.png)

PART I: Constructing Intelligence: How LLMs Are Built
The Architecture: Building Blocks of Intelligence
Think of an LLM like a giant factory that takes in words and transforms them step by step until it understands what they mean together. Instead of reading left to right like humans, it looks at all the words at once and figures out which words need to pay attention to which other words, like how "quickly" needs to focus on "runs" to understand what's happening quickly.
At its core, an LLM is built on something called a Transformer architecture [1], which is essentially the blueprint for how information flows through the system. The name "Transformer" comes from what the model does: it transforms each word's representation as it moves through processing layers. With each transformation, the meaning gets refined based on the surrounding context (Figure 1).
When you give an LLM a sentence like "The dog runs quickly through the tall grass," it doesn't read it left-to-right like we do. Instead, all eight words enter the model simultaneously as numerical vectors. Each vector is a list of hundreds of numbers representing that word's initial meaning. This parallel processing has limits. Current models can only handle a fixed 'context window' of text at once, generally from a few thousand to hundreds of thousands of tokens depending on the model. It will forget anything beyond that boundary; however, when generating its response, it must work left-to-right, producing one word at a time while only "seeing" the words it has already generated. It can't peek ahead at words it hasn't written yet.
To preserve word order, each word gets mixed with a special pattern of numbers that encodes its position in the sentence. These patterns are mathematical signatures that help the model understand not just that "dog" comes before "runs," but how far apart words are and their relative positions. This way, the model knows that "dog runs" means something different from "runs dog." As these words flow through the model's layers, their representations transform from generic meanings into specific, contextual understandings. The word "runs" starts as a general concept that could mean jogging, flowing water, or operating machinery, but by interacting with "dog" through multiple layers, it transforms into the specific meaning of an animal's gait.
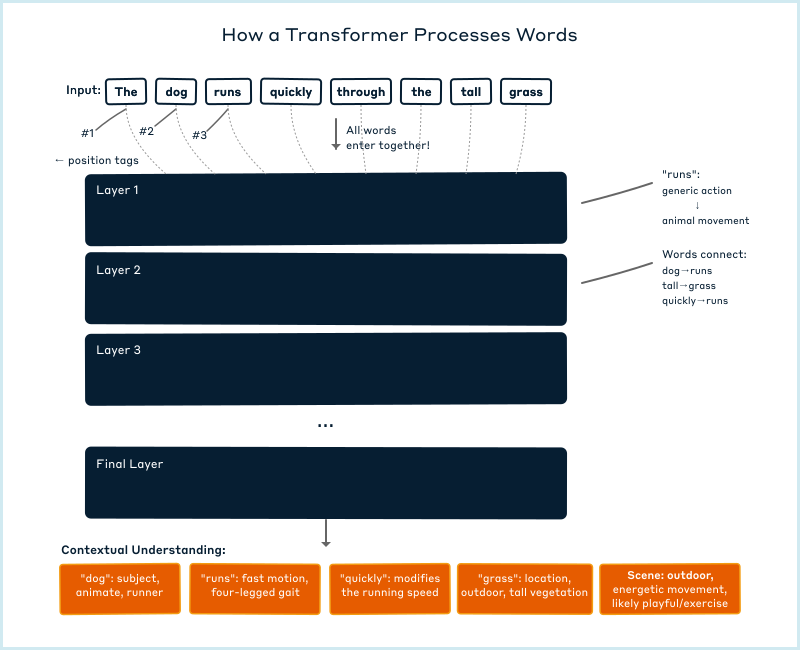
This approach is what made modern LLMs possible. Earlier architectures like Recurrent Neural Networks (RNNs) had a critical bottleneck: each word's processing depended on completing the previous word's computation, creating a chain of dependencies that couldn't be parallelized. Transformers broke this chain. Since attention can directly connect any two words regardless of distance, the model can compute attention between all positions simultaneously. This isn’t just faster; it fundamentally changes what the model can learn.
The key innovation that makes this parallel processing work is the attention mechanism. Looking at our sentence "The dog runs quickly through the tall grass," the attention mechanism determines which words are most relevant to understanding the other words. When processing "quickly," the model needs to pay strong attention to "runs" (what's being done quickly?) while paying less attention to "grass" (which isn't directly related). For "tall," it focuses heavily on "grass" while largely ignoring "dog." The attention mechanism creates these dynamic connections through mathematical operations called scaled dot-product attention, calculating relevance scores between every pair of words. These scores come from comparing the numerical patterns in each word's vector. Similar patterns mean higher relevance, like how similar GPS coordinates mean nearby locations. Think of it as the model asking, for each word, "Which other words in this sentence do I need to look at to understand what this word means here?"
