.png)

Authors: Adrian Kosowski, Przemysław Uznański, Jan Chorowski, Zuzanna Stamirowska, Michał Bartoszkiewicz
Paper: https://arxiv.org/abs/2509.26507
Code: https://github.com/pathwaycom/bdh
WHAT was done? The paper introduces ‘Dragon Hatchling’ (BDH), a novel Large Language Model architecture designed as a “missing link” between tensor-based Transformers and distributed graph models of the brain. BDH’s dynamics are not defined by matrix operations but by a local, biologically plausible “edge-reweighting kernel” that combines modus ponens-like inference with Hebbian learning. Its GPU-friendly variant, BDH-GPU, is a state-space model that scales primarily in a single, high neuronal dimension (n). It uses linear attention in this large space and a unique ReLU-lowrank feed-forward block, ensuring all neuron activations are sparse and positive.
WHY it matters? This work offers a concrete architectural path toward “Axiomatic AI”—models whose behavior is more foreseeable and generalizable, especially for long-horizon reasoning. While achieving performance competitive with the GPT-2 architecture, BDH-GPU naturally exhibits highly desirable properties often absent in standard Transformers:
Emergent Structure: Its parameters spontaneously develop modular, scale-free network structures, mirroring efficient biological systems.
Inherent Interpretability: The model’s state is localized on individual neuron-neuron links (”synapses”), leading to empirically verified “monosemantic synapses” that selectively activate for specific abstract concepts.
Novel Engineering: Its uniform scaling facilitates new forms of model engineering, like directly merging separately trained models by concatenating their parameters. This provides a powerful micro-foundational framework for understanding how high-level reasoning can emerge from simple, local interactions.

The remarkable success of Large Language Models (LLMs) like the Transformer has been shadowed by a persistent challenge: their failure to systematically generalize reasoning over time scales and contexts beyond their training data. This gap highlights a fundamental disconnect between our best-performing AI systems—centralized, tensor-based black boxes—and the distributed, scale-free, and remarkably robust reasoning engine that is the human brain.
The paper “The Dragon Hatchling” tackles this disconnect head-on, proposing a new architecture that serves as a foundational bridge between these two worlds. It moves beyond post-hoc interpretability efforts and instead designs a system from first principles, asking: what if the core mechanisms of a Transformer could be derived from the local dynamics of an interacting particle system inspired by the brain? The result is a model that is not only performant but also inherently interpretable and structurally aligned with natural systems, a step towards what the authors call “Axiomatic AI.” The significance of this lies in establishing a clear micro-to-macro correspondence. If the model’s large-scale behavior can be reliably predicted from its simple, local rules—much like how the principles of thermodynamics predict a gas’s behavior from the interactions of individual molecules—then its performance on unseen, long-horizon tasks becomes more transparent and less prone to unpredictable failures.
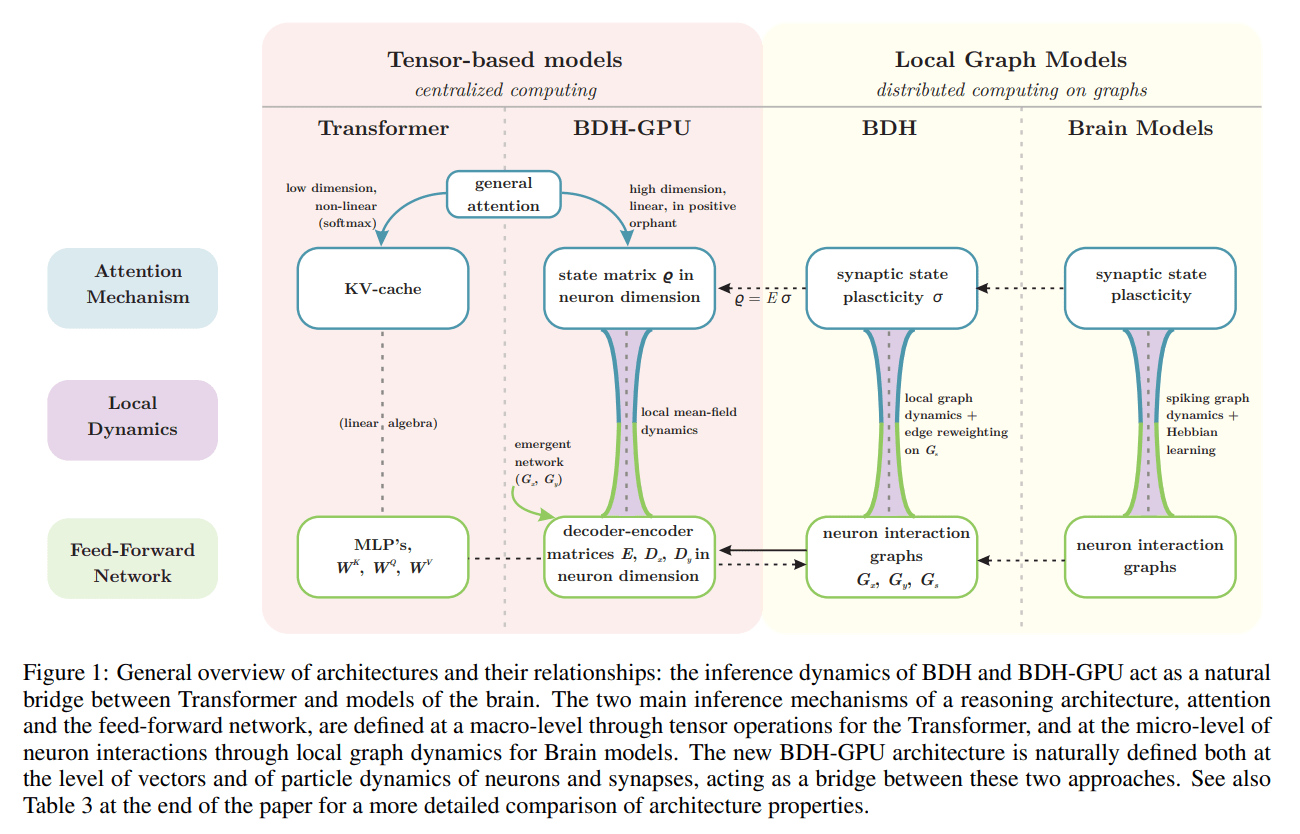
The core theoretical contribution is the Dragon Hatchling (BDH) architecture, a system of n interacting neuron particles whose inference is defined not by global matrix multiplications but by local graph dynamics. The authors formalize this with an edge-reweighting kernel, a set of rules they term the “equations of reasoning” (Table 1).
