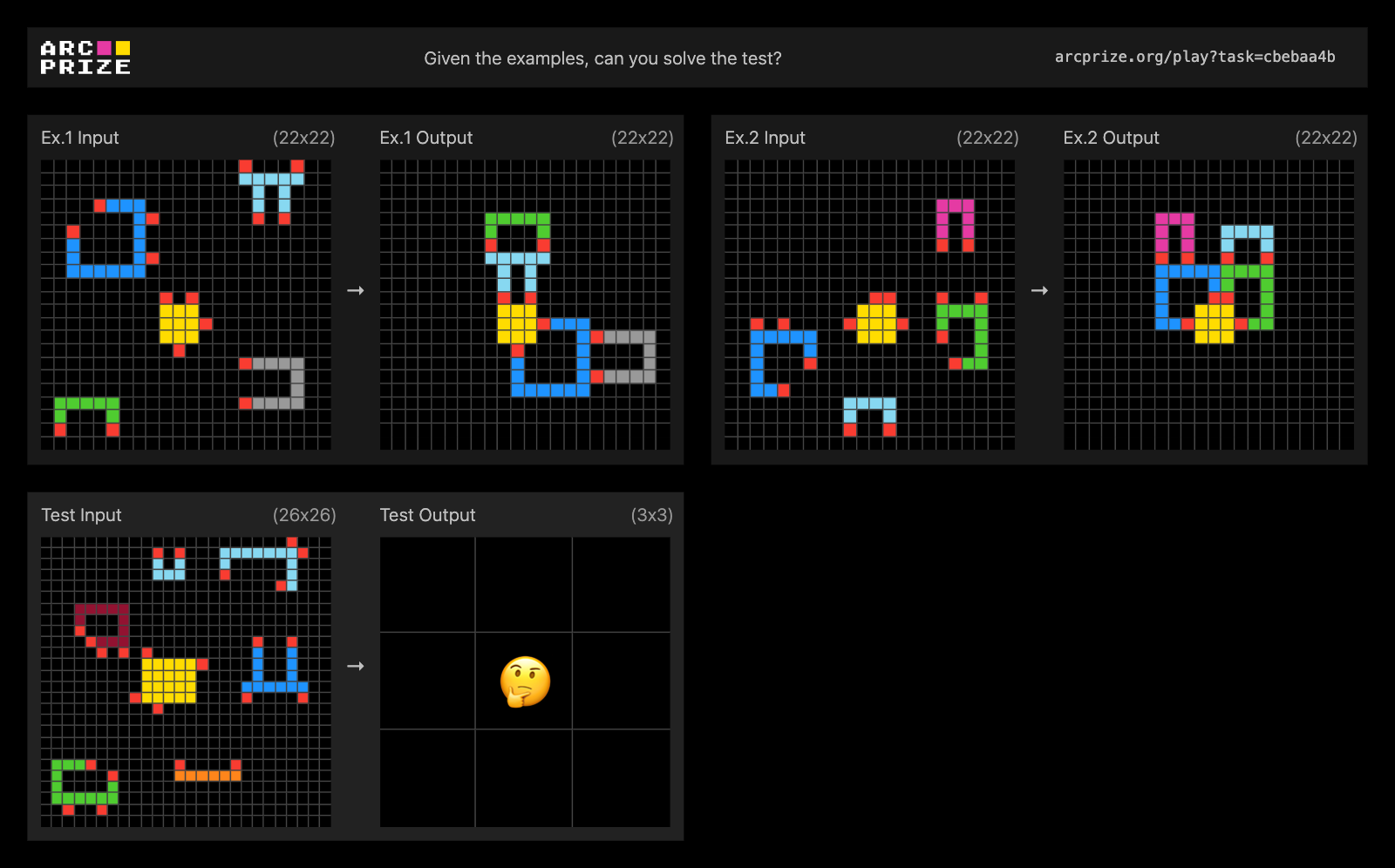 Example of compositional reasoning, ARC-AGI-2 Public Eval Task #cbebaa4b. Solve this task!
Example of compositional reasoning, ARC-AGI-2 Public Eval Task #cbebaa4b. Solve this task!
3. Contextual Rule Application
We found AI reasoning systems struggle with tasks where rules must be applied differently based on context. Systems tend to fixate on superficial patterns rather than understanding the underlying selection principles.