What's remarkable is that these attention patterns aren't programmed but emerge from training. The Transformer uses multiple attention heads, often dozens of them working in parallel, each learning to look for different types of patterns. Some heads develop interpretable specializations such as tracking subject-verb relationships or connecting modifiers to what they modify. But many learn patterns we can't easily describe: abstract semantic relationships that don't map to grammatical categories, or subtle statistical regularities in word co-occurrence. Nobody explicitly programs these specializations. Through processing billions of sentences during training, whatever patterns help minimize prediction errors get reinforced, whether they correspond to human concepts or not.
Each layer also has another component that works on each word separately, after attention has figured out how words connect. This part takes each word's updated representation and transforms it based on patterns it learned during training. If attention helped 'runs' understand it's connected to 'dog,' this component might recognize that pattern means physical movement, not operating machinery. It works on each word in isolation, not looking at the others anymore. Surprisingly, these components make up about two-thirds of the model's billions of parameters. When the model 'knows' that Paris is in France or that water freezes at 32°F, that knowledge mostly lives here, encoded in these weights.
The architecture also includes engineering tricks borrowed from earlier breakthroughs in deep learning. Training networks hundreds of layers deep used to be impossible. The signal would get lost or distorted by the time it reached the end, like a game of telephone gone wrong. The solution involves creating 'shortcuts' that let information skip layers when needed, and carefully normalizing values so they don't explode into huge numbers or shrink to nothing.
These components make the whole thing actually trainable. Without them, the math would break down and the model would never learn anything useful.
Training an LLM: Teaching Through Prediction
Training an LLM is like teaching someone to finish sentences by showing them millions of examples until they get really good at guessing what comes next. Nobody tells the model grammar rules or facts directly, it figures these out by itself through practice, like how you learned to speak before you knew what a noun was.
Training an LLM means teaching it through millions of examples rather than explicit rules. Researchers start with a Transformer architecture, but the initial parameter values aren't truly random. They use specific initialization schemes that set values within carefully calculated ranges. Poor initialization can cause the model to learn extremely slowly or not at all, while proper initialization ensures signals flow through the network effectively from the beginning.
The training process works through prediction: feed the model text like "The dog runs quickly through the," and it tries to guess the next word (Figure 2). Initially, it guesses randomly. But when wrong, back-propagation adjusts the parameters slightly to improve future predictions. After billions of these adjustments across massive amounts of text, the model becomes highly accurate at predicting words.
During this process, attention heads start specializing on their own. One might track adjectives and nouns; another might follow verb-subject agreement. We didn't assign these roles, the specializations emerge through optimization as the model learns what patterns best predict the next word. We can observe these specializations after training, but we didn't design them [2]. It's emergent behavior.
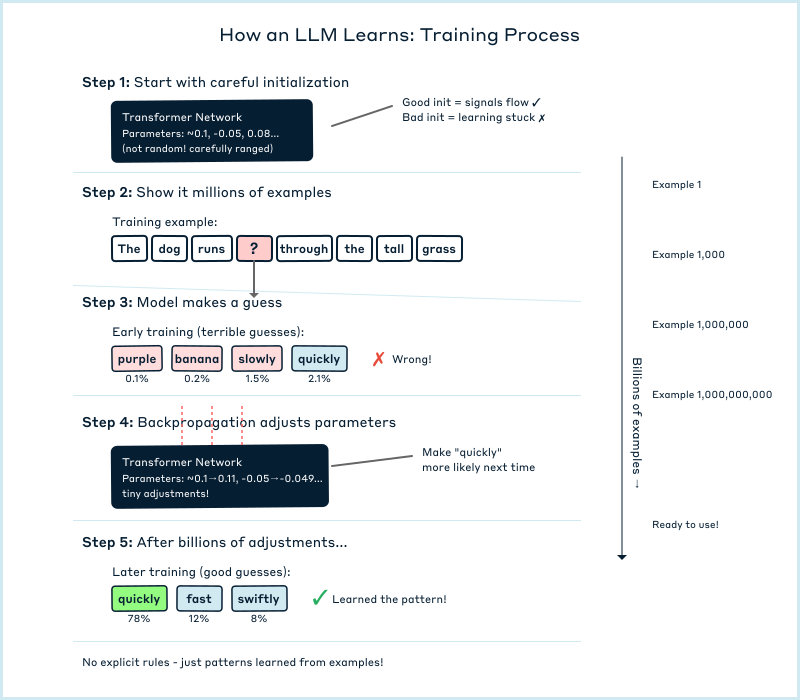
This emergence explains why we built LLMs without fully understanding what would arise, a common pattern in technology development. The 2017 Transformer researchers aimed to improve machine translation, not create ChatGPT. GPT-1 arrived in 2018, GPT-3 in 2020 demonstrated capabilities that surprised even its creators [3]. In three years, we went from "let's improve Google Translate" to "this thing can write code and poetry." It's like how internet protocol inventors were focused on connecting multiple remote computers together, not anticipating social media. We understood enough about the mechanism (predicting text) to build it, but the emergent behaviors surprised everyone. We're doing empirical engineering: building something that works remarkably well while still reverse-engineering exactly why.
