.png)

Published on 2025-03-31, 4102 words, 15 minutes to read
Especially if you want a UX as good as Docker images give you.

Anubis is an AI scraper bot filter that puts a wall between your website and the lowest-hanging fruit of bot filtering. I developed it to protect my git server, but it's also used to protect bug trackers, Mastodon instances, and more. The goal is to help protect the small Internet so small communities can continue to exist at the scale they're currently operating at without having to resort to overly expensive servers or terrifyingly complicated setups.
Anubis has kind of exploded in popularity in the last week. GitHub stars are usually a very poor metric because they're so easy to game, but here's the star graph for Anubis over the last week:
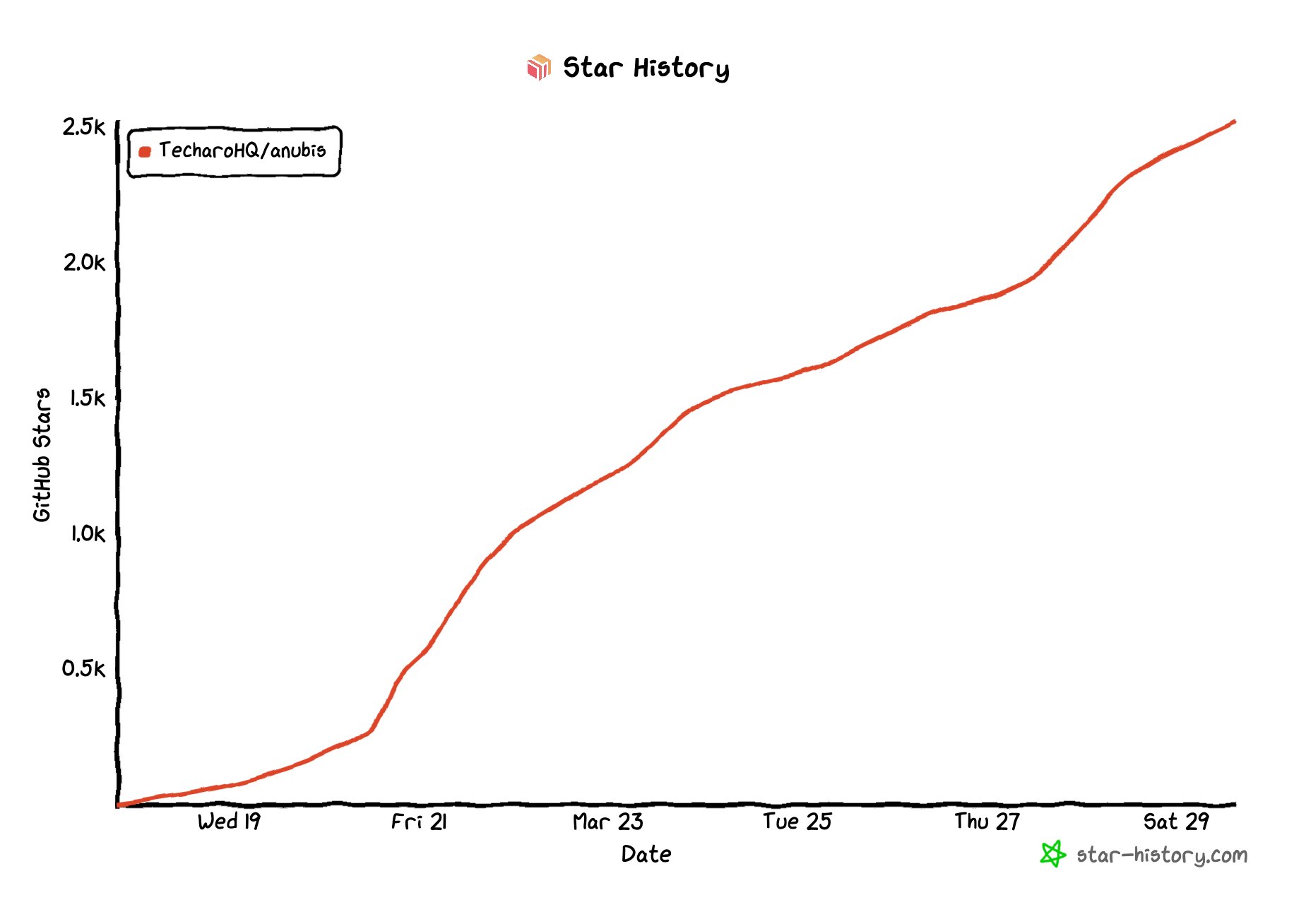 A graph showing the GitHub star history for Anubis, it hockey sticked upwards and has a sine wave at about a 45 degree angle.