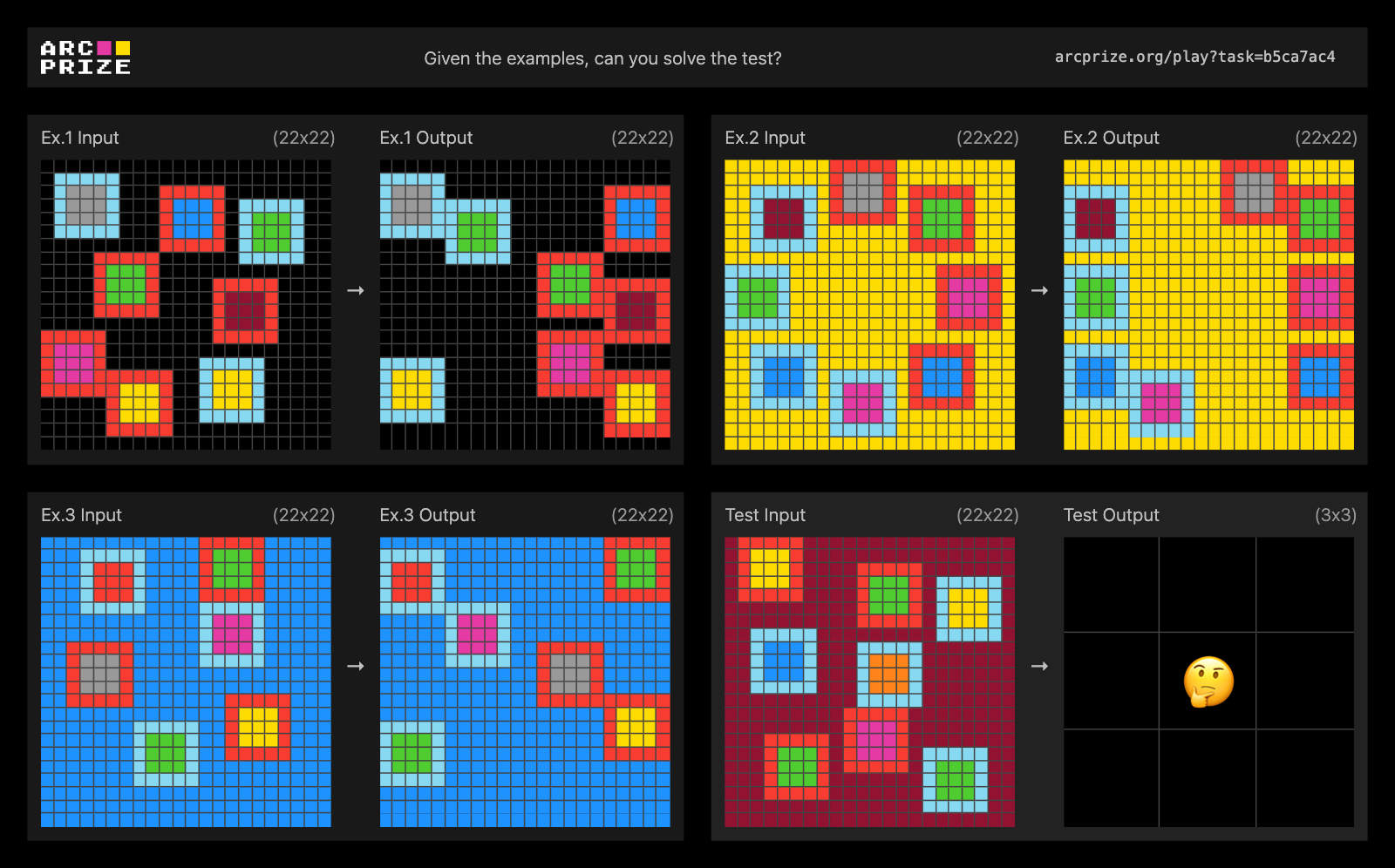 Example of contextual rule application, ARC-AGI-2 Public Eval Task #b5ca7ac4. Solve this task!
Example of contextual rule application, ARC-AGI-2 Public Eval Task #b5ca7ac4. Solve this task!
Humans can solve 100% of ARC-AGI-2
400 people, 1,400+ tasks
To back up the claim that ARC-AGI-2 tasks are feasible for humans, we tested the performance of 400 people on 1,417 unique tasks. We asked participants to complete a short survey to document aspects of their demographics, problem-solving habits, and cognitive state at the time of testing.
Interestingly, none of the self-reported demographic factors recorded for all participants demonstrated a clear significant relationships with performance outcomes. This finding suggests that ARC-AGI-2 tasks assess general problem-solving capabilities rather than domain-specific knowledge or specialized skills acquired through particular professional or educational experiences.
 In-person human testing on ARC-AGI-2 candidate tasks.
In-person human testing on ARC-AGI-2 candidate tasks.
At least 2 people solved every task
To ensure each task was solvable by humans, we made a minimum success bar of: "two people in two attempts or less." On average, each task was attempted by about 9-10 participants. Many tasks were solved by more than two individuals (see the histogram below). Tasks that did not meet this threshold were considered too challenging and were excluded from ARC-AGI-2.