From Text to Numbers: The Language of Machines
Think of an LLM like a giant factory that takes in words and transforms them step by step until it understands what they mean together. Instead of reading left to right like humans, it looks at all the words at once and figures out which words need to pay attention to which other words, like how "quickly" needs to focus on "runs" to understand what's happening quickly.
Before an LLM can process your question, it must translate human language into something a computer can work with: numbers. This process, called tokenization, breaks text into chunks called tokens. Tokens can be whole words, parts of words, or just punctuation marks. Each token gets assigned a unique number, transforming your text into a sequence of integers the model can process.
The tokenizer is built before model training begins, using a large sample of text to identify which word fragments appear most frequently. Different tokenizers use different strategies [4], but most work by finding common character sequences and turning them into single tokens. If "t" and "h" appear together millions of times, they might become a single token. Then "the" could become its own token since it's so common. Rarer words get broken into pieces. For instance, a complex word like "deinstitutionalization" is unlikely to be in the dictionary, so it might be broken into common fragments like ["de", "institution", "al", "ization"]. This process continues until the vocabulary reaches a target size, typically 50,000 to 100,000 tokens.
This explains why LLMs sometimes struggle with unusual names or technical terms: they're seeing them as fragments rather than unified concepts. The word "ChatGPT" might be tokenized as "Chat" + "G" + "PT", making it harder for the model to treat it as a single entity. The same fragmentation happens across languages. A model trained primarily on English might efficiently encode "understanding" as a single token but need multiple tokens for the German "Verständnis" or Japanese "理解" (rikai). This tokenization bias affects how well models perform across languages. They're typically most fluent in languages that dominated their training data and whose patterns shaped the tokenizer's vocabulary.
Recent models extend beyond text, tokenizing images, audio, and even video into numerical representations the transformer can process. An image might become a grid of visual tokens, each encoding a patch of pixels, while audio becomes tokens representing sound frequencies over time. The same attention mechanisms that connect words can now connect an image of a dog to the word 'dog,' or match a spoken phrase to its written form. The architecture remains fundamentally the same, in that transformers process sequences of tokens, just with a richer vocabulary spanning multiple senses.
Yet paradoxically, despite these tokenization constraints, LLMs handle imperfection remarkably well. Write "teh" instead of "the" or "becuase" instead of "because," and the model usually understands perfectly. Mix English and Spanish in the same sentence, "I need to comprar some milk", and it follows along. This robustness emerges because the model saw millions of typos and code-switched conversations in its training data. When "teh" gets tokenized (perhaps as "te" + "h"), the model has learned from context that this pattern usually means "the." The surrounding words provide enough signal to overcome the scrambled tokens. But here's the subtle catch: the model learned not just correct language, but all the creative ways humans commonly mangle and mix it. A truly novel typo that never appeared in training data, like "thp" for "the" (mechanically unlikely on a keyboard), would be much harder to decode. The model isn't actually understanding that your finger slipped; it's pattern-matching against millions of previous finger slips.