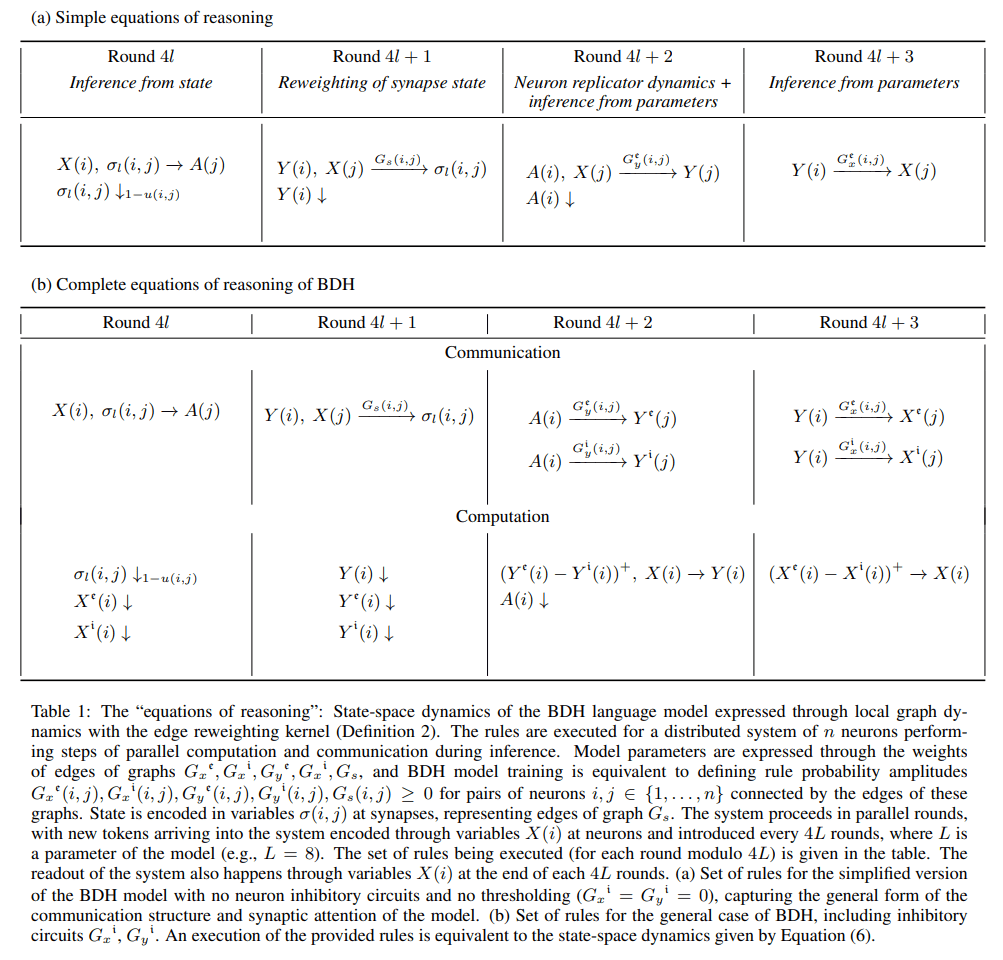
This framework elegantly fuses two fundamental concepts:
Logical Inference: A generalized form of the modus ponens rule, where a belief in fact i contributes to a belief in fact j based on the connection strength between them.
Hebbian Learning: The biological principle that “neurons that fire together, wire together,” where the connection (synaptic) strength between two neurons is potentiated based on their correlated activity, foundational work for which can be found in D. O. Hebb’s Organization of behavior (1949).
In BDH, the model’s parameters define the static topology of a communication graph, while the dynamic, in-context state (σ) is represented by the weights on the graph’s edges (synapses). State updates are local, direct manipulations of these synaptic weights, a process the authors show can be emulated by a graph-based Spiking Neural Network.
To build intuition, the authors offer a delightful physical analogy for BDH (Figure 2).
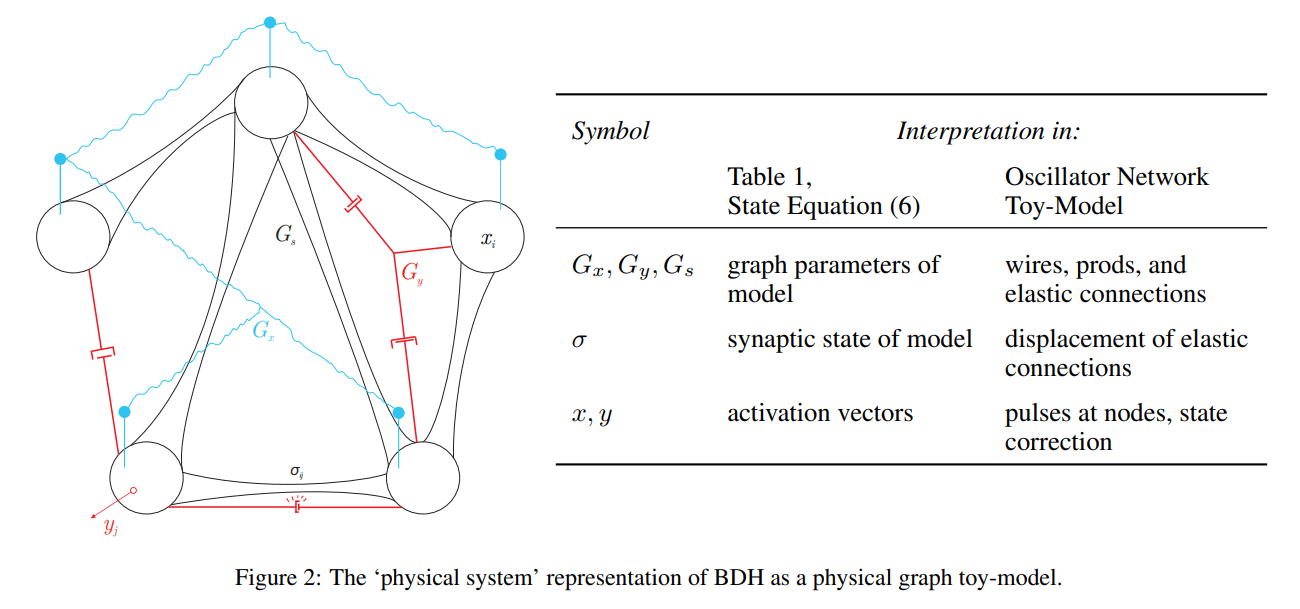
Imagine the neurons as particles connected by elastic bands (the dynamic synapses, σ). A pulse of activity at one neuron (x) propagates through fixed ‘wires’ to another, causing it to pulse (y). If these two pulses happen in close succession, the elastic band connecting them tightens—the synapse potentiates. This metaphor grounds the abstract equations in a tangible, mechanical system of tension and propagation, making the model’s inner workings feel incredibly intuitive.
To make this model computationally tractable on modern hardware, the authors introduce BDH-GPU, a tensor-friendly state-space system that serves as a special case of BDH. This practical implementation is achieved by approximating the “communication by wire” graph dynamics with a “mean-field” interaction, allowing the state to be represented by a low-rank n×d matrix (ρ) instead of a full n×n matrix.
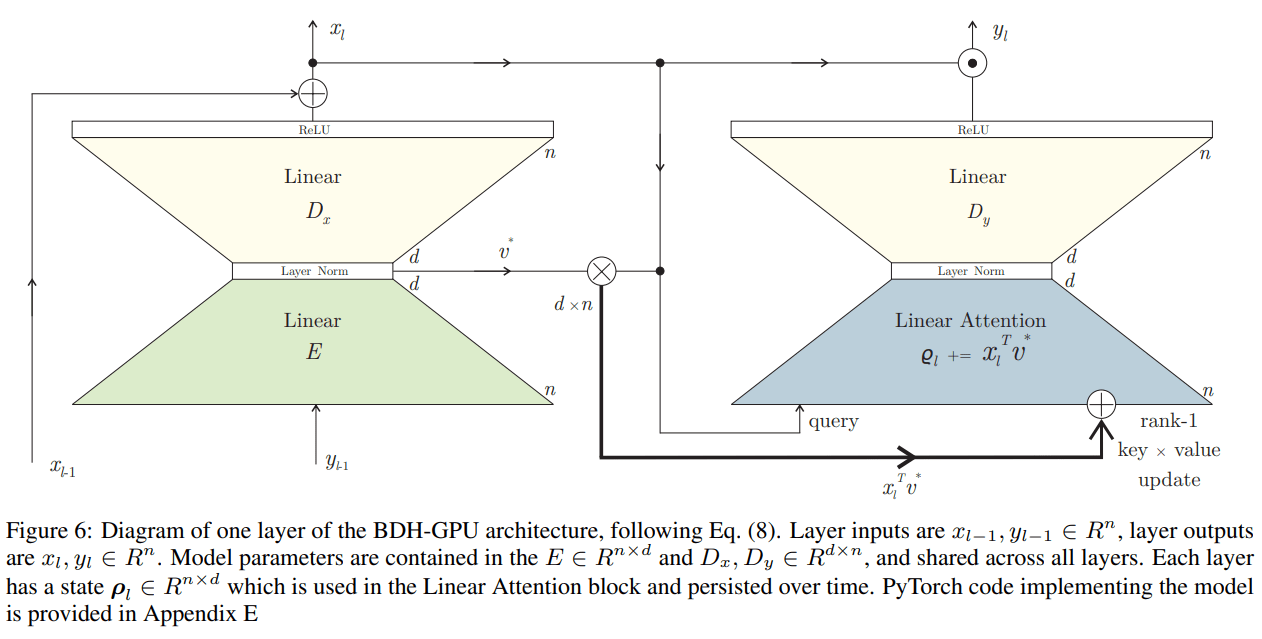
The BDH-GPU architecture (Figure 6) is governed by a layer-recurrent state-space equation and relies on two key components that operate in the high neuronal dimension n:
ReLU-Lowrank Feed-Forward Network: The FFN uses the transformation z→(DEz)+, where E is an encoder (n→d) and D is a decoder (d→n). The ReLU non-linearity is crucial, as it ensures all activation vectors are positive and empirically leads to high sparsity (~5% non-zero). This block acts as a signal propagation mechanism that reinforces communication within emergent neuron clusters.
High-Dimensional Linear Attention: The attention mechanism is linear and operates on the n-dimensional activation vectors. It updates the recurrent state matrix ρ by accumulating key-value correlations, treating the state as a large, fixed-size associative memory.
The complete state-space dynamics for a single layer l at time t are given by (Equation 8)

Here, x vectors act as keys/queries, y vectors are used to generate values, U handles positional information (e.g., RoPE), and LN is Layer Normalization. This structure positions BDH-GPU in the family of modern State-Space Models aiming to overcome fixed context limits, like Mamba (more here and here).
The most compelling aspect of BDH-GPU is its ability to achieve competitive performance while naturally developing properties characteristic of biological systems.
Performance and Scaling: Experiments show that BDH-GPU follows Transformer-like scaling laws. A variant (BDH-GPU’) matches the performance of a GPT-2 style baseline that uses state management from Transformer-XL on translation tasks at scales from 10M to 1B parameters (Figure 7).