A graph showing the GitHub star history for Anubis, it hockey sticked upwards and has a sine wave at about a 45 degree angle.Normally when I make projects, I don't expect them to take off. I especially don't expect to front page news on Ars Technica and TechCrunch within the span of a few days. I very much also do not expect to say sentences like "FFmpeg uses a program I made to help them stop scraper bots taking down their issue tracker". The last week has been fairly ridiculous in that regard.
There has been a lot of interest in me distributing native packages for Anubis. These packages would allow administrators that don't use Docker/OCI Containers/Podman to use Anubis. I want to build native packages, but building native packages is actually a fair bit more complicated than you may realize out of the gate. I mean it sounds simple, right?
But you can JUST build a tarball, right? Anubis is written in Go, you can just do that easily with GOOS=linux GOARCH=amd64 CGO_ENABLED=0 go build -o var/anubis-linux-amd64 ./cmd/anubis and not faff around with the Docker webshit bloat right?
It would be "just" that simple for getting something out of the door, but it's a poor UX compared to what Docker gives--
I have detected bloat, you YAML merchant you! Reject complexity! Return to native packages!
Okay, okay, the conversations don't go exactly like that, but that's what it can feel like sometimes.
Here's a general rule of thumb: "just" is usually a load-bearing word that hides a lot of complexity. If it was "just" that simple, it would have already been done.
A note to downstream packagers
If you want to package Anubis for your distribution of choice, PLEASE DO IT! Please make sure to let me know so I can add it to the docs along with instructions about how to use it.
Seriously, nothing in this post should be construed into saying "do not package this in distros". A lot of "stable" distros may have difficulty with this because I need Go 1.24 features for an upcoming part of Anubis. I just want to cover some difficulties in making binary packages that y'all already have had to reckon with that other people have not yet had to think about.
With all that said, buckle up.
Anubis' threat model
Before I go into the hard details of building native packages and outlining what I think is the least burdensome solution, it may be helpful to keep Anubis' (and Techaro's) threat model in mind. The solution I am proposing will look "overkill", but given these constraints I'm sure you'll think it's "just right".
Things in Anubis' favor
Anubis is open source software under the MIT license. The code is posted on GitHub and is free for anyone to view the code, download it, learn from it, produce derivative works from it, and otherwise use the software for any purpose.
Personally, I'd hope that bigger users of this will contribute back to the project somehow so that I can afford to have working on this be my full-time job. However I understand that not every project or community can afford doing that. Open source projects are usually nights and weekends affairs. The goal of Anubis is to protect the small internet, and small internet usually comes with small budgets.
Anubis is trusted by some big organizations like GNOME, Sourcehut, and ffmpeg. This social proof is kind of both a blessing and a curse, because it means if anything goes wrong, it could go very wrong all at once.
The project is exploding in popularity. Here's that star count graph again:
A graph showing the GitHub star history for Anubis, it hockey sticked upwards and has a sine wave at about a 45 degree angle.The really wild part about that star count graph is that you can see a sine wave if you rotate it by 45 degrees. A sine wave in metrics like that lets you know that growth is healthy and mostly human-sourced. This is wild to see.
Things not in Anubis' favor
Right now the team is one person that works on this during nights and weekends. As much as I'd like this to not be the case, my time is limited and my dayjob must take precedence so that I can afford to eat and pay my bills. Don't get me wrong, I'd love to work on this full time, but my financial situation currently requires me to keep my dayjob.
I also have a limited capacity for debugging "advanced" issues (such as those that only show up when you are running a program as a native package instead of in an environment like Docker/OCI/Podman), and I am as vulnerable to burnout as you are.
Speaking of burnout, this project has exploded in popularity. I've never had a project go hockey stick like this before. It's happened at companies I've worked at, sure, but never something that's been "my fault". This is undefined territory for me. Waking up and finding out you're on the front page of Ars Technica and getting emails requesting comment from TechCrunch reporters is kinda stressful.
Maybe it's a "good" kind of stress though? I don't know. What I do know is that I broke my media training that I've gotten from past employers over the years replying to the journalist from TechCrunch.