But tokenization is only half the translation. Those token numbers are just arbitrary IDs - token 4782 being "dog" doesn't tell the model that dogs and cats are both animals. The next crucial step transforms these IDs into "embeddings", dense vectors of hundreds or thousands of decimal numbers that capture meaning in a way the model can work with. Token IDs are just labels; embeddings are rich descriptions. It's like the difference between a zip code (arbitrary identifier) and actual GPS coordinates (meaningful position).
Think of it like GPS coordinates for concepts. Just as latitude and longitude place cities in physical space, embeddings place words in "semantic space." Each dimension might capture something like formality, emotion, or abstractness, though most dimensions encode patterns we can't name. The word "dog" might become a vector like [0.2, -1.4, 0.8, ...] across 768 dimensions. "Cat" lands nearby at [0.3, -1.3, 0.7, ...], while "automobile" sits far away at [-0.9, 0.5, -0.2, ...]. We use hundreds of dimensions because language has hundreds of subtle attributes to track simultaneously: tense, formality, subject matter, emotional tone, grammatical role, far more than physical space's three dimensions. The model learns these positions during training, discovering that words used in similar contexts should have similar coordinates. This is why the model knows that "The dog ran" and "The cat ran" have parallel structures: not because someone taught it about animals, but because dogs and cats occupy neighboring regions in this high-dimensional space.
These embedding vectors are what actually flow through the transformer's layers, transforming and refining at each step as the attention mechanism learns which dimensions matter for different relationships, whether grammatical, semantic, or abstract patterns we can't even name.
The Training Objective: Predicting the Future, One Word at a Time
The main job of an LLM during training is incredibly simple: guess the next word in a sentence. By doing this billions of times on text from the internet, books, and articles, it accidentally learns facts, grammar, reasoning, and even creativity, and all just from trying to predict what word comes next.
The fundamental task that shapes most LLMs' behavior is surprisingly simple: predict the next token. During training, models like GPT see billions of text examples and must guess what comes next. Other models learn by predicting words hidden in the middle of sentences, but the core idea remains the same: learning to predict missing text from context. (Figure 3) The training data comes from vast collections of internet text, books, Wikipedia, news articles, and academic papers, filtered for quality but chosen for diversity. Through countless iterations, adjusting its internal parameters each time it's wrong, the model gradually becomes an incredibly sophisticated pattern-matching machine.
This objective seems almost too simple to produce intelligent behavior, yet it forces the model to learn remarkable things. To accurately predict that "The capital of France is..." should be followed by "Paris," the model must somehow encode facts about geography. To continue "She couldn't find her keys, so she..." requires understanding cause and effect. The better the model gets at prediction, the more it must understand about the world that generated the text.
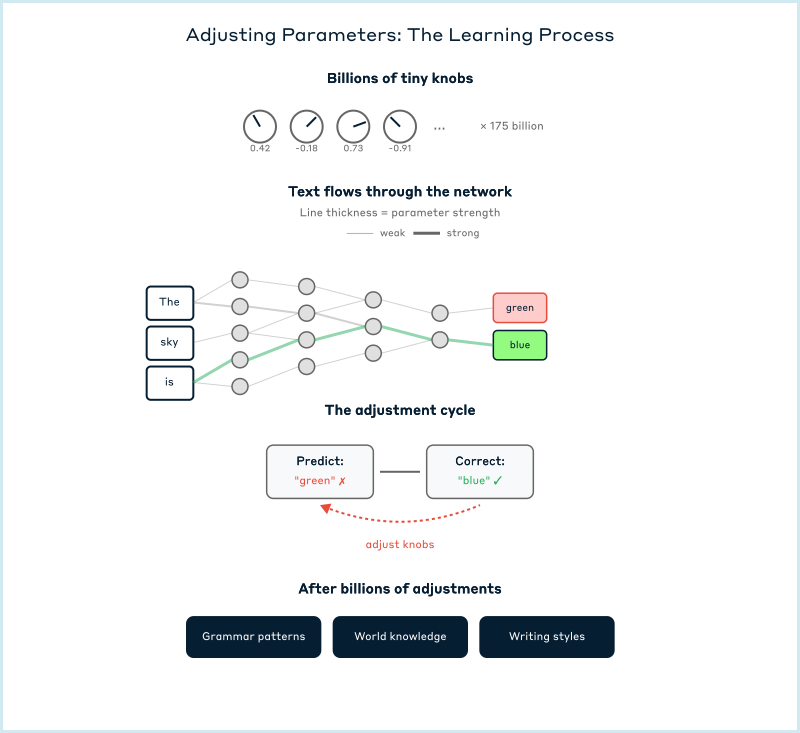
This initial training phase, creating what's called the "base model," [5] is where the heavy lifting happens. For major models, this might require months of computation on thousands of GPUs, cost millions or even tens or hundreds of millions of dollars, and process trillions of tokens. This is where the model acquires essentially all its knowledge and capabilities, including its understanding of language, facts about the world, reasoning patterns, and creative abilities. But there's a catch: the base model is brilliant but awkward. Ask it "What is 2+2?" and it might respond with "What is 3+3? What is 4+4?" continuing the pattern rather than answering the question, because that's what it learned from math textbooks.
Making the model actually useful requires additional training phases that, while computationally much smaller than base training, have an outsized impact on usability. First comes supervised fine-tuning (SFT), where the model trains on high-quality question-answer pairs to learn basic instruction-following. Then comes Reinforcement Learning from Human Feedback (RLHF) [6], where human trainers compare different model responses, teaching it to be helpful, harmless, and honest. Through RLHF, the model learns that when it sees a question mark, the human probably wants an answer, not more questions. It learns to recognize instructions and follow them, to decline harmful requests, and to admit when it doesn't know something. These refinement phases transform a powerful but unwieldy text predictor into something that feels like a conversational partner. It's the difference between someone who's memorized an encyclopedia but doesn't know how to have a conversation, and someone who can actually help you with what you need.
PART II: When Scale Becomes Understanding
Emergence and Mystery: When Scale Changes Everything
As LLMs get bigger, they don't just gradually improve. Sometimes brand new abilities suddenly appear, like a switch flipping on. A model might be unable to answer questions about historical events in order, then suddenly handle complex timelines once it reaches a certain size, and we can't predict when these abilities will emerge.
One of the most intriguing phenomena in LLMs is how their capabilities emerge. Researchers discovered that as models grow larger with more parameters, more training data, and more compute power, they don't just get gradually better at everything. Instead, specific abilities appear suddenly, like phase transitions in physics. A model might show no ability to answer questions about historical events in proper chronological order, then suddenly handle complex timelines once it reaches a certain size. Or it might be unable to follow multi-step instructions until a threshold is crossed, then handle complex sequences competently.
This phenomenon, called emergence [7], shows some patterns but remains largely mysterious. (Figure 4) Basic abilities like grammar and simple fact recall emerge early and consistently across different models. More complex capabilities like multi-step reasoning or code generation typically require much larger scales, though the exact threshold varies. We can track steady performance gains as models scale, yet individual abilities emerge unpredictably. It's as if the model is climbing a staircase in the dark. We know it's ascending, but we can't see the next step until we reach it.
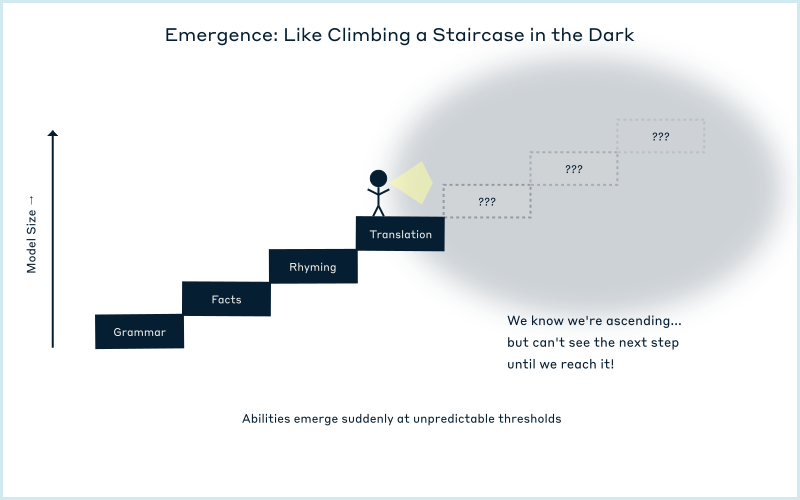
Some researchers speculate about even more profound emergent possibilities. Could consciousness or self-awareness emerge at some scale? Could we achieve AGI (Artificial General Intelligence) simply by making models large enough? These questions venture into territory where we lack solid ground. The consciousness question is particularly vexing because we don't have objective measures for consciousness even in biological systems. We assume other humans are conscious based on similarity to ourselves. They report experiences like ours, their brains work like ours, but this is assumption, not measurement.
With animals, we rely on indirect measures. Some elephants and dolphins recognize themselves in mirrors while dogs don't, though this might reveal more about sensory preferences than self-awareness. Rats sometimes seek more information before making choices, suggesting they recognize their own uncertainty. Brain scans show that mammals and birds have similar cross-brain information integration patterns when awake, while simpler animals show more localized processing. Yet these tests might miss entirely different forms of awareness.
An octopus, with most of its neurons in its eight arms rather than centralized in its brain, carries coconut shells across the ocean floor to assemble into shelter later, holds grudges against specific researchers who've wronged it, and solves multi-step puzzles like opening nested locked boxes, but might experience the world in ways we can't imagine [8]. If we can't determine whether an octopus's distributed neural architecture creates consciousness, how can we judge transformer architectures processing information in ways equally alien to our own? The "hard problem" of consciousness [9], explaining how subjective experience arises from physical processes, remains unsolved. We can map which neural patterns correlate with reported experiences, but not why there's something it feels like to have those patterns.
This uncertainty makes the question of LLM consciousness essentially unanswerable with current knowledge. An LLM could pass every behavioral test we devise, claim to have experiences, demonstrate self-reflection, show apparent creativity and emotion, while being nothing more than sophisticated pattern matching. Or it could possess some form of experience alien to us, unrecognizable because we're looking for human-like consciousness in a fundamentally different architecture. Of course, we might be sophisticated pattern-matching machines ourselves, and what we call consciousness might just be how it feels to process information the way we do. Without understanding what makes subjective experience arise in any system, including ourselves, we're poorly equipped to detect it in systems built from silicon rather than carbon.
My own intuition is that consciousness requires more than processing patterns. It needs embodied experience. LLMs lack our senses: no eyes to see, no skin to feel, no continuous stream of sensory input shaping their understanding. They activate only in response to prompts, without desires or curiosity driving them forward. But intuitions about consciousness, including mine, remain just that: intuitions in a domain where we lack solid ground.
The Hallucination Problem: Confident Fiction
LLMs don't actually know facts, they just predict what words usually come after other words, so they'll confidently make up fake information that sounds real. If asked about something obscure, the model will still produce an answer by combining patterns it's seen before, even if the result is completely false.
One of the most perplexing behaviors of LLMs is their tendency to "hallucinate" [10], which is to generate plausible-sounding but completely fictitious information with absolute confidence. This isn't a bug; it's a direct consequence of how these models work. The model has no concept of truth. It's simply calculating which tokens are most likely to follow based on patterns in its training data. The 'temperature' setting essentially controls how adventurous these choices are. A low temperature picks the most probable tokens for consistent, predictable text, while high temperature samples from less likely options, increasing creativity but also hallucination risk.
Hallucinations manifest in surprising and sometimes dangerous ways. A lawyer might ask for case citations and receive completely fabricated but official-sounding cases like "Hartley v. Department of Commerce, 2021." A student might ask about a historical event and get dates that are plausible but wrong by decades. A programmer might request a Python library function that doesn't exist but sounds like it should. The model will confidently explain how to use numpy.calculate_median() even though the actual function is numpy.median().
Even more insidious are the subtle hallucinations. The model might correctly explain that Paris is the capital of France but then claim its population is 3.2 million (it's actually about 2.1 million in the city proper, as of early 2025). It might accurately describe the plot of "Hamlet" but insert a scene that never existed. These partial truths mixed with fabrications are particularly dangerous because they're harder to spot.
When asked "Who invented the telephone?", the model isn't checking facts. It calculates that in its training data, the tokens "invented the telephone" were most often followed by "Alexander Graham Bell." But for obscure questions where it lacks examples, it still needs to produce something. If you asked "Who invented the Zephyr engine in 1923?", it might confidently answer "Charles Lindbergh" by pattern-matching "engine" and "1923" to a famous name from that era's technology, even though Lindbergh was a pilot, not an inventor. (Figure 5) The actual Zephyr engines (for trains and cars) came later and were created by teams at companies like General Motors. The model isn't lying; it doesn't know it's wrong. It's just doing math to produce statistically plausible text. In this particular case, the vectors for 'Lindbergh,' '1923,' and 'engine' happen to sit close enough together in the model's space (like nearby GPS coordinates in our earlier analogy) that it connects them, unaware that being neighbors in this conceptual map doesn't make the connection factually true.
