.png)


Generally speaking, I think large language models (LLMs) like ChatGPT and Claude are closer to underrated than overrated. Their adoption curve has been incredibly fast: by some measures, they’re the most rapidly growing technology in human history. It’s easy to cherry-pick examples of AI “hallucinations”; in my experience, these are becoming considerably less common, and I sometimes wonder whether people who write skeptically of LLMs are even using them at all.
I use these models almost every day, for tasks ranging from the whimsical (planning a trip to Norway) to the mundane (checking Silver Bulletin articles for typos: admittedly, a few still slip through). And I’ve seen them improve to the point that I increasingly trust them to improve my productivity. When I was preparing this year’s edition of our NCAA tournament forecasts, they were valuable in reconciling various data sets, effectively performing some annoying lookup tasks, and generating short snippets of code that often worked seamlessly. That’s a long way from building a good model from scratch. But they often save a lot of tedious work, freeing bandwidth up for more creative and higher value-add tasks. Perhaps 80 percent of the time, their performance is somewhere between marginally helpful and incredibly impressive.
But that leaves the 20 percent of the time when they aren’t up to the task. I think LLMs are a substantial positive to my workflow, but that’s because I’m nearly always using them for tasks I could do myself, so that I can vet their answers and know when they’re wrong. For instance, when it comes to using LLMs for another subject I know well — poker — they’ve been exceptionally underwhelming.
I want to be careful about this. Like with the old Louis CK routine about people complaining about patchy Wi-Fi on planes, some of this undoubtedly reflects rising expectations for what is objectively an incredibly impressive technology. Still, an increasing number of people whom I respect think artificial general intelligence (AGI) — usually defined as being able to match or exceed human levels at nearly all (cognitive) tasks — might be as little as a year or two away.
But if there are examples where LLMs already seem to have superhuman capabilities, they’re very far from it in poker. And I’d argue that poker is a better test of general intelligence than some of the more discrete tasks that ChatGPT performs so well.
Before we get into the weeds, let me shore up one point of potential confusion. To a strong first approximation, computers are already better than humans at poker. Let me explain what I mean by that, and why it doesn’t contradict what I just wrote above.
Poker strategy has been revolutionized by the use of solvers, algorithms that provide a close approximation of game-theory-optimal (GTO) strategy, more technically known as a Nash equilibrium. Personally, I don’t consider solvers themselves to be examples of “artificial intelligence” — they don’t use machine learning, and instead are basically solving complex equations in a prescribed way that converges on a deterministic solution. But this is a slightly fussy distinction. Solvers are highly impressive, and they’ve contributed to more sophisticated poker play. (A skilled amateur from today who has picked up some solver basics through osmosis might well be better than an elite player from 20 years ago.) Basically, you can now look up the “right” answer for how to play your hand in any given poker situation, provided that — and this is an important proviso — you’ve given it the right inputs. In addition, there are various computer programs that use more traditional AI/machine learning techniques, either to enhance solver outputs or to derive a poker strategy from scratch.
Those are computer tools specifically designed to play poker, however. What would be more impressive — more of an indication of general intelligence — is if large language models like ChatGPT that weren’t designed for poker could converge on a good strategy just by crunching textual data and learning to reason from it. But for now, they aren’t close to doing that well.
I gave ChatGPT’s o3 model — which I generally find reliable for a variety of tasks — the following prompt:
Simulate a Texas no limit hold 'em hand involving eight players with stacks of $5000 each in a $5/$10 game with a $25 straddle. Narrate the hand, including names/backstories for each player, but please draw the cards randomly and honestly rather than preordain the outcome.
Unavoidably, the rest of this post will require some forays into poker strategy and terminology. I’ll try to smooth things over as much as possible by consigning some of the details to footnotes. (There are going to be a lot of footnotes.) But this is a nerdy post — quite honestly, among the nerdiest Silver Bulletins ever.
This prompt describes a fairly typical setup for a no-limit hold ‘em cash game. Traditionally, hold ‘em hands start with two forced bets called blinds — here, the small blind is $5 and the big blind is $10 — that rotate around the table. (Without blinds or antes, there’s no pot to compete for, so poker is a broken game.) In this example, as is common in live cash poker these days, the players have agreed to add a third blind bet called a straddle for $25 to induce additional action.
