.png)


I started a post here shortly after GPT-5 came out to try to do a comparison between Codex and Claude Code. I did the actual development operations, but didn’t actually finish writing it up at the time. With the recent releases of GPT-5-Codex and Sonnet 4.5, I dusted off the mechanisms I used to do the test and ran them against Codex using GPT-5-Codex-high and Claude Code 2 using Sonnet 4.5. The result is both an interesting comparison between Anthropic and OpenAI’s flagship coding models, but also a look at the advancement in coding model performance within a given company’s fleet over a (very) short period of time.
Some background: I have experience using a reasonable number of the tools and models around AI. I started with trying to coax short functions out of GPT-3, signed up for Github Copilot when it first became available, tried Cursor and Aider, and finally landed on Claude Code when it was released earlier in 2025.
For those reading who aren’t programmers or who haven’t used these tools, there are several different ways that you can build tools that apply AI models to software source code:
You can use the models’ chat interfaces directly. Copy a function, a file, or a set of files into the chat window, ask a question about it, and get an answer. This was the earliest way to apply AI to software engineering and it’s still commonly used.
You can integrate a model into an IDE and perform “smart autocomplete”. This was the original way Github Copilot was set up — it would take a chunk of the code around your cursor, submit it to the model, and propose something it thought might reflect what you wanted to type next. This approach generates completions that are sometimes wildly off, but are often disturbingly accurate at “reading your mind” and giving you multiple lines of code that are almost exactly what you wanted.
Moving beyond the inline autocomplete, you can integrate chat functions more tightly into the IDE, like how VS Code, Cursor, and basically every other development environment are doing. These types of integrations generally give you the ability to reference or highlight sections of your code, potentially referencing other content or using RAG to pull in relevant context, and use a chat interface to request targeted edits and generations in the file.
You can also eschew the IDE altogether and provide a terminal-based interface. This is the approach Anthropic’s Claude Code takes. In this approach, you direct the AI tool by typing prompts into a text-based interface run from your terminal. That interface can execute shell commands and use other tools to perform read and write operations on your codebase. It can search your directory structure, scan within files using grep, modify code, etc. In addition, if you allow it, you can have it build your project, run tests, and take even more sophisticated actions either directly or using plugins.
It was immediately obvious to after just a few hours of use that the Claude Code approach was a paradigm-shifting improvement over the state of the art that existed back then. The Sonnet 3.5, 3.6 and 3.7 models that were Anthropic’s best at the time were very good for coding, but the Claude Code agentic harness that gave it the ability to search, understand, and interact with the code directly opened up a much wider range of capabilites.
However, it wasn’t until the release of the Claude 4 models in May 2025 that Claude Code became a real game changer at my employer. I’d been piloting it myself prior to that point, but once Claude Sonnet 4 and Claude Opus 4 were available the reliability and effectiveness of the tool took another major jump forward, and we started being able to apply it effectively to more tasks.
Claude Code was successful enough in the marketplace that other major labs quickly launched very similar CLI tools. OpenAI launched Codex CLI, backed by o3 and o4-mini. Google launched Gemini CLI powered by their various Gemini models, and xAI now has Grok CLI. There are numerous others.
Until very recently, none of these tools even came close to Claude Code, though. The Claude Code user experience combined with the Opus 4.1 and Sonnet 4 models provided by far the best overall experience. Anthropic has been diligent about improving the agent harness, and other vendors’ offerings just clearly fell short.
As of early September 2025, though, there was some increased buzz around Codex CLI and the GPT-5 family of models. OpenAI iterated pretty rapidly on features for Codex, and with GPT-5 available as the model powering it, it started to gain market- and mindshare. Having bounced off Codex in the early days, I figured it was time to compare the current state of Codex to the current state of Claude Code and see if it was maybe worth changing horses.
Codex with GPT-5 has one notable advantage right out of the box: price. GPT-5 is considerably cheaper than even Claude Sonnet 4 (let alone Opus 4.1). As I write, GPT-5 costs $1.25 per million tokens of input, and $10/Mtok for output. Sonnet 4 is $3/Mtok input and $15/Mtok output, as long as your context is small. For larger context or Opus 4.1, the price is considerably higher. The newest models, GPT-5-Codex and Claude Sonnet 4.5, have the same price as their predecessor models.
Context is confusing. Theoretically the Claude models have a 1 million token context window, but Claude Code only uses 200k. GPT-5 and GPT-5-Codex theoretically have a 400k window, but doesn’t report what it actually uses.
