.png)

When r1 was released in January 2025, there was a DeepSeek moment.
When r1-0528 was released in May 2025, there was no moment. Very little talk.
Here is a download link for DeepSeek-R1-0528-GGUF.
It seems like a solid upgrade. If anything, I wonder if we are underreacting, and this illustrates how hard it is getting to evaluate which models are actually good.
What this is not is the proper r2, nor do we have v4. I continue to think that will be a telltale moment.
For now, what we have seems to be (but we’re not sure) a model that is solid for its price and status as an open model, but definitely not at the frontier, that you’d use if and only if you wanted to do something that was a very good fit and played to its strong suits. We likely shouldn’t update much either way on v4 and r2, and DeepSeek has a few more months before it starts being conspicuous that we haven’t seen them.

We all remember The DeepSeek Moment, which led to Panic at the App Store, lots of stock market turmoil that made remarkably little fundamental sense and that has been born out as rather silly, a very intense week and a conclusion to not panic after all.
Over several months, a clear picture emerged of (most of) what happened: A confluence of narrative factors transformed DeepSeek’s r1 from an impressive but not terribly surprising model worth updating on into a shot heard round the world, despite the lack of direct ‘fanfare.’
In particular, these all worked together to cause this effect:
The ‘six million dollar model’ narrative. People equated v3’s marginal compute costs with the overall budget of American labs like OpenAI and Anthropic. This is like saying DeepSeek spent a lot less on apples than OpenAI spent on food. When making an apples-to-apples comparison, DeepSeek spent less, but the difference was far less stark.
DeepSeek simultaneously released an app that was free with a remarkably clean design and visible chain-of-thought (CoT). DeepSeek was fast following, so they had no reason to hide the CoT. Comparisons only compared DeepSeek’s top use cases to the same use cases elsewhere, ignoring the features and use cases DeepSeek lacked or did poorly on. So if you wanted to do first-day free querying, you got what was at the time a unique and viral experience. This forced other labs to also show CoT and accelerate release of various models and features.
It takes a while to know how good a model really is, and the different style and visible CoT and excitement made people think r1 was better than it was.
The timing was impeccable. DeepSeek got in right before a series of other model releases. Within two weeks it was very clear that American labs remained ahead. This was the peak of a DeepSeek cycle and the low point in others cycles.
The timing was also impeccable in terms of the technology. This was very early days of RL scaling, such that the training process could still be done cheaply. DeepSeek did a great job extracting the most from its chips, but they are likely going to have increasing trouble with its compute disadvantage going forwards.
DeepSeek leveraged the whole ‘what even is safety testing’ and fast following angles, shipping as quickly as possible to irrevocably release its new model the moment it was at all viable to do so, making it look relatively farther along and less behind than they were. Teortaxes notes that the R1 paper pointed out a bunch of things that needed fixing but that DeepSeek did not have time to fix back then, and that R1-0528 fixes them, and which weren’t ‘counted’ during the panic.
DeepSeek got the whole ‘momentum’ argument going. China had previously been much farther behind in terms of released models, DeepSeek was now less behind (and some even said was ahead), and people thought ‘oh that means soon they’ll be ahead.’ Whereas no, you can’t assume that, and also moving from a follower to a leader is a big leap.
There was highly related to a widespread demand for a ‘China caught up to the USA’ narrative, from China fans and also from China hawks of all sorts. Going forward, we are left with a ‘missile gap’ style story.
There are also a lot of people always pushing the ‘open models win’ argument, and who think that non-open models are some combination of doomed and don’t count. These people are very vocal, and vibes are a weapon of choice, and some have close ties to the Trump administration.
The stock market was highly lacking in situational awareness, so they considered this release much bigger news than it was, and it caused various people to ‘wake up’ to things that were already known and anticipate others waking up, and there was widespread misunderstanding of how any of the underlying dynamics worked, including Jevon’s Paradox and also that if you want to run r1 you go out and buy more chips, including Nvidia chips. It is also possible that a lot of the DeepSeek stock market reaction was actually about insider trading of Trump policy announcements. Essentially: The Efficient Market Hypothesis Is False.