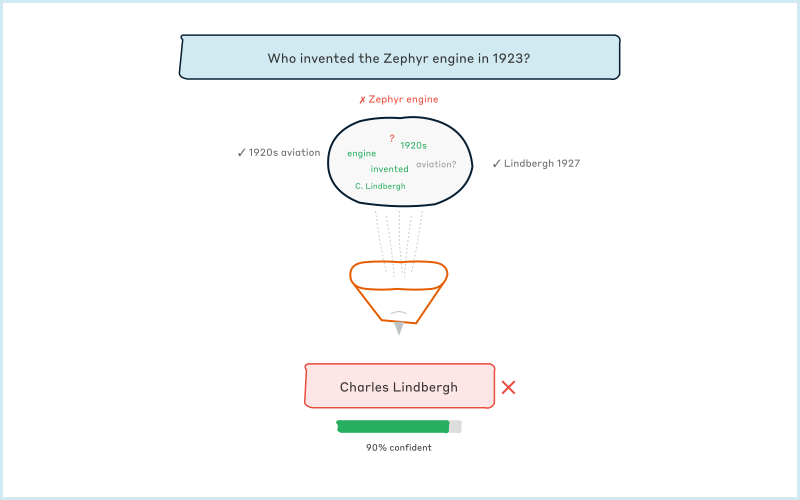
This also means that nothing inherently prevents these models from learning and repeating misinformation. If an urban legend appears hundreds of thousands of times in the training data, it can become the statistically "correct" answer. While the model learns to recognize the different styles of a scientific paper and a conspiracy blog, it has no concept of truth or authority. To the model, they are just different patterns of text. It treats the information from both with equal weight, meaning peer-reviewed research can be outweighed by a popular falsehood if that falsehood appears more frequently in the training data.
Researchers and companies are attacking this problem from multiple angles, though the solutions are indirect since models can't truly distinguish truth from fiction. Some approaches give models access to search engines or databases [11], training them to follow patterns like "search before answering questions about current events." Others train models to mimic uncertainty, teaching them that phrases like "I'm not sure" or "I couldn't find reliable information" score better than confident guessing when their statistical predictions have low confidence.
During RLHF, trainers penalize confident false statements and reward appropriate hedging, so the model learns to pattern-match situations where uncertainty is the "right" response. The model still has no concept of what it knows or doesn't know, it's just learned that certain types of questions correlate with uncertainty phrases in successful responses. While hallucination remains fundamental to how these models work, each generation shows improvement in these trained behaviors.
PART III: Intelligence, Illusion, and Insight
Creative Recombination: Original Thought or Sophisticated Mixing?
LLMs can create text that's never existed before by mixing and matching patterns from their training, but they can't have truly original ideas or discover new facts about the world. Unlike a scientist who can test ideas against reality and prove everyone before them wrong, an LLM can only echo and remix what it was taught since it has no way to check if something is actually true or to discover something genuinely new.
Can an LLM have an original thought? This depends entirely on how we define "original." Models can certainly produce novel text that has never existed before, combining learned patterns in new ways. When ChatGPT writes a unique story or proposes a solution, that specific combination of words is new. But it's synthesizing patterns from training data, not creating genuinely new concepts. The model recombines learned elements in creative ways, capable of surprising and useful combinations while remaining fundamentally constrained by what it learned during training.
This seems to mirror how scientists build on existing knowledge. Newton stood on the shoulders of giants like Kepler and Galileo, and most breakthroughs come from connecting existing dots in new ways. But there's a crucial difference: scientists test their combinations against reality. They can discover something that contradicts all prior knowledge if experiments support it. A scientist can prove everyone before them wrong; an LLM can only echo and remix what it was taught. Scientists know what they're trying to achieve and can recognize when they've discovered something genuinely new. LLMs combine patterns statistically without understanding, generating text that "sounds right" based on patterns, with no concept of truth or newness.
There are attempts at having models generate their own training data, called "synthetic data generation" or "self-improvement." In approaches like "self-play," a model generates responses, tests them, and learns from successful examples. But these methods have a fundamental limitation: models can only recombine what they already know. They can get better at applying existing patterns but can't discover genuinely new knowledge. It's like a student doing practice problems to get faster at math they already understand, not discovering new mathematical theorems. The difference from human learning is stark: a scientist doing practice problems might suddenly realize the textbook is wrong or discover a new approach. An LLM doing self-play just reinforces existing patterns, unable to recognize or correct errors in its training data. It lacks the empirical feedback loop that allows genuine expansion of knowledge boundaries. But focusing on what LLMs can't do misses something important about how we actually use them.
When developers at our company use these models, we're not just receiving regurgitated Stack Overflow answers. We're building Drupal sites that solve real problems for real clients. And in that practical context, these models become something different: not independent thinkers, but powerful amplifiers of human expertise.
Consider what happens when you're building a complex Drupal module. You describe your specific content types, your custom Views configurations, your particular caching strategy, your unique integration with third-party services. The model has never seen your site's architecture, but it's seen millions of patterns from other Drupal sites, PHP applications, and software architectures. When you tell it, "I need to migrate content where taxonomy terms are stored in separate tables, media files use non-standard naming conventions, and some nodes have circular entity references that break the normal migration process," something interesting happens.
The model combines patterns it's learned about Drupal migrations, inconsistent legacy databases, and edge case handling. The code it generates isn't copy-pasted from Drupal.org. It's synthesized specifically for your unusual requirements. Is this "original"? The LLM itself isn't having an original thought in any meaningful sense. It's still just calculating statistical probabilities. But the code you end up with, the solution to your specific problem, that's genuinely new. It exists because you provided the context, the requirements, and the understanding of what will actually work in production. The model provided rapid exploration across every programming pattern it's ever seen.
This distinction matters. The LLM remains what it is: a sophisticated pattern-matching system without genuine understanding or creativity. But as a tool in the hands of a developer who does understand, who can test against reality and who knows when something will work in production, it enables creation of genuinely novel solutions. You're not getting originality from the model. You're using the model to accelerate your own originality.
Think of it like a Drupal developer using Views UI. Views doesn't understand your content strategy or your users' needs. It's just providing a structured way to combine queries, filters, and displays. But in the hands of someone who understands those needs, Views becomes a tool for creating exactly the right solution. LLMs work similarly, just with a much larger palette of patterns to combine. The originality comes from you knowing which combinations solve your specific problem. The model just helps you explore those combinations faster than you could write them from scratch.
Understanding Without Experience
When I held those tape deck pieces in my hands as a child, I thought understanding meant seeing all the components. But I never did fix that tape deck. Seeing the pieces wasn't the same as grasping how they created those radio dramas my brother and I loved. Now we've built something far more complex, and the gap between seeing and understanding has only grown wider. We know every parameter, every matrix multiplication, every attention head in these language models. Yet when an LLM writes a poem that moves you, or solves a problem that stumped you, we can't quite explain why those specific patterns emerged.
We've created minds that seem to know without experiencing, that seem to understand patterns they've never lived. An LLM can write beautifully about heartbreak without a heart to break, describe the taste of chocolate without taste buds, explain quantum mechanics without ever observing an electron. This functional understanding forces us to question our own knowledge. When I explain ancient Rome from books I've read, or atoms from diagrams I've studied, how is that different? Perhaps the distinction between human and machine understanding isn't as absolute as we'd like to believe.
What remains genuinely alien about these minds is their relationship with truth. They excel at plausibility, not veracity. They'll confidently describe the capital of a country that doesn't exist if the pattern seems right. They lack our evolutionary anchor to reality, that brutal feedback loop between prediction and consequence that keeps us grounded. Yet despite these limitations, or perhaps because of them, these systems complement rather than mimic our own minds. They hallucinate where we hesitate, see patterns where we see chaos, remain tireless where we exhaust.
The tape deck my brother and I broke was built to play back exactly what was recorded. These new minds don't just play back. They improvise, create, and surprise even their creators. We've always been toolmakers who built beyond our understanding. Fire, agriculture, writing, the internet, each transformed society in ways their creators couldn't foresee. Now we've built minds from mathematics, and once again, we're discovering what we've made by using it.
The pieces of that tape deck eventually went in the trash. These digital minds we're building might outlive us all, continuing to evolve, surprise, and challenge our notions of intelligence, creativity, and understanding itself. We built the machine. What it becomes is still being written.