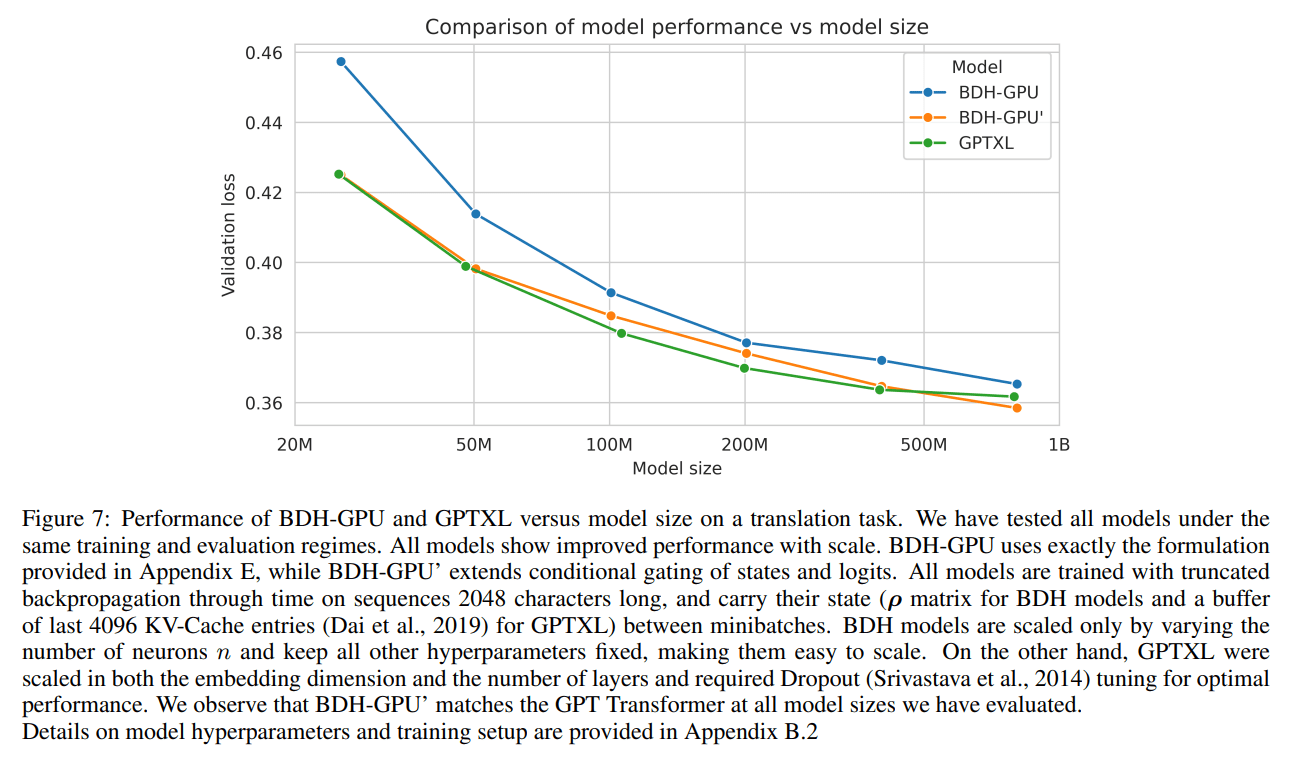
Crucially, it achieves this by scaling almost exclusively in a single neuronal dimension n, a simpler and more uniform approach than the multi-dimensional scaling of Transformers.
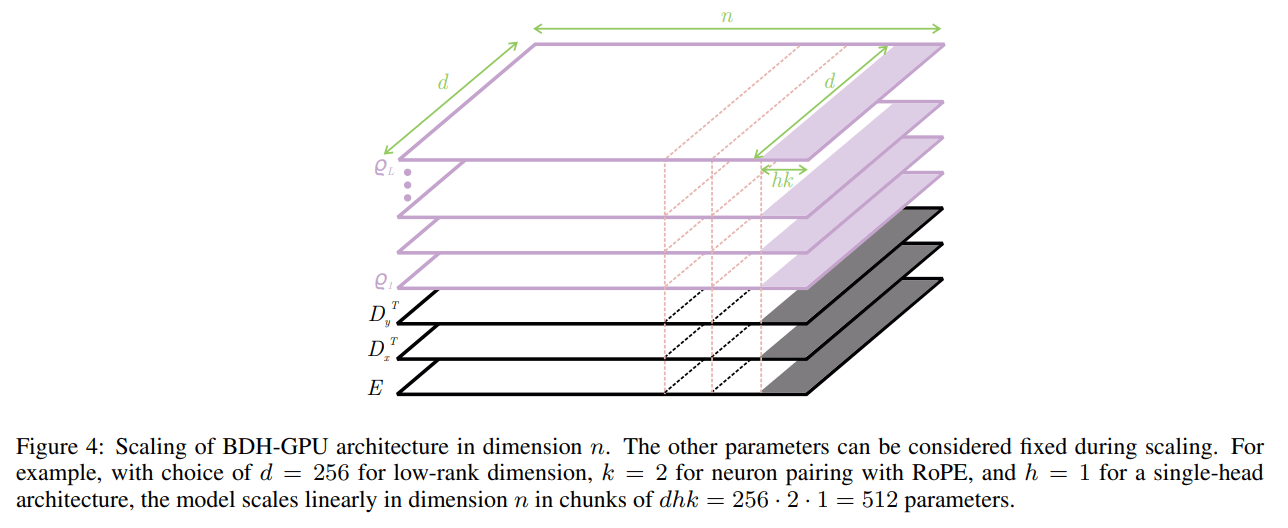
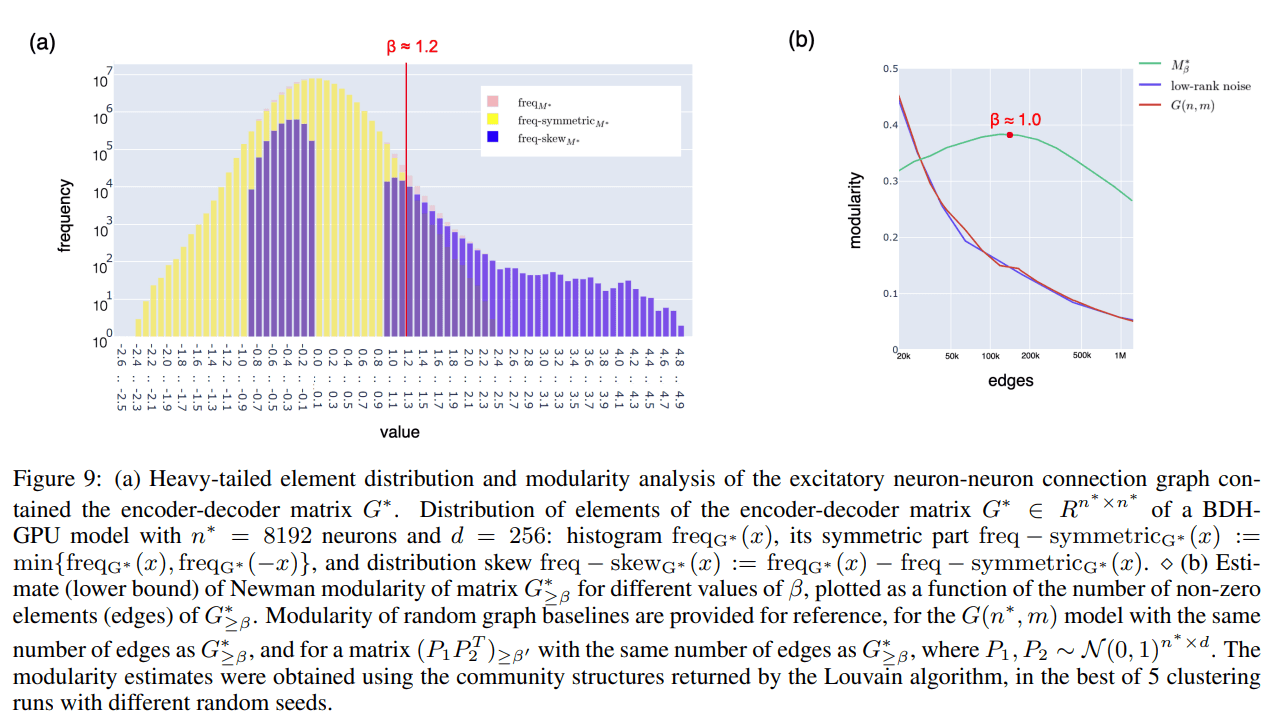
Emergent Structure: During training, the parameter matrices (DxE,DyE) spontaneously develop a modular, scale-free network structure.