Across all testing, we observed that participants spent an average of approximately 2.3 minutes per task, highlighting the accessible, yet cognitively demanding nature, of ARC-AGI-2 tasks.
Make sure to read the technical report for more details on human performance on ARC-AGI-2.
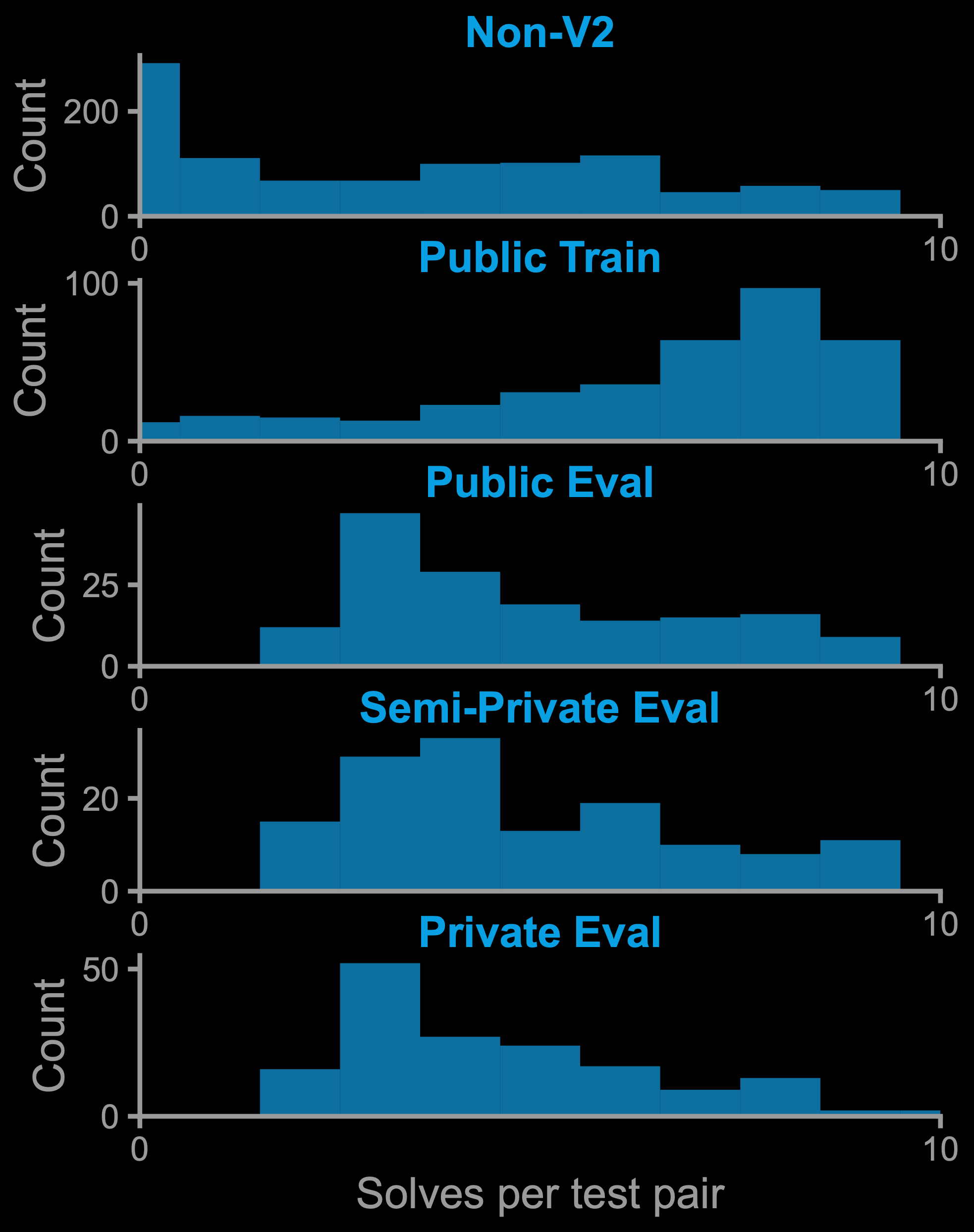 ARC-AGI-2 count of tasks by number of solves.
ARC-AGI-2 count of tasks by number of solves.
As a fun aside, this selection process left us with a collection of very difficult ARC-AGI tasks that could potentially form the basis of an even more challenging future benchmark — maybe, ARC-AGI-2+ or "ARC-AGI-2 Extreme!" However, this is not an immediate priority. These most challenging tasks remain available to us as a compelling demonstration of the upper limit of human performance on the benchmark to date.