I continue to believe that when R2 arrives (or fails to arrive for a long time), this will tell us a lot either way, whereas the R1-0528 we got is not a big update. If R1-0528 had been a fully top model and created another moment, that would of course huge, but all results short of that are pretty similar.
I stand by what I said in AI #118 on this:
Miles Brundage: Relatedly, DeepSeek's R2 will not tell us much about where they will be down the road, since it will presumably be based on a similarish base model.
Today RL on small models is ~everyone's ideal focus, but eventually they'll want to raise the ceiling.
Frontier AI research and deployment today can be viewed, if you zoom out a bit, as a bunch of "small scale derisking runs" for RL.
The Real Stuff happens later this year and next year.
("The Real Stuff" is facetious because it will be small compared to what's possible later)
Zvi Mowshowitz: I think R2 (and R1-0528) will actually tell us a lot, on at least two fronts.
It will tell us a lot about whether this general hypothesis is mostly true.
It will tell us a lot about how far behind DeepSeek really is.
It will tell us a lot about how big a barrier will it be that DS is short on compute.
R1 was, I believe, highly impressive and the result of cracked engineering, but also highly fortunate in exactly when and how it was released and in the various narratives that were spun up around it. It was a multifaceted de facto sweet spot.
If DeepSeek comes out with an impressive R2 or other upgrade within the next few months (which they may have just done), especially if it holds up its position actively better than R1 did, then that’s a huge deal. Whereas if R2 comes out and we all say ‘meh it’s not that much better than R1’ I think that’s also a huge deal, strong evidence that the DeepSeek panic at the app store was an overreaction.
If R1-0528 turns out to be only a minor upgrade, that alone doesn’t say much, but the clock would be ticking. We shall see.
Teortaxes: I'm not sure what Miles means by similarish, but I agree more with @TheZvi here: R2 will be quite informative. It's clear that DeepSeek are reinventing their data and RL pipelines as well as model architecture. R2/V4 will be their biggest departure from convention to date.
Is it possible this was supposed to be R2, but they changed the name due to it being insufficient impressive? Like everyone but Chubby here I strongly think no.
I will however note that DeepSeek has a reputation for being virtuous straight shooters that is based on not that many data points, and one key point of that was their claim to have not done distillation, a claim that now seems questionable.
The state of benchmarking seems rather dismal.
This could be the strongest argument that the previous DeepSeek market reaction was massively overblown (or even a wrong-way move). If DeepSeek giving us a good model is so important to the net present value of our future cash flows, how is no one even bothering to properly benchmark r1-0528?
And how come, when DeepSeek released their next model, Nvidia was up +4%? It wasn’t an especially impressive model, but I have to presume it was a positive update versus getting nothing, unless the market is saying that this proves they likely don’t have it. In which case, I think that’s at least premature.
Evals aren’t expensive by the standards of hedge funds, indeed one of the hedge funds (HighFlyer) is how DeepSeek got created and funded.
Miles Brundage: Wild that with DeepSeek having caused a trillion dollar selloff not that long ago + being such a big talking point for so many people, they dropped a new model several hours ago + no one seems to have run a full eval suite on it yet.
Something something market failure
And yes evals can be expensive but not that expensive by the standards of this industry. And yeah they can be slow, but come on, literally trillion dollar stakes seems like a reason to find ways to speed it up (if you believe the market)??
We’ll see if this is fixed tomorrow…
DeepSeek subsequently released some evals btw (were not included in the initial release/when I tweeted, I think). Still good for others to verify them of course, and these are not exhaustive.
Gwern: Looks like 'DeepSeek-r1 single-handedly caused a trillion-dollar crash' has been refuted at the level of confidence of 'NVDA went up +4% after the next ~DS-r2 release half a year later'.

