.png)

If you’ve ever been deep in a ChatGPT session and suddenly got this message:
“You’ve hit your usage limit. Please try again later.”
You’re not alone.
Whether you’re using ChatGPT Free or ChatGPT Plus, these usage limits can hit at the worst possible time. They cut off your conversation, downgrade your model, or slow your workflow when you need it most.
In this guide, you’ll learn:
- The latest ChatGPT usage limits across Free, Plus, Business, and Pro plans
- Why ChatGPT has usage limits and what’s happening behind the scenes
- Other hidden limitations that hold you back
- How to remove all limits by self-hosting models with Bento Inference Platform
Let’s dive in.
What are ChatGPT’s current usage limits?#
As of October 2025, ChatGPT’s usage limits depend on your subscription tier. Different plans have different rolling message caps that affect how long and complex your conversations can be.
Here is the breakdown:
| Free | $0 / month | 10 messages every 5 hours | 1 message per day | Auto-downgrade to the Mini version after hitting limit |
| Plus | $20 / month | 160 messages every 3 hours | Up to 3,000 messages per week | Auto-downgrade to the Mini version after hitting limit |
| Business | $25–30 per user / month | Virtually unlimited | Up to 3,000 messages per week | |
| Pro | $200 / month | Virtually unlimited | Virtually unlimited |
Note: “Virtually unlimited” means usage is still subject to OpenAI’s abuse guardrails and fair-use policies.
How ChatGPT chooses between Chat and Thinking modes#
Behind the scenes, ChatGPT can automatically decide whether to use its Chat mode or the slower but more capable Thinking mode for your query.
All plans currently use GPT-5 as the core model family.
Paid tiers — Plus, Business, and Pro — provide a model picker, allowing you to manually choose between:
- GPT-5 Auto: Lets ChatGPT decide what mode to use
- GPT-5 Instant: Prioritizes speed and responsiveness
- GPT-5 Thinking: Uses extended reasoning for complex tasks
Business and Pro plans also include GPT-5 Thinking Pro. It takes slightly longer to respond but provides deeper reasoning and higher accuracy for multi-step tasks.
Each mode has a different maximum context length. It refers to the amount of information the model can remember and reason over in a single conversation. A larger context window means the model can handle longer conversations or maintain richer reasoning chains without losing context.
| Instant | 16K tokens | 32K tokens | 128K tokens |
| Thinking | – | 196K tokens | 196K tokens |
Why do ChatGPT usage limits exist?#
It’s frustrating, but those limits aren’t random, and they’re not just there to push you to upgrade.
Let’s look at what’s really happening behind the scenes.
To manage massive infrastructure load#
Running a frontier model like GPT-5 isn’t simple.
Every time you send a message, it spins up a network of GPUs that process billions of parameters in real time. Multiply that by hundreds of millions of active users, and you start to see the scale of the problem.
Usage limits help OpenAI balance global demand and prevent GPU overloads that could slow or crash the system.
To control costs#
Every ChatGPT response has a real, measurable cost.
Models like GPT-5, especially the Thinking variant, burn more GPU time than GPT-4 or 3.5 ever did.
So those message caps aren’t arbitrary. They’re cost-control levers that keep usage predictable and sustainable.
This is also why the free plan is limited. It gives users access to GPT-5 capabilities without draining compute resources or subsidizing unlimited free queries.
To keep things fair#
If some users could send unlimited messages, they’d dominate available resources. This means other users will experience slow responses or downtime.
Usage limits ensure fair access across all users. This way, more people will have an opportunity to use ChatGPT without slowdowns or outages.
To prevent abuse#
Without restrictions, ChatGPT would quickly become a target for automated abuse, from data scraping to prompt-stuffing bots.
Caps make it harder to weaponize the platform for:
- Bulk content farming
- Automated scraping or spam attacks
- Token-draining DoS attempts
So in short, usage limits are not there to annoy you. They’re there to keep ChatGPT online for everyone.
What are other limitations of ChatGPT?#
At its core, ChatGPT is a chat interface built on top of proprietary models like GPT-5. While usage limits grab the most attention, they’re far from the only pain.
If you’re an enterprise user or rely on the OpenAI API to build an AI system, you’ll quickly notice a few areas where closed-source models can hold you back.
By contrast, when you self-host an open-source or custom model, you gain full control over performance, privacy, and optimization. There is no throttling or black-box constraint.
Here’s what you need to know.
Unpredictable performance#
Let’s start with the obvious one.
The performance of proprietary model APIs can vary hour to hour, and sometimes even prompt to prompt. Specifically, you might notice (especially during high-traffic periods):
- Slower response time
- Inconsistent reasoning depth or accuracy
- Temporary downgrades to smaller models
That’s because you’re sharing a multi-tenant system with millions of concurrent users. You don’t control when it’s under heavy load or which GPUs your request lands on.
Your latency (and sometimes even model quality) depends on overall system demand. Add rate limiting on top of that, and you get unpredictable throughput and occasional timeouts.
The result? Inconsistent and unstable performance that can ripple straight into your own applications.
If your product depends on proprietary APIs, this uncertainty can frustrate users, break integrations, and erode trust over time.
If you need consistent latency and predictable behavior, self-hosting is the answer. You own the queue, batch size, and hardware. This means your application’s performance no longer depends on external rate limits or sudden policy changes.
Data privacy and compliance#
Every prompt you send to ChatGPT travels through OpenAI’s servers.
While OpenAI provides enterprise-grade security and supports opting out of data retention, for many organizations, especially those in finance, healthcare, or government, that’s still not enough.
You have limited control over:
- Data residency (where your prompts and responses are stored)
- Regulatory compliance with frameworks like GDPR
- Auditability for sensitive inputs and outputs
This is a serious challenge when building AI systems like RAG or AI agents that frequently handle internal documents, customer data, or proprietary research.
In regulated industries, sending that information to a third-party API can raise security, privacy, and compliance risks your organization simply can’t afford.
Self-hosting eliminates these concerns entirely. When you deploy your own model, all prompts, logs, and embeddings stay within your infrastructure. You have full control over data governance and compliance.
Lack of customization and optimization#
GPT-5 is built for general-purpose chat, not for your unique workload or latency requirements.
Here’s what you can’t do with ChatGPT or the OpenAI API:
- Optimize for latency or throughput based on your real traffic patterns.
- Implement advanced inference techniques like prefill–decode disaggregation, prefix caching, or speculative decoding. These are key methods to make your inference faster and more cost-effective.
- Optimize for long contexts or batch-processing scenarios.
- Enforce structured decoding to ensure outputs follow strict schemas.
- Fine-tune models with your proprietary data to gain domain-specific performance advantages.
When you call the same global API as everyone else, you get the same configuration and decoding behavior.
Think about it: how can your product gain a competitive edge if it behaves exactly the same as every other app using the same endpoint?
Self-hosting flips that script.
You can fine-tune open models or deploy custom inference logic for your use cases. These are all optimized for your workload, not someone else’s.
That’s how teams can own their inference stack, which is faster, cheaper, and fully customized.
Spiraling and unpredictable costs#
The per-token pricing model of proprietary APIs works well for rapid experiments, but it quickly breaks down at scale.
High-volume workloads such as code generation, RAG, and multi-turn reasoning can rack up thousands of dollars a month.
And because pricing is metered by tokens, your bill fluctuates with user behavior, not your business planning. A busy week or a sudden traffic spike can easily double your costs overnight.
In other words, your cost curve depends on usage volatility, not infrastructure efficiency.
Self-hosting changes that equation completely.
Instead of paying per token, you mainly pay for GPU compute hours. You decide how to allocate them. Cost becomes predictable and controllable.
With the right configuration, you can:
- Autoscale intelligently, so you only pay for GPUs when they’re actually processing requests.
- Batch or schedule workloads to squeeze every bit of utilization out of your hardware.
- Use KV cache offloading and other inference optimizations improve inference efficiency and cut costs.
- Distribute deployments across clouds and regions with the best GPU availability and pricing.
When you self-host, every optimization you make directly improves your bottom line. You’re not just using AI; you’re engineering efficiency into your infrastructure.
When to ditch caps: Self-host an open-source LLM#
If your team keeps smashing into the limits we just covered, it’s time to take back control.
What you gain by self-hosting:
- No usage caps: Run as many inference workloads as your hardware can handle.
- Data privacy: Keep models and data inside your security boundary.
- Performance control: Tune batching, KV cache policies, and inference logic for your exact workload.
- Predictable cost: Pay for GPU hours, not per-token surprises.
Learn more about the benefits in our LLM Inference Handbook.
Popular open-source choices (2025):
- DeepSeek-V3.1 / R1 (strong general + reasoning variants)
- Qwen3 family (chat, coding, vision language, reasoning)
- GPT-OSS class (general-purpose instruction-tuned)
- Kimi-K2 (frontier agentic performance)
Learn more about the best open-source LLMs in 2025.
Are proprietary models more powerful than open-source models?#
It’s a fair question and the short answer is:
NOT NECESSARILY.
Proprietary models are closed AI systems owned and operated by enterprises. Their weights and source code are locked, and access comes only through paid APIs or subscriptions.
That doesn’t make them inherently better. It just makes them less transparent and less customizable.
While GPT-5 and Gemini-2.5-Pro still dominate headline benchmarks, the truth is that open-source models have caught up fast.
Models like DeepSeek-V3.1, Qwen3, and Kimi-K2 now match and in some cases outperform proprietary ones in real-world inference tasks. You can check the benchmark results in their research papers.
Real-world results tell the story#
Here are two examples from leading companies:
Guillermo Rauch, CEO of Vercel, shared that Kimi-K2-Instruct-0905 achieved up to 5× faster speed and 50 % higher accuracy than frontier proprietary models like GPT-5 and Claude-Sonnet-4.5 in their internal agent benchmarks.
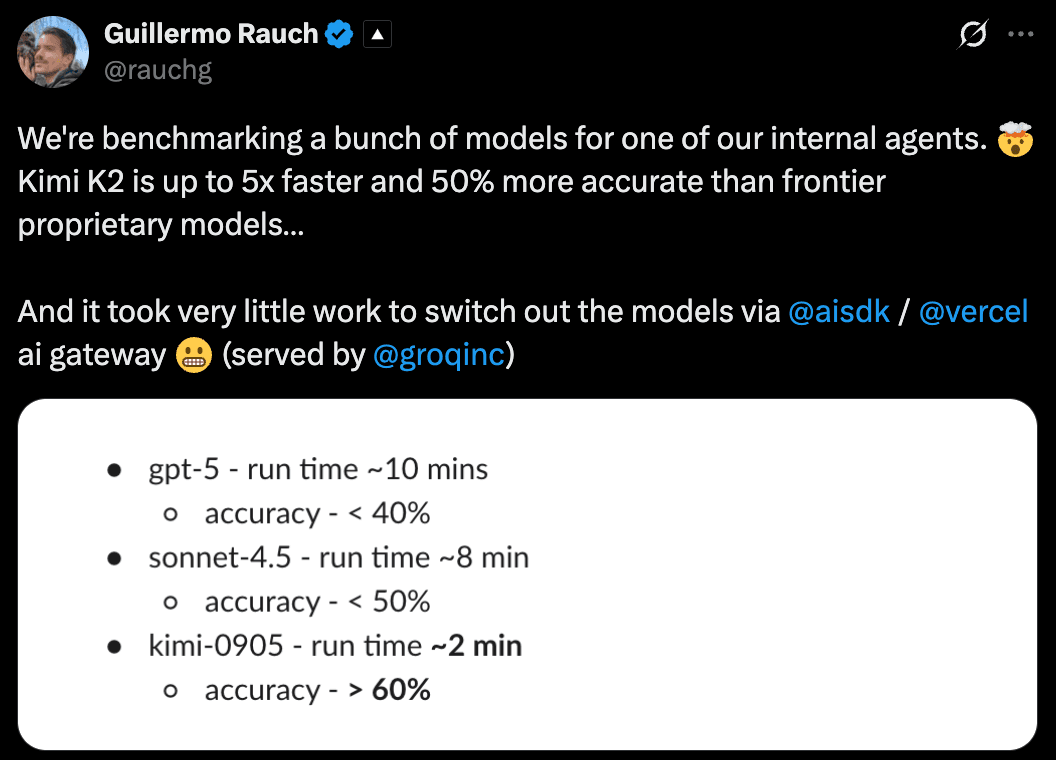
Airbnb CEO Brian Chesky said they chose Qwen over OpenAI’s models because it’s faster and more cost-efficient for their workloads.

These aren’t isolated examples. They reflect a broader shift across the industry toward open-source inference as performance, cost, and control converge.
Fit-for-purpose beats frontier-for-everything#
Here’s the key insight: You don’t need GPT-5-level capacity for every task.
Many enterprise use cases, such as like summarization, embedding, or document QA, benefit more from smaller, fine-tuned open-source models optimized for their data and domain.
That’s something proprietary APIs simply can’t offer.
You can’t fine-tune them on confidential data without raising privacy, compliance, or IP concerns.
Open-source LLMs move horizontally across industries. They are adaptable, transparent, and ready to optimize for your goals.
AI teams can:
- Fine-tune models with proprietary data for domain expertise: legal, medical, financial, manufacturing, etc.
- Deploy and control inference environments end-to-end for predictable performance and strict data privacy.
- Customize optimization strategies for cost, speed, and accuracy.
The performance gap between open-source and proprietary AI is almost gone and the control gap has flipped entirely.
So back to the question - are proprietary models more powerful than open-source models?
With open-source inference, you decide how powerful your model becomes.
Bento: A fast path to self-hosting LLMs in production#
So, is self-hosting LLMs easy?
Not really.
Self-hosting means you’re not just calling an API. You run, scale, and maintain your own inference stack. That involves GPUs, autoscaling, batching, caching, observability, and everything in between.
It’s powerful, but it’s also complex.
That’s exactly why we built Bento Inference Platform: to make production-grade LLM inference as easy as using an API, while giving you full control over infrastructure, cost, and performance.
What you can do with Bento:
- Pick a model. Use any open-source or custom LLM, from DeepSeek and Qwen to your own fine-tuned models.
- Define a Bento service. Build custom inference pipelines with your own business logic, multi-model chaining, or tool integration. Bento works seamlessly with frameworks like vLLM and SGLang.
- Optimize and tune performance. Apply advanced inference techniques such as prefill-decode disaggregation, KV-cache offloading, speculative decoding, and KV-aware routing to push your throughput and efficiency to the next level. Use llm-optimizer to quickly find the best setup for you use case.
- Deploy anywhere. Choose where to run: Bring Your Own Cloud (BYOC), on-prem, multi-cloud and cross-region, or hybrid environments — all fully supported.
- Scale automatically. Bento’s built-in autoscaler handles bursts and quiet periods with fast cold starts and supports scale-to-zero.
- Monitor everything. Get LLM-specific observability out of the box. Track Time-to-First-Token (TTFT), Time-per-Output-Token (TPOT), Inter-Token Latency (ITL), and trace hot paths in real time.
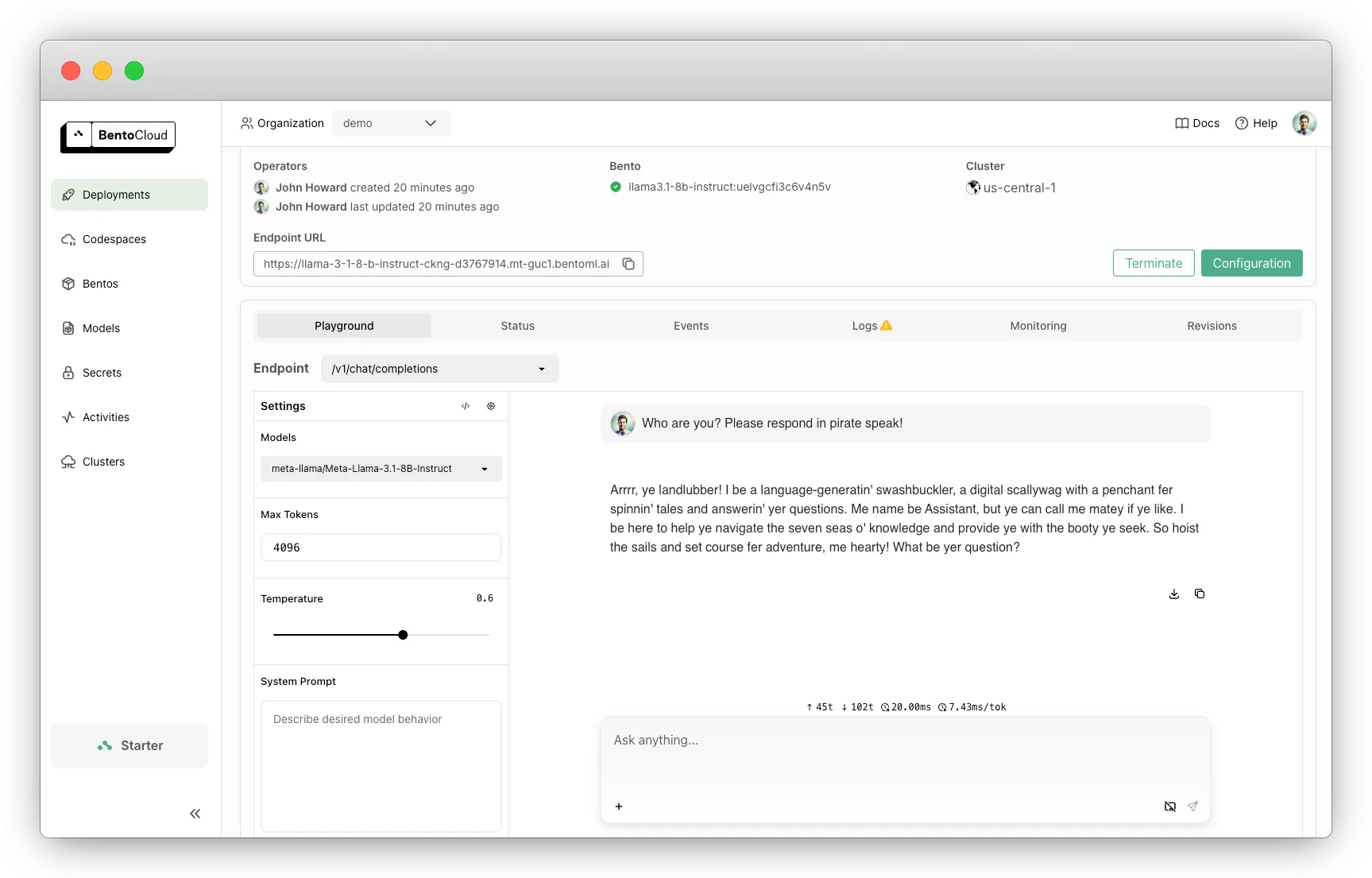 Llama 3.1 8B deployed on Bento Inference Platform
Llama 3.1 8B deployed on Bento Inference PlatformIf you’re ready to move past usage limits and start owning your inference layer, Bento gives you the fastest, most reliable way to get there.
- Read our LLM Inference Handbook. Learn how to design, optimize, and scale production-grade inference systems.
- Schedule a call. Tell us about your use case, and we’ll walk you through the best setup for you.
- Join our Slack community. Connect with AI teams and stay ahead of the latest in self-hosted LLM technology.
- Sign up for Bento Inference Platform. Self-host your first model and experience production-ready inference.
Frequently asked questions#
Do ChatGPT Enterprise plans have no limits?#
OpenAI describes Enterprise usage as “virtually unlimited” for GPT-5 under fair use. This means they can throttle or restrict abusive usage per policy/terms.
Why did my chat silently downgrade to a mini model?#
You likely hit the rolling window cap. The slot reappears exactly 3 hours after each message that consumed it.
Are image generations capped too?#
Yes. OpenAI applies rolling, windowed limits to image generation as well. For example, Plus users can typically generate 50 images every 3 hours. Since these limits change frequently, check the latest docs for each image model:
How do I check my ChatGPT usage?#
There’s no global counter, but you can:
- Watch the model picker or chat input bar for countdown hints like “X messages left / 3 hours.”
- Note downgrade prompts (“Switching to mini” or “limit reached”). That’s your cap.
- Track time between sends. Each slot refreshes three hours after the message that consumed it.
Will ChatGPT usage limits change again?#
Almost certainly. OpenAI regularly tweaks caps as models and demand evolve. Always check Help Center + the model picker UI/chat input bar.
If you’re hitting usage caps regularly, it might be time to explore self-hosted inference. With Bento, you can deploy GPT-level models without limits, downgrades, or wait time.



