.png)

Piet Mondrian is one of the great modernists. Readers will be familiar with his iconic primary-coloured rectangles and perpendicular black lines on a white background, even if they do not recognise the name. These paintings are cornerstones in the development of expressionism and minimalism. The most famous sold for more than $50 million in 2015.
In the 1960s, two decades after Mondrian’s death, an early computer artist called Hiroshi Kawano developed a statistical prediction of which colours Mondrian would choose, and how long he would make the lines. It was based on his body of work. He wrote the programme using the rudimentary programming language of the day and calculated the results on the University of Tokyo’s mainframe computer. The computer couldn’t output colour images and so Kawano would take the statistical results and hand-paint the coloured rectangles. Kawano did not use the exact same primary colour palette as Mondrian to “[express] his admiration for Piet Mondrian…without claiming any close visual resemblance”. Below is KD 29, one of the prints in his Artificial Mondrian series.
I think it is. Kawano has different motivation to Mondrian for this work. Kawano began as a philosopher, who learned programming in order to experiment with using machines to make art. He was one of the first artists to explore “human-computer interaction”. By contrast, Mondrian wanted to express universal harmony with the most simple elements possible. The process was different too. Kawano would write a program in FORTRAN, send it for batch processing and hand paint the results, while Mondrian would sketch the proportions of elements in an empty studio, making small studies before committing to the final canvas.
In a legal sense, Kawano has not violated copyright. Ideas cannot be copyrighted, only expressions of ideas. The idea of using blocks of primary colours with straight perpendicular lines is not copyrightable, and even then, it seems that Mondrian and Kawano were expressing different ideas. It also helps that Kawano did not stick to the same colour palette. The Artificial Mondrian is identifiably in the style of Mondrian but this is not sufficient to constitute a copyright violation. Styles cannot be copyrighted.
This depends on what, in your view, Mondrian owns. It is difficult to define the precise scope of Mondrian’s protected expression. Perhaps it is the balance or proportions between the colours and the lines. But as Kawano proves, there is a lot of space for creativity within this. Perhaps it is the combination of the primary colours and the proportions which belong to him.
There is danger in having an overly expansive definition of what Mondrian owns. Specified too broadly, and too many building blocks would be enclosed from the commons. Branches of the tree could become unexplorable for artists like Kawano and posterity.
In this case, I don’t think that Kawano needs Mondrian’s permission for this work. It doesn’t seem reasonable that Mondrian should have been able to prevent the painting above from happening. And in general, it seems a little silly to mandate consent for making art. “Oi mate, you got a loicense for that painting?”, does not seem like the kind of laissez-faire spirit in which the best works of culture happen. In particular because new forms of art often begin as peripheral, avant-garde or illegitimate (photography, impressionism etc); the incumbents can be resistant, but that doesn’t make them correct.
This would probably be considered fair use in the US, not copyright infringement. The US system evaluates based on four principles:
The purpose and character of the use — are you going to make money or do research or something else? How transformative is the use?
The nature of the copyrighted work.
The amount and substantiality of the work used — how much of the work have you used, how central is that to the essence of the work?
The effect of the derivative on the potential market for the original.
The last characteristic is the most important, typically. Kawano’s use of Mondrian’s work is limited: he used the statistical relationship between elements to predict future ones, but did not copy exact relationships. He did not copy colours. And the purpose was different: it was a new kind of artwork, though it was still art and still commercial. My expectation would be that it is deemed fair use because Kawano’s work did not harm the market for original Mondrian paintings. If anything, it could have enhanced it by increasing interest in the original work.
In the EU, Kawano’s derivative work would be allowed under the text and data mining exemption unless Mondrian had decided to opt-out of his work being used.
I do not think Kawano owes money for the print. I think this follows from whether he needs permission and whether the algorithm constitutes fair use.
However, selling the program by itself is less transformative and could potentially interfere more with the market for Mondrian’s work. Perhaps it “uplifts” many people to make Mondrian-like paintings rather than to buy prints from the artist, causing them lost revenue. While Kawano had chosen not to use the same colour palette as Mondrian’s, who’s to say that others wouldn’t do the same? A potentially informative precedent is Warhol v. Goldsmith (2023). Andy Warhol had used a picture taken by Goldsmith for the basis of a silkscreen illustration of Prince. While this changed the image’s appearance quite dramatically, it still competed in the same market as Goldsmith’s original work — magazine licensing — and so it was deemed not to be fair use.