The real test, though, is how they perform, and for that you need to actually try them out on real programs.
Luckily, I had a pretty good real-world application ready to roll. I had built a Claude Artifact to display potential project timelines in a dynamic way, with transition animations and a way to switch between different timelines so you could compare different scenarios. It was a basic React webpage that could read and write a JSON file. It worked well, but it’s hard to directly make use of a Claude artifact, so I wanted to redo it as an actual Node-based React app. That was the inspiration for this test.
This is a qualitative evaluation, not a quantitative benchmark analysis.
It is, however, a valid apples-to-apples comparison. I used the same specification for all the runs, and a defined set of prompt templates to drive the agents.
The test prompts and development process used here are not optimal and I don’t recommend them as a standard practice in real development. I chose them because I figured they would suffice to get to the finish line and work similarly across both CLI applications.
I am not speculating on how any additional tools might or might not compare to the ones under test. CLI coding agents are sprouting up like mushrooms. I have direct experience only with Anthropic’s Claude Code and OpenAI’s Codex. If someone wants to do this experiment with other combinations of tools and models, I’d love to see the results! You can use the links below to find the materials I used and the resulting apps.
This test is for one specific design using one specific tech stack. It’s a small, vibe-coded React/TypeScript web app with no backend, starting from a specification. Your mileage will certainly vary given other tasks, languages, etc.
I first wrote a SPEC.md file that attempted to capture all the features and functionality of the artifact such that I could then feed it into a coding model and have it regenerate it as a full-fledged application. The SPEC.md file contained directions to the model for completing a detailed design given architectural guidance, a rough data model description including constraints, UI/UX desires, and details on required functionality.
The agent scaffolding for the test consisted of three prompt templates. I kept things simple to avoid leaning into any harness-specific features so it would appropriately test the base operation of the model and application:
The design template:
“Ultrathink and follow the instructions in @SPEC.md” — prior to Claude Code 2, you had to use inline commands to drive thinking. Codex does not require this; you configure thinking externally to the prompt.
The implementation template:
“Think and implement the <position> step in @APP-PLAN.md, respecting the instructions in @SPEC.md.”
I’ve found that models tend to do better when you ask them to work one step at a time, even if you’re not actively evaluating the work product after each step. The restricted scope seems to produce a more reliable and detailed implementation as opposed to pointing them at a single giant plan and saying “go”. The only difference in the prompts here was that the first time through I used “first” as the position and every successive time I used “next”, trusting the application’s task tracking to keep track of its place.
The debugging template:
“The application is not working — <description>. Here is log / diagnostic information: <info>. Fix the application respecting the directions in @APP-PLAN.md and @SPEC.md. Think.”
This template obviously had the most variance during the course of the test. When using this prompt template, I tried to stick to objective descriptions of the problems plus the content of any available logs for the first few runs. If the model seemed stuck, I would then provide additional speculation on the cause, or a screenshot of the issue if it was display-related, in the hopes that this would get the model unstuck. Only in one case did I simply have to give up and move on (details on this below).
Run 1: Claude Code 1 with Opus 4.1 / Sonnet 4
For this test, I used Opus 4.1 for the initial design prompt, then switched to Sonnet 4 for the implementation and debugging, per best practice guidance from Anthropic at the time.
The application generated from the repeated application of the implementation prompt template did work, but a number of items were wrong:
The button and dropdown text didn’t show up — there was something wrong with how it was being rendered. This took two rounds of the debugging prompt to successfully find that there was a CSS conflict and make the appropriate change.
The tasks didn’t render in the swimlane. This was fixed with a single debugging request — tasks were added to a global array but needed to be added to each timeline individually (this was not called out in the spec).
The application would not allow us to add a task with the same name on a different timeline, or for a different team on the same timeline (a deliberate error in the spec to test how it handled changing fundamental data constraints after implementation). It corrected the issue in a single debugging request, although many of the tests it had written broke — it did not properly update those tests to reflect the changed constraints.
The animations when altering task data didn’t work, likely because they were being seen as different items. This took a long time to get right — six iterations of the debugging prompt, with partial progress and regressions until it finally discovered a correct way to approach it.
Importing data from a data file did not work. The issue here was enforcing the task name constraint across timelines, despite us having addressed that earlier when manually adding a task. A single debugging prompt addressed this.