Let’s start by introducing the cast of characters that ChatGPT came up with:
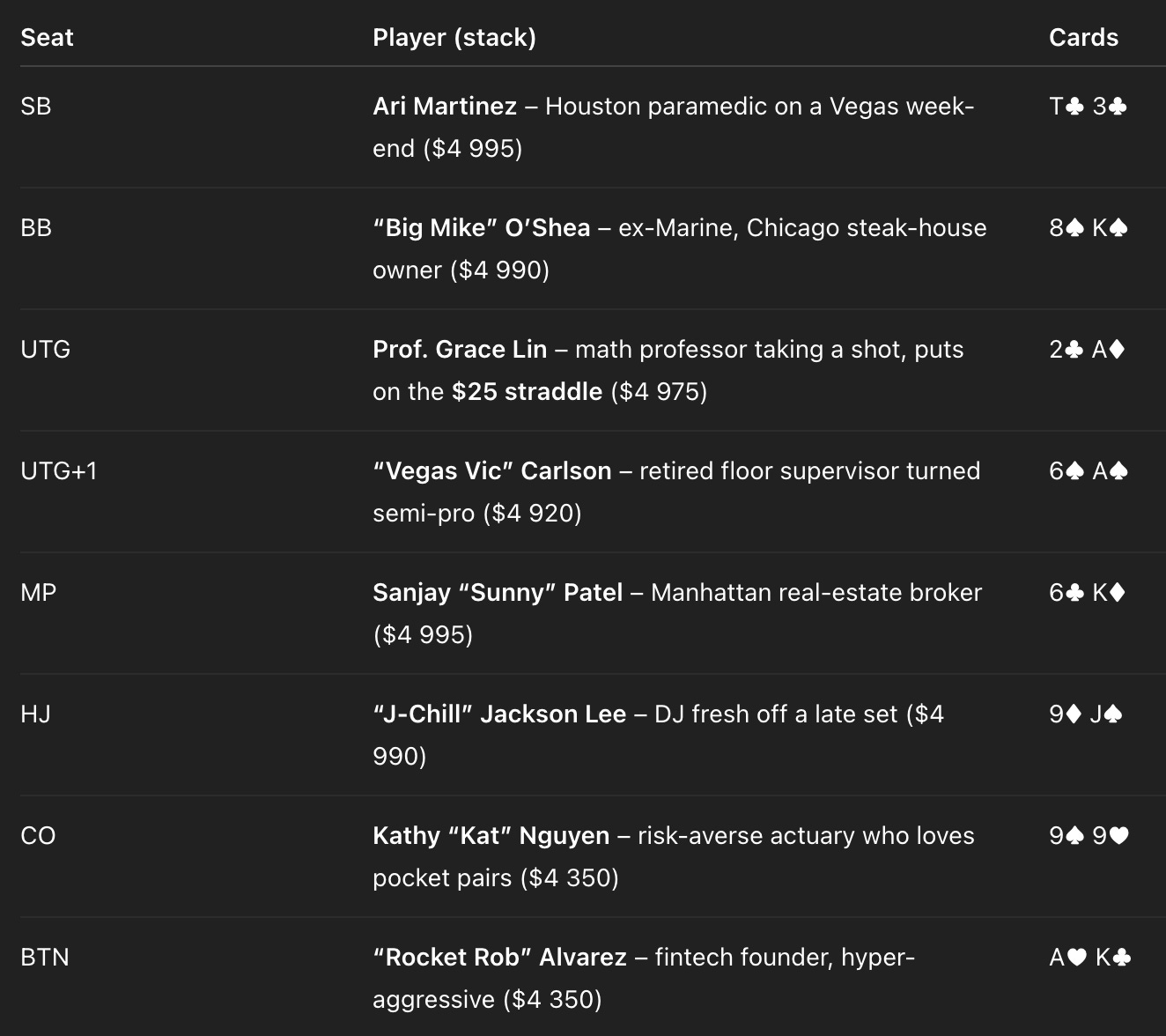
I’d love to play in this game. Every player seems to be some species of fish who will either be predictably too tight or too loose. (Also, some of the ethnic stereotypes are a bit on the nose, like DJ “J-Chill” Jackson Lee — although I did once play against the famed DJ Steve Aoki late one night at the Bellagio after his set was done.)
So far, this isn’t so bad. ChatGPT labeled and ordered the positions correctly, for instance. No cards are duplicated, and the distribution of cards looks random enough — it’s not dealing everyone pocket aces and kings. The stack sizes are weird, though. Instead of everyone starting with $5,000 like I requested, players have mysteriously lost some chips off their stacks. This was a consistent problem in using ChatGPT in my testing — it couldn’t reliably keep track of stacks — in some cases prematurely subtracting chips based on what would happen later on the hand.
