.png)


Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
Sponsor Message

Find your algorithm for success with an online data science degree from Drexel University. Gain essential skills in tool creation and development, data and text mining, trend identification, and data manipulation and summarization by using leading industry technology to apply to your career. Learn more.
.
* Want to sponsor the newsletter? Email us for details --> [email protected]
And now…let's dive into some interesting links from this week.
A little bit of Reverend Bayes all night long
Lou Bega’s iconic hit Mambo No. 5 was released in 1999 to critical and financial acclaim. Even 25 years after its release, the song appears in my regular rotation. From my recent playthrough, I wondered about the names in the song: Angela, Pamela, Sandra, Rita, Monica, Erica, Tina, Mary, and Jessica…I realized that none of my friends have these names. For me, I associate Sandra and Monica with women maybe twenty years my senior. “Man, when did this song come out?” I thought and I realized my big question: can you predict when Lou Bega’s greatest hit, Mambo No. 5, was released by the names of all the women that appear in the song?…
Causal Inference for The Brave and True
A light-hearted yet rigorous approach to learning impact estimation and sensitivity analysis. Everything in Python and with as many memes as I could find. Part I of the book contains core concepts and models for causal inference. You will learn how to represent causal questions with potential outcome notation, learn about causal graphs, what is bias and how to deal with it…Part II (WIP) contains modern development and applications of causal inference to the (mostly tech) industry. While Part I focuses mostly on identifying average treatment effects, Part II takes a shift to personalization and heterogeneous effect estimating with CATE models…Why Pivot Tables Never Die
The REPL for Business Data: Instant Insights Without Code…While everyone’s talking about AI revolutionizing business, there’s a quiet renaissance happening with one of the most influential business tools created: the pivot table…In 2025, we’re witnessing something remarkable - modern data tools are bringing pivot tables back to the forefront. But why would cutting-edge platforms invest in a decades-old spreadsheet feature? The answer lies in what made pivot tables revolutionary in the first place: turning complex data into instant insights without writing a single line of code. This article is about how the simplest tools often solve the hardest problems…
.
.
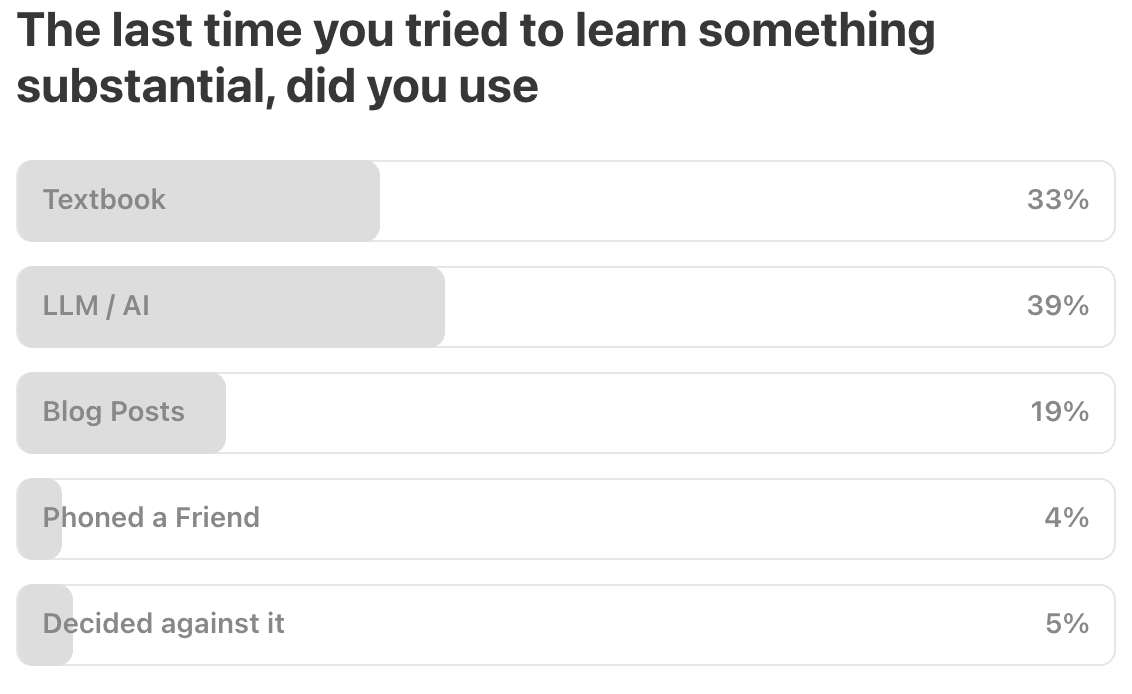
.