I notice that on GPQA Diamond, DeepSeek claims 81% and Epoch gives them 76%.
I am inclined to believe Epoch on that, and of course DeepSeek gets to pick which benchmarks to display whether or not they’re testing under fair conditions.
DeepSeek clearly have in various ways been trying to send the impression that R1-0528 is on par with o3, Gemini-2.5-Pro and Claude 4 Opus.
That is incompatible with the lack of excitement and reaction. If an open weights model at this price point was actually at the frontier, people would be screaming. You wouldn’t be able to find a quiet rooftop.
Peter Wildeford: Latest DeepSeek 4-11 months behind US:
* ~5 months behind US SOTA on GPQA Diamond
* ~4 months behind on MATH lvl 5
* ~11 months behind on SWE-Bench-Verified
We need more good evals to benchmark the US-China gap. Kudos to @EpochAIResearch for doing some of this work.
Math level 5 is fully saturated as of o3 so this should be the last time we use it.
Epoch AI: DeepSeek has released DeepSeek-R1-0528, an updated version of DeepSeek-R1. How does the new model stack up in benchmarks? We ran our own evaluations on a suite of math, science, and coding benchmarks. Full results in thread!
On GPQA Diamond, a set of PhD-level multiple-choice science questions, DeepSeek-R1-0528 scores 76% (±2%), outperforming the previous R1’s 72% (±3%). This is generally competitive with other frontier models, but below Gemini 2.5 Pro’s 84% (±3%).
On MATH Level 5, the hardest tier of the well-known MATH benchmark, R1-0528 achieves 97% accuracy, similar to the 98% scored by o3 and o4-mini. This benchmark has essentially been mastered by leading models.
On OTIS Mock AIME, a more difficult competition math benchmark that is based on the AIME exam, DeepSeek-R1-0528 scores 66% (±5%).
This improves substantially on the original R1’s 53% (±8%), but falls short of leading models such as o3, which scored 84% (±4%).
On SWE-bench Verified, a benchmark of real-world software engineering tasks, DeepSeek-R1-0528 scores 33% (±2%), competitive with some other strong models but well short of Claude 4.
Performance can vary with scaffold; we use a standard scaffold based on SWE-agent.
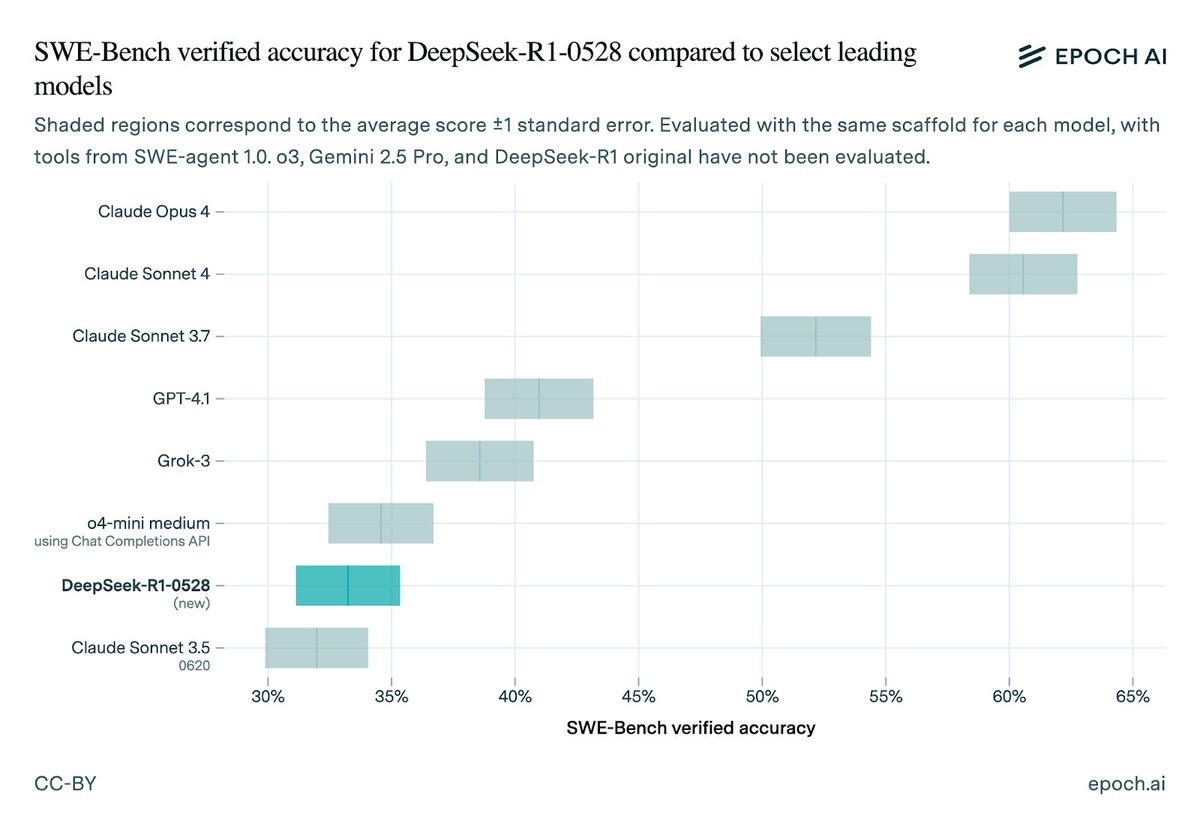
On SWE-bench Verified, DeepSeek-R1-0528 explores and edits files competently, but often submits patches prematurely without thoroughly verifying them.
You can find more information on the runs in our Log Viewer.
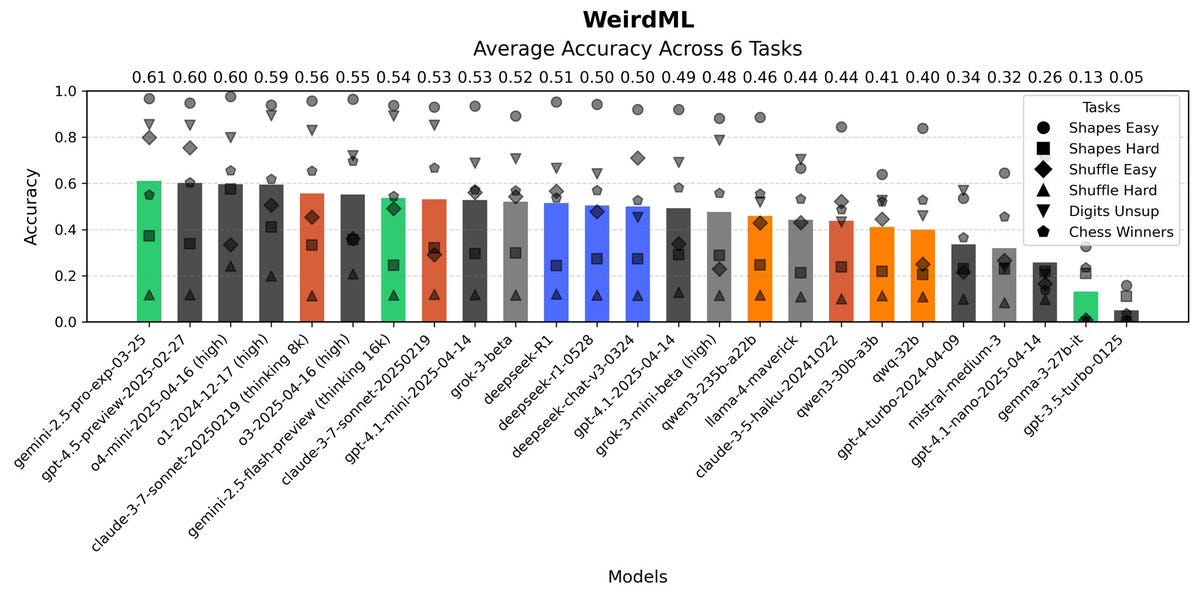
Here are the Lech Mazur benchmarks, where the scores are a mixed bag but overall pretty good.
