.png)

Bonjour!
I'm Julien, freelance data engineer based in Geneva 🇨🇭.
Every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
Snowflake, AWS, Databricks, and GCP all have their own Iceberg catalog implementations…
So I needed mine 😂.
Since S3 introduced conditional writes, I’ve had this idea: use it to build a damn simple Iceberg catalog.

No server to set up.
No REST API.
No cloud service.
No config.
Just one (boring) JSON file — and a smooth developer experience.
Let’s dive into the boring catalog story.
The boring catalog is an experiment and still in its early days. Use with caution.
This implementation is very basic and doesn’t cover some enterprise requirements like governance or advanced security.
The goal is simple: to let people experiment easily with Iceberg’s commit mechanism and remove some of the usual friction around catalog setup.
Boring catalog is distributed as a Python package:
uv install boringcatalogIt is composed of a CLI called “ice”:
ice --helpand a Python package
from boringcatalog import BoringCatalog catalog = BoringCatalog()Inspired by Thomas McGeehan, I took inspiration from the git workflow to design the catalog UX:
ice initThis command creates two files:
catalog.json — the actual catalog file (by default, created in a new catalog folder)
.ice/index — a small file that stores the path to your catalog, similar to how .git/index works

Of course, you can store your catalog.json anywhere, as long as it’s a PyArrow Filesystem or fsspec–compatible URI:
... AWS CLI auth ... ice init --catalog s3://<your-bucket>/catalog.jsonOkay, our catalog is set up.
Let’s write some data to Iceberg.
First, grab a Parquet file:
curl https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2023-01.parquet -o /tmp/yellow_tripdata_2023-01.parquetThen commit it to the catalog:
ice commit my_table --source /tmp/yellow_tripdata_2023-01.parquetThis will automatically create a default namespace and a new table called my_table.
Note: For now, commit only accepts Parquet files as input and appends data to the target table.
Iceberg uses a snapshot mechanism — every operation (like appends or schema changes) is recorded as a distinct snapshot.
To view the history of operations made to your catalog, run:
ice logSimilar to the git log command, the most recent commit is shown first, along with a summary of the operation:
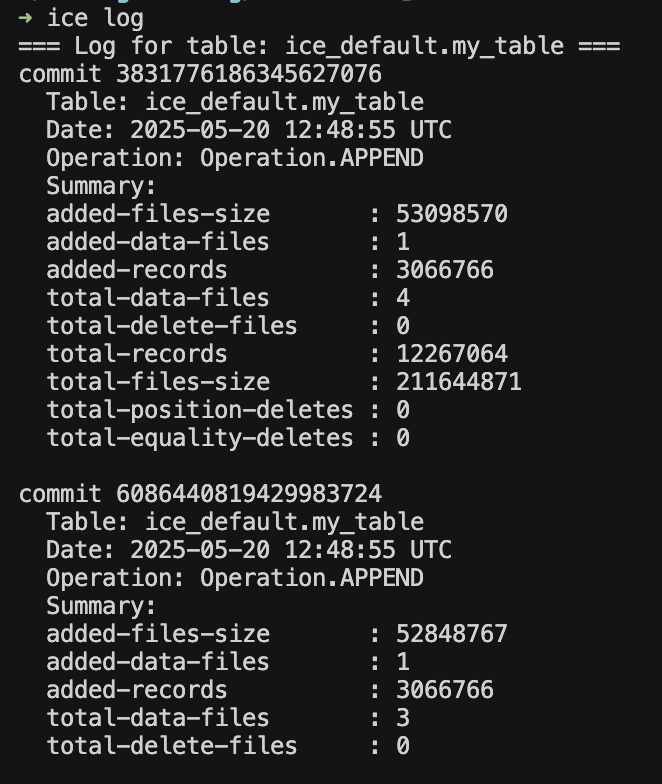
Each entry includes metadata such as the snapshot ID, timestamp, operation type (e.g., append), and the number of files or rows involved.
