.png)

Ever since I wrote the ClickHouse post, it has been living in my head rent-free. I was thinking a lot about running it as the backend for a SaaS service and realized its multi-tenancy model isn't great.
And that led me into a rabbit hole where I realized I am very opinionated, but at the same time, know very little about running systems at scale.
SaaS solutions come in all shapes and sizes. You could be building a solution where you only have a handful of tenants, but each is super large, or you could be building something like Grafana Cloud.
We have 1000s of tenants in each cluster with all kinds of different sizes. For example, in Grafana Cloud, we have the free tier that is used by many small organizations and hobbyists, and many a time, these tenants slowly grow to be massive. This means our clusters have more than 10K tenants in them of all shapes and sizes. You could have 1000s of tenants with only 10K active series in the same cluster that hosts tenants having 50Mil+ active series.
Yes, this isn't a very common use case, but hey, this is the use case I am familiar with. Companies like SigNoz, Dash0, and PostHog are built on top of ClickHouse and it is a very relevant problem for them, so I was curious how they'd solve this.
ClickHouse has an excellent guide on how to do multi-tenancy: https://clickhouse.com/docs/cloud/bestpractices/multi-tenancy.
Since we are talking about 1000s of tenants on the same cluster, the only viable approach from the doc is Shared table using a column for the tenant_id. PostHog publishes part of its schema here: https://posthog.com/handbook/engineering/clickhouse/schema/sharded-events and they use team_id as the column name, and that's how they implement multi-tenancy.
You can then use row policies to ensure that each tenant can only access their data. You could create a user per tenant or even do something like:
CREATE ROW POLICY filter_by_org_id ON <table> USING org_id=getClientHeader('X-Scope-OrgID') TO readonly-user;I would create a user per tenant so I can enforce configurable query limits on each user.
But, but, no shuffle sharding!
🚫
Disclaimer: ClickHouse was not built to be a SaaS service. So its trade-offs make perfect sense. And nothing is stopping them from implementing a tenancy-aware DistributedTable.
So let's say we start off by implementing tenancy with an org_id column. And then the product becomes quite successful and now has 1000s of tenants of all sizes. Some tenants send 1 million rows/sec, and some send only 100 rows/sec.
And you have to scale the cluster to many nodes to cater to this scale. You'll need to implement sharding, where the sharding key should ideally include the org_id. If you don't include it, then all the writes from a large tenant will go to a single node, causing hotspots. But then including the org_id would then spread the data of a single tenant on all the nodes.
But now, an outage of a single shard or a single misbehaving tenant will affect all the tenants. AWS came up with Shuffle Sharding to mitigate this issue. Colm MacCárthaigh's excellent thread explains it well, and with pictures!
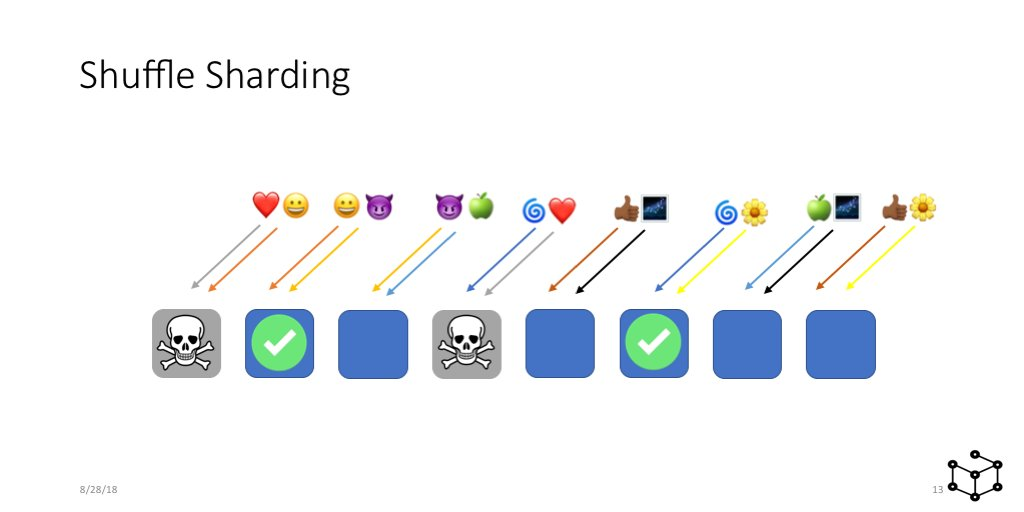
Basically run each tenant on a subset of the nodes so that there is very little overlap of infrastructure between tenants. For more details, you can also see our KubeCon talk and its implementation in Mimir.
Shuffle sharding is also great for the uneven tenant sizes. We keep the smaller tenants on only 3 shards and increase the shard size as the tenant's scale grows. If we take the case of tenants with only 100 rows/sec, this will mean better compression and would also mean that queries will only need to go to 3 nodes, instead of the whole cluster.
This is the context I have, and for me, it's unthinkable to run 1000s of uneven tenants on 100s of nodes without shuffle sharding. I wondered how Dash0, PostHog, and others handle this.
And I found out that most people run very few shards. From this article from April, Dash0 only runs a single shard. I'm sure they bring up dedicated clusters for their larger customers but stick to a single shard for their smaller customers.
PostHog runs a “big cluster” with only 8 shards! They're running into problems with 8 shards, but that's when I realized that's a “large cluster” for ClickHouse. I know of a massive company that runs its entire logging infrastructure on a 2-shard, 2-replica cluster, with each node having 70 CPUs and 600 Gi RAM.
When you only have a few nodes, shuffle sharding becomes less of a requirement. I wonder if we (Grafana Cloud) are doing the wrong thing running 100s of nodes per cluster 😄.
I also got interested enough to read the ClickHouse paper, and they made some curious trade-offs. Maybe I will share my notes on it one of these days.

![Watt Amp That Changed the Industry [video]](https://www.youtube.com/img/desktop/supported_browsers/edgium.png)