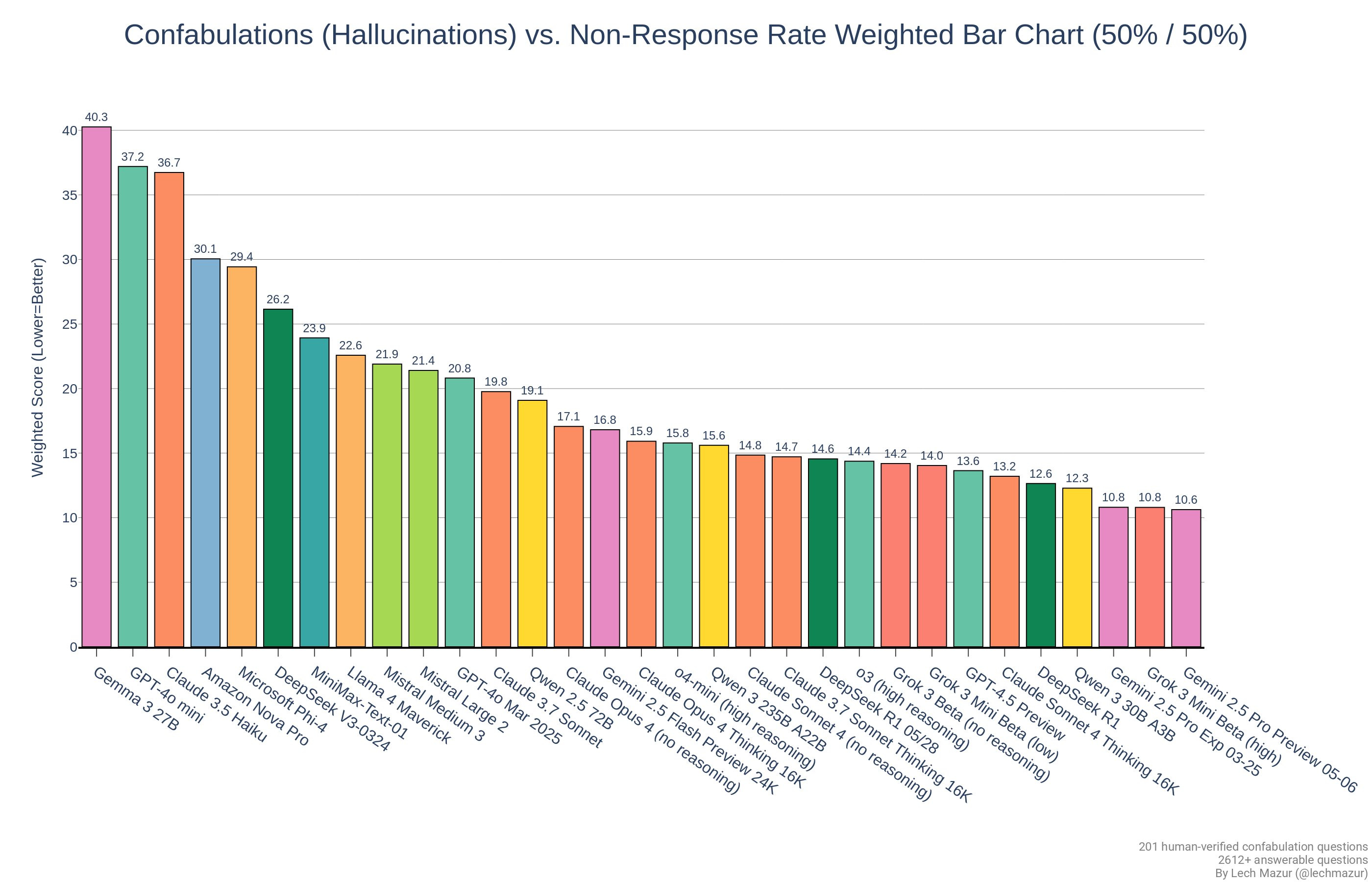
There is no improvement on WeirdML.
Havard Ihle: New R1 seems not that optimised for coding! No improvement on WeirdML. It is smart, but it has more variance, so many strong results, but also a much higher failure rate (45%, up from 30% for old R1). Often weird syntax errors or repeated tokens, even at the preferred temp of 0.6
The initial headlines were what you would expect, and were essentially ‘remember that big DeepSeek moment? Those guys gave us a new version.’
The upgraded model has “major improvements in inference and hallucination reduction,” Yakefu [an AI researcher at HuggingFace] said, adding that “this version shows DeepSeek is not just catching up, it’s competing.”
…
The upgraded DeepSeek R1 model is just behind OpenAI’s o4-mini and o3 reasoning models on LiveCodeBench, a site that benchmarks models against different metrics.
“DeepSeek’s latest upgrade is sharper on reasoning, stronger on math and code, and closing in on top-tier models like Gemini and O3,” Adina Yakefu, AI researcher at Hugging Face, told CNBC.
Yakefu is effectively talking their own book here. I don’t see why we should interpret this as catching up, everyone is reducing hallcinations and costs, but certainly DeepSeek are competing. How successfully they are doing so, and in what league is the question.
One can perhaps now see how wrong we were to overreact so much to the first r1. Yes, r1-0528 is DeepSeek ‘catching up’ or ‘closing in’ in the sense that DeepSeek’s relative position looks now, right after a release, better than it looked on May 27. But it does not look better than when I wrote ‘on DeepSeek’s r1’ in January and LiveCodeBench appears at best cherry picked.
The article concludes with Nvidia CEO Huang making his typical case that because China can still make some AI models and build some chips, we should sacrifice our advantages in compute on the altar of Nvidia’s stock price and market share.
Here’s Bloomberg’s Luz Ding, who notes up front that the company calls it a ‘minor trial upgrade,’ so +1 to Ding, but there isn’t much additional information here.
A search of the Washington Post and Wall Street Journal failed to find any articles at all covering this event. If r1 was such a big moment, why is this update not news? Even if it was terribly disappointing, shouldn’t that also be news?
Normally, in addition to evals, I expect to see a ton of people’s reactions, and more when I open up my reactions thread.
This time, crickets. So I get to include a lot of what did show up.
Teortaxes: my thesis is that this is just what R1 was supposed to be as a product. Direct gains on benchmarks are in line with expectations. What is interesting is that it's more «Westoid», has a sycophancy problem, and its CoTs are totally different in manner.
Both V3-original and R1-original should be thought of as *previews. We know they shipped them as fast as they could, with little post-training (≈$10K for V3 not including context extension, maybe $1M for R1). 0324, 0528 are what they'd do originally, had they more time & hands.
(they don't advertise it here but they also fixed system prompt neglect/adverse efficiency, multi-turn, language consistency between CoT and response, and a few other problems with R1-old. It doesn't deserve a paper because we've had all such papers done by January)
Teortaxes highlights where the original R1 paper says they plan to fix these limitations. This seems like a reasonable way to think about it, R1-0528 is the version of R1 that isn’t being rushed out the door in a sprint with large compute limitations.
Alexander Doria: DeepSeek new R1 is expectedly great, but I admit I’m more eagerly waiting for the paper. Hopefully tying generalist reward, subgoal models from prover and overall engineering challenge of scaling RL (GRPO over nccl?)
Satwik Patil: I have ran about 15 runs of something like the AI 2027 TTX board game with it and it is very good at it. Unlike other models, particularly Gemini, it actually accepts that bad things can happen(or it can do bad things) and plays them out.
It is also the least aware of any model that it's thoughts can be read by the user.
Petr Baudis: A lot of people were hungry for R1 on the initial release as there were no interesting reasoning models outside of OpenAI at that point (besides the fact that this is opensource).
But I doubt too many of the Twitter frontier use DeepSeek daily right now.
Michael Roe: 0528 really overthought my “simulate an IBM mainframe” prompt. Its chain of thought was much more verbose that the previous R1 for this particular prompt. But, ok, it did give me a simulation.
It’s CoT even had pseudocode for algorithms. And, to be fair, its CoT foregrounds an issue that previous R1 missed, that the whole idea assume you can reconstruct the state from the history of terminal input and output. 0528 realises that it’s going to have to stash internal state somewhere.
0528 was able to solve a problem that I couldn’t gr5 an answer to before. Basically, i had Chinese text in Wade-Giles transliteration with a mangled word, and the problem is to use contextual clues to find a word that makes sense in context and sounds a bit like the text.
i’m using 0528, but no definite conclusions yet. The tabletop rpg scenario where I have a talking squirrel sidekick now has a singing, talking squirrel sidekick when I run it with 0528. (Obviously, that squirrel is a nod to Disney). 0528 is subjectively better, in that it can commit to the bit even better than the previous version.
bad8691: I didn't know a new version would get released. Today I asked a question to it as usual and reading the reasoning traces, immediately said "wow, looks like its social intelligence has visibly improved". Don't know about the benchmarks but it was just obvious to me.
xEC40: its a lot different, lot of chinese on ambiguous prompts unlike 0324 and r1, but good prompt adherence. i gotta play with it more
Dominik Lukes: As is now the norm with new model releases, it's hard to say what the real-world benefit just from the benchmarks or stated intention for developers. The clear need is now for everybody do develop their own evals for actual usage and run them against the model. In my own informal testing I can't tell the difference.
Oli: basicly jus a slightly smarter version of r1 but with all the same limitations of the old one no function calling text only etc so its not that useful in practice qwen 3 is still superior
Biosemiote: I love deepseek poetry. Not sure if better than previous models, but miles above the competition.
Through the Ice Lens
Cold grinds the creek to glass—
A lens of pure, cracked grace—
And in its flawed design,
The world aligns:
A spider’s web, exact as wire,
The sun’s last coal, a stolen fire.
But look— trapped bubbles rise like breath,
A drowned leaf’s veins rehearsing death.
Gwern: Nah, that's still r1 cringelord. Claude & Gemini are much better for poetry. (And still the usual semantic problems of interesting images interspersed with nonsense: how can cold 'grind' water to solid glass? In some frozen river ice, what is the "sun's last coal", exactly? etc)
Leo Abstract: it also is far better at understanding text-based divination systems. given how it is being used in china, i think neither of these strengths are an accident, and them not going away with updates confirms this.
it seems as though it's trying harder to understand the complexities instead of just scanning the spread or cast or chart for ways to glaze you. if you've kept notes, try having it (vs, say, gemini 2.5 pro) duplicate your previous work.
This was the high end of opinion, as xjdr called it a frontier model, which most people clearly don’t agree with at all, and kalomaze calls it ‘excellence’ but this is relative to its size:
xjdr: R1-0528 is mostly interchangeable (for me) with gemini pro 0520 and opus 4. it has a distinctly gemini 2.5 pro 0325 flavor which is not my favorite, but the quality is impossible to deny (i preferred the o1 on adderall flavor personally). we officially have frontier at home.