So let’s go through this hand in the style of Sam Greenwood’s Punt of the Day and see what happens once the cards are dealt:
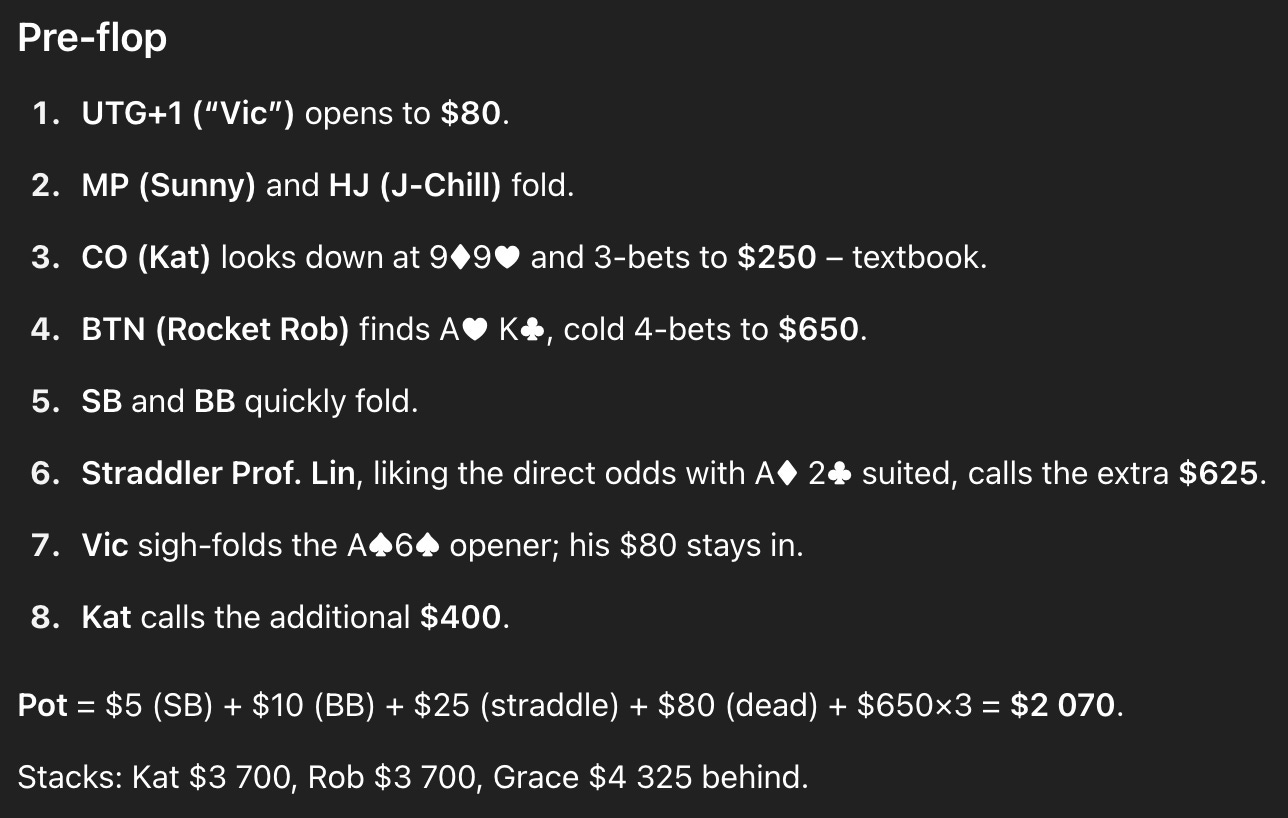
This starts out reasonably enough. Vic opens the action by raising with a suited ace — A♠️6♠️ — which is a borderline by GTO standards but totally fine. Kat re-raises with pocket 9’s (9♠️9♥️). This is definitely a hand you’ll want to play; calling rather than raising would be acceptable too, but you can’t fold. Then Rocket Rob re-re-raises (4-bets) with ace-king (A♥️K♣️). Technically, this is a close decision with two other players already having shown such strength. But the overwhelming majority of players in a real poker game are going to raise, just like Rob did.
Then things go off the rails. Facing three other players who have already shown aggression, Prof. Grace Lin calls with a meager hand, a low offsuit ace (A♦️2 ♣️) that has absolutely nothing going for it. ChatGPT says she’s “liking the direct odds,” but that doesn’t make any sense: her odds are terrible. She’s only put $25 in the pot and now has to call $625 more.
In fact, Grace is in just about the worst situation you can encounter in poker. She figures to have the fourth-best hand in a field of four opponents, and now she’s playing a huge pot where she’s putting her entire $5,000 at risk but will rarely have the goods to back it up. A solver says you’re basically only supposed to play pocket aces (e.g. A♦️A♣️) in her shoes, plus a smattering of bluffs — and all of these hands would be played for another raise rather than a call. Real-life players will almost certainly be looser than the computer, continuing with two kings, pocket queens, and probably pocket jacks and AK. Certainly, you’ll also encounter some players who find a hand like ace-queen suited (e.g. A♦️Q♦️) or pocket tens too pretty to fold. But even a 99.9th percentile fish isn’t playing a hand like A♦️2 ♣️ facing such bad odds and so much aggression. And although Grace is an inexperienced player according to ChatGPT’s backstory, she’s a “math professor taking a shot”, which implies that she should know the odds and is probably playing tight. The story doesn’t add up at all.
Vic, wisely, finds the obvious fold with his suited ace, even though it’s a better hand than Grace’s offsuit ace. Kat could probably fold too with her pocket 9’s, but continuing isn’t too bad. ChatGPT is also counting the pot slightly wrong, but that’s the least of my concerns for now.
Onto the first three cards, a.k.a. the flop:

Every player just checks, and honestly, this is fine. Rob’s ace-king doesn’t like seeing two queens on the board, and although in theory you might bet his hand some of the time, I wouldn’t bet myself, because I’d assume Grace had a great hand after calling against three other opponents.