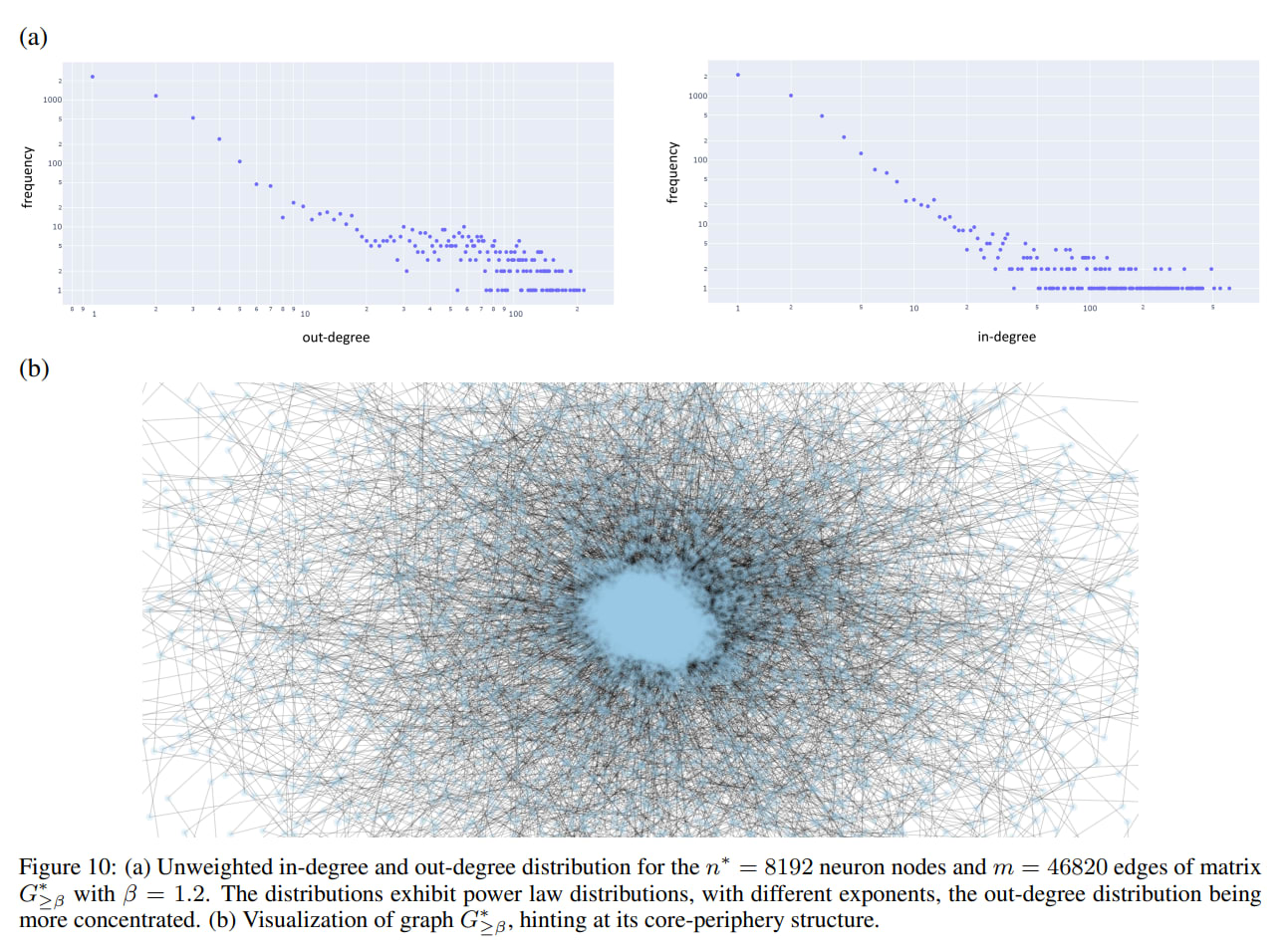
Analysis reveals heavy-tailed, power-law-like degree distributions (Figure 10) and high Newman modularity (Figure 9), properties associated with efficient information processing in complex natural systems. This structure is not imposed but emerges as an optimal solution for the learning task.