I personally love using DuckDB for data exploration and quick manipulation.
If you run:
ice duckThis opens a DuckDB shell with your Iceberg context already loaded.
You’ll get:
A table listing all namespaces
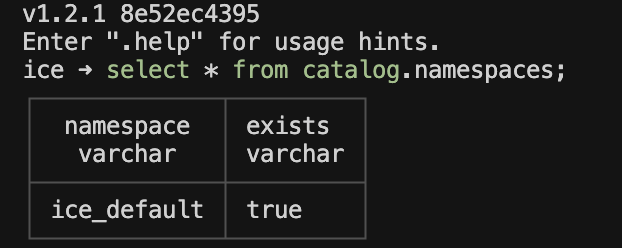
A table listing all the Iceberg tables

Views are automatically created for each Iceberg table, ready to query
Iceberg tables are accessed via the Iceberg DuckDB extension

And of course, for a more visual experience, you can launch the DuckDB web UI with:
ice duck -ui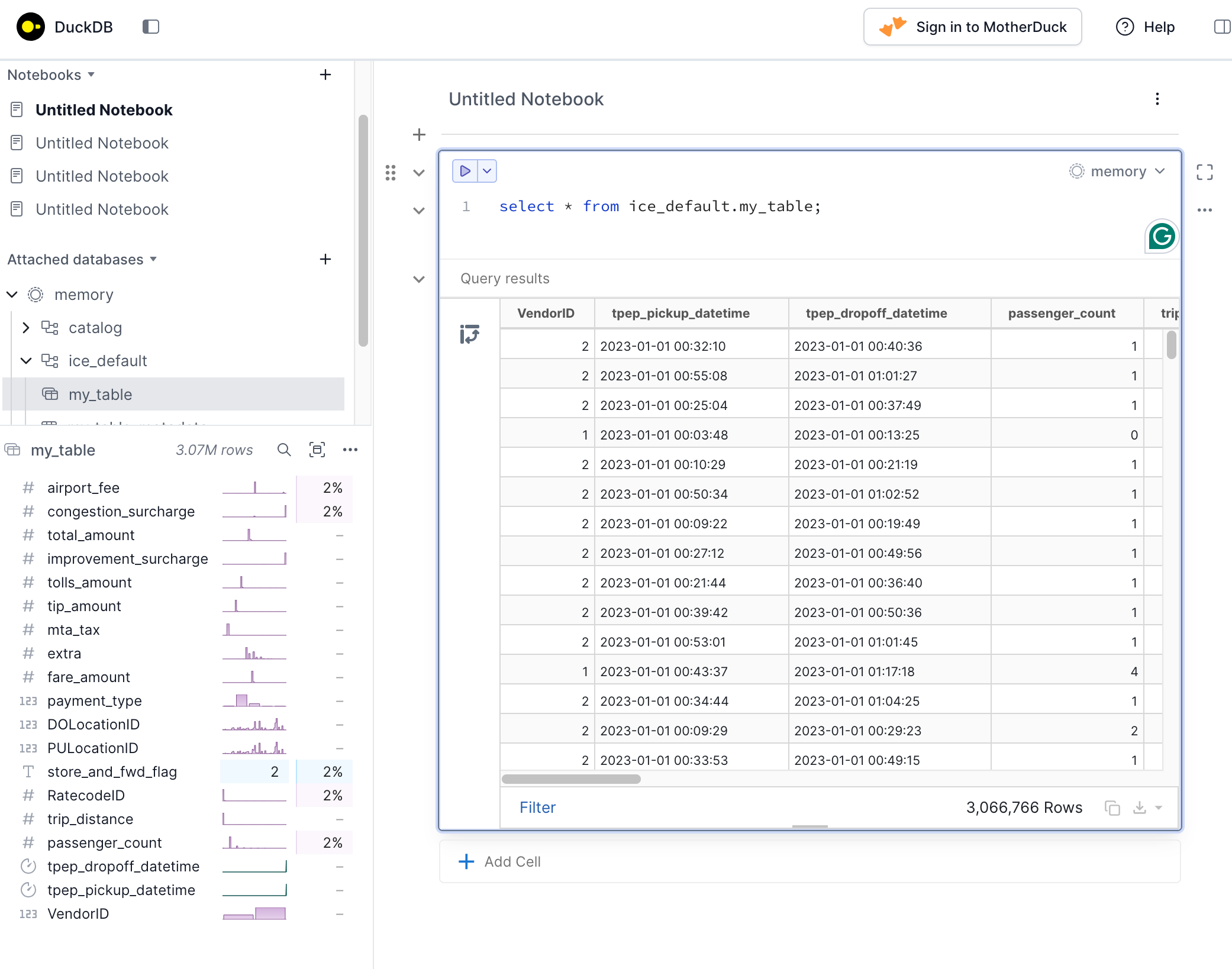
As mentioned earlier, you can also interact with the catalog via Python using the boringcatalog library:
from boringcatalog import BoringCatalog catalog = BoringCatalog()You can then use it just like you would with PyIceberg:
import pyarrow.parquet as pq df = pq.read_table("/tmp/yellow_tripdata_2023-01.parquet") table = catalog.load_table(("ice_default", "my_table")) table.append(df)Since Polars integrates with PyIceberg, you can also ingest data directly via Polars:
import polars as pl df = pl.read_parquet("/tmp/yellow_tripdata_2023-01.parquet") ... table = catalog.load_table("ice_default.my_table") df1.write_iceberg( target = table, mode = "append" )Under the hood, the catalog is simply an instance of the generic Catalog class from the PyIceberg library.

PyIceberg already provides several catalog implementations out of the box — Hive, REST, AWS Glue, Nessie, and more.
I just adapted a few methods to read from and write to a plain JSON file.
That’s it.
⚠️ What About Concurrency?
Traditional catalog backends use a database or service to coordinate concurrent writes.
In this implementation, we leverage S3 conditional writes to ensure consistency without a separate backend.
Here’s how it works:
Fetch the current ETag of the catalog.json file
Perform the operations
Before committing to the catalog, check if the file ETag has changed
If not, proceed to update the catalog.json file
If yes, raise an error
It’s then up to the writer to refresh the catalog and retry the operation.
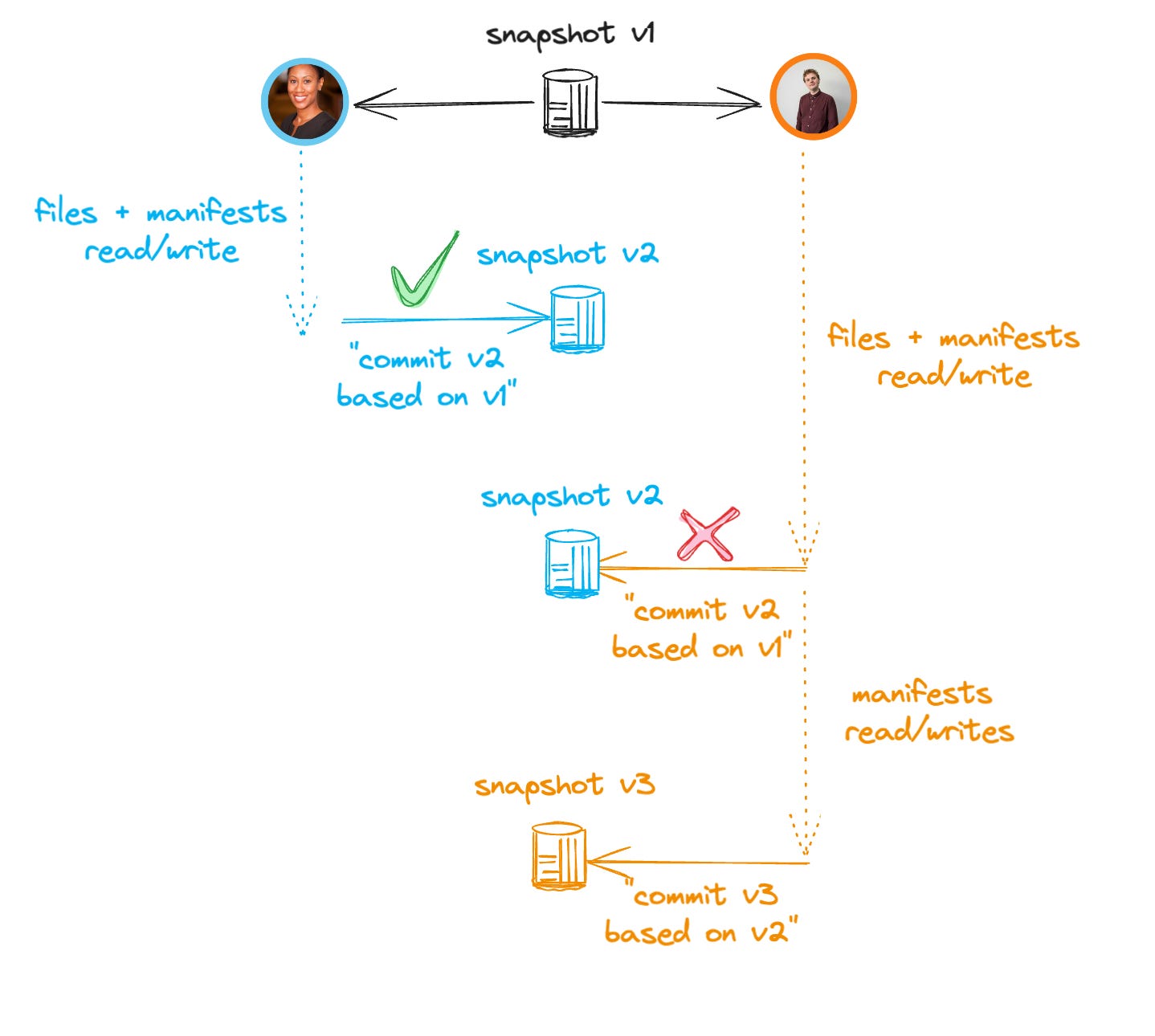
⚠️ What About Governance?
This will probably be the main complaint about such implementation: there is no control over who can read/write a table (except S3 access control).
I mostly use this catalog to quickly spin up an Iceberg setup and experiment with different behaviors.
I’ve noticed that using the ice CLI provides a really smooth and fast experience, especially when sensible defaults are set up, like a default namespace and automatic table creation.
So, I want to enrich the CLI experience by adding more features for playing with partition specs, merge operations, schema evolution, etc.
An interesting next step I’m considering is to expose a REST catalog interface for the boring catalog, either via the CLI command:
ice rest(or maybe even through a Lambda URL)
You might wonder: why expose a REST interface?
Simply because REST catalogs are becoming the standard way Iceberg integrates with other platforms.
For example, Snowflake supports REST catalogs now:
So, a possible next step would be to enable writing directly from Snowflake in the boring catalog.
If you like the project, please consider giving the GitHub repo a star.
And don’t hesitate to comment on this article or reply to this email and tell me what you think about it: stupid, interesting, or anything else.
I’d love your honest feedback.
Building a data stack is complex—too many moving pieces, too little time.
That’s where Boring Data comes in.
I’ve created a data stack onboarding package combining ready-to-use templates and hands-on workshops.
Interested?
Check out boringdata.io or reply to this email—I’d be happy to walk you through our templates and workshops.
Thanks for reading,
-Ju




