.png)


Shivam Anand
Shivam Anand is a seasoned machine learning engineer and technical leader with nearly a decade of experience at Meta and Google. He’s worked across integrity, ads, fraud detection, and video search, building ML systems that operate at trillion-event scale. His recent focus is on adversarial ML, using multimodal LLMs to defend against sophisticated bad actors. Shivam is passionate about making ML interviews more transparent and helping candidates navigate them with confidence. You can connect with him on LinkedIn.
I’m Shivam Anand, currently leading machine learning engineering (MLE) efforts at Meta, focused on integrity, recommendation, and search systems. Over the past decade, I’ve applied state-of-the-art ML to some of the toughest challenges in big tech—from scaling anti-abuse systems at Google Ads to rebuilding ML systems for Integrity enforcement at Facebook.
I’ve worked across a wide spectrum of ML teams: infra-heavy environments where we built real-time pipelines processing trillions of events, research-oriented initiatives involving LLMs and graph modeling, and applied ML settings focused on ranking, personalization, and abuse detection. My experience includes deploying systems that replaced thousands of handcrafted rules with ML, improving precision/recall across key metrics while reducing infra cost by 90%+.
Why write this? I’ve seen first-hand how the nature of ML work varies massively across team types and career paths. This guide is my attempt to map that space for others navigating (or considering) careers in ML—especially those targeting roles in big tech.
I will cover different ML team types, the kinds of roles you’re likely to see on those teams, how interview processes vary for ML roles, and how to make the lateral move from a software engineering role to an MLE one.
Disclaimer: As with any topic as broad as this, I’ve had to use sweeping generalizations. You can probably find exceptions to all of these.
What are the kinds of ML teams?
All ML teams in big tech can be placed on a spectrum along two key dimensions: infra focus vs. ML focus and research vs. application.
Infrastructure focus vs. ML focus
A team can be ML-adjacent, such as an ML infrastructure team that builds tooling, model training pipelines, or deployment frameworks. Some examples include:
- Facebook’s FBLearner team, which develops internal tools for training and deploying models across Meta.
- Google’s TFX (TensorFlow Extended) team, which builds scalable and production-ready ML pipelines used across Alphabet’s products.
- Uber’s Michelangelo team, which developed end-to-end ML infrastructure for internal product teams.
On the other end of the spectrum, a team may be focused on direct ML contributions, where improving model quality is the team’s core charter. Some examples include:
- YouTube’s recommendation team, responsible for optimizing watch time and engagement via personalized recommendations.
- Instagram’s Feed and Stories ranking team, which focuses on ranking content using ML to maximize user satisfaction.
- Amazon Search Relevance team, which applies ML to improve query understanding and search result quality.
Many teams start off with a hybrid focus—handling both infrastructure and modeling—but eventually split into specialized teams as their scope and scale grow.
Research vs. Application
A research-focused ML team concentrates on advancing the state of the art in areas like computer vision, natural language processing, or reinforcement learning. Their work often results in papers, new techniques, or reusable components that support multiple product teams. Examples:
- Facebook AI Research (FAIR), which publishes regularly in CVPR, NeurIPS, etc., and contributes open-source tools like PyTorch.
- Google DeepMind, which has driven breakthroughs in large language models and RL.
- Microsoft Research, especially in vision-language tasks and multimodal learning.
An application-focused team, on the other hand, owns a specific product or business metric. Their success is measured by KPIs such as click-through rate, time spent, or revenue. Examples:
- Facebook Ads CTR optimization teams, which apply ML to personalize ad delivery for better user engagement.
- Netflix personalization team, which applies ML to content ranking and recommendations.
- LinkedIn Feed ranking or People You May Know teams, which focus on engagement and growth metrics.
What are the types of ML engineers on a team?
Most ML teams consist of 2 kinds of ML engineers.
ML Specialists: These engineers specialize in a particular area of ML, like LLMs, Image modeling etc. Think of them as the go to expert within the team for their area of expertise.