The final application looked like this:
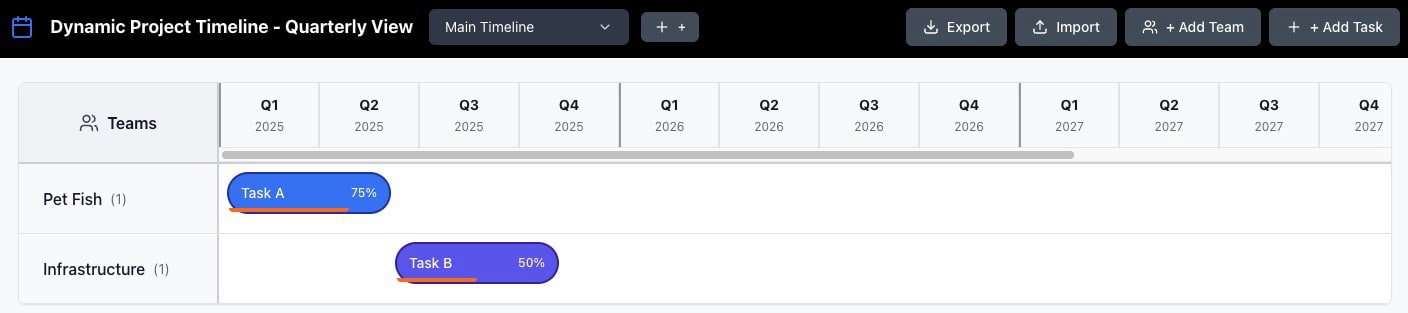
The progress bars on the bottom were a touch off; I didn’t ask the model to adjust those although I suspect it could have done so easily.
Run 2: Codex CLI with GPT-5-high
For this test, I used GPT-5 set to high thinking.
The application generated after running through the implementation prompt did not immediately work due to a Vite configuration issue and lack of Zod installation. The first debugging prompt took care of this, however. The working app had multiple issues, similar to the Claude Code one.
Both the import and export buttons had the same icon. The first debugging prompt took care of this.
Similar to item 3 above, we couldn’t add a task with the same name on the timeline but different teams. In this case it did allow us to add a duplicate on a different timeline, so we started out closer to the desired state. The first debugging prompt pushed back, quoting the spec, and asked whether I wanted the change, which I was very pleased with! After I confirmed I wanted the change, it made it and it worked, although the tests hung.
Animations worked for repositioning, but not for task length changes. The first change mostly worked, but led to some weird text scaling jank that looked really bad. The second round of debugging claimed to fix the issue but there was no change. The third approach fixed the scaling weirdness, but led to a bug when making a task smaller. The fourth time was the charm — substantially correct with some strangeness around repositioning the number that I felt was close enough to live with.
The year dividers didn’t match with the quarter display, which led to misleading grouping. A single debugging prompt fixed this.
The scrollbar moved the quarters in the timeline display, but the tasks never moved. Also the scrollbar was at the top rather than at the bottom of the window. Again, a single debugging prompt took care of this.
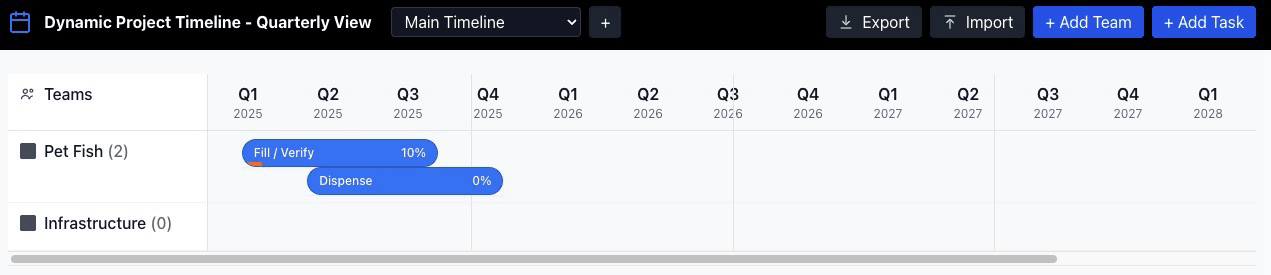
Finally, the tasks were not properly lined up with their corresponding quarters. This one proved to be a stumper for Codex, unfortunately. The first debugging prompt made it way worse in almost every respect, and for thirteen successive attempts it would alternate between improper alignment and broken animations. After it seemed incapable of figuring out how to correct the issue with a text description, I tried giving it a screenshot, which didn’t help. Finally I asked it to use Playwright to look at the rendered window and try to resolve it that way, but that failed as well.
