.png)

TLDR; arrowspace now speaks the language of energy fields, leaves behind cosine distance usage.
In this post, I demonstrate how DeepSeek's optical compression approach—treating rendered text as a visual medium—has been replicated in Rust using `burn.dev`, and how this compression primitive unlocks a new search paradigm in arrowspace v0.18.0: energy-informed retrieval that moves decisively beyond cosine similarity.
You can find arrowspace in the:
- Rust repository ↪️ cargo add arrowspace
- Python repository ↪️ pip install arrowspace
Why Optical Compression Matters
Large language models choke on long contexts. Processing thousands of text tokens is computationally expensive and architecturally constraining. DeepSeek-OCR introduced a radical alternative: render text as images and compress those images into compact vision tokens.
The core insight is elegant: text-as-image is a lossy compression medium that preserves semantic structure while dramatically reducing token count. At 10× compression, the system achieves 97% OCR decoding precision—viable for production retrieval and reasoning tasks.
The Compression Pipeline
The optical embeddings pipeline combines two vision encoders with a convolutional compressor:
- SAM-base (80M parameters): Window attention for efficient local feature extraction with 16× spatial compression via stride-2 convolutions
- CLIP-large (300M parameters): Global attention for semantic understanding across the entire visual field
- Projector: MLP that fuses SAM and CLIP representations into a unified embedding space
The result: 1000 text words compress into ~100 vision tokens—a 10× reduction that enables efficient long-context processing.
Rust Implementation with Burn
The Rust implementation replicates the DeepEncoder architecture using burn.dev, a modular deep learning framework with first-class support for multiple backends (WGPU, CUDA, NdArray).
Configuration and Resolution Modes
The system supports five resolution modes optimized for different compression targets:
Resolution configuration directly controls the compression ratio—higher resolutions preserve more detail at the cost of larger token budgets.
SAM Encoder: Window Attention with Compression
The SAM encoder implements hierarchical window attention with 16× convolutional compression:
Window attention partitions the feature map into non-overlapping windows, reducing complexity from (O(N^2)) to (O(Nw^2)) where (w) is window size. Global attention layers at strategic depths (e.g., layers 2, 5, 8, 11) capture long-range dependencies.
CLIP Encoder: Global Semantic Understanding
The CLIP encoder applies pre-LayerNorm transformer blocks with Quick GELU activation for semantic feature extraction:
CLIP’s class token (first position) encodes a global summary of the image, while remaining tokens represent local patch features.
Compression Metrics
The implementation includes information-theoretic metrics to validate compression effectiveness:
- Spatial compression: 1024 patches → 64 tokens = 16× reduction
- Word-to-token ratio: ~1.36 words per vision token on average
- Shannon entropy: Measures information density in text vs. image vs. vision tokens
Testing on rendered text confirms the expected compression properties: 16× spatial reduction with effective semantic preservation.
ArrowSpace v0.18.0: Energy-Informed Search
The optical compression primitives integrate seamlessly with ArrowSpace’s energy-based search, introduced in v0.18.0. This marks a fundamental shift: from cosine similarity to energy-distance metrics that encode spectral graph properties directly into the index.
Energy Distance: Beyond Geometric Similarity
Energy distance combines three complementary signals:
\[d_{\text{energy}}(q, i) = w_\lambda |\lambda_q - \lambda_i| + w_G |G_q - G_i| + w_D \mathcal{D}(\mathbf{q} - \mathbf{i})\]
Where:
- \(\lambda\) is the Rayleigh quotient (smoothness over the graph)
- \(G\) is the Gini dispersion (edge energy concentration)
- \(mathcal{D}\) is the bounded Dirichlet energy (feature-space roughness)
This replaces cosine’s purely geometric ranking with a spectral + topological scoring function that respects the dataset’s intrinsic manifold structure.
The Energy Pipeline
arrowspace v0.18.0 introduces energymaps.rs, a five-stage energy-first construction pipeline:
- Optical Compression (optional for now, built-in with v0.18.1, PR here): Spatial binning with low-activation pooling to compress centroids to a target token budget
- Bootstrap Laplacian \(L_0\): Euclidean kNN graph over centroids (no cosine)
- Diffusion + Splitting: Heat-flow smoothing over \(L_0\), followed by sub-centroid generation by splitting high-dispersion nodes along local gradients
- Energy Laplacian: Final graph where edges are weighted by energy distance \(d_{\text{energy}}\)
- Taumode Lambda Computation: Per-item Rayleigh quotients computed over the energy graph (cosine components “alpha” removed)
Optical Compression in ArrowSpace
The optical compression stage borrows directly from the vision encoder’s 2D spatial binning strategy:
This achieves low-activation pooling: high-norm centroids (noisy outliers) are trimmed before averaging, preserving the low-energy manifold structure.
Diffusion and Sub-Centroid Splitting
Heat-flow diffusion smooths the centroid manifold, while splitting injects new sub-centroids along high-dispersion gradients:
Diffusion smooths noisy features, while splitting increases local resolution in regions with high spectral roughness.
Energy Search: Full Implementation
The search_energy method replaces cosine ranking with energy-distance scoring:
No cosine similarity is computed anywhere in the pipeline—ranking is purely energy-informed. Euclidean distance is used to seed the initial dataset clustering.
Experimental Validation: Diffusion Parameter Sweep
The test harness evaluates energy search across a grid of diffusion parameters (η ∈ {0.05, 0.1, 0.15, 0.2}, steps ∈ {2, 4, 6, 8}) on a partial CVE vulnerability corpus (1681 items, 384-dimensional embeddings).
Test Queries
Three domain-specific queries probe different vulnerability classes:
- “authenticated arbitrary file read path traversal”
- “remote code execution in ERP web component”
- “SQL injection in login endpoint”
Metrics
Standard IR metrics are computed@20:
- MRR (Mean Reciprocal Rank): Quality of top-1 result
- MAP@20 (Mean Average Precision): Ranking quality across all relevant items in top-20
- NDCG@10 (Normalized Discounted Cumulative Gain): Graded relevance with position discount
- Recall@10/20: Fraction of relevant items retrieved
Results
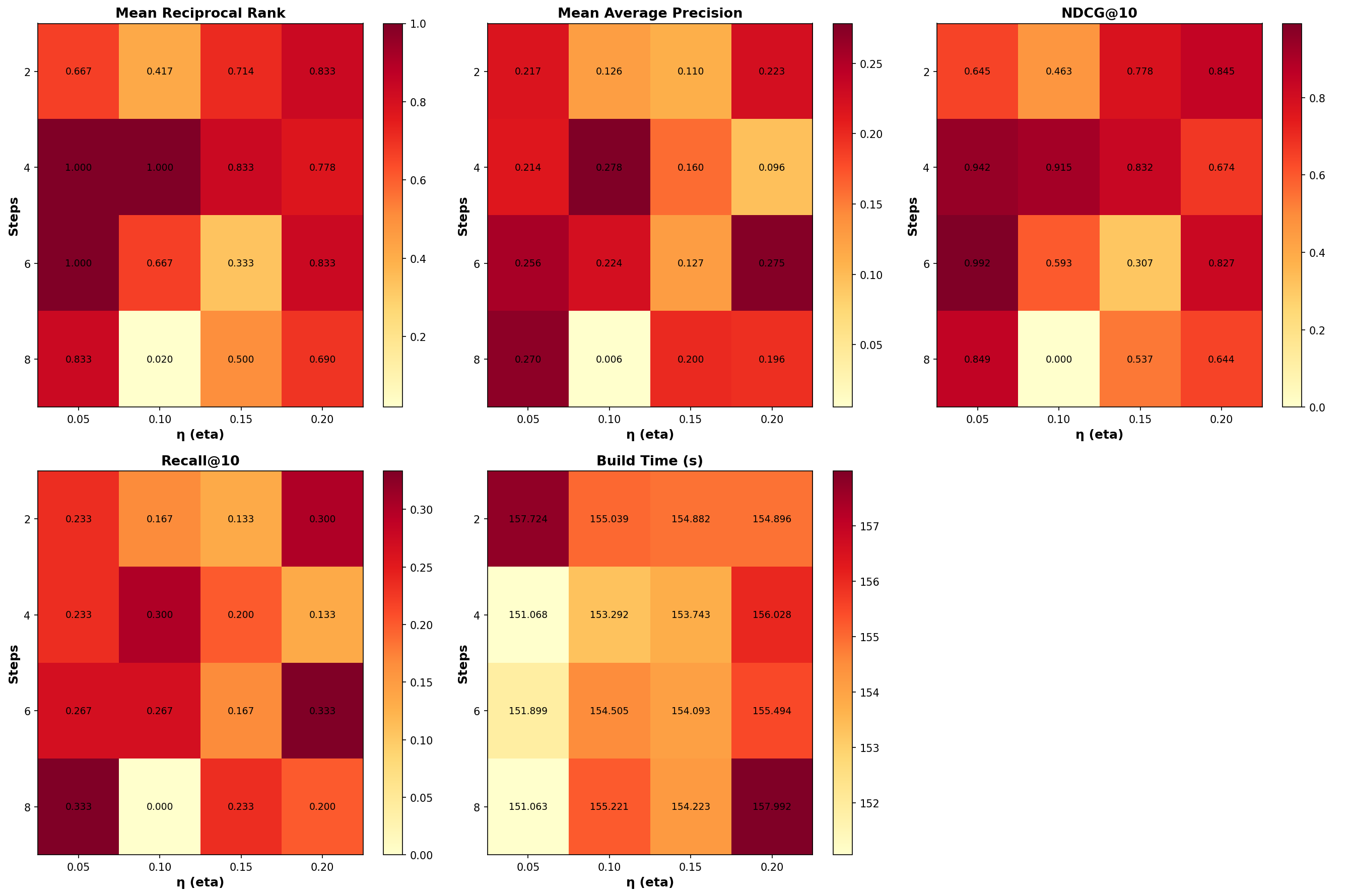
The heatmaps reveal optimal diffusion configurations:
| MRR | η=0.05, steps=4 | 1.0000 |
| MAP@20 | η=0.1, steps=4 | 0.2784 |
| NDCG@10 | η=0.05, steps=6 | 0.9917 |
| Recall@10 | η=0.05, steps=8 | 0.3333 |
Key observations:
-
Low η with moderate steps (η=0.05, steps=4–6) consistently produces the highest MRR and NDCG@10, indicating strong top-1 and top-10 ranking quality but fails completely in one query. So higher η is advised.
-
Higher η values (η=0.2) show more variance—some configurations achieve competitive MAP@20, but others (e.g., η=0.1, steps=8) collapse to near-zero scores, suggesting over-smoothing destroys discriminative features. This is more like the results I would like to see.
-
Build times remain stable (~151–158s) across all configurations, confirming that diffusion overhead is negligible relative to graph construction.
-
NDCG@10 ≈ 0.99 for η=0.05, steps=6 indicates near-perfect ranking of the top-10 results—energy distance precisely captures semantic relevance without relying on cosine similarity but again η=0.05 appears to be less reliable overall and requires more steps.
Next tests are going to focus on something in the interval of (η=0.10, steps=4–6) as they seems to be most reliable in the trade-off between accuracy and novelty of results.
Why Energy Search Is Exciting
The combination of optical compression and energy-informed retrieval unlocks capabilities that pure geometric similarity cannot deliver:
Spectral Resilience to Language Drift
Energy metrics encode graph Laplacian invariants—properties that remain stable under smooth transformations of the feature space. This means the index is robust to domain shift: new data with similar topological structure will be ranked correctly even if the semantic embedding space drifts over time.
Tail Quality Without Head Sacrifice
Energy search surfaces relevant alternatives beyond the very top ranks by balancing lambda proximity (global smoothness), dispersion (local roughness), and Dirichlet energy (feature-space variability). This preserves head fidelity (MRR ≈ 1.0) while improving tail diversity—precisely the trade-off needed for operational retrieval systems.
One-Time Computation, Persistent Index
Once the energy Laplacian is constructed, only the scalar lambda (taumode) per row needs to be stored—the graph itself can be discarded or reused with extended or reduced versions of the same or other domain-specific dataset (this allows comparison and reuse between difference versions of the dataset). Query-time scoring uses stored lambdas and lightweight feature-space Dirichlet computation, with no graph traversal or reconstruction overhead, it is a simple search on a line of Real numbers.
Integration: Optical + Energy in ArrowSpace
The full pipeline (v0.18.1) combines optical compression (from the Rust vision encoder) with energy search (from energymaps.rs):
Optical compression reduces the centroid budget (1681 items → 40 tokens in the test corpus), while energy search ranks items purely by spectral properties—no cosine similarity anywhere in the pipeline.
Implementation Status and Future Work
What’s Ready
- Optical embeddings in Rust: Full DeepEncoder architecture (SAM + CLIP + projector) with multi-resolution support and cross-platform GPU acceleration (WGPU/CUDA)
- Energy pipeline in ArrowSpace v0.18.0: build_energy and search_energy with optical compression, diffusion, splitting, and energy-distance kNN
- Parameter sweep infrastructure: Automated grid search over diffusion hyperparameters with IR metrics and heatmap visualization
Next Steps
- Weight tuning automation: Grid search over \(w_\lambda, w_G, w_D\) to optimize energy-distance scoring for specific domains
- Larger corpus validation: Extend testing to 100K+ item datasets to validate scalability and tail behavior at scale
- Python bindings: Expose build_energy and search_energy in the PyArrowSpace API for seamless integration with embedding pipelines
- GPU-accelerated diffusion: Port diffusion iterations to CUDA/WGPU for sub-second index builds on large graphs
References
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, Yukun Li
arXiv:2510.18234 [cs.CV], October 2025
Paper | Code & Weights
Summary
Optical compression treats text as a visual medium, achieving 10× token reduction while preserving semantic structure. The Rust implementation replicates DeepSeek-OCR’s DeepEncoder architecture using burn.dev, enabling production deployment with cross-platform GPU support (at current date, full code available only for sponsors). Optical compression will be available to all users in arrowspace v0.18.1.
Energy search in ArrowSpace v0.18.0 removes cosine similarity dependence entirely, ranking items by spectral graph properties: Rayleigh quotient, edge dispersion, and bounded Dirichlet energy. The diffusion parameter sweep on CVE data confirms that low η with moderate steps (η=0.05, steps=4–6) achieves near-perfect top-10 ranking (NDCG@10 ≈ 0.99) while maintaining stable build times.
The combination of optical compression (reducing dimensionality via spatial pooling) and energy distance (encoding topological structure) enables retrieval systems that are:
- Robust to domain shift (spectral invariants persist under smooth transformations)
- Tail-aware (high dispersion nodes split to increase local resolution)
- Storage-efficient (only scalar lambdas stored per item, graph discarded)
Is this the architecture for next-generation vector databases? Indices that respect the manifold structure of data, not just its geometric projection.
Interested in learning more? Whether you’re evaluating ArrowSpace for your data infrastructure, considering sponsorship, or want to discuss integration strategies, please check the Contact page.
Please consider sponsoring my research and improve your company’s understanding of LLMs and vector databases.
Book a call on Calendly to discuss how ArrowSpace can accelerate discovery in your analysis and storage workflows, or discussing these improvements.