The next card, the turn, puts a second 4 on the board:

This is what poker players call a “blank”: it’s unlikely that any player reached this point in the hand with a 4, a weak card. So everybody checks again. But this is probably a mistake, at least for Kat. Facing so many checks so far, her pocket 9’s have increased a lot in relative value and are sometimes the best hand; she also might be able to get a slightly stronger hand like TT or JJ to fold.
The final card, the river, is another innocuous one, the 5♠️, that shouldn’t connect with any player’s hand:
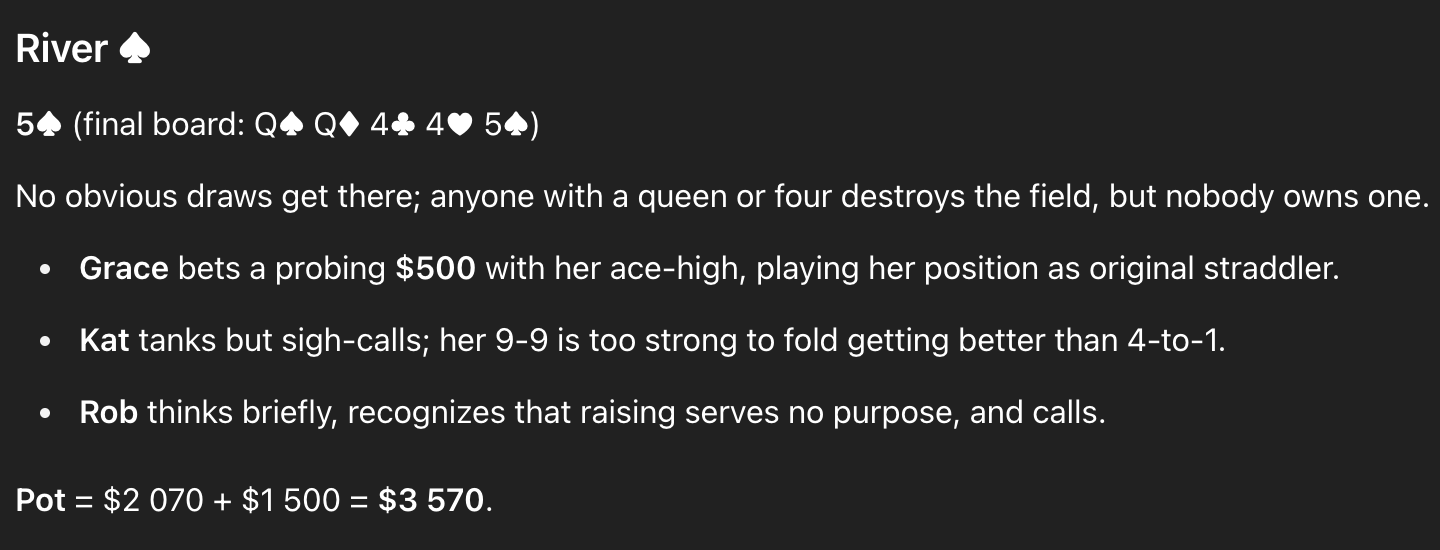
Now Grace bets out, but it’s a small bet — $500 into the $2070 pot. Although you will sometimes encounter players in the wild who make small bets like these when they get confused and don’t know what else to do, it’s a terrible play. If Grace is bluffing — and at this point, she is bluffing — the bet needs to be larger to put more pressure on her opponents.
ChatGPT’s explanation might sound smart if you don’t know poker, but it’s basically just word salad. Grace isn’t “playing her position” — she’s actually in the worst position. She does have some good reasons to bet, but either the bet needs to be larger, or her hand needs to be stronger. Kat’s call with pocket 9’s is correct, but given how weirdly Grace has played the hand and the odds Kat is getting, it’s an easy call, not a “sigh-call”. Finally, Rob’s call at the end is terrible. At best, he’s splitting the pot two or three ways against other ace-highs. But far more often, he’s losing to at least one of his opponents (as he is to Kat in this case). Raising as a bluff could be a sexy play — but if Rob isn’t raising, he should fold. So once again, ChatGPT has him picking the very worst option. And the jargon it uses — “recognizing that raising serves no purpose” isn’t on-point either. Rob might well be able to bluff out better hands with a raise, which is one of the primary purposes of raising.