But at the same time, this kind of uplift is positive too: it democratises access to creating Mondrian-style work and might lead to greater creativity on-net. An interesting precedent here is Oracle vs Google (2021). Oracle alleged that Google had infringed their copyright by using parts of the code for the Java API (read: connection to Oracle) and that this cost them software license revenue. The Court upheld Google’s fair use of this code in the Android platform, on the grounds that it made it easier for developers to create new applications for the Android ecosystem. The social benefits for consumers outweighed the lost license revenue for Oracle.
A related, and important question, is whether Kawano is responsible for copyright infringement from people he sold the program to. He has uplifted them, but it was ultimately within their scope to make work that did or didn’t infringe on copyright. As a parallel, in 1998, the US created a legal safe harbour for internet platforms whose users infringed on copyright. The platforms were not responsible so long as when they received a notice to take the copyrighted material down, they did so. For this reason, it does not seem to me that Kawano was participating in copyright infringement — he was just making a tool.
So I could be persuaded either way: it can be argued that Kawano should pay Mondrian for selling access to the program if it caused him to lose revenue and this did not outweigh the wider social benefits to other creatives.
As it is, the EU’s rules allow Kawano to sell access to the tool wihout paying Mondrian, provided they take reasonable steps to prevent downstream infringement. The EU AI Act’s Code of Practice allows text and data mining to create commercial AI models but says Signatories will…
make reasonable efforts to mitigate the risk that a model memorizes copyrighted training content to the extent that it repeatedly produces copyright-infringing outputs and
prohibit copyright-infringing uses of a model in their acceptable use policy, terms and conditions, or other equivalent documents [for closed-source models].
Some people will reasonably disagree with me, and say that Kawano selling prints and copies of the program is making use of Mondrian’s protected expression. As it is, the Tate Shop offers prints for £5. But if one does disagree with the Tate and me, it is useful to consider when the infringement occurred. Was it…
Sometime during the statistical analysis?
Sometime during the writing of the program?
While the computer processed the results?
While Kawano hand-painted the primary colours onto the image?
At the point of sale of the prints?
I am much more persuaded by answers which come later. Merely doing the statistical analysis, or making the program feels like a much less compelling argument for copyright infringement, than the moment of commercialisation. In this, the purpose of the use is changing and the market is being affected, and so the fair use becomes less compelling.
The discourse on how we might apply copyright law to AI systems has, unfortunately, been collapsed into a culture war framing. In the popular media, it is framed as “the bohemians against the tech broligarchs”. See, for example, this editorial: “The Guardian view on AI and copyright law: big tech must pay.” Or Elton John’s interview with Laura Kuenssberg:
“Thievery on the highest scale...you’re going to rob young people of their legacy and their income, it’s a criminal offence, I think. I think the government are just being absolute losers.
…
I don’t know who the tech minister is, what’s his name? … Yeah, well he’s a bit of a moron.”
I do not claim that the Kawano-Mondrian is a perfect analogy to AI, nor a water-tight piece of jurisprudence, but it should provide an intuition for the kind of questions we need to answer, at a remove from present-day politics.
There are a number of dangers to reducing this issue to friends or enemies, young creatives or big tech billionaires.
The first is that the copyright debate is used to litigate other issues, like how some Silicon Valley elites are close to the Trump Administration, that streaming and social media has changed the structure of media and entertainment markets, or that some incumbents in the creative industries and big tech have very large market power. Interviewed alongside Elton John, the playwright James Graham said, “So many are leaving the industry because it is an incredibly tough time. This advancement into the digital space and the online space is not benefiting the artists and hasn’t traditionally.” This is not an invalid thing to care about, and nor are the other reasons above, but it cannot be adjudicated through the copyright debate.
The second danger of simplification is that in aiming to attack your ‘enemy’, it ends up backfiring. A letter from industry representatives to the Government says:
“We will lose an immense growth opportunity if we give our work away at the behest of a handful of powerful overseas tech companies and with it…any hope that the technology of daily life will embody the values and laws of the United Kingdom.”
