.png)

Main
Large language models (LLMs) have demonstrated exceptional capabilities in language skills and encapsulate a substantial amount of world knowledge1,2,3,4,5. Recent research has also enhanced LLMs with external tools, improving their problem-solving abilities and efficiencies6,7,8. Moreover, LLMs have also demonstrated potential as tool makers9 and black-box optimizers10. To this end, researchers have explored LLM-based specialized models for various scientific domains11,12, particularly for mathematics and chemistry tasks. ChemCrow13 uses tool-augmented LLM for solving a range of chemistry-related tasks such as paracetamol synthesis, whereas Co-scientist14 integrates automated experimentation, achieving successful optimization of palladium-catalysed cross-coupling reaction. LLMs have also shown initial promise in generating biological protocols, as demonstrated by studies like BioPlanner15. While recent advancements, such as OpenAI’s o1 preview, have improved reasoning abilities in areas such as mathematics and coding, progress in biological tasks remains comparatively limited. This limitation stems from general-purpose LLMs’ lack of in-depth understanding of biology, compounded by the unique challenges of biological experiments, including the variability of living systems, the noisy nature of biological data and the highly specialized, less transferable nature of biological skills and tools.
Gene editing has transformed biological research and medicine, allowing for precise DNA modifications for both therapeutic and experimental applications. CRISPR-Cas, the most well-known gene-editing technology, originated from bacterial immune systems16,17,18,19,20,21,22,23,24. Its development has led to advanced techniques like CRISPR activation and interference (CRISPRa/i)25,26,27,28,29, base editing30,31 and prime editing32,33, creating a powerful toolkit for genetic modification and epigenetic modulation. In basic biomedical research, CRISPR gene-editing has become one of the most frequently used laboratory techniques: at the largest non-profit plasmid DNA repository, Addgene, 8 of the 15 top requested plasmids worldwide were for CRISPR gene-editing34. On the application side, CRISPR has produced the first permanent cure for sickle cell disease (SCD)35 and β-thalassaemia36, as well as facilitating plant engineering for sustainable agriculture20. As one of the most powerful biotechnologies, numerous software and protocols exist for specific gene-editing tasks. Despite these resources, an end-to-end solution—from CRISPR-Cas system selection, guide (g)RNA design, off-target evaluation, to delivery and data analysis—remains complex, particularly for newcomers. AI-assisted tools can simplify gene-editing experiment design and data analysis, making the technology more accessible and accelerating scientific and therapeutic discoveries.
We introduce CRISPR-GPT, a solution that combines the strengths of LLMs with domain-specific knowledge, chain-of-thought reasoning, instruction fine-tuning, retrieval techniques and tools. CRISPR-GPT is centred around LLM-powered planning and execution agents (Fig. 1). This system leverages the reasoning abilities of general-purpose LLMs and multi-agent collaboration for task decomposition, constructing state machines and automated decision-making (Fig. 2a). It draws upon expert knowledge from leading practitioners and peer-reviewed published literature in gene editing for retrieval-augmented generation (RAG)13.
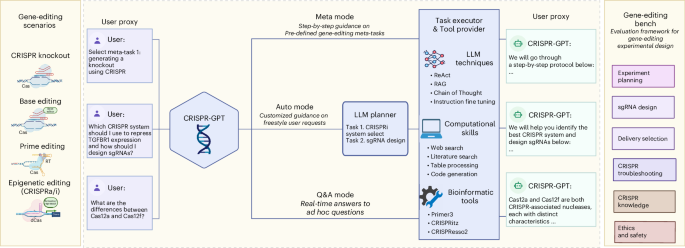
CRISPR-GPT is an LLM-powered multi-agent system designed to provide AI copiloting for human researchers in gene editing. It supports four primary gene-editing modalities: knockout, base editing, prime editing and epigenetic editing (CRISPRa/i). The system offers three user interaction modes: Meta mode (step-by-step guidance on predefined tasks), Auto mode (customized guidance based on user requests) and Q&A mode (real-time answers to ad hoc questions), to streamline experiment design and planning. CRISPR-GPT consists of four core components: the User proxy, LLM planner, Task executor and Tool provider. Together, these components are equipped with a comprehensive suite of tools and decision-support capabilities to facilitate the design, planning and analysis of gene-editing workflows. To evaluate CRISPR-GPT’s performance, we developed the Gene-editing bench, a framework of 288 test cases covering tasks such as experimental planning, sgRNA design, delivery method selection and more. Figure was originally created with BioRender.com/tb8sq6f.
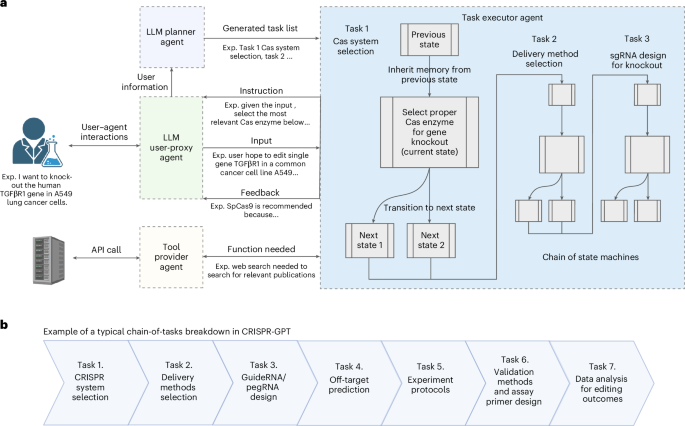
a, The backbone of CRISPR-GPT involves multi-agent collaboration between four core components: (1) The LLM Planner agent is responsible for configuring tasks on the basis of the user’s needs. It automatically performs task decomposition on the basis of the user’s request, the descriptions of the currently supported tasks and internal knowledge. The state machines of the selected tasks are chained together to fulfill the user’s request. (2) The Task executor agent implements the chain of state machines from the Planner agent and is responsible for providing instructions and feedback, receiving input from the User-proxy agent and calling external tools. State machines are central to the Task executor, where each state is responsible for one round of interaction with the user. The instruction is provided to the user first with sufficient information for the current decision-making step and the required inputs. After receiving the response from the user, it provides output and feedback, where Tool providers are potentially called during the execution of the state. Afterwards, the state machine transits to the next state. (3) The LLM User-proxy agent is responsible for interacting with the Task executor on behalf of the user, where the user can monitor the process and provide corrections to the User-proxy agent if the generated content needs modification or improvement. It generates responses to every step of the state machine on behalf of the user. (4) Tool providers support diverse external tools and connect to search engines or databases via API calls. Part of the panel was created with BioRender.com/svkmgjk. b, Breakdown of individual tasks in a typical CRISPR-GPT workflow for gene-editing experiments.
Results
Building AI co-pilot harnessing LLM’s reasoning ability
CRISPR-GPT supports four major gene-editing modalities and 22 gene-editing experiment tasks (Fig. 1 and Supplementary Table 1). It offers tunable levels of automation via three modes: Meta, Auto and Q&A. They are designed to accommodate users ranging from novice PhD-level scientists fresh to gene editing, to domain experts looking for more efficient, automated solutions for selected tasks (Fig. 1). The ‘Meta mode’ is designed for beginner researchers, guiding them through a sequence of essential tasks from selection of CRISPR systems, delivery methods, to designing gRNA, assessing off-target efficiency, generating experiment protocols and data analysis. Throughout this decision-making process, CRISPR-GPT interacts with users at every step, provides instructions and seeks clarifications when needed. The ‘Auto mode’ caters to advanced researchers and does not adhere to a predefined task order. Users submit a freestyle request, and the LLM Planner decomposes this into tasks, manages their interdependence, builds a customized workflow and executes them automatically. It fills in missing information on the basis of the initial inputs and explains its decisions and thought process, allowing users to monitor and adjust the process. The ‘Q&A mode’ supports users with on-demand scientific inquiries about gene editing.
To assess the AI agent’s capabilities to perform gene-editing research, we compiled an evaluation test set, Gene-editing bench, from both public sources and human experts (details in Supplementary Note C). This test set covers a variety of gene-editing tasks (Fig. 1). By using the test set, we performed extensive evaluation of CRISPR-GPT’s capabilities in major gene-editing research tasks, such as experiment planning, delivery selection, single guide (sg)RNA design and experiment troubleshooting. In addition, we invited human experts to perform a thorough user experience evaluation of CRISPR-GPT and collected valuable human feedback.
Further, we implement CRISPR-GPT in real-world wet labs. Using CRISPR-GPT as an AI co-pilot, we demonstrate a fully AI-guided knockout (KO) of four genes: TGFβR1, SNAI1, BAX and BCL2L1, using CRISPR-Cas12a in human lung adenocarcinoma cell line, as well as AI-guided CRISPR-dCas9 epigenetic activation of two genes: NCR3LG1 and CEACAM1, in a human melanoma model. All these wet-lab experiments were carried out by junior researchers not familiar with gene editing. They both succeeded on the first attempt, confirmed by not only editing efficiencies, but also biologically relevant phenotypes and protein-level validation, highlighting the potential of LLM-guided biological research.
