.png)

Parallelism is one of the trickiest issues I am facing in experiments using evolutionary algorithms to optimize neural networks (for Artificial Life, RL tasks…etc). If I avoid tackling it, everything will run super slow, thus reducing massively the room for experimentation.
The problem that I am facing is that I want to upgrade my hardware to accelerate my experiments. So far I’ve been experimenting on my laptop. So, what kind is the right setup to buy?
Keep in mind the following aspects of these evolutionary-based optimizations:
- A single experimental run is a loop that runs until a criteria is met (performance criteria,a limit on the compute budget…etc).
- Each iteration of this loop is called a generation
- Each generation contains N neural networks to evaluate.
- Each neural network is called an individual
- Individuals are independent
- Due to the stochastic nature of the target task, each individual is evaluated over M independent trials (i.e., restart the environment and run the simulation M times, and aggregate the performance)
- And finally, due to the stochastic nature of the evolutionary algorithm itself, the optimization loop repeated Z times, and a statistic is reported.
In case of artificial life and RL tasks, a key aspect in the evaluation of each neural network (aka: single individual) is that it has a batch size of one.
So, in get the best acceleration, shall I:
- Parallelize the run of the N independent individuals? (i.e., run each of them inside a separate process to evaluate the individual)
- Or parallelize the evaluation of the M trials instead? An example workflow:
- Create multiple environments. Progress one step inside all those environments in parallel
- Collect the observations, form a batch, and feed it to the neural network
- Or optimize for execution of each neural network instead?
- Or parallelize the Z repetitions of the optimization loop?
But, wait a minute…I said neural network?? then it must be a GPU, right? RIGHT?….Well, not so fast. The reason why a GPU is not that obvious choice is due to the nature of the artificial life experiments.
- All neural network evaluations are done on batch size of 1
- The neural networks are relatively small in size (in the order of tens of thousands of parameters), no backpropagation, and many sequential steps.
- From a naive point of view, the room for parallelization is to run multiple experiment in parallel, as opposed to having a larger batch size
- Thus, it is not clear how to avoid:
- Choking the system resources
- Creating a complex and specific solution, that doesn’t generalize well to the next experiment
Thus, it is not immediately clear whether a GPU is the right option.
In this blog, I will benchmark the accelerating of the neural networks execution on different CPUs.
To do so, I will use a simple benchmark (matrix multiplication) using PyTorch, at different number of process and dimensions, over the following hardware
- My MacBook Air laptop: M3 processor, 8 cores (8 threads), 24 GB RAM (no neural engine used), running on macOS 15.5
- My old Intel Xeon server: Intel Xeon E5-1650 v4 3.6 GHz, 12 cores (24 threads), 32 GB RAM, running on Ubuntu 24.04.2 LTS
- Compute Optimized server (Google Cloud): Intel Cascade Lake (whatever that means), 16 CPUs (16 threads), 64 GB RAM, running on Debian GNU/Linux 12
- Arm64 server (Google Cloud): Google Axion CPU, 8 CPUs (8 threads), 16 GB RAM, running on Debian GNU/Linux 12
Why Arm64? I was surprised by my MacBook results (spoiler alert: it is the best CPU by far), and I thought it might has something to do with being Arm-based processor.
Among the benchmarked CPUs, on every aspect, my MacBook outperforms every other type by far
I observed the runtime (in seconds) of matrix multiplication task, repeated 1000 times, over the following configurations:
- Different dimensions
- Different number of threads
Why different number of threads? A concern I’ve when evaluating parallel neural network is chocking the compute resources on a single machine. By managing the number of threads and parallel processes, I am aiming to avoid that.
Let’s first look at aggregated view overall the different configurations.