But one of the reasons “the technology of daily life” struggles to “embody the values and laws of the United Kingdom” is that it doesn’t get made here. The UK’s interpretation of copyright laws wouldn’t apply to companies doing AI training elsewhere and it might difficult to enforce rules on AI deployment by foreign companies. J.D. Vance was very clear:
[T]he Trump Administration is troubled by reports that some foreign governments are considering tightening the screws on U.S. tech companies with international footprints. Now, America cannot and will not accept that, and we think it’s a terrible mistake not just for the United States of America but for your own countries.
If it is only possible to enforce rules on domestic companies, then having a stricter regime would differentially affect domestic companies. This could either push companies to move jurisdictions, not move to the UK, or be less competitive. Not having domestic tech companies makes it harder, in fact, makes it more difficult to steer those technologies towards your values in future and to tax them, to pay for the things you value.
The third issue with simplification is that it does not balance objectives. The goal is to have a more flourishing creative future. This involves having finer tools, to say the thing we mean, exactly. It means having lower barriers to actualise our creations, it means more leisure and tutoring to develop mastery. It means having a richer common context to draw from.
There are two threats to this scenario. The first is — as advocates point out — if the property rights of creatives are not suitably enforced, they will not internalise the market returns for their work and so will not pursue the arts or invest in creative innovation. The second is that we do not create the tools or necessary context to create this progress. Free and rich societies have advantages to producing creative work. If we fail on the first count, we end up in a wealthy but an unexpressive, greyer future. In the second, we end up culturally stagnating with our current set of tools or unable to uphold the freedoms for individual expression. The task is to balance these modes of failure.
I fear that in pursuit of particular policy objectives — whether there is an opt-out or opt-in regime for AI training, or the degree of transparency requirements — we trade a great amount of steering power for the course of technology in the future. It is exactly because I think the UK would steer better in the long run, relative to others, that it is so worthwhile to ensure AI is developed here.
The following is my attempt to find the synthesis between values in this particular case — transparency and fairness — and realpolitik which allows the UK to pursue its values in the long-run.
Critical to this is my expectation that competitive pressures lead foundation model developers to train their systems in whichever jurisdictions offer the most permissive copyright regime. There is, like taxation, a “race to the bottom”, where middle powers like the UK cannot set global standards. OpenAI’s input to the Office for Science and Technology put this in much more bombastic terms:
Given concerted state support for critical industries and infrastructure projects, there’s little doubt that the PRC’s AI developers will enjoy unfettered access to data—including copyrighted data—that will improve their models. If the PRC’s developers have unfettered access to data and American companies are left without fair use access, the race for AI is effectively over. America loses, as does the success of democratic AI. Ultimately, access to more data from the widest possible range of sources will ensure more access to more powerful innovations that deliver even more knowledge.
It is clear they state their interest as strongly as possible. Since then, the Trump Administration fired the Head of the US Copyright Office who had published an advisory report which suggested a more stringent interpretation of fair use. For this reason, I expect the UK’s rules on AI training will be unenforceable on companies from the EU, US, and China, and it will only be possible to impose rules on domestic AI companies. The difference in rules will either push developers away from training in the UK, prevent developers moving to the UK, or could mean that companies never get started which otherwise would have. To make the abstract concrete, Google DeepMind have just released a very good video and audio model, Veo 3. This would have been trained on copyrighted materials outside the UK, but will be part of the Google offering in the UK. Meanwhile, Synthesia is one of the world’s leading AI video companies based in London. What should they do? Compete against Google on an unfair playing field, or leave the UK?
This is similar to the non-dom tax regime: while I have beliefs about what constitutes a fair society, the world as it is means that rich people can leave and the UK will have less money if they do. I prefer to trade more tax receipts for an abstract notion of fairness. I certainly don’t think a non-dom loophole was fair but it just seems better than engaging with a fictitious version of the world “as I wish it was”. The moral high ground doesn’t pay for public services.
With this in mind, there are three major considerations for the UK’s rules:
Whether to have an opt-in or opt-out for AI training on copyrighted materials.
What the transparency requirements for AI training data should be.
What should be required of model developers to mitigate copyright infringement.
The training process is roughly approximate to “making a copy and reading it”, if deployment is “writing”. I have been slightly confused by the focus on AI training in the copyright debate. How the model is deployed seems to have a great deal more impact on rightsholders.