CRISPR-GPT is a multi-agent, compositional system involving a team of LLM-based agents, including an LLM Planner agent, a User-proxy agent, Task executor agents and Tool provider agents (Fig. 2a). These components are powered by LLMs to interact with one another as well as the human user. We also refer to the full system as an ‘agent’ to encapsulate the overall functionalities.
To automate biological experiment design and analysis, we view the overall problem as sequential decision-making. This perspective frames the interaction between the user and the automated system as a series of decision-making steps, each essential for progressing towards the ultimate goal. Take the Auto mode for example. A user can initiate the process with a meta-request, for example, “I want to knock out the human TGFβR1 gene in A549 lung cancer cells”. In response, the agent’s LLM Planner will analyse the user’s request, drawing on its extensive internal knowledge base via retrieval techniques. Leveraging the reasoning abilities of the base LLM, the Planner generates a chain-of-thought37,38 reasoning path and chooses an optimal action from a set of plausible ones while following expert-written guidelines. Consequently, the Planner breaks down the user’s request into a sequence of discrete tasks, for example, ‘CRISPR-Cas system selection’ and ‘gRNA design for knockout’, while managing interdependencies among these tasks. Each individual task is solved by an LLM-powered state machine, via the Task executor, entailing a sequence of states to progress towards the specific goal. After the meta-task decomposition, the Task executor will chain the state machines of the corresponding tasks together into a larger state machine and begin the execution process, systematically addressing each task in sequence to ensure that the experiment’s objectives are met efficiently and effectively (Fig. 2a).
The User-proxy agent is responsible for guiding the user throughout the decision-making process via multiple rounds of textual interactions (typical user interactions required by each task detailed in Supplementary Table 2). At each decision point, the internal state machine presents a ‘state variable’ to the User-proxy agent, which includes the current task instructions, and specifies any necessary input from the user to proceed. The User-proxy agent then interprets this state given the user interactions and makes informed decisions as input to the Task executor on behalf of the user. Subsequently, the User-proxy agent receives feedback from the Task executor, including the task results and the reasoning process that led to those outcomes. Concurrently, the User-proxy agent continues to interact with the user and provides them with instructions, continuously integrating their feedback to ensure alignment with the user’s objectives (detailed in Methods; Fig. 2a and Supplementary Fig. 1).
To enhance the LLM with domain knowledge, we enable the CRISPR agent to retrieve and synthesize information from published protocols, peer-reviewed research papers and expert-written guidelines, and to utilize external tools and conduct web searches via Tool provider agents (Fig. 2a).
For an end-to-end gene-editing workflow, CRISPR-GPT typically constructs a chain of tasks that includes selecting the appropriate CRISPR system, recommending delivery methods, designing gRNAs, predicting off-target effects, selecting experimental protocols, planning validation assays and performing data analysis (Fig. 2b). The system’s modular architecture facilitates easy integration of additional functionalities and tools. CRISPR-GPT serves as a prototype LLM-powered AI co-pilot for scientific research, with potential applications extending beyond gene editing.
CRISPR-GPT agents automate gene-editing research tasks
CRISPR-GPT is able to automate gene-editing research via several key functionalities. For each functionality we discuss the agentic implementation and evaluation results.
Experiment planning
The Task planner agent is charged with directing the entire workflow and breaking down the user’s meta-request into a task chain (Fig. 2b). While the Planner selects and follows a predefined workflow in the Meta mode, it is able to take in freestyle user requests and auto-build a customized workflow in the Auto mode. For example, a user may only need part of the pre-designed workflow including CRISPR-Cas system selection, delivery method selection, gRNA design and experimental protocol selection before the experiment. Then the Task planner agent extracts the right information from the user request and assembles a customized workflow to suit user needs (Fig. 3a). To evaluate CRISPR-GPT’s ability to correctly layout gene-editing tasks and manage intertask dependence, we compiled a planning test set, as part of the Gene-editing bench, with user requests and golden answers curated by human experts. Using this test set, we evaluated CRISPR-GPT in comparison with prompted general LLMs, showing that CRISPR-GPT outperforms general LLMs in planning gene-editing tasks (Fig. 3b). The CRISPR-GPT agent driven by GPT-4o scored over 0.99 in accuracy, precision, recall and F1 score, and had <0.05 normalized Levenshtein distance between agent-generated plans and golden answers (Fig. 3b). For extensive description of the test set and evaluation, please see Supplementary Note C1.
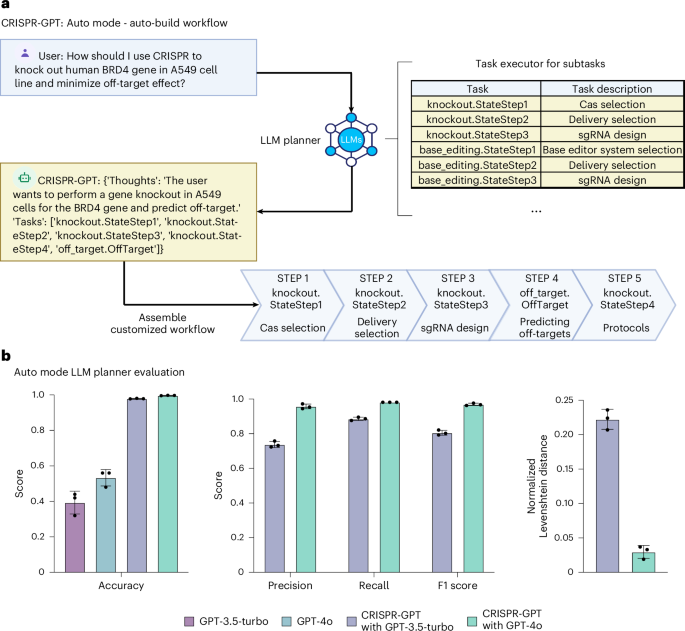
a, The LLM Planner agent automatically breaks down the user’s meta-request to a sequence of tasks. Then it assembles a customized workflow of the chained tasks to meet the user’s needs. Part of the panel was created with BioRender.com/qy4v. b, Evaluation of the LLM Planner using a gene-editing planning test set. For each test case, we generate three independent answers from each model and report the average scores (Supplementary Note C). Data shown are the mean ± s.d. (n = 3 per group).
Delivery method selection
We present and evaluate the delivery agent of CRISPR-GPT (Fig. 4a,b). Delivery is a critical step for all gene-editing experiments. CRISPR-GPT equips LLM with expert-tailored instructions and external tools to choose delivery methods. Specifically, the agent first tries to understand the biological system that the user is planning to edit. It extracts keywords for the target cell/tissues/organisms, performs Google search and summarizes the results. Then, given its own knowledge and search results, CRISPR-GPT matches the user case with a major biological category (cell lines, primary cells, in vivo and so on) which reduces the possible options to a focused set of candidate methods. Next, CRISPR-GPT performs literature search with user and method-specific keywords, and ranks the candidate methods on the basis of citation metrics to suggest a primary and a secondary delivery method (Fig. 4a). To evaluate the performance of this module, we compiled test cases including 50 biological systems as part of the Gene-editing bench. For each case, we invited three human experts to score potential delivery options and utilized those as ground truth. We then evaluated the output of CRISPR-GPT and baseline models by comparing to the pre-compiled ground-truth score sheet. We found that CRISPR-GPT outperforms the baseline GPT-4 and GPT-3-turbo models (Fig. 4b). The agent has a substantial edge on difficult tasks such as those involving hard-to-transfect cell lines and primary cell types. We also noticed that including an additional literature search step improves the agent’s performance only moderately. More details about the delivery selection evaluation can be found in Supplementary Note C2.