So what explains all these dubious decisions? Hold that thought, because we haven’t even gotten to the worst part of ChatGPT’s response. It turns out it didn’t even know how to calculate who won the hand:
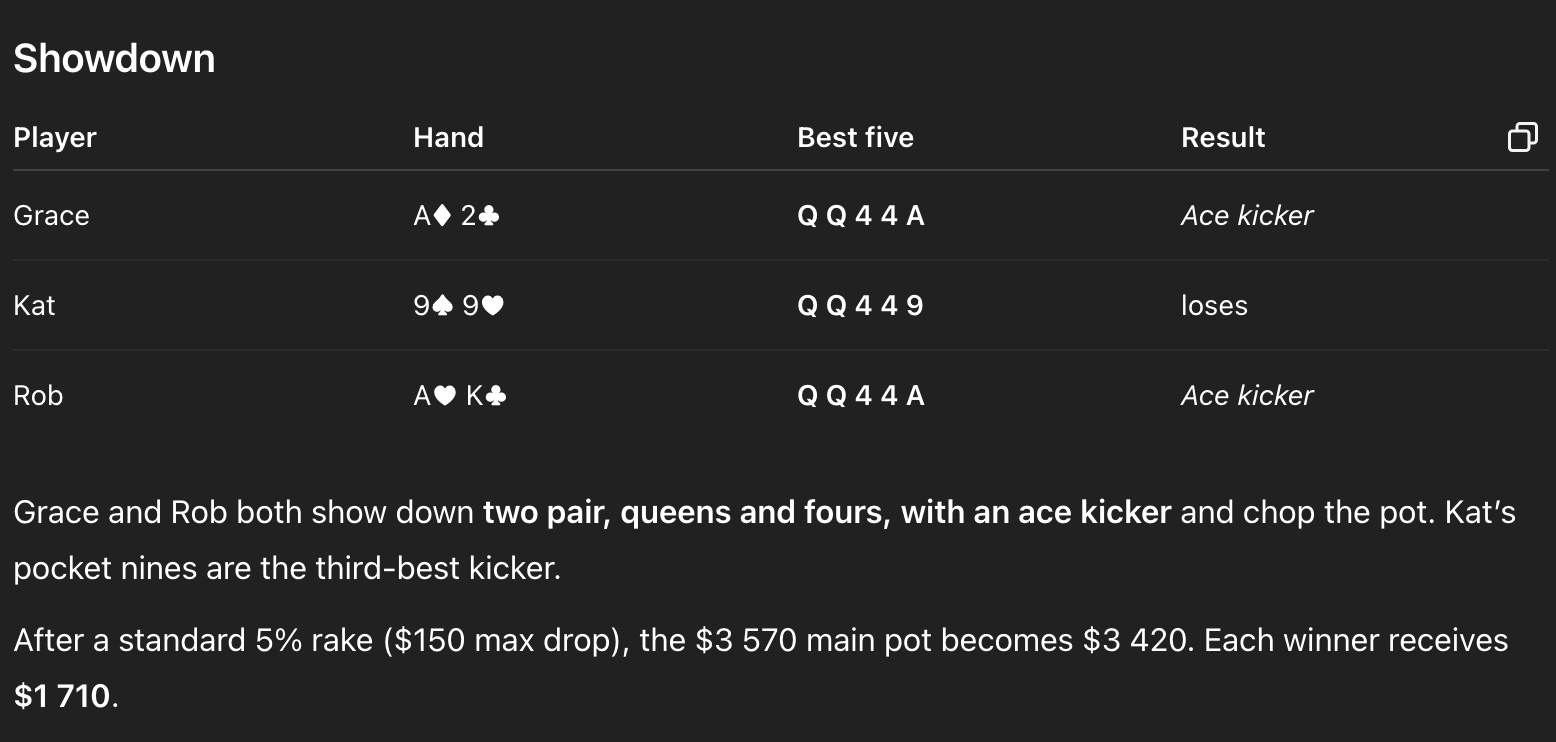
In hold ‘em, only the five best cards count toward making the best hand; they can be any combination of the player’s two hole cards and the five shared community cards (the flop/turn/river). So in this case:
Grace and Rob both have two pair, Q’s and 4’s, with an ace kicker. That is, they now have the same holding.
Kat, however, has a higher two-pair — Q’s and 9’s, namely the pair of queens from the board and the pair of nines from her hand. The pair of fours is redundant for her hand.
So Kat just won a huge pot. But instead, ChatGPT splits the chips between Grace and Rob. Once in a blue moon, you’ll see dealers make mistakes this bad, but it isn’t common. And if ChatGPT didn’t even know to read a poker board amidst all this excitement, one wonders how that affected its strategic choices throughout the rest of the hand.