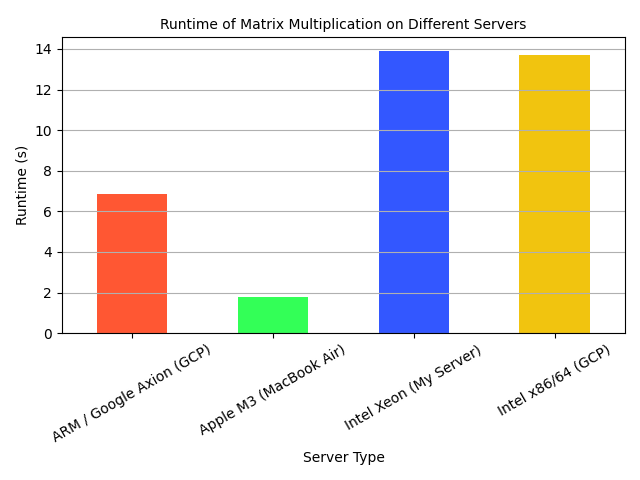
We can see that, overall, the MacBook outperformed the other machines.
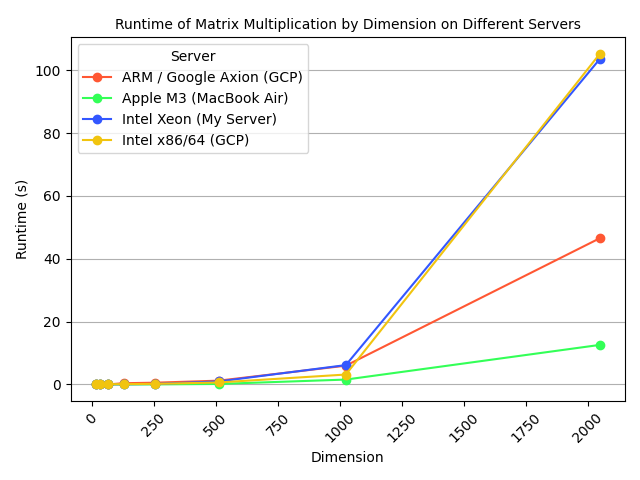
When changing only the matrix dimension, the MacBook scaled better than the rest.
Testing different thread counts did not affect the MacBook (likely due to optimizations in macOS), and its performance remained ahead of the other machines at every value.
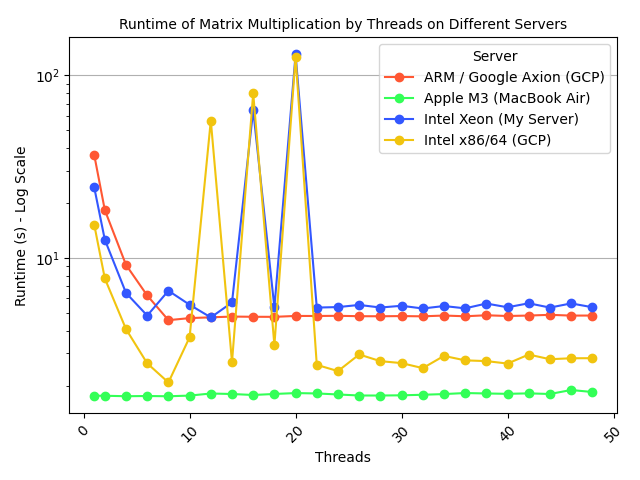
These results were unexpected, and I cannot fully explain the observed performance differences.
- I expected the Intel processors to perform better (since they are promoted in GCP as “compute optimized”)
- Even without macOS optimizations, the ARM processor performed better than Intel
- The number of threads has no effect on the MacBook performance
- Both Intel processors performance fluctuated significantly between ~10 and ~20 threads (why??)
This suggests I should invest in a desktop Apple device (e.g., Mac mini) and use it as my experiment server.
In the next round, I will:
- Benchmark a GPU versus my MacBook on the same task (expecting the GPU to win, but to validate my setup)
- Create a more realistic benchmark (e.g., run an RL optimization task)
I will decide on my purchase after that.