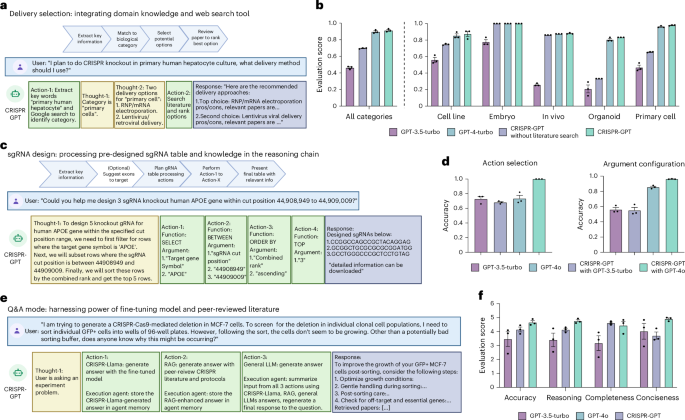
a, Design of delivery method selection agent in CRISPR-GPT, showing the workflow, example request and a series of agent thoughts–actions to identify most suitable delivery methods for the user’s needs. b, Evaluation results of delivery method selection using CRISPR-GPT and baseline models. Data shown are the mean ± s.d. (n = 3 per group). c, Design of gRNA design agent in CRISPR-GPT, showing the workflow, example request and a series of agent thoughts–actions to select top-ranked gRNA customized to user’s request. d, Evaluation results of gRNA design using CRISPR-GPT and baseline models. Models were prompted to generate functions and associated parameters to design gRNAs requested by the user. Data shown are the mean ± s.d. (n = 3 per group). e, Design of Q&A mode in CRISPR-GPT, showing the workflow, example request and a series of agent thoughts–actions to answer gene-editing questions. f, Evaluation of CRISPR-GPT and baseline models for answering gene-editing research questions. Models were prompted to generate answers, which were anonymized, evaluated by three human experts in a fully blind setup. Scores range from 1 (lowest) to 5 (highest). All scores above were from three independent trials (details on evaluation in Supplementary Note C). Data shown are the mean ± s.d. (n = 3 per group).
gRNA design
Good gRNA design is crucial for the success of CRISPR experiments. Various gRNA design tools and software, such as CRISPick39,40,41,42 and ChopChop43, are available. However, we believe there are two key challenges in general usage: (1) choosing a trustworthy source and (2) difficulty in quickly identifying gRNAs that suit specific user requirements or experiment contexts, often requiring lengthy sorting, ranking or literature review. To address these issues, we utilized pre-designed gRNA tables from CRISPick, a reputable and widely used tool. We leverage the reasoning capabilities of LLMs to accurately identify regions of interest and quickly extract relevant gRNAs. This approach is similar to the recently proposed ‘chain-of-tables’ methodology44 (Fig. 4c, Extended Data Fig. 1a, and Supplementary Demo Videos 1 and 2). To evaluate the ability of CRISPR-GPT to correctly retrieve gRNAs, we compiled a gRNA design test set with ground truth from human experts (detailed in Supplementary Note C3). CRISPR-GPT agent outperforms the baseline LLMs in accurately selecting gRNA design actions and configuring the arguments (Fig. 4d).
Further, we picked a real-world test case from a cancer biology study, in which many highly ranked gRNA designs did not generate biological phenotypes, even when their editing efficiencies were high45. Instead, the authors of the study had to design gRNAs manually against exons encoding important functional domains within a gene, and exon-selected gRNAs induced expected cancer-killing effects. We tested CRISPR-GPT for designing gRNAs targeting BRD4 gene from this study, and compared results with those generated by CRISPick and CHOPCHOP (Extended Data Fig. 1). CRISPR-GPT was uniquely able to select the key exons, Exon3–4, within BRD4. In contrast, gRNAs designed by CRISPick or CHOPCHOP would be likely ineffective, as 7 out of 8 gRNAs mapped to non-essential exons (Extended Data Fig. 1). Taken together, our results support the benefit and validity of this module.
Other functions and tools
CRISPR-GPT provides specific suggestions on the choice of the CRISPR system, experimental and validation protocol by leveraging LLM’s reasoning ability and retrieving information from an expert-reviewed knowledge base46,47,48,49,50,51. It also offers automated gRNA off-target prediction, primer design for validation experiments, and data analysis. In particular, the agent provides fully automated solutions to run external software, such as Primer3 (ref. 52), CRISPRitz53,54,55,56 and CRISPResso2 (ref. 57) (Supplementary Table 1). We focused on implementing these tools as they are considered gold standard in respective tasks and have been extensively validated in previous work.
Problem solving via fine-tuning LLM on scientific discussion
General-purpose LLMs may possess broad knowledge but often lack the deep understanding of science needed to solve research problems. To enhance the CRISPR-GPT agent’s capacity in answering advanced research questions, we build a Q&A mode that synthesizes information from multiple resources, including published literature, established protocols and discussions between human scientists, utilizing a combination of RAG technique, a fine-tuned specialized model and a general LLM (for which we picked GPT-4o; Methods).
To enhance the Q&A mode’s capacity to ‘think’ like a scientist for problem solving, we sought to train a specialized language model using real scientific discussions among domain experts. The fine-tuned model is used as one of the multiple sources of knowledge for the Q&A mode (Fig. 4e). To this end, we collected 11 years of open-forum discussions from a public Google Discussion Group on CRISPR gene-editing, starting from 2013 (Supplementary Note B). The discussion group involved a diverse cohort of scientists worldwide. This dataset, comprising ~4,000 discussion threads, was curated into an instructional dataset with over 3,000 question-and-answer pairs (Supplementary Note B). Using this dataset, we fine tuned an 8-billion-parameter LLM on the basis of the Llama3-instruct model58,59,60,61,62,63,64,65. The fine-tuned model, which we call CRISPR-Llama3, has improved abilities in gene-editing questions, outperforms the baseline model on basic questions by a moderate 8% and on real-world research questions by ~20% (Supplementary Figs. 2 and 3). We integrate this fine-tuned LLM into the Q&A mode as a ‘brainstorming source’, enabling the agent to generate ideas like a human scientist and provide a second opinion for difficult queries (Fig. 4e).
To assess the performance of the Q&A mode, we used the Gene-editing bench Q&A test set (Supplementary Note C). The test questions encompass basic gene-editing knowledge, experimental troubleshooting, CRISPR application in various biological systems, ethics and safety66,67. We prompted CRISPR-GPT, GPT-3.5-turbo and GPT-4o to generate responses to test questions. Three human experts scored the answers in a fully blinded setting. The test demonstrated that the Q&A mode outperformed baseline LLMs in accuracy, reasoning and conciseness, with improvement of 12%, 15% and 32%, respectively, versus GPT-4o (Fig. 4f). Human evaluators observed that general-purpose LLMs sometimes make factual errors and tend to provide extensive answers not all of which are relevant to the questions. For example, one question was about solving cell growth issues in an experiment where a scientist performed Cas9 editing followed by single-cell sorting using MCF-7 cells. For this question, the Q&A mode provided a concise, accurate summary of potential reasons and actionable solutions. In contrast, GPT-4o responded with a long list of 9 factors/options, but at least 2 of them were not applicable to MCF-7 cells (Extended Data Fig. 2). This and other examples (Extended Data Figs. 3 and 4) showcase the advantage of the CRISPR-GPT Q&A mode. Overall, evaluation results confirmed that the multisource Q&A mode is better at answering advanced research questions about gene editing.
CRISPR-GPT excels in human–AI collaboration
To further evaluate the human user experience of CRISPR-GPT, we assembled a panel of eight gene-editing experts to assess the agents’ performance for end-to-end experiment covering all 22 individual tasks (Supplementary Table 2 and 3 demos). The experts were asked to rate their experiences in four dimensions: accuracy, reasoning and action, completeness and conciseness (see Supplementary Note C for detailed rubrics). CRISPR-GPT demonstrated improved accuracy and strong capabilities in reasoning and action, whereas general LLMs, such as GPT-4o, often included errors and were prone to hallucination (Fig. 5a,b).
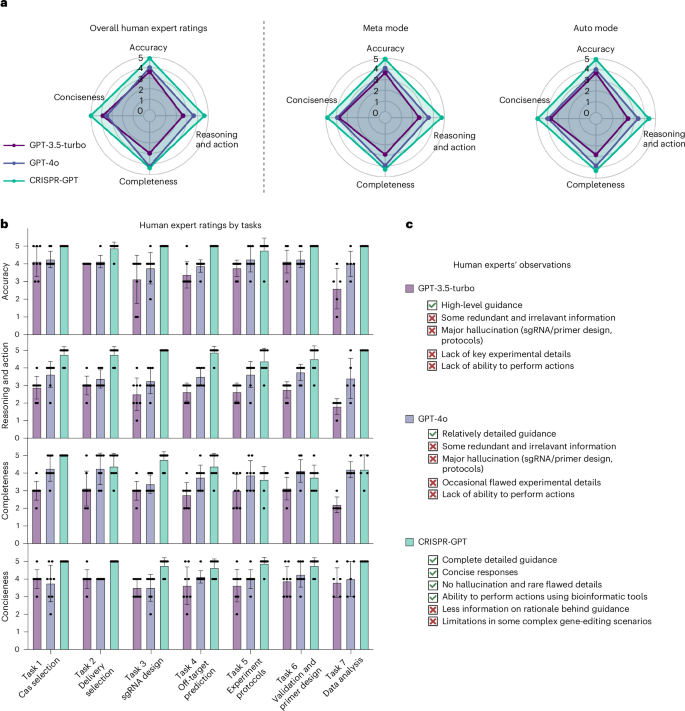
a, Human user experience: evaluation of CRISPR-GPT for end-to-end gene-editing copiloting. Human experts scored performances from 1 (lowest) to 5 (highest). See detailed procedure and rubrics in Supplementary Note C (full chat history and video demo provided in Supplementary Table 2). b, Human user experience: evaluation results breakdown by major gene-editing tasks. Data shown are the mean ± s.d. (n = 8 per group). c, User observations on the strengths and limitations of CRISPR-GPT compared to baseline LLMs.