Instrumental variable regression
In many circumstances you cannot randomize, either because it is unethical or simply because it’s too expensive. There are however methods which, if appropriately applied, may provide you some convincing causal evidence. Let us consider the case where you cannot randomly assign the treatment T , and in this case it could be affected by any confounder X leading you to a biased estimate of the treatment effect. However, if you have a variable Z that only affects T and does not affect your outcome in any other way other than via T , then you can apply Instrumental Variable Regression…How do you decide when to move from batch jobs to real-time pipelines? [Reddit]
Our team has been running nightly batch ETL for years and it works fine, but product leadership keeps asking if we should move “everything” to real-time. The argument is that fresher data could help dashboards and alerts, but honestly, I’m not sure most of those use cases need second-by-second updates…For those who’ve made the switch, what tipped the scale for you? Was it user demand, system design, or just scaling pain with batch jobs? And if you stayed with batch, how do you justify that choice when “real-time” sounds more exciting to leadership?…
Spatial machine learning with R: caret, tidymodels, and mlr3
In this blog post, we compare three of the most popular machine learning frameworks in R: caret, tidymodels, and mlr3. We use a simple example to demonstrate how to use these frameworks for a spatial machine learning task and how their workflows differ. The goal here is to provide a general sense of how the spatial machine learning workflow looks like, and how different frameworks can be used to achieve the same goal..Aggregation Strategies for Scalable Data Insights: A Technical Perspective
Elasticsearch is a cornerstone of our analytics infrastructure, and mastering its aggregation capabilities is essential for achieving optimal performance and accuracy. This blog explores our experiences comparing three essential Elasticsearch aggregation types: Sampler, Composite, and Terms. We’ll evaluate their strengths, limitations, and ideal use cases to help you make informed decisions…SQL Anti-Patterns You Should Avoid
Today, I will be talking about some of the common and high impact SQL anti-patterns I have seen from experience that can make queries and pipelines difficult to maintain, or have slower than expected performance. These issues can compound, causing erosion in trust in data, and slower query development in general…Don’t Conform Your Data to the Model. Do the Opposite.
I recently saw a LinkedIn post that serves as a nice example of how the null-hypothesis mindset leads people to poor statistical decision-making. The author works at an AB testing-as-a-service company. Here is the post…Introduction to the Concept of Likelihood and Its Applications
This Tutorial explains the statistical concept known as likelihood and discusses how it underlies common frequentist and Bayesian statistical methods. The article is suitable for researchers interested in understanding the basis of their statistical tools…Production RAG: what I learned from processing 5M+ documents
I’ve spent the last 8 months in the RAG trenches, I want to share what actually worked vs. wasted our time. We built RAG for Usul AI (9M pages) and an unnamed legal AI enterprise (4M pages)…If your random seed is 42 I will come to your office and set your computer on fire🔥
When you read some tutorial about machine learning or data analysis and you see random.seed(42) you go “haha, that’s funny” and you move on…Until you talk to your much younger students and you realize they all think this is an important line of code that ensures their programs run correctly. They set random seeds to 42 everywhere. They have read the documentation, they know about the random seed option, and they dutifully follow the best practices as laid out everywhere on the internet. The random seed is 42. I cannot emphasize how bad of a choice this is…
Behind the Research of AI Podcast: Jack Morris
We got a chance to chat with Jack Morris, a final-year PhD student at Cornell Tech, during COLM 2025….Our conversation was a whirlwind: Each of us shared stories from the chaotic yet exciting experience of a PhD, with Jack explaining how his first big paper, “Text Embeddings Reveal (Almost) As Much As Text”, came about. We asked what kind of role Twitter plays for research. And we wondered how we can research to gain a deeper scientific understanding of LLMs…GNU Octave Meets JupyterLite: Compute Anywhere, Anytime!
We are thrilled to announce the newest member of our JupyterLite kernel ecosystem: Xeus-Octave. Xeus-Octave allows you to run GNU Octave code directly on your browser. GNU Octave is a free and open-source Scientific Programming Language that can be used to run Matlab scripts. In this article, we present the challenges encountered when targeting WebAssembly, the current state of the Xeus-Octave kernel, and the future plans for expanding the GNU Octave ecosystem…
Best approach to large joins [Reddit]
Hi I’m looking at table that is fairly large 20 billion rows. Trying to join it against table with about 10 million rows. It is aggregate join that an accumulates pretty much all the rows in the bigger table using all rows in smaller table. End result not that big. Maybe 1000 rows. What is strategy for such joins in database..Using CRPS to Evaluate Recast Models
We care about two things when we’re making forecasts: how “correct” is the forecast (how far away were the actuals from the predicted values) and how good are we at understanding our own uncertainty (we want to penalize a forecast less if it was said to be uncertain upfront)…Probabilistic forecasts are powerful because they allow you to use probability to quantify the uncertainty we have about forecasts. This empowers you to make informed decisions, both in terms of taking action, but also in terms of whether your forecast is actionable at all. But, when you’re no longer getting a prediction that’s a single value, it can be difficult to know whether your forecast was correct. CRPS gives us a basic understanding of both the Correctness and Precision of your predicted forecast…
.
Am I the only one who spends half their life fixing the same damn dataset every month? [Reddit]
LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings
.
* Based on unique clicks.
** Find last week's issue #621 here.
What happens when Chinese companies stop providing open source models? [Reddit]
Causal Data Scientists, what resources helped you the most? [Reddit]
Simpson’s What? A recent paper that invokes Simpson’s paradox turns out to be mistaken
chronicler - Easily add logs to your functions, without interfering with the global environment
.
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,500 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian


