.png)


👋🏼 This is part of series on concurrency, parallelism and asynchronous programming in Ruby. It’s a deep dive, so it’s divided into several parts:
- Your Ruby programs are always multi-threaded: Part 1
- Your Ruby programs are always multi-threaded: Part 2
- Consistent, request-local state
- Ruby methods are colorless
- The Thread API: Concurrent, colorless Ruby
- Bitmasks, Threads and Interrupts: Concurrent, colorless Ruby
- When good threads go bad: Concurrent, colorless Ruby
- Thread signal handling: Concurrent, colorless Ruby
- Thread and its MaNy friends: Concurrent, colorless Ruby
- Fibers: Concurrent, colorless Ruby
- Processes, Ractors and alternative runtimes: Parallel Ruby
- Scaling concurrency: Streaming Ruby
- Abstracted, concurrent Ruby
- Closing thoughts, kicking the tires and tangents
- How I dive into CRuby concurrency
You’re reading “Bitmasks, Threads and Interrupts: Concurrent, colorless Ruby”. I’ll update the links as each part is released, and include these links in each post.
- Interrupting Threads
- Managing threads
- An important interruption
- Stuck threads
- Thread shutdown
- raise and kill
- Don’t kill threads
- Interrupt your threads safely
- ensure cleanup
- Don’t use timeout
- Use term_on_timeout with rack-timeout
- Monitor your thread costs
- Get a handle_interrupt on things
- Thread.handle_interrupt
- raise and kill
- The way you ensure success
- Signal handling
Interrupting Threads 🧵
The Ruby thread scheduler is rude. There, I said it.
It’s always telling your threads how to run, when to run, how long they can run - it stops them whenever it wants and then tells other threads they have to start working. It’s bossy as hell. On top of that, it’s not even polite about it. It feels free to interrupt your threads - it decides when, and your threads have to just play along and listen.
But threads put up with it. They even benefit from it, if you can believe that. The thread scheduler may be abrupt, but it’s looking out for the runtime. If that’s the case - there must be a good reason… Why do threads put up with these scheduler shenanigans?
Managing threads 👷🏼♂️👷🏻♀️
The primary need for a thread scheduler is efficiency and fairness. It manages what threads are running, for how long, and what context each thread gets loaded with.
In normal operation this comes down to a few things:
- Time sharing: every thread, under normal circumstances, gets roughly 100ms of CPU runtime1. Since only one thread can run Ruby code at a time2, this keeps a single thread from dominating the program3
- Blocking operations: certain operations will “block” a thread. Most forms of IO, and sleep, for instance. When the thread blocks, the thread scheduler allows other threads to run
- Priority: we can suggest a priority for our threads, and the thread scheduler will take it into consideration when choosing what to run next
- Passing control: we can suggest actions to the thread scheduler, like passing control or stopping the current thread so other threads can take over
- Locking: we can synchronize access to resources, and the thread scheduler chooses the order of access to the resource
How does it handle all this?
An important interruption
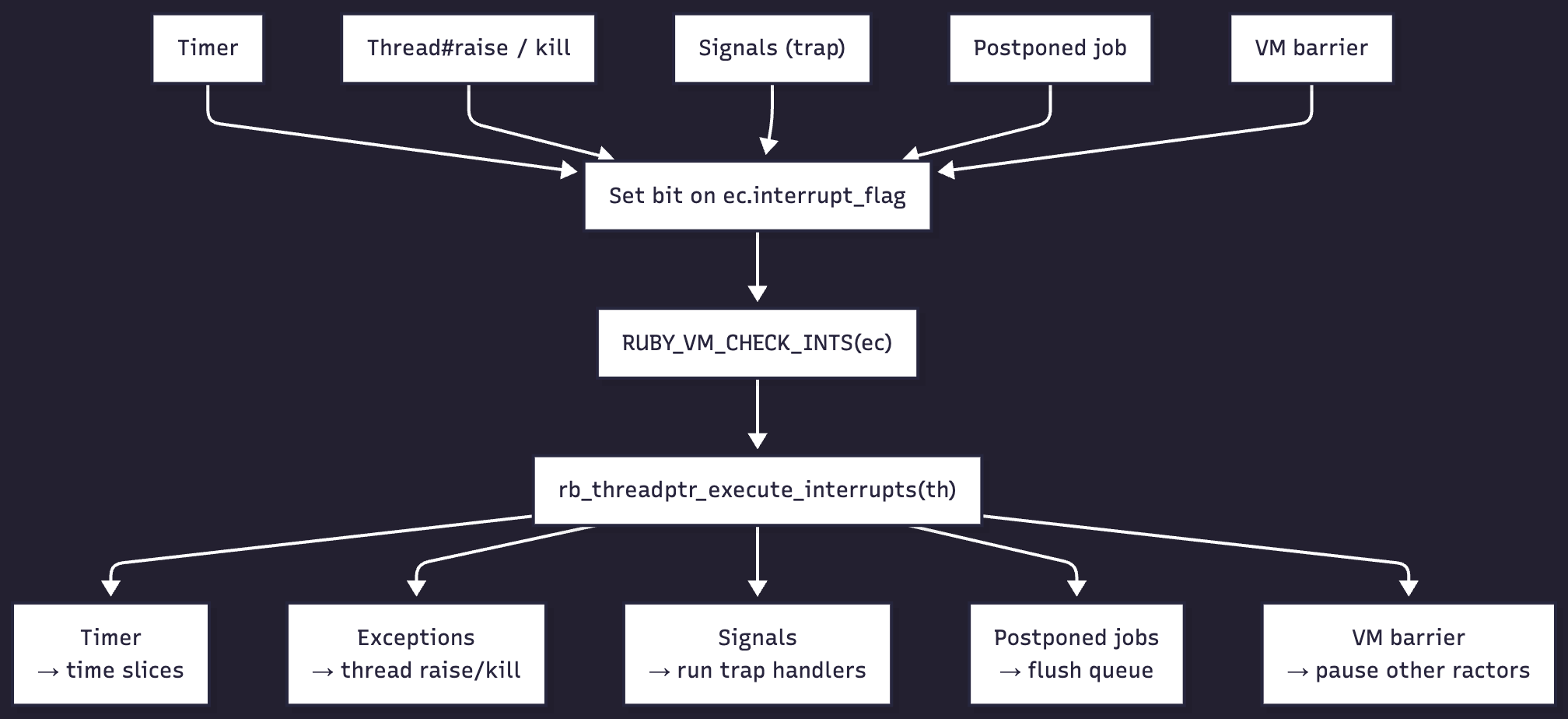
The scheduler isn’t a single object - it is the behavior produced by specific VM checks and functions. In this post, we’ll focus on time sharing, priority, and interrupting threads - which are managed through a concept deeply woven into CRuby - a set of functions the VM calls at specific checkpoints.
In the CRuby runtime, this concept revolves around “interrupts”4. It contains a set of possible events that could “interrupt” the flow of a Ruby program in general, and different threads in particular. There are several interrupt events possible:
- Timer interrupt
- Trap interrupt
- Terminate interrupt
- VM barrier interrupt
- Postponed job interrupt
- Pending interrupt
In the CRuby internals, these are represented by an integer mask. If we took the C code and represented it in Ruby, it would look like this (each mask is a hex value):
A sidenote on integer masks
What is an integer mask, and why would CRuby represent internal states this way?
📝 “mask” is a conventional name for a pattern to isolate specific bits. A “mask” sounds like something that would cover up something else (ie, a mask covering your face). In a sense, these serve a similar purpose - the mask is put on or taken off, clearing or setting bits and testing them efficiently.
Integer masks provide a compact and efficient way to represent multiple program states within a single number. Each state is stored as a single bit - representing a power of 2 - so in concept a 64-bit integer can represent up to 64 independent on/off states. Here’s a visualization of the first 8 bits in a number (a byte):
0 0 0 0 0 0 0 0 | | | | | | | | | | | | | | | +- 1 (2^0) 0x01 | | | | | | +--- 2 (2^1) 0x02 | | | | | +----- 4 (2^2) 0x04 | | | | +------- 8 (2^3) 0x08 | | | +--------- 16 (2^4) 0x10 | | +----------- 32 (2^5) 0x20 | +------------- 64 (2^6) 0x40 +--------------- 128 (2^7) 0x80 Byte Decimal Power HexThis is an adaptation of a visual from a blog post about bitwise operations: https://www.hendrik-erz.de/post/bitwise-flags-are-beautiful-and-heres-why
Being able to represent all this information in a compact way is convenient, but checking whether it matches a particular mask is also very fast. CPUs are well optimized for this sort of thing.
There are several operators for performing these checks called “bitwise” operators. Here’s a table of the operators, and the impact they have on bits:
| 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 | 1 | 0 |
| 1 | 1 | 1 | 1 | 0 | 0 |
We can demonstrate using the Ruby binary syntax5:
- Bitwise AND:
- Bitwise OR:
- Bitwise XOR:
- Bitwise NOT:
The & 0xFF forces us into 8-bits to demonstrate the NOT correctly
These aren’t relevant to masks specifically, but for completeness, you can also shift bits left or right to change values:
0b00000101 << 1 # Left shift # 0b00001010 0b00000101 >> 1 # Right shift # 0b00000010Back to the interrupt queue
The reason these efficient mask checks matter, is because these interrupts are checked a lot.
Here’s a program that simply iterates for a little while, incrementing a counter6:
This will check interrupts five hundred thousand times7, one check for each iteration of the loop. That’s a lot. And if your programming language is going to do something a lot, it needs to be efficient. The overhead of checking for interrupts should be undetectable in your Ruby program. As discussed earlier, bit mask checks are one of the most efficient checks you can make.
But why does this innocuous program need to check for interrupts so often? It’s part of the opt-in! The Ruby virtual machine is filled with checkpoints where it is safe for Ruby internals to check for interruptions in the program. One of those checkpoints is an if statement (did you think I’d say while loop?!).
Let’s disassemble this into Ruby bytecode:
puts RubyVMInstructionSequence.compile( DATA.read ).disassemble __END__ i = 0 while i < 500_000 i += 1 endWhich gives us the following:
0000 putobject_INT2FIX_0_ 0001 setlocal_WC_0 i@0 # | i = 0 0003 jump 16 # | jump to while i < ... ... 0009 getlocal_WC_0 i@0 # | i += 1 0011 putobject_INT2FIX_1_ # | 0012 opt_plus # | 0014 setlocal_WC_0 i@0. # |____________ 0016 getlocal_WC_0 i@0 # | i < 500_000 0018 putobject 500000 # | 0020 opt_lt # | 0022 branchif 9 # | jump to instruction 9, # | which is i += 1 # |____________ 0024 putnil 0025 leaveFor the moment you can trust me that branchif is the critical section here. Let’s see how branchif is defined:
DEFINE_INSN branchif (OFFSET dst) (VALUE val) () { if (RTEST(val)) { RUBY_VM_CHECK_INTS(ec); JUMP(dst); } }❗️Woah! What the heck is that weird syntax? Is that Ruby? Is that C?
It’s neither! This is a special, CRuby internal specific DSL that is similar to C. In CRuby, there is a file called insns.def which defines every instruction the Ruby Virtual Machine (YARV) can run.
- DEFINE_INSN tells us we are defining an instruction
- branchif is the instruction name
- OFFSET dst is the argument - 9 in our case, which would take us to 0009 getlocal_WC_0
- VALUE val is the last value pushed on the stack - the result of i < 500_000
- () that last empty set of parens is the optional return value - we don’t have one - we jump if val is true, or we fall through
Interesting! A couple things stick out to me here when theRTEST(val) (our while condition) is true:
- We’re running RUBY_VM_CHECK_INTS anytime we call an if statement. RUBY_VM_CHECK_INTS is a key function for checking the interrupt queue. It’s embedded within VM instructions themselves!
- We JUMP to a destination8
A Nerdy Aside 🤓
In the typical case of a branchif, it would jump to the appropriate part of an if statement:
if is_it_true? # if it is true, jump here! else # if it isn't, jump here! endWhat caught my eye is that internally an if statement basically acts like goto! Sorry Dijkstra9.
And because branchif can jump anywhere you tell it, that also means it can jump to previous code as well. In the case of a while loop, branchif truly takes on its goto roots. Instead of jumping to a future piece of code, it reruns the content of the while loop by jumping back to earlier instructions!
Pardon that interruption
So now we know that interrupts are woven into vm instructions themselves in insns.def - where else?
- Method invocations
- IO
- Threads
- Processes
- The Regex engine
- BigNumber
And there are various function calls that ultimately get invoked: RUBY_VM_CHECK_INTS_BLOCKING, RUBY_VM_CHECK_INTS, rb_thread_check_ints, vm_check_ints_blocking, vm_check_ints.
Fun fact: one of the places RUBY_VM_CHECK_INTS is called is from the once bytecode instruction. An unexpected callback to my article The o in Ruby regex stands for “oh the humanity!”
Want to double the number of checks from our example? Let’s add a method:
def add(a, b) a + b end i = 0 j = 0 while i < 500_000 i += 1 j = add(i, j) endNow CRuby checks the interrupt queue one million times10! That’s because of the opt_send_without_block instruction, which is one of the instructions for Ruby method calls:
DEFINE_INSN opt_send_without_block (CALL_DATA cd) (...) (VALUE val) { // ... val = vm_sendish(ec, GET_CFP(), cd, bh, mexp_search_method); // Before returning from exec, int check! JIT_EXEC(ec, val); // ... }👆More of that fancy CRuby DSL
In the end, despite the myriad entry points into it, they all call the same thing: rb_threadptr_execute_interrupts.
😮💨 Why am I showing all of this low-level stuff?
I think understanding the runtime at a deeper level can actually make using a programming language simpler. Or at the very least, less mystical.
Explaining these pieces shows that a “thread scheduler” is just a program we can understand - its functions being called at particular checkpoints, same as how our own programs run.
Interrupt refresher
Before we start interrupting, let’s refresh on the types of interrupts.
- Timer interrupt: signals a periodic safepoint so Ruby can reschedule threads, deliver signals, and perform VM housekeeping
- Trap interrupt: indicates a caught POSIX signal (e.g., SIGINT) that Ruby should deliver as an exception
- Terminate interrupt: requests asynchronous termination of a thread (e.g., via Thread#kill) or from another ractor.
- VM barrier interrupt: forces threads in other ractors to reach a safepoint so global VM operations can proceed safely
- Postponed job interrupt: triggers execution of deferred internal C callbacks (registered via rb_postponed_job_register)
- Pending interrupt: marks that an asynchronous exception or signal is queued but delivery is deferred until a safe point.
Let’s see how they’re called and then see how they work!
Interrupt masks
CRuby has macros for setting each of the interrupt flags:
#define RUBY_VM_SET_TIMER_INTERRUPT(ec) ATOMIC_OR((ec)->interrupt_flag, TIMER_INTERRUPT_MASK) #define RUBY_VM_SET_INTERRUPT(ec) ATOMIC_OR((ec)->interrupt_flag, PENDING_INTERRUPT_MASK) #define RUBY_VM_SET_POSTPONED_JOB_INTERRUPT(ec) ATOMIC_OR((ec)->interrupt_flag, POSTPONED_JOB_INTERRUPT_MASK) #define RUBY_VM_SET_TRAP_INTERRUPT(ec) ATOMIC_OR((ec)->interrupt_flag, TRAP_INTERRUPT_MASK) #define RUBY_VM_SET_TERMINATE_INTERRUPT(ec) ATOMIC_OR((ec)->interrupt_flag, TERMINATE_INTERRUPT_MASK) #define RUBY_VM_SET_VM_BARRIER_INTERRUPT(ec) ATOMIC_OR((ec)->interrupt_flag, VM_BARRIER_INTERRUPT_MASK)📝 ec in these examples refers to the “execution context”, which contains per-thread information about the running Ruby program
This ATOMIC_OR macro is an abstraction on top of bitwise operations that stays roughly as efficient, but makes sure the operations run atomically - multiple operating system threads can run this at the same time - this helps to avoid read-modify-write issues.
Those abstractions obscure the actual bitwise operation - we learned a bit about Ruby bitwise operations earlier, let’s show these macros in Ruby form for clarity:
class ExecutionContext def initialize @interrupt_flag = 0 end def ruby_vm_set_timer_interrupt @interrupt_flag |= TIMER_INTERRUPT_MASK self end def ruby_vm_set_interrupt @interrupt_flag |= PENDING_INTERRUPT_MASK self end def ruby_vm_set_postponed_job_interrupt @interrupt_flag |= POSTPONED_JOB_INTERRUPT_MASK self end def ruby_vm_set_trap_interrupt @interrupt_flag |= TRAP_INTERRUPT_MASK self end def ruby_vm_set_terminate_interrupt @interrupt_flag |= TERMINATE_INTERRUPT_MASK self end def ruby_vm_set_vm_barrier_interrupt @interrupt_flag |= VM_BARRIER_INTERRUPT_MASK self end endNow let’s make our own slimmed down Ruby execution context that we can use with those methods:
def to_b(number) number.to_s(2).rjust(8, '0') end class ExecutionContext # ... def interrupt_to_b to_b(@interrupt_flag) end end📝 Integer#to_s can be handed a base, which converts to the specified base before returning as a string. In our case, we are converting it to base 2 to show it as binary. We then rjust to pad the left side with 0’s. So for instance, this returns to_b(2) as 00000010.
0 0 0 0 0 0 0 0 = 0x0 = interrupt_flag | | | | | | | | | | | +- TIMER_INTERRUPT_MASK | | | | +--- PENDING_INTERRUPT_MASK | | | +----- POSTPONED_JOB_INTERRUPT_MASK | | +------- TRAP_INTERRUPT_MASK | +--------- TERMINATE_INTERRUPT_MASK +----------- VM_BARRIER_INTERRUPT_MASKLet’s test the output:
def new_ec ExecutionContext.new end new_ec.ruby_vm_set_timer_interrupt.interrupt_to_b # => "00000001" new_ec.ruby_vm_set_interrupt.interrupt_to_b # => "00000010" new_ec.ruby_vm_set_postponed_job_interrupt.interrupt_to_b # => "00000100" new_ec.ruby_vm_set_trap_interrupt.interrupt_to_b # => "00001000" new_ec.ruby_vm_set_terminate_interrupt.interrupt_to_b # => "00010000" new_ec.ruby_vm_set_vm_barrier_interrupt.interrupt_to_b # => "00100000" new_ec.ruby_vm_set_timer_interrupt .ruby_vm_set_interrupt .ruby_vm_set_postponed_job_interrupt .ruby_vm_set_trap_interrupt .ruby_vm_set_terminate_interrupt .ruby_vm_set_vm_barrier_interrupt .interrupt_to_b # => "00111111" new_ec.ruby_vm_set_timer_interrupt .ruby_vm_set_interrupt .ruby_vm_set_trap_interrupt .ruby_vm_set_vm_barrier_interrupt .interrupt_to_b # => "00101011"When one of these is invoked, they don’t do anything on their own. They must be interpreted by one of the opt-in functions. At the end of every C call into a Ruby method, for instance:
static VALUE vm_call0_body(rb_execution_context_t *ec...) { // ... success: RUBY_VM_CHECK_INTS(ec); return ret;And after various types of “blocking” operations:
VALUE rb_thread_io_blocking_call(rb_blocking_function_t *func...) { // ... RUBY_VM_CHECK_INTS_BLOCKING(ec); // ... }But we’ve been beating around the bush long enough. We’re opting-in, great. What do these opt-in functions actually do?
It's masks all the way down
Let’s start with RUBY_VM_CHECK_INTS. This is a macro that gets replaced with a function call to rb_vm_check_ints. Inside of rb_vm_check_ints, it calls RUBY_VM_INTERRUPTED_ANY, and if that is true it calls rb_threadptr_execute_interrupts:
#define RUBY_VM_CHECK_INTS(ec) rb_vm_check_ints(ec) static inline void rb_vm_check_ints(rb_execution_context_t *ec) { if (UNLIKELY(RUBY_VM_INTERRUPTED_ANY(ec))) { rb_threadptr_execute_interrupts(rb_ec_thread_ptr(ec), 0); } }We want to get to rb_threadptr_execute_interrupts, but what does RUBY_VM_INTERRUPTED_ANY do?
static inline bool RUBY_VM_INTERRUPTED_ANY(rb_execution_context_t *ec) { // ... return ATOMIC_LOAD_RELAXED(ec->interrupt_flag) & ~(ec)->interrupt_mask; }Pretty simple. Let’s transcribe the code into our Ruby ExecutionContext class:
class ExecutionContext # ... def ruby_vm_interrupted_any? # (flag & ~mask) != 0 (@interrupt_flag & ~@interrupt_mask) != 0 end endThen set a flag and try it:
new_ec.ruby_vm_set_interrupt.ruby_vm_interrupted_any? # `ruby_vm_interrupted_any?': undefined method `~' for nil # (@interrupt_flag & ~@interrupt_mask) != 0 # ^Oops. I didn’t define @interrupt_mask. What is that exactly!? Looks like it’s defined alongside the interrupt_flag on the execution context.
struct rb_execution_context_struct { // ... rb_atomic_t interrupt_flag; rb_atomic_t interrupt_mask; // ... }👺 It’s a mask! It’s a flag! It’s a… confusing mental model…
We have interrupt_flag, we have the various *_INTERRUPT_MASK constants, and now interrupt_mask. Getting a little lost? I was.
I think it’s helpful to think of interrupt_flag as interrupt_pending, and interrupt_mask as interrupt_blocked. interrupt_flag contains operations waiting to run, and interrupt_mask contains operations that are currently blocked from running.
What is that & ~ business? Remember that & is Bitwise AND, and will only return 1 if both bits are 1. ~ is Bitwise NOT, and will change 1s to 0s, and 0s to 1s. As an example, using the TRAP_INTERRUPT_MASK:
0 0 0 0 0 0 0 0 = 0x0 = interrupt_flag 0 0 0 0 0 0 0 0 = 0x0 = interrupt_mask | +------- TRAP_INTERRUPT_MASK 0 0 0 0 1 0 0 0 & # interrupt_flag ~0 0 0 0 1 0 0 0 # interrupt_mask 0 0 0 0 1 0 0 0 & # interrupt_flag 1 1 1 1 0 1 1 1 # interrupt_mask 0 0 0 0 0 0 0 0 # TRAP_INTERRUPT_MASK is blocked!It’s only used in a few places - but it seems to serve roles on critical paths, like preventing recursive calls within Signal#trap handlers:
static int signal_exec(VALUE cmd, int sig) { rb_execution_context_t *ec = GET_EC(); volatile rb_atomic_t old_interrupt_mask = ec->interrupt_mask; // ... ec->interrupt_mask |= TRAP_INTERRUPT_MASK; // run signal handlers like Signal#trap ec->interrupt_mask = old_interrupt_mask; // ... }Because the interrupt_mask matches the interrupt_flag, RUBY_VM_INTERRUPTED_ANY won’t allow us to recursively trigger a signal handler. If we were to remove the interrupt_mask check, this code would call itself recursively forever and stack overflow:
pid = fork do Signal.trap("TERM") do Process.kill("TERM", Process.pid) end end Process.kill("TERM", pid) Process.waitall # Process.kill': stack level too deep (SystemStackError)But with the interrupt block code, it just runs forever, endlessly queueing up another trap. It’s kind of hard to find a compelling example of this mask - it mostly seems like very defensive programming!
If you’ve ever written a signal handler in rails and tried using a Rails.logger, you’ve hit the interrupt mask.
trap("TERM") do Rails.logger.info("TRAP fired!") end Process.kill("TERM", Process.pid) # log writing failed. can't be called from trap contextThis is because Mutex#lock raises an error if it is used inside an interrupt trap. If the interrupt mask has TRAP_INTERRUPT_MASK set, it means we’re running in a trap and blocking anymore trap interrupts from firing:
static VALUE do_mutex_lock(VALUE self, int interruptible_p) { rb_execution_context_t *ec = GET_EC(); rb_thread_t *th = ec->thread_ptr; if (th->ec->interrupt_mask & TRAP_INTERRUPT_MASK) { rb_raise(rb_eThreadError, "can't be called from trap context"); } // ... }Internally, Rails.logger is a Logger instance from the logger gem. That Logger writes to logs using a LogDevice. It uses the MonitorMixin, which gives it a built-in Monitor instance to synchronize with:
class Logger class LogDevice include MonitorMixin def write(message) handle_write_errors("writing") do synchronize do # We can't lock a mutex in a signal! # ... end end end end end📝 You can learn more about Monitors and synchronize in my post on The Thread API
For completeness, let’s add @interrupt_mask to our ExecutionContext class:
class ExecutionContext def initialize @interrupt_flag = 0 @interrupt_mask = 0 end # ... def with_interrupt_mask(mask) old_interrupt_mask = @interrupt_mask @interrupt_mask |= mask ensure @interrupt_mask = old_interrupt_mask end def ruby_vm_interrupted_any? # (flag & ~mask) != 0 (@interrupt_flag & ~@interrupt_mask) != 0 end def mask_to_b to_b(@interrupt_mask) end endNow #ruby_vm_interrupted_any? should work! And we can create sections where we block certain interrupts from being fired:
ec = ExecutionContext.new ec.ruby_vm_set_trap_interrupt ec.ruby_vm_interrupted_any? # => true ec.with_interrupt_mask(TRAP_INTERRUPT_MASK) do ec.ruby_vm_interrupted_any? # => false endThe interruption we’ve all been waiting for
The `interrupt`ion we've all been waiting for
Ok, now we know how to check and block the flags, we know the general places they are checked, and we know why it’s valuable for those checks to be efficient. Let’s look at what this has all led up to. What actually happens when an interrupt is detected? We’ll break it down piece-by-piece, but here’s the full function to start. Understanding this function gives us insight into when Ruby decides to yield, raise exceptions, and deliver signals:
int rb_threadptr_execute_interrupts(rb_thread_t *th, int blocking_timing) { rb_atomic_t interrupt; int postponed_job_interrupt = 0; int ret = FALSE; VM_ASSERT(GET_THREAD() == th); if (th->ec->raised_flag) return ret; while ((interrupt = threadptr_get_interrupts(th)) != 0) { int sig; int timer_interrupt; int pending_interrupt; int trap_interrupt; int terminate_interrupt; timer_interrupt = interrupt & TIMER_INTERRUPT_MASK; pending_interrupt = interrupt & PENDING_INTERRUPT_MASK; postponed_job_interrupt = interrupt & POSTPONED_JOB_INTERRUPT_MASK; trap_interrupt = interrupt & TRAP_INTERRUPT_MASK; terminate_interrupt = interrupt & TERMINATE_INTERRUPT_MASK; // request from other ractors if (interrupt & VM_BARRIER_INTERRUPT_MASK) { RB_VM_LOCKING(); } if (postponed_job_interrupt) { rb_postponed_job_flush(th->vm); } if (trap_interrupt) { /* signal handling */ if (th == th->vm->ractor.main_thread) { enum rb_thread_status prev_status = th->status; th->status = THREAD_RUNNABLE; { while ((sig = rb_get_next_signal()) != 0) { ret |= rb_signal_exec(th, sig); } } th->status = prev_status; } if (!ccan_list_empty(&th->interrupt_exec_tasks)) { enum rb_thread_status prev_status = th->status; th->status = THREAD_RUNNABLE; { threadptr_interrupt_exec_exec(th); } th->status = prev_status; } } /* exception from another thread */ if (pending_interrupt && threadptr_pending_interrupt_active_p(th)) { VALUE err = rb_threadptr_pending_interrupt_deque(th, blocking_timing ? INTERRUPT_ON_BLOCKING : INTERRUPT_NONE); RUBY_DEBUG_LOG("err:%"PRIdVALUE, err); ret = TRUE; if (UNDEF_P(err)) { /* no error */ } else if (err == RUBY_FATAL_THREAD_KILLED /* Thread#kill received */ || err == RUBY_FATAL_THREAD_TERMINATED /* Terminate thread */ || err == INT2FIX(TAG_FATAL) /* Thread.exit etc. */ ) { terminate_interrupt = 1; } else { if (err == th->vm->special_exceptions[ruby_error_stream_closed]) { /* the only special exception to be queued across thread */ err = ruby_vm_special_exception_copy(err); } /* set runnable if th was slept. */ if (th->status == THREAD_STOPPED || th->status == THREAD_STOPPED_FOREVER) th->status = THREAD_RUNNABLE; rb_exc_raise(err); } } if (terminate_interrupt) { rb_threadptr_to_kill(th); } if (timer_interrupt) { uint32_t limits_us = thread_default_quantum_ms * 1000; if (th->priority > 0) limits_us <<= th->priority; else limits_us >>= -th->priority; if (th->status == THREAD_RUNNABLE) th->running_time_us += 10 * 1000; // 10ms = 10_000us // TODO: use macro VM_ASSERT(th->ec->cfp); EXEC_EVENT_HOOK(th->ec, RUBY_INTERNAL_EVENT_SWITCH, th->ec->cfp->self, 0, 0, 0, Qundef); rb_thread_schedule_limits(limits_us); } } return ret; }There it is. Guess we’re done here! See you next time!
What a joker I am 🙄.
Let’s start walking through the function. Most of the function lives inside of a while loop. The while loop sets interrupt to the return value of threadptr_get_interrupts. That function gets the current interrupt_flag & ~interrupt_mask, clearing out everything in ec->interrupt_flag in the process (except what was hidden by ec->interrupt_mask). We continue to iterate as long as the interrupt flag doesn’t come back with 0:
int rb_threadptr_execute_interrupts(rb_thread_t *th, int blocking_timing) { rb_atomic_t interrupt; int postponed_job_interrupt = 0; int ret = FALSE; // ... while ((interrupt = threadptr_get_interrupts(th)) != 0) { // ... } }Why are we using while on a single int field, where we check for every mask at once? While we’re checking existing values we’ve pulled from the interrupt_flag, it’s possible new bit masks have been set. If another mask gets set while we’re processing the current interrupts, we keep looping until we return 0.
Next up we use a Bitwise AND to check which masks are currently set. If they’re set, the int will a non-zero value (truthy), otherwise 0 (falsey). We’ll use those for the if statements later on:
int rb_threadptr_execute_interrupts(rb_thread_t *th, int blocking_timing) { // ... while ((interrupt = threadptr_get_interrupts(th)) != 0) { int sig; int timer_interrupt; int pending_interrupt; int trap_interrupt; int terminate_interrupt; timer_interrupt = interrupt & TIMER_INTERRUPT_MASK; pending_interrupt = interrupt & PENDING_INTERRUPT_MASK; postponed_job_interrupt = interrupt & POSTPONED_JOB_INTERRUPT_MASK; trap_interrupt = interrupt & TRAP_INTERRUPT_MASK; terminate_interrupt = interrupt & TERMINATE_INTERRUPT_MASK; // request from other ractors // ... } }`TIMER_INTERRUPT_MASK`
Now we start checking for work. Let’s start with time slice and priority handling with TIMER_INTERRUPT_MASK. In Your Ruby programs are always multi-threaded: Part 1 I discussed how context gets switched between threads in Ruby:
There are two common reasons context gets switched between threads in CRuby, which can result in operations only partially completing (ie, setting the proper result, then checking that result):
- ~100ms of Ruby processing have elapsed
- A blocking operation has been invoked
The TIMER_INTERRUPT_MASK condition is where we check for that processing time11. On Linux/Unix, CRuby maintains a timer thread which typically checks for work every 10ms. As part of that, it calls RUBY_VM_SET_TIMER_INTERRUPT, which sets the TIMER_INTERRUPT_MASK.
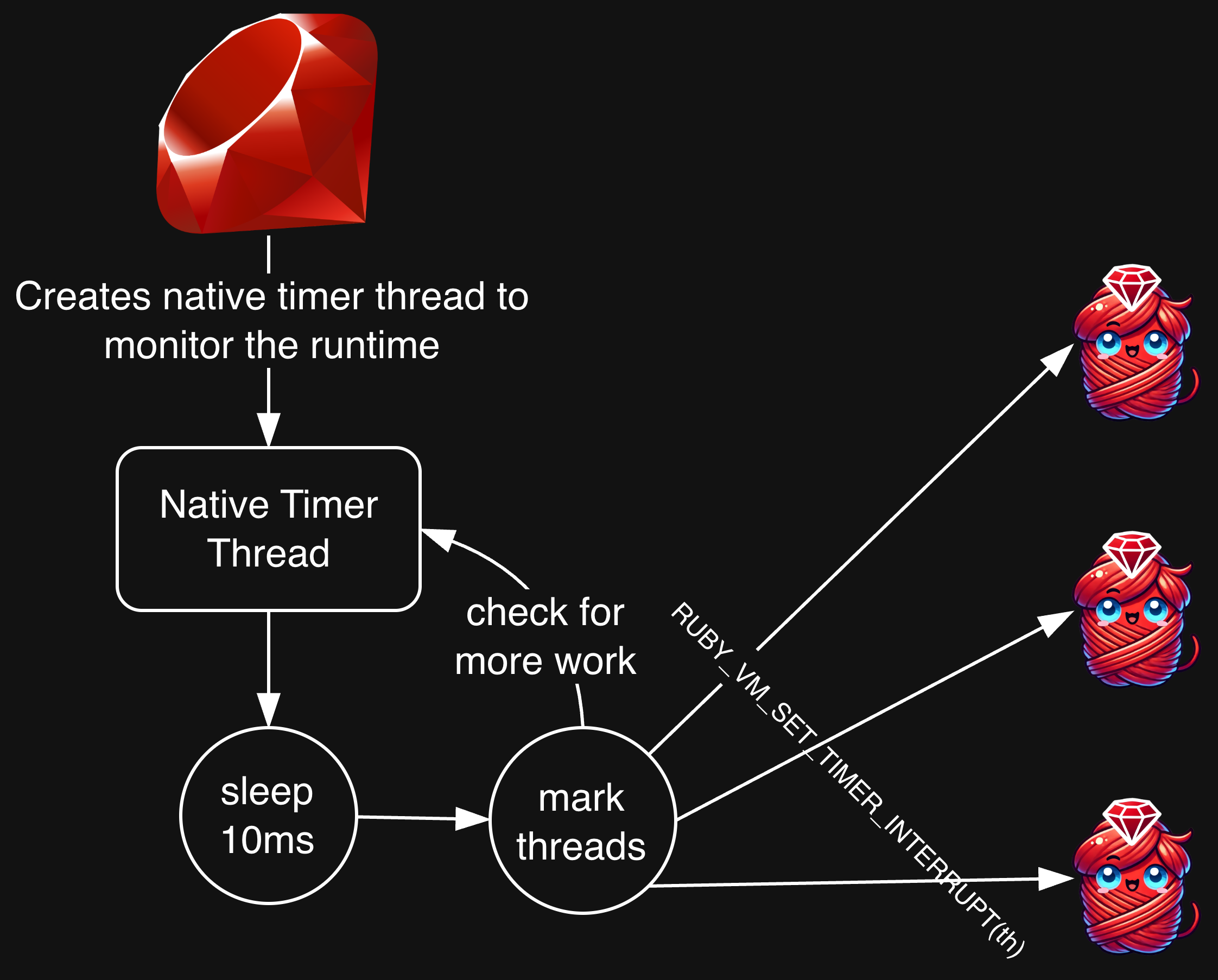
The timer interrupt is fairly straightforward:
-
Get the current “quantum” (the CRuby name for the amount of time each thread can run before being context switched)
-
Priority is used to increase or decrease the amount of time a thread can run above or below the default
-
It is assumed the thread ran 10ms before this code, so it adds 10ms to the running_time
-
An event hook is fired notifying interested plugins that a thread context switch is happening
-
Calls rb_thread_schedule_limits.
if (timer_interrupt) { uint32_t limits_us = thread_default_quantum_ms * 1000;
if (th->priority > 0) limits_us «= th->priority; else limits_us »= -th->priority;
if (th->status == THREAD_RUNNABLE) th->running_time_us += 10 * 1000; // 10ms = 10_000us
EXEC_EVENT_HOOK(th->ec, RUBY_INTERNAL_EVENT_SWITCH, th->ec->cfp->self, 0, 0, 0, Qundef);
rb_thread_schedule_limits(limits_us); }
Since Ruby 3.4, you can set your own thread_default_quantum_ms using the env variable RUBY_THREAD_TIMESLICE. This means the long-held CRuby constant of 100ms time slices is now adjustable, and folks have been adjusting it to handle different CPU saturated workloads.
rb_thread_schedule_limits checks if the thread is over its allotted running time, and yields if so:
static void rb_thread_schedule_limits(uint32_t limits_us) { rb_thread_t *th = GET_THREAD(); if (th->running_time_us >= limits_us) { thread_sched_yield(TH_SCHED(th), th); rb_ractor_thread_switch(th->ractor, th, true); } }We’ve discussed bit manipulation quite a bit - feels negligent to not briefly discuss that right and left bit shift for priority 🤷🏻♂️.
if (th->priority > 0) limits_us <<= th->priority; else limits_us >>= -th->priority;If th->priority is greater than zero, we shift every bit left. If not, it negates the priority (so negative priorities turn positive) and shifts every bit right. We can demonstrate how this would work easily in Ruby (using milliseconds (ms) instead of microseconds (us) for simplicity):
def calculate_priority(priority, limit) priority > 0 ? limit << priority : limit >> -priority end calculate_priority(0, 100) # => 100 calculate_priority(2, 100) # => 400 calculate_priority(-2, 100) # => 25 to_b(100) # => 01100100 = 100 to_b(calculate_priority(0, 100)) # => 01100100 = 100 to_b(calculate_priority(2, 100)) # => 110010000 = 400 to_b(calculate_priority(-2, 100)) # => 00011001 = 25 # 01100100 01100100 # << 2 >> 2 # 110010000 00011001That means that at the default quantum of 100ms, if you give a CRuby thread a priority of 2, it will be given 400ms of runtime before being forced to switch! And -2 means your thread will only run for 25ms at a time. When we shift right, we lose bits, which is why the value is lower.
`TRAP_INTERRUPT_MASK`
Now we’re onto signal handling using TRAP_INTERRUPT_MASK. The first part is what you might expect from a “trap” interrupt - signal handling. According to this code - you’ll only ever run trap handlers on the main thread. If there is a trap mask and we aren’t on the main thread, we ignore it:
/* signal handling */ if (th == th->vm->ractor.main_thread) { // ... }The thread in this Ruby example will always equal Thread#main:
trap("INT") do puts "hello from #{Thread.current}: #{Thread.current == Thread.main}" # => hello from #<Thread:0x000000010445b2a8 run>: true endNext we iterate through each available signal. If multiple signals have not been processed, we process them all here. rb_signal_exec internally calls signal_exec, which we looked at earlier:
while ((sig = rb_get_next_signal()) != 0) { ret |= rb_signal_exec(th, sig); }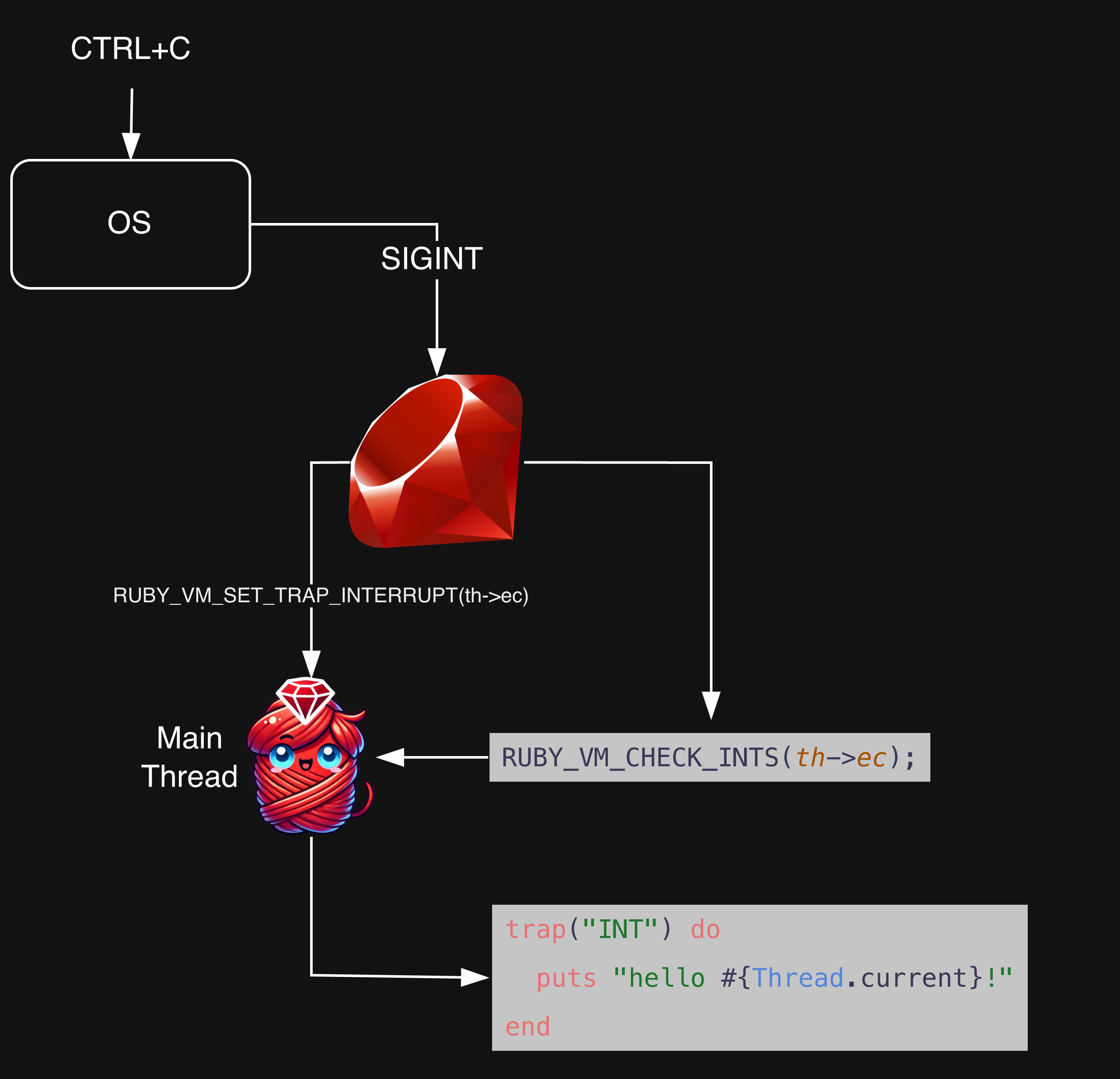
Prior to Ruby 3.4, that was the exclusive purpose of TRAP_INTERRUPT_MASK. Ruby 3.4+ also uses it to alert other threads that there is work for them to execute. You put work into the threads interrupt_exec_tasks list, and call threadptr_interrupt_exec_exec on each thread:
if (!ccan_list_empty(&th->interrupt_exec_tasks)) { // ... threadptr_interrupt_exec_exec(th); // ... }threadptr_interrupt_exec_exec runs the requested task (a function), either in a new thread, or inline:
if (task->flags & rb_interrupt_exec_flag_new_thread) { rb_thread_create(task->func, task->data); } else { (*task->func)(task->data); }Seems generally handy, but was introduced for a specific purpose: supporting require and autoload inside of Ractors:
# Ruby < 3.3 Ractor.new { pp "hey there!" } # autoloads `pp` # => `require': can not access non-shareable objects in constant Kernel::RUBYGEMS_ACTIVATION_MONITOR by non-main ractor. (Ractor::IsolationError) Ractor.new { require "json" puts JSON.parse('"hey there!"') } # => `require': can not access non-shareable objects in constant Kernel::RUBYGEMS_ACTIVATION_MONITOR by non-main ractor. (Ractor::IsolationError) # Ruby >= 3.4 Ractor.new { pp "hey there!" } # => "hey there!" Ractor.new { require "json" puts JSON.parse('"hey there!"') } # => hey there!Requiring a gem requires accessing non-shareable objects - Ractors cannot access any state that is non-shareable. The only Ractor with access to these non-shareable objects is the main Ractor, Ractor.main. To get around this, non-main Ractors add a task to the interrupt_exec_tasks list on the main Ractor thread, and set TRAP_INTERRUPT_MASK:
rb_ractor_t *main_r = GET_VM()->ractor.main_ractor; // for `require` calls rb_ractor_interrupt_exec(main_r, ractor_require_func...) // for autoloading, like when calling `pp` rb_ractor_interrupt_exec(main_r, ractor_autoload_load_func...) // ... // ractor_require_func/ractor_autoload_load_func are // referenced in task->node ccan_list_add_tail(&th->interrupt_exec_tasks, &task->node);
`PENDING_INTERRUPT_MASK`
Now we’ve got the heavy-hitter of thread interrupts - PENDING_INTERRUPT_MASK. It’s not clear from the name, but this mask gets set by Thread#raise and Thread#kill. It doesn’t get much more interruptive than arbitrarily raising an error within, or killing a thread.
The reason it’s called PENDING_INTERRUPT_MASK is because it indicates there are errors waiting to be evaluated in the threads pending_interrupt_queue. Every thread has a pending_interrupt_queue, and it manages the interrupts that have been enqueued by calls like Thread#raise and Thread#kill. Sometimes those interrupts are actual error instances (Thread#raise), and sometimes they are integer flags (Thread#kill).
We start off by checking if there are any active pending interrupts in the queue. If there are, we dequeue the first available interrupt. The blocking_timing relates to the #handle_interrupt method, and we’ll dig into those next time in “When good threads go bad”. For now, just know it gives you the ability to defer the thread being interrupted:
/* exception from another thread */ if (pending_interrupt && threadptr_pending_interrupt_active_p(th)) { VALUE err = rb_threadptr_pending_interrupt_deque(th, blocking_timing ? INTERRUPT_ON_BLOCKING : INTERRUPT_NONE); // ... }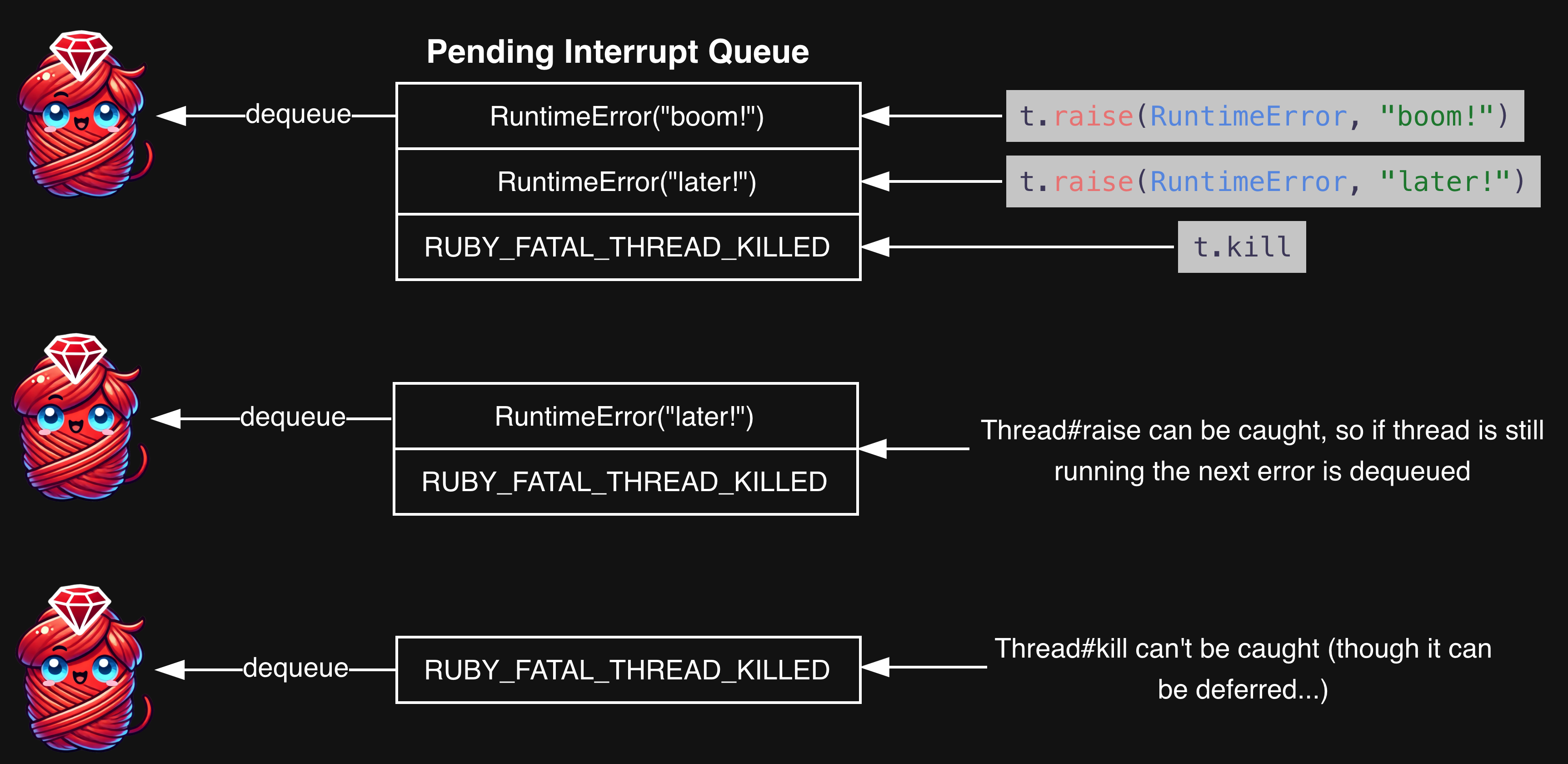
Next, we check if the dequeued interrupt is one the flags set by Thread#kill/Thread#terminate/Thread#exit, all representing that the thread should be killed immediately. We set the terminate_interrupt, which later in the function triggers rb_threadptr_to_kill. This kills the thread and cannot be rescued:
if (/* Thread#kill received */ err == RUBY_FATAL_THREAD_KILLED || /* Terminate thread */ err == RUBY_FATAL_THREAD_TERMINATED || /* Thread.exit etc. */ err == INT2FIX(TAG_FATAL)) { terminate_interrupt = 1; } // ... // outside of the pending interrupt if statement if (terminate_interrupt) { rb_threadptr_to_kill(th); }Next, we make sure the thread is in a running state. Then we force it to raise an error at whatever point in the code it goes to execute next. This raises whatever error we set with Thread#raise:
/* set runnable if th was slept. */ if (th->status == THREAD_STOPPED || th->status == THREAD_STOPPED_FOREVER) th->status = THREAD_RUNNABLE; rb_exc_raise(err);Personally, I was surprised to find that these interrupts are stored in a queue! Can we try to prove it in our Ruby code? Let’s try:
CatchyError = Class.new(StandardError) class ErrorCatcher def self.===(exception) exception.message =~ /1|2|3/ end end t = Thread.new do sleep rescue ErrorCatcher redo rescue CatchyError raise end sleep 0.1 t.raise(CatchyError.new('1')) t.raise(CatchyError.new('2')) t.raise(CatchyError.new('3')) t.raise(CatchyError.new('4')) t.join # => #<Thread:0x0000000120961420 (irb):84 run> terminated with exception (report_on_exception is true): # in 'Kernel#sleep': 4 (CatchyError)In the above code:
- We setup a dynamic error matcher so we can raise the same error, but catch it differently depending on the message12
- We rescue and redo if we get a CatchyError with 1, 2, or 3 as the message
- Even though we t.raise four times, only the fourth CatchyError is raised. If you change the regex to match /1|2/, it will fail on the third error instead
- It really is running through the queue of errors!
`TERMINATE_INTERRUPT_MASK`
TERMINATE_INTERRUPT_MASK is pretty niche. You’ll remember this code from the Thread#kill code earlier triggered by the pending_interrupt_queue:
if (terminate_interrupt) { rb_threadptr_to_kill(th); }There are two ways to trigger that code:
- Using Thread#kill, as we already learned
- When a Ruby process is shutting down. As part of that shutdown, all Ractors are terminated, which set TERMINATE_INTERRUPT_MASK on each of their threads
`POSTPONED_JOB_INTERRUPT_MASK`
Still in the niche-zone, we’ve got POSTPONED_JOB_INTERRUPT_MASK.
This mask is used when work needs to be performed, but can’t safely run in its current context. By making it an interrupt mask, the work can be inserted into a safe point for execution in the CRuby runtime:
if (postponed_job_interrupt) { rb_postponed_job_flush(th->vm); }The rb_postponed_job_flush function iterates through work in the postponed_job_queue, calling each function in the queue.
In CRuby, I can only find references to it in the Tracepoint source code. In concept, it seems very similar to the interrupt_exec_tasks used for Ractor#require. I’m sure there is a CRuby committer who could explain this further - I’d be curious to understand it better!
`VM_BARRIER_INTERRUPT_MASK`
Not to be outdone by TERMINATE_INTERRUPT_MASK and POSTPONED_JOB_INTERRUPT_MASK, we’ve got king-niche: VM_BARRIER_INTERRUPT_MASK. When set, it runs RB_VM_LOCKING() on the thread:
if (interrupt & VM_BARRIER_INTERRUPT_MASK) { RB_VM_LOCKING(); }It’s niche, but seems to play an important role in giving the entire VM exclusive access to an operation. This appears to have been introduced with Ractors in Ruby 3. That makes sense - Ractors are the first truly parallel unit of execution in Ruby.
Certain operations, like YJIT compiling bytecode, require exclusive access to the VM when running. For instance, when rb_yjit_compile_iseq is called, the first thing it does is call rb_vm_barrier:
void rb_yjit_compile_iseq(const rb_iseq_t *iseq, rb_execution_context_t *ec, bool jit_exception) { RB_VM_LOCKING() { rb_vm_barrier();rb_vm_barrier sets the VM_BARRIER_INTERRUPT_MASK on all running threads across Ractors, then waits for each to stop at the barrier:
// interrupts all running threads rb_thread_t *ith; ccan_list_for_each(&vm->ractor.sched.running_threads, ith, sched.node.running_threads) { if (ith->ractor != cr) { RUBY_VM_SET_VM_BARRIER_INTERRUPT(ith->ec); } } // wait for other ractors while (!ractor_sched_barrier_completed_p(vm)) { ractor_sched_set_unlocked(vm, cr); rb_native_cond_wait(&vm->ractor.sched.barrier_complete_cond, &vm->ractor.sched.lock); ractor_sched_set_locked(vm, cr); }———
😮💨 We dug deep in this one. Bitmasks, CRuby internals, Thread management - what could be next? With all this knowledge, we’re primed and ready to dig into what to do when a thread goes rogue. See you next time in “When good threads go bad” 👋🏼
![News Integrity in AI Assistants [pdf]](https://news.najib.digital/site/assets/img/broken.gif)