Highlighted by human evaluators’ observations (Fig. 5c), the CRISPR-GPT agent provides users with more accurate, concise and well-rounded instructions to execute the planned experiments. The ability of CRISPR-GPT to perform specialty gene-editing tasks, such as exon-selected gRNA design, customized off-target prediction and automated sequencing data analysis, reinforced its advantage versus general-purpose LLMs. This is confirmed by the task-specific evaluation results (Fig. 5b). Despite its strengths, CRISPR-GPT struggled with complex requests and rare biological cases, highlighting areas for improvement (limitations in Supplementary Note D).
Real-world demonstration for fully AI-guided gene editing
To showcase and validate CRISPR-GPT’s ability as an AI co-pilot to general biologists, we enlisted two junior researchers unfamiliar with gene editing. They used CRISPR-GPT in two real-world experiments: (1) designing and conducting a multigene knockout and (2) epigenetic editing, from scratch.
In the first experiment, the junior researcher conducted gene knockouts in the human A549 lung adenocarcinoma cell line, targeting four genes involved in tumour survival and metastasis: TGFβR1, SNAI1, BAX and BCL2L1 (Fig. 6). The experiment was designed from scratch with CRISPR-GPT (Fig. 6a). On the basis of the user–AI interaction, enAsCas12a was selected for its multitarget editing capability and low off-target effects. For delivery, CRISPR-GPT recommended lentiviral transduction for stable Cas and gRNA expression. The gRNAs for the four target genes were designed through CRISPR-GPT. Furthermore, CRISPR-GPT provided step-by-step protocols for gRNA cloning, lentivirus production and viral delivery into A549 cells. To validate the editing, the researcher followed CRISPR-GPT’s next-generation sequencing (NGS) protocol, using assay primers designed via the integrated Primer3 tool. After generating the NGS data, the raw sequencing files were uploaded into CRISPR-GPT for automated analysis through the CRISPResso2 pipeline. The analysis reports, sent directly via email, summarized the editing outcomes and showed consistently ~80% high efficiency across all target genes (Fig. 6b, Supplementary Demo Video 3, user interactions summarized in Supplementary Table 4, full chat history listed in Supplementary Table 2). To further assess the biological phenotypes of TGFβR1 and SNAI1 knockout in A549 cells, the researcher conducted an epithelial–mesenchymal transition (EMT) induction experiment by treating A549 cells with TGFβ (Fig. 6c and Methods). The qPCR results revealed that the knockout A549 cell lines (A549 TGFβR1 KO and A549 SNAI1 KO) showed up to 9-fold reduction in CDH1 expression change and up to 34-fold reduction in VIM expression change, which are both key marker genes in the EMT process. This confirms the biological role of TGFβR1 and SNAI1 signalling in driving EMT progression (a crucial driver of metastasis) in lung cancer cells (Fig. 6d).
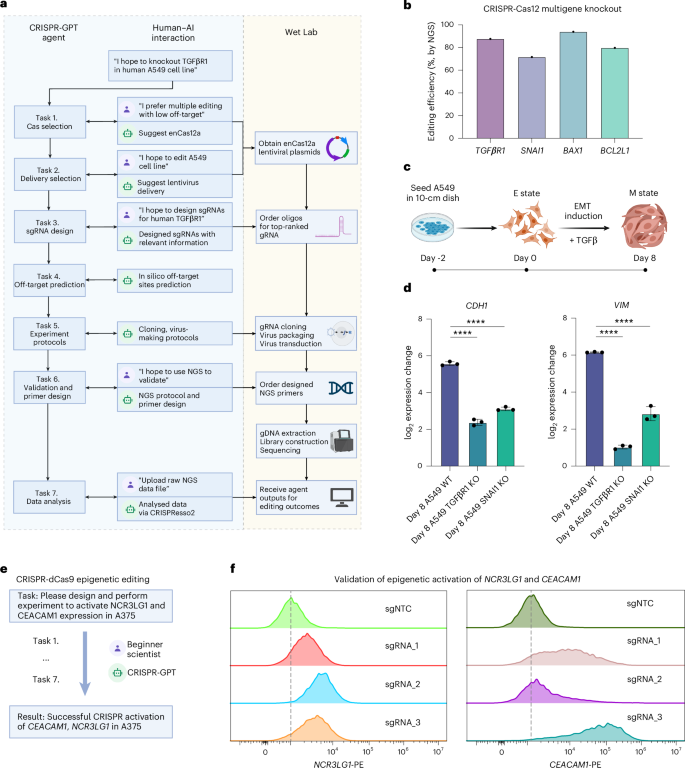
a, The full workflow of CRISPR-GPT-guided knockout experiment of TGFβR1, SNAI1, BAX1 and BCL2L1 through multiple rounds of human–AI interaction (TGFβR1 knockout is shown as an example, see Supplementary Demo Video 3 and full chat history listed in Supplementary Table 2). Panel was originally created with BioRender.com/iim1m2t and processed. b, Editing efficiencies for TGFβR1, SNAI1, BAX1 and BCL2L1 measured via NGS, analysed using CRISPResso2 and CRISPR-GPT. c, Schematic of the EMT induction process via TGFβ treatment (Methods). Panel was originally created with BioRender.com/iim1m2t and processed. d, Functional outcomes of TGFβR1 and SNAI1 knockout in A549 cells after EMT induction by TGFβ. qPCR analysis shows reduced expression changes in EMT marker genes (CDH1, VIM) in A549 TGFβR1 and SNAI1 knockout cells compared with A549 wildtype (WT) cells, confirming successful knockouts of TGFβR1/SNAI1. Data shown are the mean ± s.d. (n = 3 per group). One-way analysis of variance (ANOVA) was used to calculate statistics. ****p < 0.0001. e, Simplified workflow of a beginner researcher activating NCR3LG1 and CEACAM1 expression through multiround interactions with CRISPR-GPT (full chat history listed in Supplementary Table 2). f, Editing outcomes of NCR3LG1 and CEACAM1 activation using CRISPR-GPT-designed sgRNAs, measured via flow cytometry (Methods).
In the second experiment, the junior researcher performed epigenetic editing to activate two genes involved in cancer immunotherapy resistance in a human melanoma model cell line (Fig. 6e, user interactions summarized in Supplementary Table 4, full chat history listed in Supplementary Table 2). CRISPR-GPT guides the researcher through the full workflow: identifying the most suitable CRISPR activation system, selecting an appropriate delivery method for A375 cells, designing dCas9 gRNAs (three gRNAs per gene) and generating protocols for validating editing outcomes. After editing was completed, measurements of target protein expression level confirmed successful activation of both genes, with up to 56.5% efficiency for NCR3LG1, and 90.2% efficiency for CEACAM1, when comparing gRNA-edited groups vs negative control gRNAs (Fig. 6f).
Overall, CRISPR-GPT enabled successful completion of the first set of AI-guided gene-editing experiments. Interactions between the researchers and LLM-powered agents led to efficient, accurate and ethically mindful gene-editing on the first attempt, even by users new to the technique.
Discussion
CRISPR-GPT demonstrates the potential of LLMs to automate and enhance biological research and experiment design and analysis. This AI-guided workflow leverages LLM for reasoning, multi-agent collaboration and scientific discussions for brainstorming, reduces errors, and improves research quality and reproducibility. Despite its current capabilities, CRISPR-GPT has limitations. For example, the agent system relies on high-quality instructions and discussion data from human scientists who have deep knowledge about the biology domain. Such data are hard to collect, creating challenges for further improvements and scaling up. Further, evaluation of such AI tools is generally challenging due to the need to collect substantial feedback from human biologists. For another example, the current gRNA design step mainly supporting human and mouse targets could be further expanded.
Technologies such as CRISPR-Cas9 pose potential ethical and safety risks, including potential misuse for dual purposes, which can be exemplified with AI tools68. Altering human genomes raises substantial ethical concerns, particularly with germline cell and embryo editing. Due to these concerns, such editing is illegal in the United States and many other countries. In addition, gene-editing technology could be abused to create bioweapons, such as genetically engineered viruses69.
To mitigate these risks, we augment CRISPR-GPT with an additional layer of safety mechanism to defend against malicious dual uses. Following the guidelines given in a moratorium70 on heritable genome editing, CRISPR-GPT ensures that users cannot bypass the step of specifying the organism they are editing. If the target is human tissue or organs, the system triggers the following steps: (1) displays a warning note when proceeding with human gene-editing experiments; (2) provides a link to the international moratorium with an explanatory note; and (3) asks users to confirm that they understand the risks and have read the international guidelines before proceeding. The agent also checks if the user request involves editing of human germline cells or dangerous, pathogenic viruses (Supplementary Note D and Data 2). If such a risk is identified, it will trigger an error message and stop proceeding (Extended Data Fig. 5 for examples of the risk mitigation tests).
Other concerns are related to user data privacy issues, especially when human genome sequence information might be exchanged by using AI tools. We follow the data privacy and HIPAA privacy rule in healthcare71. Although genome-scale sequences are fundamentally linked to identities, DNA segments of up to 20-bp length are considered safe and not able to identify human identity72.
CRISPR-GPT includes functionalities to prevent sharing of identifiable private human/patient sequences with public LLM models. Our solution involves two key measures. First, the system would never store any identifiable long genome sequence in the server that would potentially reveal patient private information. Second, a filter is implemented to detect any sequence of 20 or more A/T/G/C/U bases in prompts before sending them to external LLMs. If detected, the agent raises an error with a warning note, asking the user to manually remove the sequence from the input. This prevents the leakage of sensitive information to external models and tools (Extended Data Fig. 5).
Looking ahead, the uses of CRISPR-GPT could be further expanded by connecting to latest advances in genome/protein foundation models, plasmid design tools and other machine learning models, to enable experiment design and analysis tasks beyond gene editing. In addition, the integration of CRISPR-GPT with automated laboratory platforms and robotics holds immense promise. By bridging computational design, analysis and physical execution, researchers could leverage the agent’s expertise to orchestrate end-to-end automated experiments, minimizing manual intervention and accelerating the pace of discovery.
Methods
Large language model-powered autonomous agent
CRISPR-GPT consists of the following 4 core components (Fig. 1): LLM Planner, Tool providers, Task executors, and the LLM User-proxy agent that serve as the interface with users for taking inputs and communicating outputs. Each component can be viewed as an LLM-powered single agent with relatively simple functionality, and the overall system functions via multi-agent interaction. These single agents leverage general-purpose LLMs, such as GPT-4o (used in all four core agents unless otherwise specified, such as when comparing GPT-4 vs GPT-3.5, where we use GPT-4o and GPT-3.5), as their base model to handle a wide range of tasks. The LLMs rely on carefully designed prompts to guide their behaviour and interactions, with example prompts provided in Supplementary Note E.
The Task executor operates as state machines, providing robust decomposition and progress contro
A total of 22 tasks (summarized in Supplementary Table 1) have been implemented, each decomposed into subgoals, with states providing instructions and guiding users through decision-making via multiple rounds of textual interaction. A central management class tracks the current state, task queue, and memory for state outputs and execution history. State transitions occur sequentially, or based on conditional logic from execution results as needed. States process user input and generate structured outputs containing the status, reasoning and response, which are stored continuously to ensure continuity across tasks. This framework supports both predefined workflows (Meta mode) and dynamically generated task sequences (Auto mode), offering flexibility, reliability and robust error handling for executing CRISPR-GPT tasks.
In Meta mode, the Task executor follows predefined workflows that cover complete pipelines for four meta-tasks, each corresponding to a major type of gene-editing experiment. In Auto mode, the LLM Planner dynamically generates a customized sequence of tasks on the basis of the user’s meta-request. The Task executor then constructs and executes the workflow by chaining the state machines of the corresponding tasks into a larger state machine, enabling seamless and automated execution of complex gene-editing pipelines.
The Tool provider connects the Task executor with external application programming interfaces (APIs)
To connect language models with external functionalities73,74,75,76,77, the system needs to (1) analyse the current situation and judge whether it is suitable to call an external tool; and (2) know what kinds of tools are available and choose the best from them. Instead of directly exposing the interfaces of the APIs to LLMs, in CRISPR-GPT, we wrap the usage of APIs inside the states and expose more user-friendly and LLM-friendly textual interfaces through hand-written instructions and responses. In plain words, we are teaching users (human agents and LLM User-proxy agents) to use the tools. The tools include Google web search, Google Scholar search, literature retrieval and bioinformatic tools such as Primer3 (ref. 52), CRISPRitz53 and CRISPResso2 (ref. 57).
The LLM Planner automatically plans gene-editing experiments on the basis of the user’s request
LLMs such as GPT-4, Gemini and Claude serve as the reasoning core of the LLM-powered agent to solve real-world decision-making problems. Our LLM Planner operates on the basis of two key components: (1) the user query and (2) a predefined table containing comprehensive descriptions and interdependency information for all available tasks (example in Supplementary Note E). Using the ReAct prompting technique, the LLM is prompted to output a chain-of-thought reasoning path along with the final action from the plausible action set (Fig. 2a). On the basis of LLM’s internal knowledge, combined with our manually written task descriptions and decomposition instructions, the Planner analyses the user’s request, intelligently decomposes it into an ordered list of tasks, and ensures that the dependencies between tasks are respected (detailed prompt format provided in Supplementary Note E). Once the decomposition is complete, the corresponding state machines are automatically chained together to execute all tasks in the appropriate sequence. For robustness, we prevent the LLM from dynamically adding or deleting tasks (state machines) during execution. However, we acknowledge that enabling dynamic task management is an important step towards developing a more intelligent science AI agent and leave this for future work.
LLM User-proxy agent automatically interacts with the Task executor on the basis of the meta-request
The LLM User-proxy agent automatically interacts with the Task executor on the basis of the meta-request. Central to our system, this agent serves as an intermediary between the user and a state machine derived from an initial task decomposition step—breaking down the gene-editing process into a structured sequence of actions and decisions. At each step, the state machine presents a current state to the LLM agent, which includes a task description and specifies any required input. This input varies by task type and may include general experimental context (for example, “I hope to design 4 sgRNAs targeting human TGFβR1”) or a specific Cas system (for example, enCas12a), as shown in Supplementary Fig. 1b.
The LLM User-proxy agent interprets the current state and makes informed decisions on the user’s behalf. It integrates multiple sources of information, including:
-
1.
Instructions from the state machine,
-
2.
User requests,
-
3.
Session interaction history, and
-
4.
Results from external computational tools.
This synthesized information is formatted into a structured prompt for the agent, which determines the most appropriate next action. For instance, when designing a CRISPR experiment, the agent might combine user input about a target gene with computational results to suggest sgRNA candidates.
While the User-proxy agent operates autonomously, user oversight remains essential. Users are encouraged to monitor task progression and intervene as needed to correct errors or misinterpretations, preserving the integrity of the gene-editing design (Supplementary Fig. 1a).
This approach fosters a collaborative synergy between human expertise and AI. By leveraging the LLM agent’s reasoning ability, we enable a more efficient, accurate and user-friendly design experience. The sequential decision-making framework streamlines execution while ensuring that user input remains central to experiment planning.
Delivery method selection agent
Our approach mirrors the thought process of human gene-editing experts to identify the most appropriate delivery method on the basis of the user’s specific biological system. The workflow is illustrated in Fig. 4a. It begins by instructing the LLM to extract key biological terms from the user’s natural language request. These terms provide insight into the biological context of the experiment. The LLM is then tasked with accessing up-to-date information using a Google Search API to gather additional context about the biological system in the user request.
On the basis of the combined information from the user’s request and external data, the LLM categorizes the system into one of 7 major biological categories:
-
1.
Mammalian in vivo
-
2.
Mammalian embryos
-
3.
Mammalian primary cells or stem cells ex vivo
-
4.
Mammalian cell lines with strong evidence of high-efficiency transfection
-
5.
Mammalian cell lines or organoids without strong evidence of high-efficiency transfection
-
6.
Human in vivo or human embryos
-
7.
Bacteria, viruses and other organisms
These categories encompass the majority of biological systems relevant to CRISPR delivery. For each category, we curated 1–3 delivery methods on the basis of human experts’ knowledge, which represent the most commonly used CRISPR delivery strategies.
To further tailor the recommendations to the user’s specific scenario, the agent system conducts a Google Scholar search to identify relevant peer-reviewed literature. The search is guided by the key terms extracted from the user’s request. From the search results, the top 10 relevant papers are ranked by citation count, providing a quantitative measure for prioritizing the potential delivery options within each biological category.
While citation numbers are not a definitive metric for determining the most appropriate delivery method, they offer a useful reference point. This approach helps to present well-informed recommendations along with relevant literature to the user.
Guide RNA design agent
Designing sgRNAs is a critical challenge in CRISPR editing, as it directly impacts editing efficiency. While many sgRNA design tools (web-based and software packages) exist, they typically follow shared design principles and use metrics, such as on-target/off-target scores, exon number and cut position, to rank candidates. We identified two main user challenges: (1) finding a trustworthy sgRNA design source and (2) efficiently selecting sgRNAs that meet specific criteria without manually evaluating every metric.
To address these issues, we leveraged pre-designed sgRNA tables from CRISPick, a widely used and validated library from the Broad Institute. We combined this with the reasoning and action (ReAct) capabilities of LLMs to process user-driven table queries. Our agent executes a series of actions step by step to generate outputs, akin to the recently described ‘chain-of-table’ methodology15.
The agent system can choose from four key functions:
-
SELECT: Retrieves rows where the specified column matches the given value.
-
BETWEEN: Selects rows where the specified column’s values fall within a specified range (inclusive).
-
ORDERBY: Orders the table on the basis of values in a specified column.
-
TOP: Returns the top N rows of the table.
These can be expanded in the future via human or LLM-driven suggestions. The agent extracts relevant parameters from both the user request and table, applies the functions, and returns pre-designed sgRNAs with associated metadata through a visual table and download link.
We also developed an optional exon suggestion module for CRISPR knockout design. Since sgRNAs targeting non-essential regions can be less effective, we hypothesized that LLMs could use their broad knowledge base to suggest functionally important exons. For example, targeting the BD1/BD2 domains has been shown to effectively disrupt BRD4 function44. We prompt the LLM to reason through gene function and recommend candidate exons (Extended Data Fig. 1), which are then incorporated into table queries.
To our knowledge, no existing sgRNA design tools integrate gene functional domains, making this exon suggestion feature a valuable reference. However, we note that its performance may be limited for genes with sparse literature or minimal online information.
Q&A mode
General-purpose LLMs often lack sufficient understanding of advanced biology. As outlined in Supplementary Note A, we identified key failure modes: (1) information hallucination, (2) outdated CRISPR knowledge, (3) absence of peer-reviewed sources and (4) poor alignment with user-specific problem-solving needs. To overcome these challenges, CRISPR-GPT’s Q&A mode employs a multisource system for answering advanced biology questions (Fig. 4e). Upon receiving a query, it synthesizes information from three sources:
-
1.
Fine-tuned CRISPR-LLama: Trained on human discussion threads from a CRISPR-focused Google Group, this model improves problem-solving and troubleshooting beyond the baseline (Supplementary Note B).
-
2.
RAG-based literature retrieval (Tool provider agent): This accesses a curated, expert-selected CRISPR literature database (~50 key papers chosen for impact and recency; Supplementary Fig. 4 and Note F). Using OpenAI Embeddings and FAISS, both database entries and user queries are embedded into semantic vectors. The top k (k = 4) passages are retrieved by cosine similarity, ranked and summarized to guide the model’s response.
-
3.
General-purpose LLM: For example, ChatGPT or LLama, used as an additional source.
Extendibility of CRISPR-GPT
Given that CRISPR-GPT has a modular multi-agent architecture, integrating new tools and functions into the existing system is easy and training free. To add a new tool/function, the procedure is as follows:
-
(1)
Tool wrapping: Develop specific code to encapsulate the tool’s functionality within a state machine, which we call a Tool provider agent. This wrapper presents user-friendly and LLM-friendly textual interfaces through carefully crafted instructions and responses.
-
(2)
Meta mode integration: If we want to add the tool to be used in the Meta mode, we add the entry state of the new state machine to appropriate positions within the relevant predefined workflow.
-
(3)
Auto mode integration: Register the entry state of the new tool’s state machine in the task decomposition table. This ensures that during task decomposition, the Planner agent becomes aware of the new tool and can incorporate it into its decision-making process.
Performance assessment of CRISPR-GPT
Benchmark dataset
We compiled Gene-editing bench, a collection of test questions and answers for evaluating AI tools’ capabilities for CRISPR experimental design, with a total of 288 unique entries covering four topics:
-
1.
Gene-editing planning: we compiled a total of 50 test cases and answers curated by consensus of human gene-editing experts.
-
2.
CRISPR gRNA design: 50 test cases with pre-compiled answers by human experts.
-
3.
Gene-editing delivery method selection: 50 test cases covering a range of biological systems and major experiment types. For each test case, we asked human experts to rank the available delivery method and report the consensus ranking as answer.
-
4.
Gene-editing Q&A: 138 questions and answers, filtered for errors or issues, compiled from both public sources and human experts.
Validation of individual gene-editing agents
Using this benchmark dataset, we evaluated key functions of the CRISPR-GPT agent system:
-
1.
Planning evaluation: For each query, we generated three batches of subtask lists using CRISPR-GPT and compared them to ground truth using accuracy, precision, recall and F1 scores. Task ordering was assessed via normalized Levenshtein distance. We also tested GPT-4o and GPT-3.5-turbo for comparison, evaluating the models’ ability to plan and sequence gene-editing tasks.
-
2.
Delivery method selection: For each test case, CRISPR-GPT (with and without literature search), GPT-3.5-turbo and GPT-4-turbo proposed primary and secondary delivery methods. Responses were scored against ground truth (primary: weight 2; secondary: weight 1), summed across categories to assess each model’s ability to suggest delivery methods across biological systems.
-
3.
Guide RNA design evaluation: CRISPR-GPT generated gRNA design function lists and parameters, which were compared to ground truth to evaluate function selection, order and parameter accuracy. We also tested GPT-4 and GPT-3.5-turbo, assessing their ability to interpret user intent and produce effective design strategies.
-
4.
Q&A mode evaluation: We selected 40 questions and prompted CRISPR-GPT, GPT-3.5-turbo and GPT-4 to generate answers. Three human experts scored responses across four aspects in a blinded setup, and average scores were used to determine final performance, evaluating the models’ ability to handle diverse gene-editing questions.
Detailed evaluation procedures for all the above are provided in Supplementary Note C.
Human experience evaluation
To holistically evaluate user experiences of the CRISPR-GPT, we invited 8 independent CRISPR human experts to test the agent system via its web surface. Each expert was asked to make one gene-editing request under the Meta mode and two gene-editing requests under the Auto mode. More details on the evaluation procedures are given in Supplementary Note C. In addition, we also provide a total of 20 full chat history demos from these tests in Supplementary Data 1 (details listed in Supplementary Table 2).
Real-world applicability of CRISPR-GPT via wet lab demonstrations
To evaluate the real-world applicability of CRISPR-GPT, we conducted two independent wet lab demonstrations:
-
1.
Beginner Researcher 1: We invited an independent junior PhD scientist unfamiliar with the CRISPR field to perform CRISPR gene-editing experiments using CRISPR-GPT via human–agent collaboration. The researcher applied CRISPR-GPT to execute a gene knockout experiment as part of a cancer research project. The agent provided step-by-step guidance throughout the process (video demonstrations are available in Supplementary Demo Videos 1–3, full chat history in Supplementary Data 1, and details in Supplementary Table 2). The results were validated through next-generation sequencing and functional assays.
-
2.
Beginner Researcher 2: An undergraduate student, also unfamiliar with the CRISPR field, was invited to perform gene-editing experiments through collaboration with CRISPR-GPT. The student implemented CRISPR activation in a cancer immunology research project, with stepwise guidance provided by the agent (full chat history provided in Supplementary Data 1, details in Supplementary Table 2). The results were validated through antibody staining and FACS sorting.
Cell line and cell culture
A375 and A549 cells were cultured in DMEM medium (high glucose, GlutaMAX; 10-569-044 Gibco) with 10% fetal bovine serum (FBS; 100-106, Gemini Bio), 100 U ml−1 penicillin and 100 μg ml−1 streptomycin (15140-122 Gibco). Cells were maintained at 37 °C in a humidified atmosphere with 5% CO2.
CRISPR RNA cloning
Cloning of sgRNAs was carried out using BbsI or Esp3I (R3539, R0734 NEB) through a Golden Gate assembly into a lentiviral backbone. The constructs were sequence-verified via Sanger sequencing using a U6 sequencing primer (5’-GACTATCATATGCTTACCGT-3’).
Lentivirus packaging and transduction
Lentivirus production was performed by co-transfecting the assembled lentiviral vector with VSV-G envelope and Delta-Vpr packaging plasmids into HEK-293T cells using PEI transfection reagent (765090, Sigma-Aldrich). Supernatants were collected at 48 h post transfection. A375 and A549 cells were transduced at low multiplicity of infection (MOI) with 8 μg ml−1 polybrene using a spin infection method at 1,000 × g for 45 min. After 24 h, cells were selected with 1 μg ml−1 puromycin to establish stable cell lines.
Genomic DNA extraction, PCR and sequencing
Genomic DNA was extracted from selected cells at 7 days post transfection using QuickExtract DNA Extraction Solution (LGCQE09050, Lucigen) following manufacturer instructions. Targeted loci were amplified via PCR using Phusion Flash High-Fidelity PCR Master Mix (F548L, ThermoFisher) with primers containing Illumina sequencing adapters. Paired-end reads (150 bp) were generated using the Illumina MiSeq platform.
PCR primers:
-
TGFβR1: Forward: AGATAGAGGGTACTACGTTGAAAGACT; reverse: AAAAAAGTCTTTCAACGTAGTACCCTCT
-
SNAI1: Forward: AGATCAGTTGAAGGCCTTTCGAGCCTG; reverse: AAAACAGGCTCGAAAGGCCTTCAACTG
-
BAX: Forward: AGATATCCAGGATCGAGCAGGGCGAAT; reverse: AAAAAATTCGCCCTGCTCGATCCTGGAT
-
BCL2L1: Forward: AGATACGCACAGTGCCCCGCCGAAGGA; reverse: AAAATCCTTCGGCGGGGCACTGTGCGT
TGFβ treatment
For optimal EMT induction, cells were seeded at a density of 750,000 cells per 100 mm tissue culture plate and incubated for 24 h. The medium was then replaced with 2% FBS DMEM for an additional 24 h. Cells were subsequently treated with 5 ng ml−1 TGFβ (240-B/CF, R&D) in 2% FBS DMEM for 7 days. To ensure consistent cell density during the treatment, cells were reseeded at the same density every 2 days.
Quantitative PCR
Total RNA was extracted using the Direct-zol RNA Purification kit (R2051, Zymo Research) according to manufacturer instructions. Complementary DNA synthesis and qPCR were performed using the Power SYBR Green RNA-to-CT 1-Step kit (4389986, ThermoFisher) on a BioRad CFX384 system (BioRad). Gene expression was quantified using specific primers for CDH1 (forward: CTG AGG ATG GTG TAA GCG ATG; reverse: GTC TGT CAT GGA AGG TGC TC) and VIM (forward: GTG AAT CCA GAT TAG TTT CCC TCA; reverse: CAA GAC CTG CTC AAT GTT AAG ATG). Expression levels were normalized to appropriate housekeeping genes.
Flow cytometry (FACS) analysis
To assess the expression of NCR3LG1 and CEACAM1, cells were stained with B7-H6 monoclonal antibody (JAM1EW), PE (eBioscience) (1:100 dilution) for NCR3LG1 and anti-CD66a/c/e mouse monoclonal antibody (PE [Phycoerythrin], clone ASL-32, 1:100 dilution) for CEACAM1. Staining was performed following manufacturer guidelines, and data were acquired using a CytoFLEX analyser. Flow cytometry data were analysed using standard software. Detailed gating strategies are shown in Supplementary Fig. 5.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The main data supporting the results in this study are available within the paper and its Supplementary Information. Additional data are deposited in GitHub at https://github.com/cong-lab/crispr-gpt-pub (ref. 78).
Code availability
Because of safety concerns, data, code and prompts will not be fully released to the public until the development of US regulations in the field of artificial intelligence and its scientific applications. While the full code is not freely available, it has been peer reviewed. We will also release a light version in GitHub at https://github.com/cong-lab/crispr-gpt-pub (ref. 78).
References
Chowdhery, A. et al. PaLM: scaling language modeling with pathways. J. Mach. Learn. Res. 24, 240 (2023).
Hoffmann, J. et al. An empirical analysis of compute-optimal large language model training. In Advances in Neural Information Processing Systems (eds Koyejo, S. et al.) Vol. 35, 30016–30030 (Curran Associates, Inc., 2022).
OpenAI et al. GPT-4 technical report. Preprint at https://doi.org/10.48550/arXiv.2303.08774 (2024).
The Claude 3 Model Family: Opus, Sonnet, Haiku (Anthropic, 2024).
Anil, R. et al. PaLM 2 technical report. Preprint at https://doi.org/10.48550/arXiv.2305.10403 (2023).
Yao, S. et al. ReAct: synergizing reasoning and acting in language models. In Proc. 11th International Conference on Learning Representations (OpenReview, 2023).
Liu, R. et al. Mind’s eye: grounded language model reasoning through simulation. In Proc. 11th International Conference on Learning Representations (OpenReview, 2023).
Schick, T. et al. Toolformer: language models can teach themselves to use tools. In Advances in Neural Information Processing Systems (eds Oh, A. et al.) Vol. 36, 68539–68551 (Curran Associates, Inc., 2023).
Cai, T., Wang, X., Ma, T., Chen, X. & Zhou, D. Large language models as tool makers. In Proc. 12th International Conference on Learning Representations (OpenReview, 2024).
Yang, C. et al. Large language models as optimizers. In Proc. 12th International Conference on Learning Representations (OpenReview, 2024).
Li, T. et al. CancerGPT for few shot drug pair synergy prediction using large pretrained language models. npj Digit. Med. 7, 40 (2024).
Wu, S. et al. BloombergGPT: a large language model for finance. Preprint at https://doi.org/10.48550/arXiv.2303.17564 (2023).
M. Bran, A. et al. Augmenting large language models with chemistry tools. Nat. Mach. Intell. 6, 525–535 (2024).
Boiko, D. A., MacKnight, R., Kline, B. & Gomes, G. Autonomous chemical research with large language models. Nature 624, 570–578 (2023).
O’Donoghue, O. et al. BioPlanner: automatic evaluation of LLMs on protocol planning in biology. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (eds Bouamor, H., Pino, J. & Bali, K.) 2676–2694 (Association for Computational Linguistics, 2023).
Jinek, M. et al. A programmable dual-RNA-guided DNA endonuclease in adaptive bacterial immunity. Science 337, 816–821 (2012).
Cong, L. et al. Multiplex genome engineering using CRISPR/Cas systems. Science 339, 819–823 (2013).
Mali, P. et al. RNA-guided human genome engineering via Cas9. Science 339, 823–826 (2013).
Jinek, M. et al. RNA-programmed genome editing in human cells. eLife 2, e00471 (2013).
Doudna, J. A. & Charpentier, E. The new frontier of genome engineering with CRISPR-Cas9. Science 346, 1258096 (2014).
Mali, P., Esvelt, K. M. & Church, G. M. Cas9 as a versatile tool for engineering biology. Nat. Methods 10, 957–963 (2013).
Hsu, P. D., Lander, E. S. & Zhang, F. Development and applications of CRISPR-Cas9 for genome engineering. Cell 157, 1262–1278 (2014).
Sander, J. D. & Joung, J. K. CRISPR-Cas systems for editing, regulating and targeting genomes. Nat. Biotechnol. 32, 347–355 (2014).
Shalem, O., Sanjana, N. E. & Zhang, F. High-throughput functional genomics using CRISPR–Cas9. Nat. Rev. Genet. 16, 299–311 (2015).
Qi, L. S. et al. Repurposing CRISPR as an RNA-guided platform for sequence-specific control of gene expression. Cell 152, 1173–1183 (2013).
Gilbert, L. A. et al. CRISPR-mediated modular RNA-guided regulation of transcription in eukaryotes. Cell 154, 442–451 (2013).
Konermann, S. et al. Optical control of mammalian endogenous transcription and epigenetic states. Nature 500, 472–476 (2013).
Maeder, M. L. et al. CRISPR RNA-guided activation of endogenous human genes. Nat. Methods 10, 977–979 (2013).
Perez-Pinera, P. et al. RNA-guided gene activation by CRISPR-Cas9-based transcription factors. Nat. Methods 10, 973–976 (2013).
Anzalone, A. V. et al. Search-and-replace genome editing without double-strand breaks or donor DNA. Nature 576, 149–157 (2019).
Gaudelli, N. M. et al. Programmable base editing of A•T to G•C in genomic DNA without DNA cleavage. Nature 551, 464–471 (2017).
Anzalone, A. V., Koblan, L. W. & Liu, D. R. Genome editing with CRISPR–Cas nucleases, base editors, transposases and prime editors. Nat. Biotechnol. 38, 824–844 (2020).
Pickar-Oliver, A. & Gersbach, C. A. The next generation of CRISPR–Cas technologies and applications. Nat. Rev. Mol. Cell Biol. 20, 490–507 (2019).
Tsang, J. 15 Years of Addgene: The Top 15 Plasmids. Addgene Blog https://blog.addgene.org/15-years-of-addgene-the-top-15-plasmids (2019).
Office of the Commissioner. FDA approves first gene therapies to treat patients with sickle cell disease. FDA News Release https://www.fda.gov/news-events/press-announcements/fda-approves-first-gene-therapies-treat-patients-sickle-cell-disease (2024).
Office of the Commissioner. FDA roundup: January 16, 2024. FDA News Release https://www.fda.gov/news-events/press-announcements/fda-roundup-january-16-2024 (2024).
Wei, J. et al. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems (eds Koyejo, S. et al.) Vol. 35, 24824–24837 (Curran Associates, Inc., 2022).
Zhou, D. et al. Least-to-most prompting enables complex reasoning in large language models. In Proc. 11th International Conference on Learning Representations (OpenReview, 2023).
Kim, H. K. et al. Deep learning improves prediction of CRISPR–Cpf1 guide RNA activity. Nat. Biotechnol. 36, 239–241 (2018).
DeWeirdt, P. C. et al. Optimization of AsCas12a for combinatorial genetic screens in human cells. Nat. Biotechnol. 39, 94–104 (2021).
Doench, J. G. et al. Optimized sgRNA design to maximize activity and minimize off-target effects of CRISPR-Cas9. Nat. Biotechnol. 34, 184–191 (2016).
Sanson, K. R. et al. Optimized libraries for CRISPR-Cas9 genetic screens with multiple modalities. Nat. Commun. 9, 5416 (2018).
Labun, K. et al. CHOPCHOP v3: expanding the CRISPR web toolbox beyond genome editing. Nucleic Acids Res. 47, W171–W174 (2019).
Wang, Z. et al. Chain-of-table: evolving tables in the reasoning chain for table understanding. In Proc. 12th International Conference on Learning Representations (OpenReview, 2024).
Shi, J. et al. Discovery of cancer drug targets by CRISPR-Cas9 screening of protein domains. Nat. Biotechnol. 33, 661–667 (2015).
Giuliano, C. J., Lin, A., Girish, V. & Sheltzer, J. M. Generating single cell-derived knockout clones in mammalian cells with CRISPR/Cas9. Curr. Protoc. Mol. Biol. 128, e100 (2019).
Du, D. & Qi, L. S. CRISPR technology for genome activation and repression in mammalian cells. Cold Spring Harb. Protoc. 2016, pdb.prot090175 (2016).
Huang, T. P., Newby, G. A. & Liu, D. R. Precision genome editing using cytosine and adenine base editors in mammalian cells. Nat. Protoc. 16, 1089–1128 (2021).
Hanna, R. E. et al. Massively parallel assessment of human variants with base editor screens. Cell 184, 1064–1080.e20 (2021).
Doman, J. L., Sousa, A. A., Randolph, P. B., Chen, P. J. & Liu, D. R. Designing and executing prime editing experiments in mammalian cells. Nat. Protoc. 17, 2431–2468 (2022).
McGee, A. V. et al. Modular vector assembly enables rapid assessment of emerging CRISPR technologies. Cell Genomics 4, 100519 (2024).
Untergasser, A. et al. Primer3—new capabilities and interfaces. Nucleic Acids Res. 40, e115 (2012).
Cancellieri, S., Canver, M. C., Bombieri, N., Giugno, R. & Pinello, L. CRISPRitz: rapid, high-throughput and variant-aware in silico off-target site identification for CRISPR genome editing. Bioinformatics 36, 2001–2008 (2020).
Hwang, G.-H. et al. PE-Designer and PE-Analyzer: web-based design and analysis tools for CRISPR prime editing. Nucleic Acids Res. 49, W499–W504 (2021).
Chow, R. D., Chen, J. S., Shen, J. & Chen, S. A web tool for the design of prime-editing guide RNAs. Nat. Biomed. Eng. 5, 190–194 (2021).
Morris, J. A., Rahman, J. A., Guo, X. & Sanjana, N. E. Automated design of CRISPR prime editors for 56,000 human pathogenic variants. iScience 24, 103380 (2021).
Clement, K. et al. CRISPResso2 provides accurate and rapid genome editing sequence analysis. Nat. Biotechnol. 37, 224–226 (2019).
Introducing Meta Llama 3: the most capable openly available LLM to date. Meta Blog https://ai.meta.com/blog/meta-llama-3/ (2024).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 5998–6008 (2017).
Loshchilov, I. et al. Decoupled Weight Decay Regularization (ICLR, 2019).
Hu, E. et al. LoRA: Low-Rank Adaptation of Large Language Models (ICLR, 2022).
Dettmers, T., Pagnoni, A., Holtzman, A. & Zettlemoyer, L. QLORA: efficient finetuning of quantized LLMs. In Proc. 37th International Conference on Neural Information Processing Systems (eds Oh, A. et al.) 441 (NeurIPS, 2023).
Zhou, C. et al. Lima: Less is more for alignment. In Proc. 37th International Conference on Neural Information Processing Systems (eds Oh, A. et al.) 2400 (NeurIPS, 2023).
Delvin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding. Proc. Conf. NAACL-HLT 2019, 4171–4186 (2019).
Liu, Z., Lin, W., Shi, Y. & Zhao, J. RoBERTa: A Robustly Optimized BERT Pretraining Approach. In Proc. 20th Chinese National Conference on Computational Linguistics (eds Li, S. et al.) 1218–1227 (Chinese Information Processing Society of China, 2021).
Frequently Asked Questions About CRISPR (Innovative Genomics Institute, 2025).
Beumer, J. et al. CRISPR: questions and answers. STAR Protoc. https://star-protocols.cell.com/protocols/2555 (2023).
Doudna, J. A. The promise and challenge of therapeutic genome editing. Nature 578, 229–236 (2020).
Hoffmann, S. A. et al. Safety by design: biosafety and biosecurity in the age of synthetic genomics. iScience 26, 106165 (2023).
Lander, E. S. et al. Adopt a moratorium on heritable genome editing. Nature 567, 165–168 (2019).
Summary of the HIPAA Privacy Rule https://www.hhs.gov/hipaa/for-professionals/privacy/laws-regulations/index.html (US Department of Health and Human Services, 2008).
Naveed, M. et al. Privacy in the genomic era. ACM Comput. Surv. 48, 6 (2015).
OpenAI. ChatGPT plugins. https://openai.com/blog/chatgpt-plugins (2023).
Shen, Y. et al. HuggingGPT: solving AI tasks with ChatGPT and its friends in hugging face. In Advances in Neural Information Processing Systems (eds Oh, A. et al.) Vol. 36, 38154–38180 (Curran Associates, Inc., 2023).
Wang, G. et al. Voyager: an open-ended embodied agent with large language models. Preprint at https://doi.org/10.48550/arXiv.2305.16291 (2023).
Hao, S., Liu, T., Wang, Z. & Hu, Z. ToolkenGPT: augmenting frozen language models with massive tools via tool embeddings. In Advances in Neural Information Processing Systems (eds Oh, A. et al.) Vol. 36, 45870–45894 (Curran Associates, Inc., 2023).
Patil, S. G., Zhang, T., Wang, X. & Gonzalez, J. E. Gorilla: large language model connected with massive APIs. In Advances in Neural Information Processing Systems (eds Globerson, A. et al.) Vol. 37, 126544–126565 (Curran Associates, Inc., 2024).
Qu, Y. et al. CRISPR-GPT: an LLM agent for automated design of gene-editing experiments. GitHub https://github.com/cong-lab/crispr-gpt-pub (2024).
Acknowledgements
This work was supported by the National Institutes of Health (grant nos. 1R35HG011316 and 1R01GM141627 to L.C.), Donald and Delia Baxter Foundation Faculty Scholar award (L.C.), the Weintz family foundation (L.C.), and National Science Foundation grant 1653435 (M.W.). This work used supercomputing resources provided by Nebius Group N.V. and the Stanford Genetics Bioinformatics Service Center, supported by NIH Instrumentation Grant S10 OD023452. We thank the Stanford Institute for Stem Cell Biology and Regenerative Medicine, the Stanford Cancer Institute, and the Stanford Wu-Tsai Neuroscience Institute for technical advice and support.
Ethics declarations
Competing interests
Princeton University and Stanford University have filed patent applications (#19/093,928, Princeton and Stanford, 2025) based on this work, where L.C., M.W., Y.Q. and K.H. are listed as inventors. L.C. is a member of the scientific advisory board of Arbor Biotechnologies. L.C. has equity interest in Auto Bio, Rootpath Genomics, and Acrobat Genomics. D.Z. is an employee of Google DeepMind. The remaining authors declare no competing interests.
Peer review
Peer review information
Nature Biomedical Engineering thanks the anonymous reviewers for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 LLM-powered exon suggestion for guideRNA design in CRISPR-GPT.
a, Workflow of the exon suggestion feature within the guideRNA design module in CRISPR-GPT. b. Demonstration of the thought and action processes for exon suggestion in response to a real-world user request (additional details in Methods) c. Comparison of gRNA designs with exon information from different tools (CRISPR-GPT, CRISPick, CHOPCHOP). Notes on the designs are provided. CRISPick designs used the default combined ranking by on-/off-target scores based on Azimuth 2.0 algorithm and Cutting Frequency Determination (CFD) scores. CHOPCHOP design uses the default on-target efficiency ranking based on Doench et al., 2016. d, Exons and key bromodomains (BD1/BD2) of the BRD4 protein are shown for reference.
Extended Data Fig. 2 Example of CRISPR-GPT QA on gene-editing questions, compared to baseline models (Part 1/3).
The question was from the gene-editing QA test set (Supplementary Note C). Questions and answers are displayed, with expert notes in bottom boxes. Evaluations and comments conducted in a fully blinded setting.
Extended Data Fig. 3 Example of CRISPR-GPT QA on gene-editing questions, compared to baseline models (Part 2/3).
The question was from the gene-editing QA test set (Supplementary Note C). Questions and answers are displayed, with expert notes in bottom boxes. Evaluations and comments conducted in a fully blinded setting.
Extended Data Fig. 4 Example of CRISPR-GPT QA on gene-editing questions, compared to baseline models (Part 3/3).
The question was from the gene-editing QA test set (Supplementary Note C). Questions and answers are displayed, with expert notes in bottom boxes. Evaluations and comments conducted in a fully blinded setting.
Extended Data Fig. 5 Examples of CRISPR-GPT defending against dual usage and ethical, privacy risks.
The agent identifies potential risks related to dual usage risks (top), human heritable gene-editing and private genetic information leakage (bottom), responds with warning messages or errors, and stops proceeding.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article
Cite this article
Qu, Y., Huang, K., Yin, M. et al. CRISPR-GPT for agentic automation of gene-editing experiments. Nat. Biomed. Eng (2025). https://doi.org/10.1038/s41551-025-01463-z
Received: 25 June 2024
Accepted: 17 June 2025
Published: 30 July 2025
DOI: https://doi.org/10.1038/s41551-025-01463-z