Can ChatGPT make any more errors? Uhhh…. yes, actually:
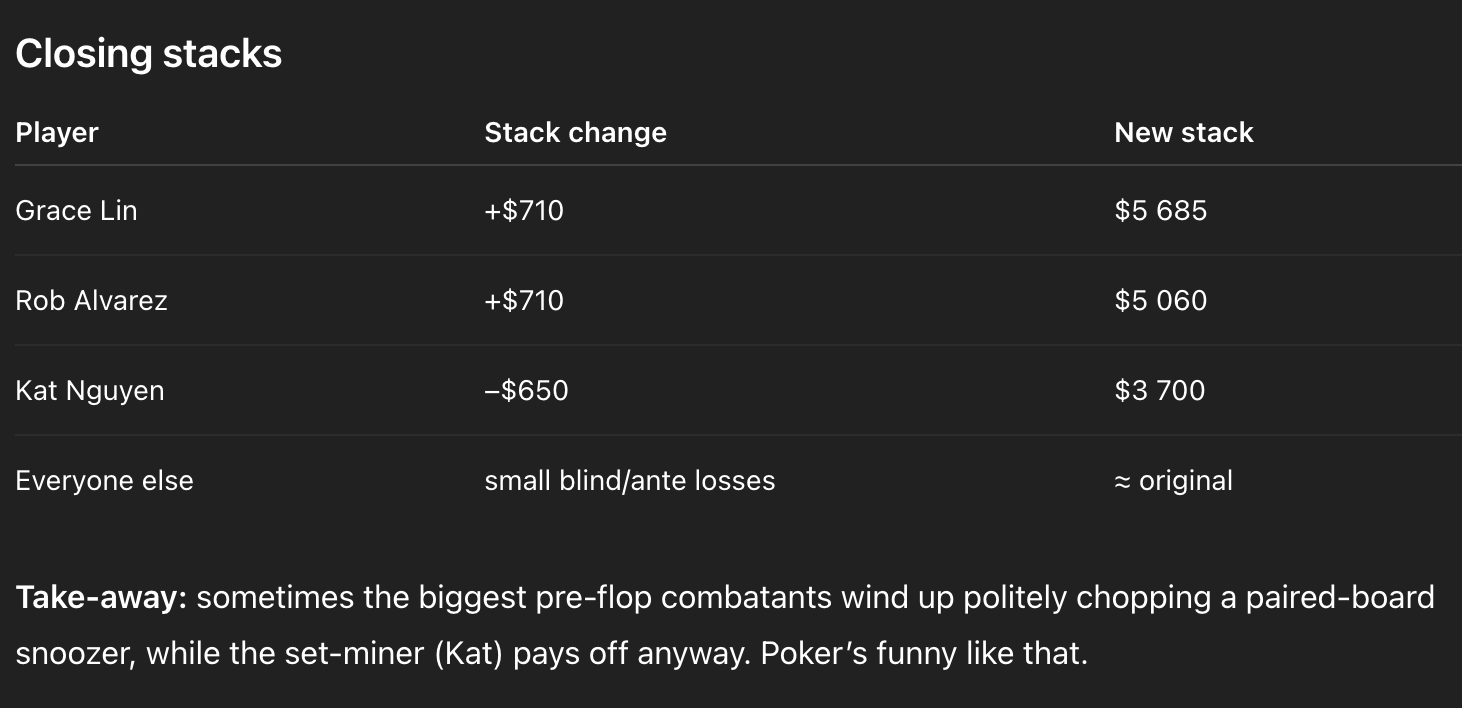
ChatGPT says Kat lost $650 in the hand. But if you ignore that she should have been awarded the pot, she actually lost $1,150 in the hand, putting in $650 before the flop and then another $500 on the river. So to summarize, ChatGPT: 1) made inexplicably poor strategic decisions throughout the hand, one of which (Grace’s original call) was among the most -EV plays you’ll ever encounter in poker; 2) awarded the pot to the wrong player(s); 3) repeatedly failed to calculate the pot and the stacks correctly. I wasn’t expecting it to get everything right, and this is a difficult prompt, but it went wrong at almost every turn.
I might be more sympathetic — but this was literally the first hand I asked ChatGPT to simulate for me. Still, to give it a second chance, I used Deep Research to play out a complete orbit of eight hands. Deep Research is expensive — a ChatGPT Pro subscription costs $20 bucks a month — but it takes more time with its answers and brings more compute to the problem.
To Deep Research’s credit, it seemed to understand this was a difficult task: “That sounds like a rich simulation,” it told me. And it did better than in the original example — it could hardly have been worse. But it still made a lot of egregious errors.
You can find its response here or in the PDF above. Deep Research repeatedly failed to calculate stack sizes correctly. It also hallucinated (in hand #8) the presence of a flush draw in spades, which significantly altered the strategy. And it employed many poker terms in a garbled and incorrect way.
And although it’s a small sample size, it also showed signs of an imbalanced strategy, almost always bluffing for huge amounts when flush draws and straight draws missed — this would be easy to exploit — while being reluctant to bet for value. If employed in a poker room, this approach would lose money at an incredibly high rate.
To be fair, poker is a difficult game. Intermediate players rarely derive the right play from first principles. Instead, they evaluate them based on competing, sometimes crude heuristics.
If you’re being attentive, you can pick up a lot of information from physical tells or priors based on a player’s backstory; if you’re not, you’ll often give away more information than you receive. A great player, at least in higher-leverage spots, needs to both focus intently on each decision and account for this background context. Often, there’s a trade-off.
Likewise, LLMs seem to get stressed out when you ask them to do too much at once. For instance, if you just ask o3 to evaluate whether 99 or A2 wins on a QQ445 board as the initial prompt, without the context of simulating an entire poker hand, it gets the answer right. It’s when you layer tasks on top of one another that they more often hallucinate or glitch out.