Some personal facts and circumstances which I am not going to go into detail about have made my sleep particularly bad the last week. As I'm writing this, I had a night with a solid 8 hours of sleep, so maybe that's on the mend. However when you get bad sleep for a bit, it tends to not make you have a good time.
Anubis is security software. Security software usually needs to be held to a higher standard than most other types of software. This means that "small typos" or forgotten bits of configuration from the initial rageware spike can actually become glaring security issues. There's been a lot of "founder code" cleanup so far and I can only see more coming in the future.
Of note: the Techaro standard about security is relevant here. At Techaro, we realize that computers are fractals of complexity and that any program is essentially built and reliant upon the behavior of a massive number of unknown unknowns. When at all possible we'll try to minimize the amount of security related bugs that may show up, but those unknown unknowns can and will bite at any time. Over time, that list of security advisories is undoubtedly going to grow because that's just how networked software works.
We try to not measure the number of vulnerabilities that made it in, we measure how we react when one does come in. Techaro treats people that report security issues to [email protected] seriously.
There's a few other standards like this (Be not a cancer upon the earth, The purpose of a system is what it does, etc.), and we could blow hot air about them, but I think it's better for them to be demonstrated by example instead of claimed on a webbed site with catchy slogans and lofty words puffed up by hot air.
Also, if this goes wrong, I'm going to get personally mega-cancelled. I would really like that to not happen, but this is the biggest existential risk and why I want to take making binary packages this seriously.
So with all of those constraints in mind, here's why it's not easy to "just" make binary packages.
Packaging software is hard
Like was said earlier:
But you can JUST build a tarball, right? Anubis is written in Go, you can just do that easily with GOOS=linux GOARCH=amd64 CGO_ENABLED=0 go build -o var/anubis-linux-amd64 ./cmd/anubis and not faff around with the Docker webshit bloat right?
Sure, it is possible to JUST build a tarball with a single shell script like this:
cd var DIR="./anubis-$(cat VERSION)-linux-amd64" mkdir -p $DIR/{bin,docs,run} GOOS=linux GOARCH=amd64 CGO_ENABLED=0 go build -o $DIR/bin/anubis ./cmd/anubis cp ../README.md $DIR cp ../LICENSE $DIR cp ../docs/docs/admin/installation.mdx $DIR/docs/installation.md cp ../web/static/botPolicy.json $DIR/docs/botPolicy.json cp ../run/* $DIR/run/ tar cJf ${DIR}.txz ${DIR}And just repeat it for every GOOS/GOARCH pair that we want to support (probably gonna start out with linux/amd64, linux/arm64, freebsd/amd64, freebsd/arm64). Let's be real, this would work, but the main problem I have with this is that this is a poor developer experience, and it also is a poor administrator experience (mostly because those binary tarball packages leave installation as an exercise for the reader).
Don't repeat yourself
When I make binary packages for Anubis, I want to specify the package once and then have the tooling figure out how to make it happen. Ideally, the same build instructions should be used for both distribution package builds and tarballs. If the experience for developers is bad or requires you to minimax into ecosystem-specific tooling, this means that the experience is fundamentally going to be better on one platform over another. I want this software to be as universally useful as possible, so I need to design the packaging process to:
- Have the same developer experience as Docker images do ("push button, receive bacon").
- Have the most seamless administrator experience possible (ideally through distribution-native flows).
- Have as little cognitive overhead as possible for all parties involved (take the most obvious approach possible, when things need to diverge then be very loud about it).
The administrator experience bit is critical. As much as we'd all like them to, administrators simply do not have the time or energy to do detailed research into how a tool works. Usually they have a problem, they find the easiest to use tool, square peg into round hole it to solve the immediate problem, and then go back to the twelve other things that are on fire.
One of the really annoying downsides to wanting to do native packages as a downstream project is that the interfaces for making them suck. They suck so much for the role of a project like Anubis. They're optimized for consuming software from remote tarballs, doing the bare minimum to fit within the distribution's ecosystem.
For the context they operate in, this makes a lot of sense. Their entire shtick is pulling in software from third parties and distributing it to their users. There's a reason we call them Linux distributions.
However with Anubis, I want to have the packaging instructions live alongside the application source code. I already trust the language-level package managers that Anubis uses (and have been careful to minimize dependencies to those that are more trustable in general), and they already have hash validation. Any solution RFC-2119-MUST build on top of this trust and use it as a source of strength.
There frankly is a middle path to be found between the "simple binary tarball" and mini-maxxing into the exact perculiarities of how rpmbuild intersects with Go modules and NPM.
Honestly, this is why I was planning on paywalling binary packages. Binary packages also have the added complication that you have to play nice with the ways that administrators configure their servers. Debugging this is costly in terms of time and required experties. I am one person doing this on nights and weekends. I only have so much free time. I wish I had more, but right now I simply do not.
Cutting scope
When creating a plan like this, it's best to start with the list of problems you want to solve so that you can aggressively cut scope to remove the list of problems you don't want to solve yet. Luckily, the majority of the Linux ecosystem seems to have standardized around systemd. This combined with the fact that Go can just build static binaries means that I can treat the following OSes as fungible:
- Ubuntu Server
- Debian
- Red Hat Enterprise Linux
- OpenSUSE
- SUSE Enterprise Linux
- Rocky Linux
- Alma Linux
- CentOS Stream
Building Debian and Red Hat packages will cover all of them.
Additionally, anything else that is RPM/Debian based except maybe Devuan. Of those, there's three main CPU architectures that are the most common with a long tail of other less common ones:
- x86_64 (64 bit x86, goarch amd64)
- aarch64 (64 bit arm, goarch arm64)
- riscv64 (64 bit RISC-v, goarch riscv64)
At some level, this only means that we need to build 6 variants (one per CPU for Debian and Red Hat derived distros) to cover 99.9% of the mutable distributions in common use. This is a much more manageable level of complexity, I could live with this.
Anything else in the "long tail" (FreeBSD, OpenBSD, Alpine Linux, etc.) is probably better handled by their native packages or ports system anyways, but this is a perfect place for the binary tarballs to act as a stopgap.
Yeeting packages out
When I was working on the big Kubernetesification of my homelab last year, I was evaluating Rocky Linux and I was also building a tool called yeet as a middle ground between complicated shell scripts and bespoke one-off deployment tools written in Go. A lot of my build and deploy scripts boiled down to permutations of the following steps:
- Build docker image somehow (Nix, Docker, Earthly, ko, etc.)
- Push to remote host
- Trigger rolling release to the new image
I started building yeet because I had previously done this with shell scripts that I copied to every project's folder. This worked great until I had a semantics bug in one of them that turned into a semantics bug in all of them. I figured I needed a more general metapattern and thus yeet was born.
I had known about a tool called nfpm. nfpm lets you specify the filesystem layout of distribution packages in a big ol' yaml file that got processed and spat out something you can pass to dpkg -i or dnf -y install. The only problem is that it just put the files into the package. This was fine for something like the wallpapers I submitted to the Bluefin project, but the build step was left as an exercise for the reader.
I was also just coming down from a pure NixOS UX and wanted something that could let me get 80% of the nice parts of Nix with only requiring me to put in 20% of the effort that it took to make Nix.
So I extended yeet to build RPM packages. Here is the yeetfile.js that yeet uses to build its own packages:
["amd64", "arm64", "riscv64"].forEach((goarch) => rpm.build({ name: "yeet", descriptions: "Yeet out actions with maximum haste!", homepage: "https://within.website/", license: "CC0", goarch, build: (out) => { go.build("-o", `${out}/usr/bin/yeet`, "."); }, }) );That's it. When you run this (with just yeet), it will create a gitignored folder named var and build 6 packages there. You can copy these packages to anywhere you can store files (such as in object storage buckets). yeet's runtime will natively set the GOARCH, GOOS, and CGO_ENABLED variables for you under the hood so that you can just focus on the build directions without worrying about the details.
The core rules of yeet are:
- Thou shalt never import code from another file nor require npm for any reason.
- If thy task requires common functionality, thou shalt use native interfaces when at all possible.
- If thy task hath been copied and pasted multiple times, yon task belongeth in a native interface.
These native interfaces are things like go.build(args...) to trigger go build, docker.push(tag) to push docker images to a remote repository, git.tag() to get a reasonable version string, etc.
All of these are injected as implicit global objects. This is intended to let me swap out the "runtime backend" of these commands so that I can transparently run them on anonymous Kubernetes pods, other servers over SSH, or other runtime backends that one could imagine would make sense for a tool like yeet.
Deep lore: yeet was originally going to be Techaro's first product, but Anubis beat it to the punch!
The game plan
I plan to split building binary packages into at least two release cycles. The first release will be all about making it work, and the second release will be about making it elegant.
When I'm designing Anubis I have three sets of experiences in mind:
- User experience: what the experience is like for the end users that don't know (or care) what Anubis is
- Developer experience: what the experience is like for me and the open source contributors developing Anubis
- Administrator experience: what the experience is like for people setting it up on their boxes
The balance here is critical. These forces are fundamentally all in conflict, but currently the packaging situation is way too far balanced towards developer experience and not towards administrator experience. I hope that this strategy makes it easier for websites like The Cutting Room Floor to get relief from the attacks they're facing.
Making it work at all
The first phase is focused on making this work at all. A lot of the hard parts involving making yeet able to build Debian and Red Hat packages are already done. A lot of the rest of this involves software adulting including:
- Setting up a dedicated Mac mini to act as the build and signing host. This machine MUST NOT be used for anything else.
- Write documentation on how to build your own Debian/RPM packages with yeet.
- Write documentation specific to how to use the packages to run Anubis.
- Ensure that critical documentation is copied to the packages so that users can self-serve without access to the Anubis website.
- Uploading built packages to GitHub releases.
A lot of this is going to be tested with the (currently private) TecharoHQ/yeet repository.
Integration with distribution-specific package managers
The next stage will involve making the administrator experience a lot nicer. When administrators install packages, they expect them to be in repositories. This enables all software on the system to be updated at once, which is critical to the anticipated user experience. In order to reach this milestone, here's what I need to do:
- Fork yeet out of the /x/ monorepo and into a TecharoHQ repo (this has already been started, but will be slow going at first, I need to de-Xe the implementation of yeet).
- Set up repositories backed by object storage. That Mac mini from before will be the only machine that is allowed to write to that bucket. I will have to coordinate with the object storage provider I will be using in order to make sure this is the case.
- Publish a noarch Debian/RPM backage to bootstrap the Techaro root of trust and repo files. There will be at least two repositories: Debian and RPM. I may have to do the thing that Tailscale does where they lie about what distros are supported so that the repo URLs don't stand out too much compared to the experience that administrators expect from other publishers.
- Add support for basically every platform that Go can compile Linux binaries for. A lot of the small internet runs on smaller hardware. By making things more compatible, we can protect more small communities.
The first pass of a repository backend will be done with off the shelf tooling like aptly and rpm-s3. It's gonna suck at first, but this pass is all about making it work. Making it elegant can come next.
Leaving the ecosystem in a better state than we found it
Finally, I will improve the ecosystem such that other people can build on top of the Anubis tooling. Among the other tasks involved with this:
- Publish tooling for automating the management of repositories stored in object storage buckets based on what I like about aptly and rpm-s3. This will probably be included into yeet depending on facts and circumstances.
- Publish Software Bill of Materials (SBOM) reports with all packages. Ideally this will be done in the package themselves, but the important part is to make them available at all.
- Add Alpine and Arch Linux packages/repositories.
By the way, regarding Software Bills of Materials, I have not found clear guidance in Ubuntu, Debian, OpenSUSE, Red Hat, or Fedora's documentation on what I'm supposed to do with it or where to put it so that the system can collect and merge it. This is extra important from the perspective of Anubis because this packaging strategy is bypassing the normal flow for building distribution packages. Am I missing something? I found a dead thread about adding the SBOM to an RPM header, but that's it.
This will take time
As much as I'd love to end this with a "and here's how you can try this now" invitation, I'm simply not ready for that yet. This is gonna take time, and the best way to make this happen faster is to donate to the project so I can focus more of my free time on Anubis.
Also, don't do the mistake I did. I started playing Final Fantasy 14. It is so good. It sucks you in hard. 10/10. Don't play it unless you're willing to get enthralled by it.
Hopefully the expanded forms of yeet and whatever repository management tooling end up being useful to other projects. But for now, I'm starting with something small, slim, and opinionated. It's much easier to remove opinions from a project than it is to add them.
In the meantime, I hope you can understand why I've only shipped a Docker/OCI/Podman image so far. The amount of scope reduction is immense. However this project is getting popular and in order to show I'm taking it seriously I need to expand the packaging scope to include machines that don't run Docker.
Facts and circumstances may have changed since publication. Please contact me before jumping to conclusions if something seems wrong or unclear.
Tags: