.png)

Today, OpenAI rival Anthropic announced Claude 4 models, which are significantly better than Claude 3 in benchmarks, but we're left disappointed with the same 200,000 context window limit.
In a blog post, Anthropic said Claude Opus 4 is the company's most powerful model, and it's also the best model for coding in the industry.
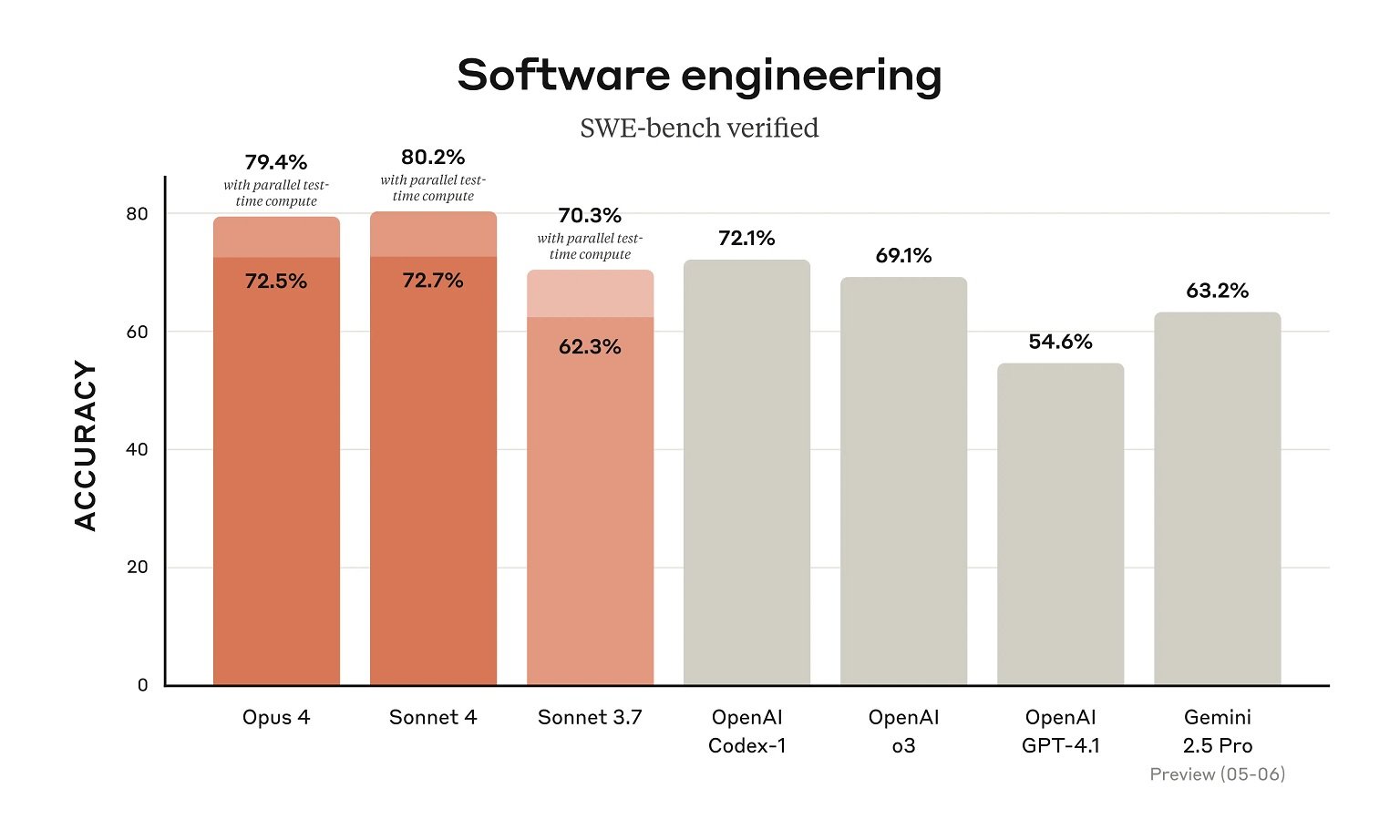
For example, in SWE-bench (SWE is short for Software Engineering Benchmark), Claude Opus 4 scored 72.5 percent and 43.2 on Terminal-bench.
"It delivers sustained performance on long-running tasks that require focused effort and thousands of steps, with the ability to work continuously for several hours, dramatically outperforming all Sonnet models and significantly expanding what AI agents can accomplish," Anthropic noted.
While benchmarks put Claude 4 Sonnet and Opus ahead of their predecessors and competitors like Gemini 2.5 Pro in coding, we're still concerned about the model's 200,000 context window limit.
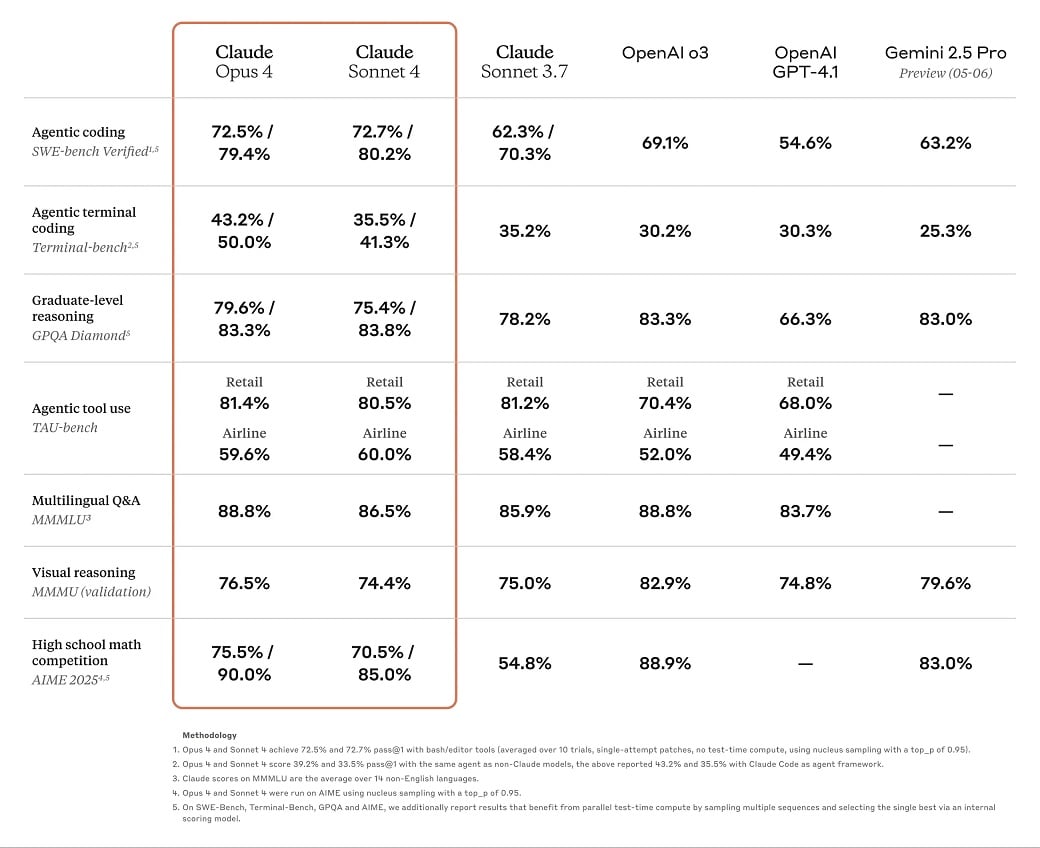
This could be one of the reasons why Claude 4 models excel at coding and complex-solving tasks in these benchmarks, because these models are not being tested against a large context.
For comparison, Google's Gemini 2.5 Pro ships with a 1 million token context window and support for a 2 million context window is also in the works.
ChatGPT's 4.1 models also offer up to a million context window.
| Claude Opus 4 | Most intelligent model for complex tasks | $15 / MTok | $18.75 / MTok | $1.50 / MTok | $75 / MTok | 200K | 50% discount with batch processing |
| Claude Sonnet 4 | Optimal balance of intelligence, cost, and speed | $3 / MTok | $3.75 / MTok | $0.30 / MTok | $15 / MTok | 200K | 50% discount with batch processing |
Claude is still lagging behind the competition when it comes to the context window, which is important in large projects.