The data is gathered from the Internet using a technique called “data scraping” using tools called “web crawlers”. Here’s an explanation of training that I prepared earlier:
The neural network is like a little computer which can be programmed by adjusting a series of dials. The aim of a neural network is to predict an output given a set of inputs. The iterative process of tuning these dials to improve the prediction is called ‘training’. The people creating the network supervise the training process by showing the data and the answers, but crucially, it doesn’t involve telling the network how it ought to process and understand the image. In other words, our process of trial and improvement tweaking of dials is essentially letting the little computer, by itself, search for the best way it can be programmed to achieve its goal, unlike ordinary computers which need a human to figure out a program first and then somehow communicate it to the computer. Dario Amodei described the training process in this way:
“You [the AI researcher] get the obstacles out of their way. You give them good data, you give them enough space to operate in, you don't do something stupid like condition them badly numerically [i.e. tweak the dials poorly], and they want to learn. They'll do it.”
One common misconception is that models “ingest” data. Again, the connotations are negatively misleading. This gives the implication that an alien mind is swallowing it or something. More actually, the model is “passing over” the words, akin to skim reading, and using them to feedback on its predictions. During this process, the parameters are learning compressions, just like humans have heuristics. The Internet is hundreds of zettabytes — 1 zettabytes is 1 trillion gigabytes — whereas Llama 3.1 is ~500 GB and can be run on a laptop. It’s incorrect to say that all the data is “in” there.
Another misconception is that the model developers want the model to memorise things. This is not the goal. Memorisation is an inefficient use of space inside the model, and memorising protected expressions isn’t what intelligence is. The graph below shows the “memorisation rate” in Google DeepMind’s series of Gemma models.
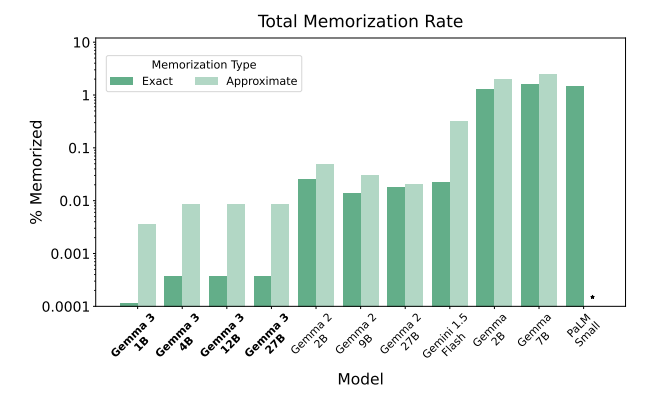
The memorisation rate in Gemma 3 is more than 1000 times lower than Gemma 1, and Gemma 2 is between 10 and 100 times lower. Notably, this is not a function of model size, but algorithmic gains because the number of parameters is roughly consistent across generations.
This is not to suggest that AI development cannot be geared towards memorisation and repeating clones of someone else’s work; it definitely can. People can train an “AustenBot” or a “DickensBot”, or distill one from a larger model. But the goal of foundation model training is to find compressions (heuristics) which generalise to solve problems. It has been proven that foundation models have complex circuits and are not just stochastic parrots. The rules have to distinguish between those who are creating a world model — in large language models, this is a general representation of “language space” — and those who are training models towards memorising a particular artist’s work.
The UK’s copyright rules do not make it possible to create world models for commercial purposes, just research. So while Google DeepMind is headquartered in London, all their training will surely happen in the US. The EU, by contrast, allows research organisations (universities, cultural heritage institutions) to train on copyright data and the rightsholders cannot opt-out. The groups can use their models for commercial purposes or research. Otherwise, commercial organisations can use web-crawlers but must provide an opt-out for rightsholders who do not want their work to be used for training.
The EU AI Act Code of Practice said that model providers cannot use tricks to get behind paywalls or use web crawlers on sites that distribute pirated books or films. Meta is being sued in the US for training their Llama models on LibGen, an online library that provides access to copyrighted material. This would not be permitted under the EU AI Act, but might constitute fair use in the US, depending on the aforementioned factors.
The UK should follow the EU in allowing for an opt-out regime for training, rather than an opt-in regime for rightsholders as some have advocated.
Large models trained on more tokens of data are more capable, so if AI developers can only train on datasets they have the permission of rightsholders it either slows their training or makes their models less capable. And while in aggregate, the tokens are essential for model performance, each given token just isn’t worth that much. A piece from Model Thinking (forthcoming, tomorrow) estimates that Llama 4 training was roughly $800 million and training used 30 trillion tokens of text composed of 120 trillion tokens of raw text. If the training cost was taxed to compensate rightsholders (note: a terrible idea to tax things you want), then each token was $0.000007 per token. A 10,000 word essay is worth just 9 cents even when charging $800 million for the data. Put differently, based on this online calculator, a model 10 times bigger than Llama 3 would cost roughly $11.25 trillion if Meta paid for tokens at the freelancer rate. This is nearly 10 times the market capitalisation of Meta. The marginal price of a token is going to zero.
Second, most of the rightsholders are so fragmented that it would be uneconomic for an AI company to try to aggregate all of these. Training an AI model in the UK would be a bit like trying to get 8,276 consents required to build HS2. (You’d cancel the sections or just pick up and go elsewhere!) If the rightsholders believe their tokens are especially valuable, the opt-out means they can remove their permission and negotiate with the tech companies for use. The opt-out functions as a de minimis exception for the tokens which are not valuable until they are aggregated.
Third, the opt-in system preferences incumbents with larger market power. Most online platforms require in their terms of service to use content posted on the platform to train their models. Large studios will have aggregated the rights of independent creatives doing work-for-hire, and so would be able to engage in “collective bargaining” but independents would be too small to do so. With the intention of “making big tech pay” the system would in fact set up defaults for online platforms that already had the rights to large datasets.
Therefore, the UK should match the EU’s rules: it is fair use if you don’t go around paywalls and make best efforts to avoid websites of pirated books (and so on). Doing opt-in doesn’t “get” anything for creatives, it just stunts the emergence of internationally-competitive AI firms in the UK.
The same consideration applies: do these rules only apply to UK companies and not their international competitors? In principle, transparency is a worthy ideal, but what is the practical cost? What do we have to trade for training transparency?
The Baroness Kidron amendment would require companies to provide a log of all of the URLs their models were trained on, and keep this up-to-date every month. By contrast, the US makes no training data transparency requirements on their model creators and the Second Draft of the EU AI Act Code of Practice required some limited disclosures about the data collection practices:
A list of the different data acquisition methods, including, but not limited to: (i) web crawling; (ii) private data licenced by or on behalf of rights holders, or otherwise acquired from third parties; (iii) data annotation or creation potentially through relationships with third parties; (iv) synthetically generated data; (v) user data; (vi) publicly available data; and (vii) data collected through other means
The time period during which the data was collected for each acquisition method, including a notice if the data acquisition is ongoing
A general description of the data processing involved in transforming the acquired data into the training data for the model
A general description of the data used for training, testing and validation.
A list of user-agent strings for web crawler(s) used, if any, in acquiring training data
The period of data collection and name of organisation(s) operating the crawler for each web crawler used
A general description of how the crawler respects preferences indicated in robots.txt for each web crawler used
A description of any methods implemented in data acquisition or processing, if any, to address the prevalence of copyrighted materials in the training, testing, and validation data.
However, the Third Draft did not include the equivalent model card, perhaps indicating that the EU AI Office had to walk back requirements to get the US labs to agree to the Code. (The Code is an option for implementation of the Act, which US labs can decide to use or argue alternative interpretations in the courts.) This provides a range of autonomy that UK legislators have to operate within.
The transparency requirements are important for implementing an opt-out. How does one verify that companies have respected the opt-out, unless there is a list of URLs to verify? However, I think the list of URLs is slightly overstated as a silver bullet for enforcement. One might reasonably respond, how does one verify that the list of URLs matches the actual training data?
The only way to enforce the opt-out is through engagement with the model. Over time, we can develop interpretability tools and data attribution tools (through research agendas like influence functions) and we can use simple elicitation methods like prompting the model. There can be steep fines for models which provably trained on material that had opted-out, but if it is not possible to identify that it has been trained on it, nor that our best probes can identify it inside the model, there is no practical answer to enforcement. Imposing transparency requirements differentially on UK startups to go further than this seems disproportionate.
The alternative approach would be to not allow an opt-out for rightsholders whose work is in the public domain. If training is akin to reading, and all work depends on the influence of others, then prima facie, a neural network should be allowed to read the whole internet, listen to all music, or watch all films as inspiration, just as a human can. It is the deployment which risks infringing copyright, not the training. The opt-out, with the EU’s approach of requiring high-level disclosures about practises stands out as giving creative industries autonomy if they do not accept this argument and thereby provides a balanced path forwards.
Until the model is released into the world, any copyright infringement has been inert: the model hasn’t done anything. The biggest risks to creators and their livelihood arise not from fractions of pennies in lost income from training, but from markets being flooded with near identical AI-generated copies.
In deployment, the UK has slightly more autonomy than when regulating training. Foreign companies serving AI models in the UK are bound by deployment rules, which doesn’t depend on training done abroad. But this is not complete: the Trump administration can tell the UK to back down on enforcement or model providers can switch off their service in the UK. AI models are going to be essential to many economic functions — imagine all white-collar workers are using multiple agents for their work — so whoever provides the models will have a lot of power.
The regulation of deployment is also most sensitive to the two failure modes discussed. If the copyright regime is too laissez-faire, model developers who are intent on creating AI-generated replicas could cause creatives lost revenue, but if it is too aggressive, the AI systems will be neutered as tools of creative innovation. There is a natural inclination towards the first consideration as today’s creatives will naturally make the case for the protection of their mode of output but the creatives of tomorrow cannot make the case for the latter scenario. But imagine, giving an AI system a harmless prompt and it responds with an error message:
All primary-coloured blocks and perpendicular lines are owned by the estate of Mondrian, do you have a license for that?
Alternatively, give this prompt when you’re in France and the US and we can fulfil the request.
That is a bleak creative future for those other than the Mondrian estate.
The Third Draft of the EU AI Act’s Code of Practice requires model developers prevent their models being used to infringe copyright, as mentioned earlier. The UK should follow their standard here.
In practice, these rules will be implemented by algorithms which determine whether models can respond to a prompt or how they should respond to a prompt. Online platforms run proactive systems to prevent copyrighted material being shared as the scale of potential infringement is too great for humans to track on the largest services. In some cases, the law might be over-enforced on legitimate work, for example, Spotify’s copyright classification system prevented a group of academics from publishing a podcast about copyright.
The foundation model developers can steer the responses of models away from infringing on copyright using techniques like RLHF and tools like constitutional classifiers. The largest model providers, with more than 500 million users, could use citizens’ assemblies (supported by experts) to review transcripts of prompts and responses, so that ordinary people can provide input into how the systems can balance being a useful tool for expression and infringing on protected expression. These labels could be used to train a reward model for RLHF, train the constitutional classifiers, or develop the model spec. Model developers could even do this of their own volition!
The goal, on which I think everyone would agree, is to have innovative creative sectors where the actual creativity receives fair compensation and that the UK has the technological autonomy to make its own rules. Having internationally uncompetitive opt-in and reporting requirements would do more to set back this cause, than advance it. The blunt truth is that companies developing models in the EU, US, and China will not follow the UK’s opt-in system and the opt-in system isn’t even a good idea on its own terms. Unilaterally burdening would-be UK model developers does not help UK creatives in practice. In fact, they might be more damaged by the reduce likelihood that in the long-term, global technology companies are here.
Many people in the UK would like to exert more influence over social media platforms, search engines, and eCommerce providers. This is difficult when they are not made here, their leaders and headquarters are not based here, and they do not pay taxes on their profits here. If we are to have “any hope that the technology of daily life will embody the values and laws of the United Kingdom”, we must do our level best to make AI here. Imagine hosting the Industrial Revolution on foreign traintacks, that can be turned off at any moment and whose owners can steer your society’s values and extract its wealth.
It is precisely because I expect the UK to have the highest quality public discourse on questions such as this, and to most robustly defend free, fair markets and property rights, that I think the UK should pursue long-term steering power for the critical technology of this century.
But one’s vision for the future is a rudderless sailboat if all AI is imported AI.

![J.Huang Reveals Nvidia's Quantum and AI Supercomputing Breakthroughs [video]](https://www.youtube.com/img/desktop/supported_browsers/firefox.png)