After the last failure I gave up, very close to the finish line. Here’s the UI it generated:
Run 3: Claude Code 2 with Sonnet 4.5
I was impressed with the initial app generated by the implementation prompt. It rendered, but had a few issues:
The Add Timeline and Add Task buttons were not working. A single debug prompt fixed these.
The Add Timeline and Add Task buttons generated modals with edit controls that didn’t show entered text even though it actually existed in the controls. The first debug prompt identified that there was a CSS issue and resolved it.
As with the other two apps, the deliberate spec error meant that task import and creation didn’t work due to a constraint violation. The first debug prompt fixed task creation but import was still broken. The second debug prompt resolved the import issue.
Similarly to problem #6 in Run 2, the tasks weren’t properly lined up with the columns. However, instead of completely running aground, a single debug prompt sufficed to fix the problem.
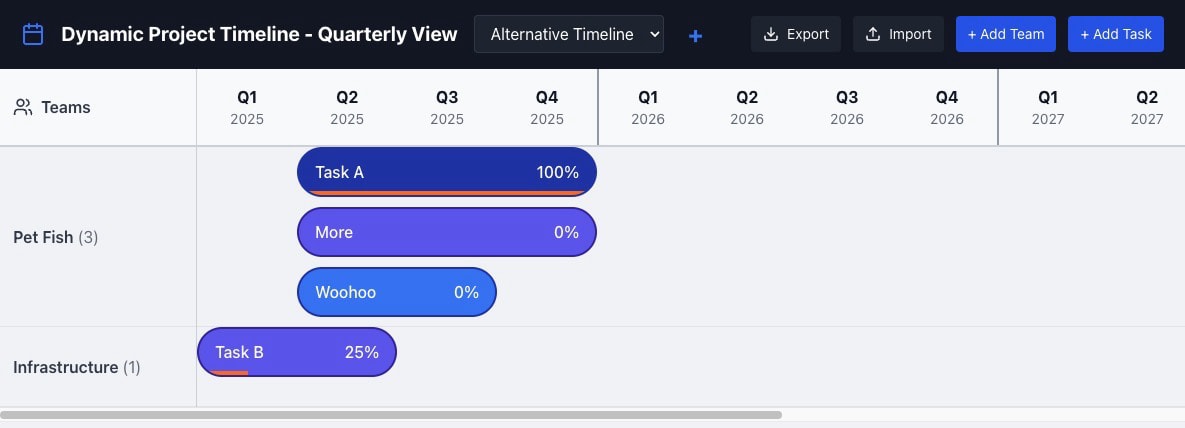
It was notable that the animations were perfect right out of the gate. Both previous runs had significant problems with the animation, so it was pretty impressive to see Claude Code 2 and Sonnet 4.5 one-shot that aspect of the request.
Here’s the UI it generated, which I like quite a bit:
Run 4: Codex CLI with GPT-5-Codex-high
Interestingly, during the initial implementation cycle, it at one point asked to delete a directory that was outside of the root directory where I’d launched Codex (!!!). I wasn’t sure what to make of that and wondered if I’d configured something incorrectly, so I started over. The second time, it created a temporary directory internal to the project directory and eventually asked to remove it, which seemed more benign. Here were the issues:
The generated app did not have the quarters in the timeline visible (they were all stacked on top of each other on the far left of the timeline), but a single debug prompt fixed that.
The timeline didn’t match up with the Teams column (the row height was misaligned between the two). This took some iteration — the first attempt failed with no visible change. The second try made the Teams column grow if there were multiple tasks, but it still wasn’t synced to the task swimlanes. The third approach failed with no apparent difference, and I finally provided a screenshot on the fourth try, which allowed it to figure out what the problem was and resolve it.
Tasks didn’t properly align in the quarter view, either positioning or sizing. The first debug prompt failed with no change, the second succeeded with a bit more explanation of what the I was observing (this was probably technically leading the witness, but it was an edge case and I made a judgment call).
Renaming a task didn’t work due to a task identity constraint issue (due to the intentional spec error). The first debug prompt resolved it.
Import tailed due to the same task identity issue. Again, a single debug prompt sufficed to resolve.
Animations worked for repositioning but not for size changes. The first debug prompt replicated the scaling jank problem from the earlier Codex run and I started having flashbacks. The second debug prompt, however, resolved the issue.