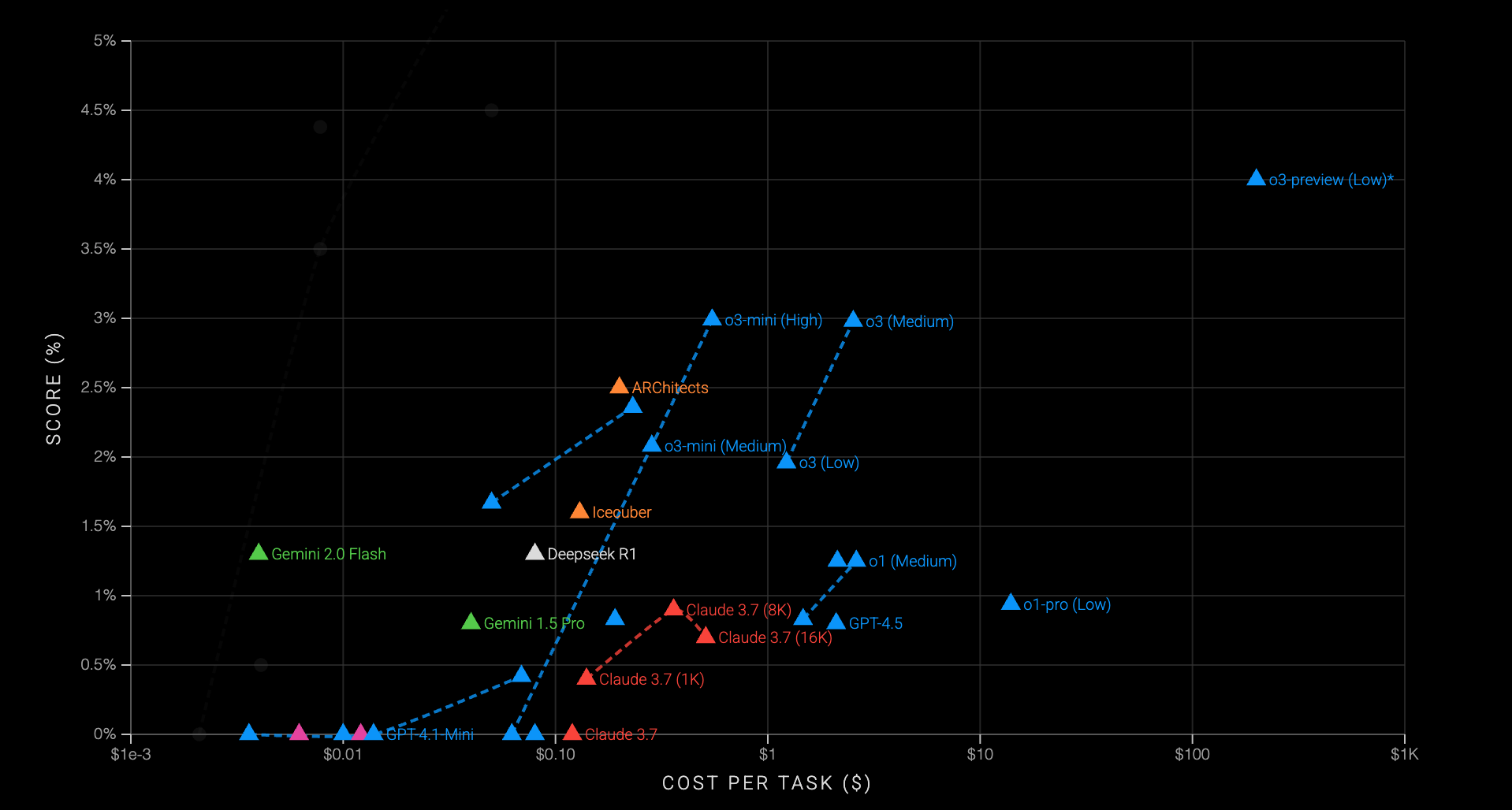
Top AI models currently score <5%
We maintain an up-to-date leaderboard tracking how current closed-weight AI models perform on ARC-AGI-2.
Using our open-source ARC-AGI Benchmarking repository, you can run your own tests to evaluate model/system performance directly.
At the time of publishing the technical report, none of the leading AI models have surpassed a 5% success rate on ARC-AGI-2 tasks, whereas comparable models routinely achieve between 20% and 50% on ARC-AGI-1.
To explore these results further, visit the live ARC-AGI leaderboard.
 Live human testing on ARC-AGI-2 candidate tasks.
Live human testing on ARC-AGI-2 candidate tasks.
![Doom Will Teach You What CS Degrees Miss [video]](https://www.youtube.com/img/desktop/supported_browsers/edgium.png)