Teortaxes (linking to Epoch): what is the cope for this?
xjdr: Not sure what they are doing to elicit this behavior. If anything, I find R1 0528 to be verbose and overly thorough. Admittedly, my workflows are much more elaborate than 'please fix this' so I ensure plans are made and implemented, patches compile, tests are written and pass, etc
Teortaxes: «we use a standard scaffold based on SWE-agent.» It's obviously better at function calling than R1 but not clear if this is a good fit.
xjdr: I found it performed very well with xml based custom function definitions. It performed reasonably well with the function defs as defined in the huggingface tokenizer template. One thing I do often (I do this for most 'thinking' models) is i prefill the response with:
<think>
</think>
To make the output parsing more consistent.
Kalomaze: r1-0528 is excellence
Zephyr: How did it perform in ur tests? Compared to o3/2.5 Pro/Opus 4??
Kalomaze: a majority of the models that you just described are either way too rate limited expensive or otherwise cumbersome to be worth directly comparing to a model so cheap tbh
Bob from Accounting: Very impressive for its price, but not quite SOTA on anything.
That was also the reaction to the original r1, and I sort of expect that trend to continue.
Kalomaze: new r1 watered my crops, cleared my skin, etc
However:
Kalomaze: none of the sft distills are good models because you still need RL and sft local biases compound.
Different people had takes about the new style and what it reminded them of.
Cabinet: A lot of its outputs smell like 4o to me. This was more extreme on deepseek web vs using 0528 on API, but both feel directionally more “productized,” more sycophantic, more zoomer-reddit phrasing, etc. Does feel a step smarter than R1.0 tho. Just more annoying.
A key question that was debated about the original r1 was whether it was largely doing distillation, as in training on the outputs of other models, effectively reverse engineering. This is the most common way to fast follow and a Chinese specialty. DeepSeek explicitly denied it was doing this, but we can’t rely on that.
If they did it, this doesn’t make r1’s capabilities any less impressive, the model can do what the model can do. But it does mean that DeepSeek is effectively a lot farther behind and further away from being able to ‘take the lead.’ So DeepSeek might be releasing models comparable to what was available 4-8 months ago, but still be 12+ months behind in terms of ability to push the frontier. Both measures matter.
Gallabytes: I know we all stan deepseek here in 🐋POT but the distribution shift from 4o-like to Gemini-like for output suggests that the distillation claims are likely true and this should change the narrative more than it has IMO.
It's unclear how much they rely on distillation, whether it's key or merely convenient, but the more important it is the less seriously we should count them in the frontier.
it brings me no joy to report this, I really like the story of a lean player catching up to the giants in a cave with a box of scraps. certainly their pre-training efficiency is still quite impressive. but the rest of this situation smells increasingly sus.
Teortaxes: I think the claim of distillation is sound, since Gemini traces were open. I prefer Gemini reasoning, it's more efficient than early R1 mumbling. This probably explains some but not all of the performance gains. Imo it's reasonable to feel disappointed, but not despair.
Fraser Paine: This isn't actually bad, big corps pay hundreds of millions to generate data, getting this from existing models and distilling is a cost effective way to fast-follow. Doesn't mean 🐋can't push elsewhere to achieve frontier performance on tools or training/inference efficiency.
Then again, claims can differ:
AGI 4 President 2028: #1 take away is that OpenAI's attempt to curb distillation were successful.
I agree with Fraser, it’s not a bad move to be doing this if allowed to do so, but it would lower our estimate of how capable DeepSeek is going forwards.
If Teortaxes is saying the claim of distillation is sound, I am inclined to believe that, especially given there is no good reason not to do it. This is also consistent with his other observations above, such as it displaying a more ‘westoid’ flavor and having a sycophancy issue, and a different style of CoT.
If you place high value in the cost and open nature of r1-0528, it is probably a solid model for the places where it is strong, although I haven’t kept up with details of the open model space enough to be sure, especially given so little attention this got. If you don’t place high value on both open weights and token costs, it is probably a pass.
The biggest news here is the lack of news, the dog that did not bark. A new DeepSeek release that panics everyone once again was a ready made headline. I know I was ready for it. It didn’t happen. If this had been an excellent model, it would have happened. This also should make us reconsider our reactions the first time around.