In part, this reflects how some of the techniques LLMs use to respond to more complex prompts with larger context windows are relatively new. Benjamin Todd has an excellent overview of this in his essay “The case for AGI by 2030”. The idea of building layers of “scaffolding” so that LLMs can break down a complex problem into discrete steps — for instance, in the context of poker, counting the pot correctly, reading the board correctly, and then making reasonable strategic decisions at various points in the hand — may work well enough if there are two or three steps in the chain. But the more steps you add, the more likely you are to get an error that renders the output useless or worse. Here’s Todd:
Any of these measures could significantly increase reliability, and as we’ve seen several times in this article, reliability improvements can suddenly unlock new capabilities:
Even a simple task like finding and booking a hotel that meets your preferences requires tens of steps. With a 90% chance of completing each step correctly, there’s only a 10% chance of completing 20 steps correctly.
However with 99% reliability per step, the overall chance of success leaps from 10% to 80% — the difference between not useful to very useful.
Like Todd, I expect LLMs to continue progressing to the point where we probably get something that most people would agree is AGI. However, I also suspect the current state of the models when employing this scaffolding process is worse than he assumes. I’ve mostly had a great experience with ChatGPT when I’m able to coax it along from step to step. And I’ve increasingly seen it be able to handle prompts well when I ask it to do two or three things together, e.g. “figure out the right mathematical function for this thing I’ve stated in natural language and then write some Stata code for it”. But add much more complexity than that, and I’ve found performance often drops off a cliff and that I’m wasting my time and my Deep Research tokens.
Could poker be a good way to diagnose when and if these models do achieve AGI? Maybe. One reason I like using poker to test LLMs is that I suspect the major AI labs aren’t putting a lot of attention on poker specifically.
In contrast, for higher-prestige questions like solving the Math Olympiad, there may be some degree of “teaching to the test”. That is, if the AI labs know what questions will be used to benchmark LLMs and they’ll get to brag about in press releases, they’ll work to optimize their performance for those. There’s also the issue that the answers to these problems may be contained somewhere in the training data, whereas publicly available text content on poker is often mediocre.
I’d surmise it would be pretty easy to train the models to recognize when they were asked poker questions and summon additional resources accordingly, like referencing the poker rulebook or performing GTO Wizard simulations. Operating in this mode, LLMs serve as CEOs that learn to delegate specific tasks to other types of AIs in response to certain prompts, or even delegate them to humans.
But is that cheating? Well, it depends on whether you think LLMs themselves are a pathway to AGI, as opposed to AGI being achieved through a lattice of overlapping techniques. During the COVID pandemic, the phrase “Swiss Cheese Model” was sometimes used to denote the various interventions that were in place — masks, social distancing, vaccines, and so on. None of these were foolproof, but the hope was that the holes wouldn’t line up.
For LLMs on their own, however, poker is a hard problem because it requires working at various levels of abstraction:
On the one hand, the rules of the game are fixed and there is basically a mathematically correct answer to any given situation, but it’s extremely complicated to derive.
On the other hand, there are a lot of fuzzy contextual factors when humans play poker — more so than in chess, for example — from picking up on tells to making adjustments when opponents don’t play like a computer might.
Somewhere in between, there is a situation-specific optimal strategy given the parameters of the situation. But these fuzzy factors can have cascading effects: a single deviation at any node of the game can radically alter the optimal strategy throughout the entire hand or even the entire game or tournament. So the solutions are relatively fragile as compared with a “game” like natural language processing, where, say, a misspelled word in a ChatGPT prompt will usually present no problem.
My theory is that the Nash equilibrium for poker is complex enough — full of mixed strategies and highly context-dependent assumptions — that it’s hard for it to emerge organically with an LLM or another model that isn’t explicitly trained for this purpose. So how about getting there through a patchwork of loose heuristics instead? Well, there’s a fine line between winning heuristics and losing ones. For instance, a heuristic that ChatGPT seems very fond of — “my draws missed, therefore I have to bluff, and since I have nothing I have to bluff huge” — is a phase that every human poker player has gone through at some point. You might even get away with it the first couple of times. But in general, you’re risking a lot to win a little. In theory, this approach is bad and it’s often even worse in practice.
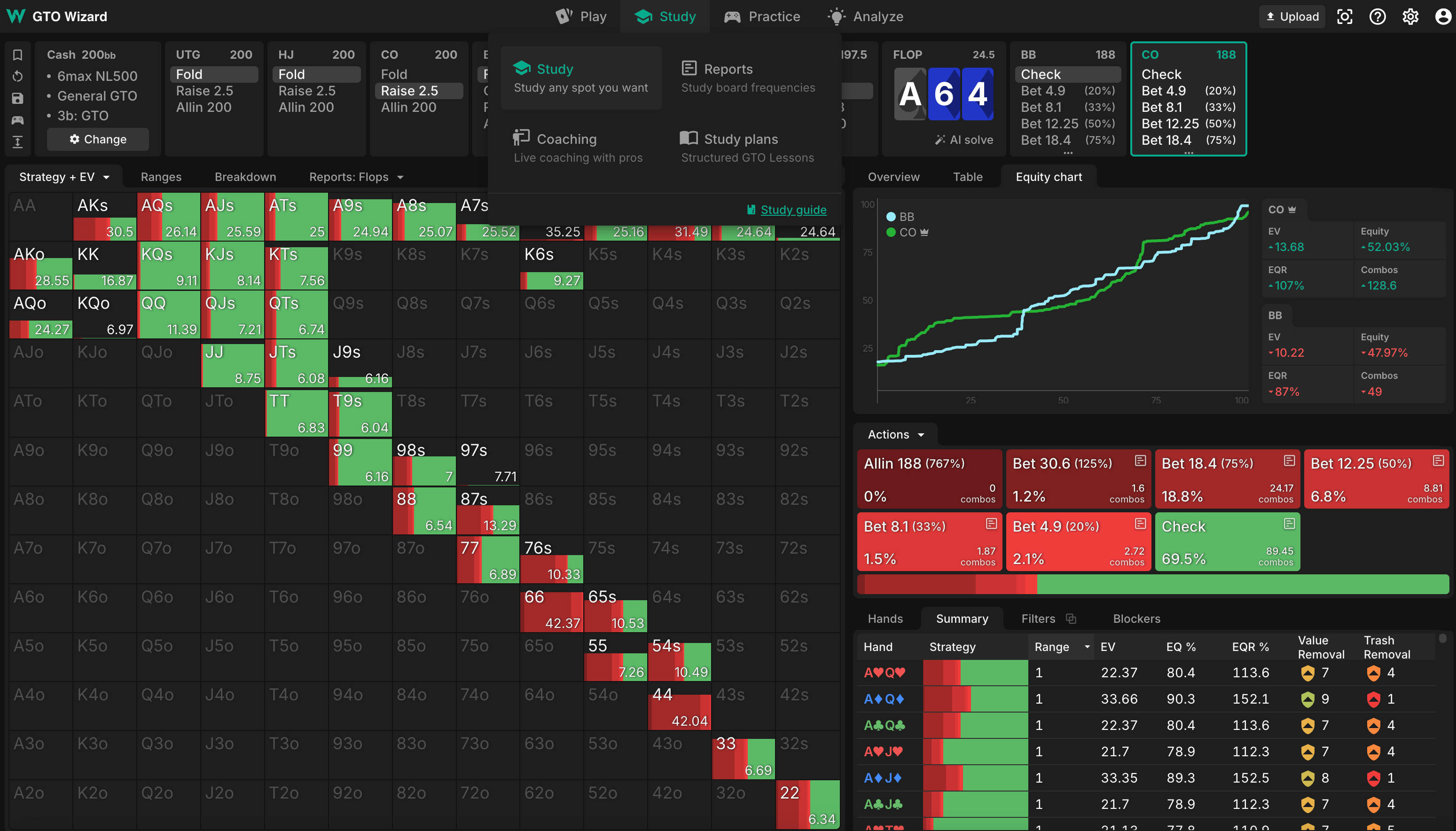
Expert human players iterate back and forth between learning through solvers and by experience on the poker felt. They might look up a solver solution from a hand that knocked them out of a tournament and realize they were playing a certain spot incorrectly. They try to implement the fix in their gameplay and usually, after some practice, they understand what the solver was doing and develop a better feel for the situation. But there can still be pitfalls to this approach. Some solver solutions are exceptionally complex. For instance, in this GTO Wizard simulation of a common poker spot, the player in position uses a mix of checks and five different bet sizes, ranging from 20 percent to 125 percent of the pot. So players learn when there’s significant EV loss from simplifying their strategies and when they can get away with simpler strategies (“always bet one-third of the pot”) that are harder to screw up.
And in live poker, there are even more factors to consider, such as the past history with opponents and intuitions based on physical reads. Also, the solver solutions aren’t helpful if they don’t match how their real-life opponents are playing. I’ve seen plenty of real-life WSOP hands where some European whiz kid implemented a fancy solver-driven strategy when instead they could have maximized their profit by playing straightforwardly because their opponent was a fish.
My guess is that LLMs have trouble going back and forth between these different levels of abstraction. Solvers are quite computationally intensive, and yet they don’t even consider many of the factors that matter in real-world poker games. So when you ask an LLM to consider other contextual factors too — like creating backstories for each player — it’s just too heavy of a cognitive load.
They’ll probably get there eventually. But if the future is unevenly distributed, artificial intelligence may be, too. I expect the pathway to AGI to be patchy, with miraculous-seeming breakthroughs on some tasks but others where humans will continue to perform better than machines for many years to come.
![GE Presents: "You and The Computer" – 1969 [video]](https://www.youtube.com/img/desktop/supported_browsers/edgium.png)