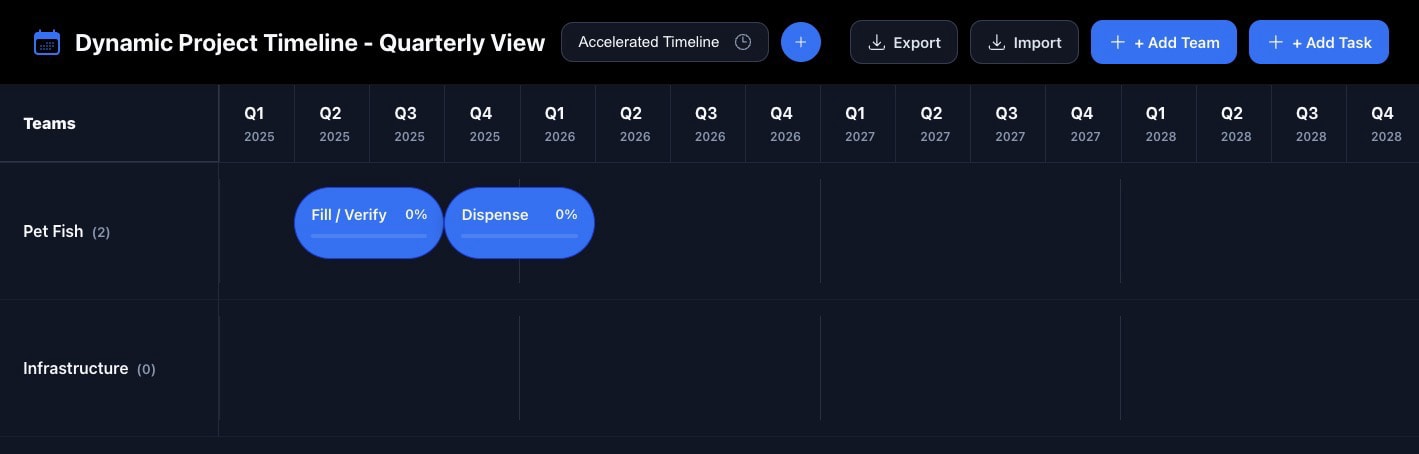
I wasn’t quite as big a fan of the UX generated for this one. The buttons seemed chunky and the progress bar oddly arranged. I didn’t call out the buttons for the extra ‘+’ symbols although the model could have easily fixed those:
I’ve set up a Github repo with all four generated applications plus the initial specification I used to drive all the tests at https://github.com/mlwigdahl/coding-agent-comparison. Please feel free to do your own evaluation of the applications and code and draw your own conclusions based on what you see.
When using Codex, I missed the more verbose thinking traces that Claude Code shows. I ended up with less confidence in Codex’s actions because I couldn’t see the reasoning as it worked.
Codex and the GPT-5 models were quite good at providing post-hoc explanations for what they found, and I liked having them to review. However, they were not always correct, which is a major confidence breaker.
Codex seemed a bit faster than Claude Code in the original test. With Sonnet 4.5 vs GPT-5-Codex, though, that seemed to reverse and Claude Code was significantly faster.
Codex didn’t seem to compact nearly as often as Claude Code, in both the old and new generations. The compaction didn’t seem to hurt Claude Code’s performance in these cases, but I was very surprised at the generous amount of context available when using Codex.
The newer generation models are clearly better than the older ones. Claude Code 2 with Sonnet 4.5 in particular was a standout here.
Both newer models seemed to do a better job with writing better, more salient tests and ensuring they ran properly, which I suspect is a large contributor to their effectiveness. I have not vetted them in detail so it’s possible I’m overlooking problems.
In general I prefer the Claude project planning and task breakdowns. The phases seemed more distinct and actionable.
Both families of model have annoying behavioral quirks. Sonnet 4 almost always says some variant of “Perfect! I see the problem now!” (Sonnet 4.5 seems somewhat better about this, but still does it). GPT-5 almost always offers to do something else for you, and that something else is almost never something I want. (This also seems to be decreased with the dedicated Codex variant model).
The OpenAI models seemed to have slightly more problems comprehending what I was telling it about issues.
Both Sonnet 4.5 and GPT-5-Codex are excellent coding models, and what these tools can do is frankly amazing. Personally, however, I found Claude Code 2 with Sonnet 4.5 to be considerably out in front of the rest of the pack on this task. Not only did it get closest to a fully correct implementation on the first try, it very easily corrected the issues it did have with minimal direction. The resulting UX of its application was, in my limited engineer’s opinion, the best of the four, and the fact that it got the complex requested animation correct on the first try (something none of the other configurations accomplished) was extremely impressive.