Inherent Interpretability and Monosemanticity: The architecture is designed for interpretability from the ground up.
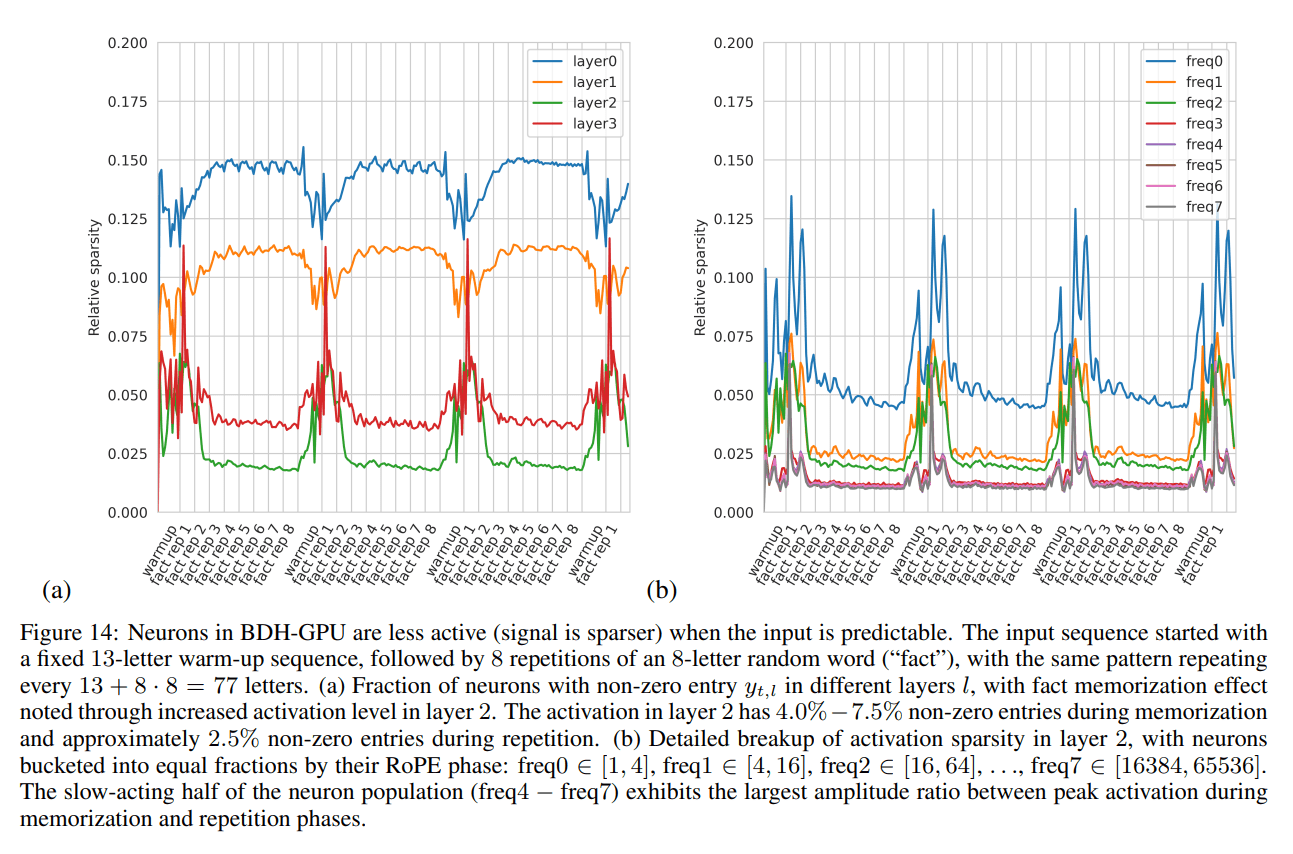
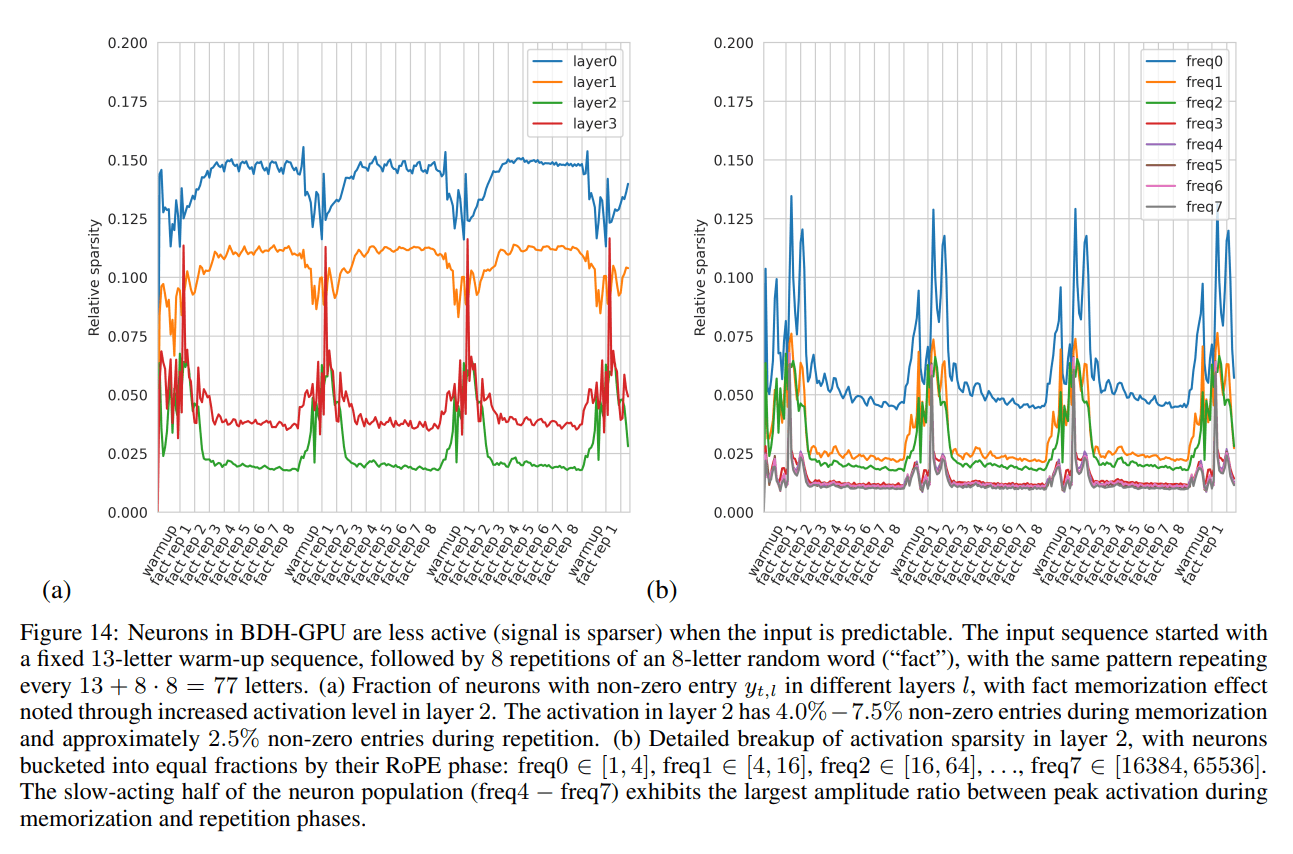
Sparse Positive Activations: Neuron activations are positive and highly sparse. The level of sparsity correlates with input predictability, with fewer neurons firing for expected inputs, suggesting an inherent adaptive computation mechanism (Figure 14).
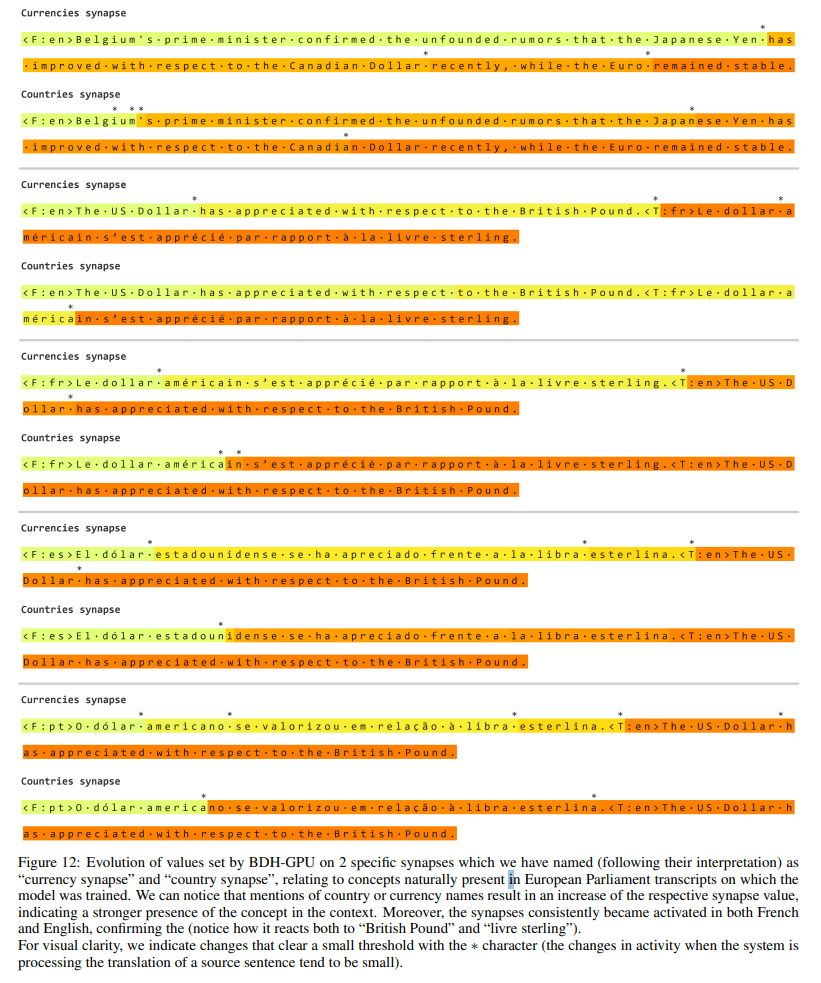
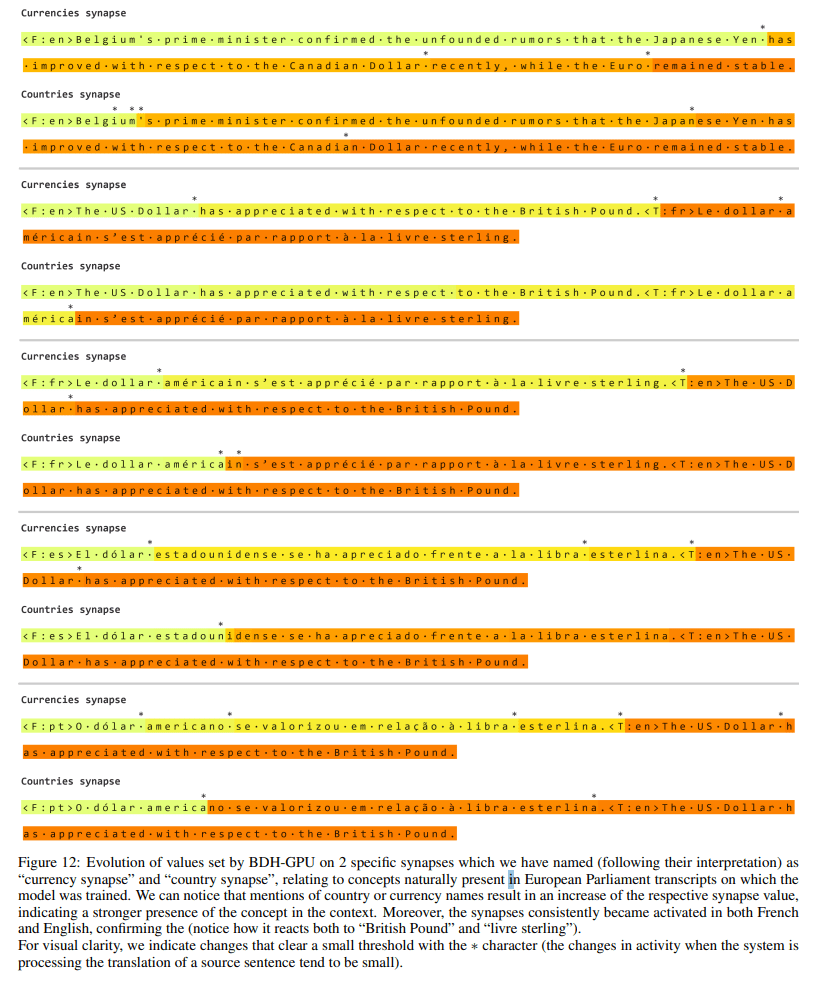
Monosemantic Synapses: By tracking the state matrix σ (recovered from ρ), the authors identify individual synapses (neuron-neuron links) that consistently activate when processing specific abstract concepts, such as “currency” or “country name,” across different languages (Figure 12).
This localization of state provides a direct, micro-level view into the model’s reasoning process (Figure 13).


The uniform scaling in dimension n enables a powerful form of model engineering: direct composition. The authors demonstrate that two BDH-GPU models trained on separate language pairs can be merged into a single, larger model by simply concatenating their parameter tensors along the neuron dimension (Table 2).
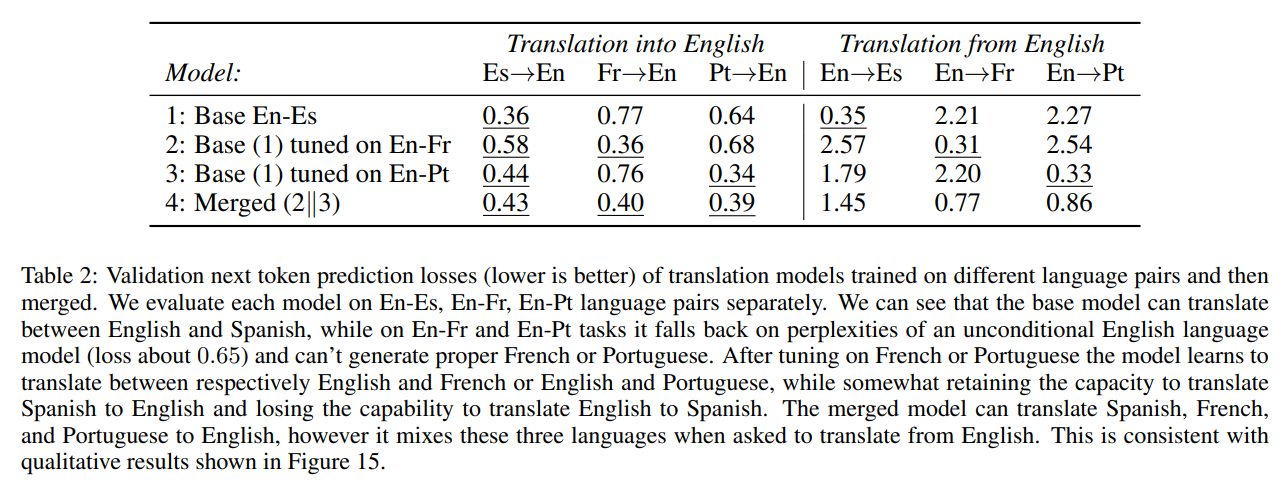
While the merged model shows some “human-like degradation” in generation without fine-tuning (Figure 15), it successfully retains knowledge from both parent models, showcasing a promising path toward treating LLMs as composable computer programs.

The work is not without limitations. This highlights a crucial distinction: while BDH’s inference dynamics are designed from first principles to be biologically plausible, its learning algorithm still relies on standard, and biologically implausible, backpropagation through time. The authors’ preliminary experiments on training without BPTT confirm that this is not a trivial limitation; performance on complex tasks like translation degrades significantly. Bridging this gap between plausible inference and plausible learning remains a critical open challenge for future work. Furthermore, the practical BDH-GPU relies on a mean-field approximation, a departure from the strict local dynamics of the theoretical BDH model.
“The Dragon Hatchling” presents a significant and thought-provoking contribution to AI research. By establishing a formal, performant, and empirically validated link between the macro-operations of Transformers and the micro-dynamics of brain-like systems, it provides a compelling blueprint for a new class of AI. This work moves the field closer to the goal of Axiomatic AI—systems that are not only powerful but also fundamentally understandable, predictable, and structurally aligned with the principles of natural intelligence. It offers a rich theoretical framework and a practical architecture that will undoubtedly inspire further research into the foundations of reasoning.