ML Generalists: These engineers are excellent in a broad range of ML techniques. While she might not be able to get us to SOTA performance on a particular topic, it’s expected that she will get us to 80% performance across a wide range of topics. It’s expected for an ML generalist to be the only ML engineer in a small team with other non-ML engineers.
Each team needs a mix of generalists and specialists. The exact composition depends on where the team lies along the two dimensions above. Teams closer to infra need strong systems engineers and infra-minded ML practitioners. Teams focused on applied ML need deep product context and iterative modeling expertise. Research-heavy teams prioritize publication-quality rigor and often have PhDs specializing in foundational areas.
What do ML interview loops look like?
At a high level, most ML interview loops include a mix of the following:
- Coding (DSA/Implementation)
- ML Knowledge/Case Study Rounds
- ML System Design
- Behavioral/Team Fit Interviews
However, the emphasis placed on each varies based on team type and the nature of the ML role:
Team Type Variation
Infra-focused teams have an emphasis on:
- Software engineering skills
- Distributed systems
- MLOps and pipeline design
- Infra-focused system design questions
- May de-emphasize deep modeling knowledge unless the role is hybrid
Applied ML teams have an emphasis on:
- End-to-end ML lifecycle: problem framing, feature engineering, modeling, evaluation
- Understanding of trade-offs between models, experimentation design
- Experience deploying models in production
Research teams have an emphasis on:
- Deep expertise in a subfield (e.g., vision, NLP, RL)
- Ability to read/interpret/apply academic papers
- Writing and defending novel approaches
- Publication track record (for senior candidates)
- These teams might skip coding rounds and focus instead on whiteboard proofs, open-ended modeling problems, and research presentations
Role Type Variation
Generalist MLE roles have a breadth-first interview structure with the expectation of:
- Good practical intuition across supervised, unsupervised, embeddings, metrics
- Comfort across the ML stack (feature pipeline, training infra, deployment)
- Strong general engineering and debugging skills
ML Specialist roles have a depth-first interview structure with the expectation of:
- Deep understanding of specific model families
- Ability to implement and optimize SOTA models
- Familiarity with current research, benchmarks, datasets in their niche
What does an ML system design interview focus on?
My area of expertise is scaling ML, which emphasizes ML system design. So, I'll do a deep dive on those interviews in this post.
An ML system design interview is designed as a conversation to discover the edge of your knowledge. Unless you’re being interviewed for a very specific role in a specialized team, your interviewer does not know if you’re an ML specialist or a generalist going into the interview.
Your interviewer will be assess your performance on these focus areas:
- Problem Navigation: Do you explore the business context and tie the ML decision to the business problem?
- Training Data: How would you identify methods to collect training data? Do you explore biases, cold start, privacy etc?
- Feature Engineering: Can you identify the relevant features and their relative importance? How do you leverage existing information?
- Modeling: How do you explain modeling choices? Is your choice of features consistent with your model choice? Can you explain the architecture of your model?
- Evaluation & Deployment: How do you test your model offline and online? How do you deploy your model to production? How do you design your launch experiments, your caching and rollback strategies?
Your interviewer will put together the same question to you, and you will be assessed along the same set of dimensions. You will get a chance to show off both your breadth and depth as an ML Engineer. While we expect some breadth and depth from all engineers, your comfort with these informs your interviewer of your specialization.
You’ll need to cover all 5 focus areas, the composition and relative weights of these areas will be different.
An ML generalist will be able to cover a wide breadth of generic techniques applicable to a wide problem set.
- The statement that the interviewer can make about the candidate is: I’ll trust them to get the first set of versions of the system up and running.
- It’s expected that the candidate will go into considerations like the latency of evaluation vs. feature availability, train vs. test pollution, caching strategies, etc.
- It’s expected that the candidate will give a breadth of 2-3 techniques during the modeling stage, though they might not be able to completely customize the model to the particular problem at hand.
In contrast, an ML specialist has limited breath but is able to focus on depth in their area of expertise.
- The statement that the interviewer can make about the candidate is: I’ll trust them to be the expert on setting up the most optimized version of the system in the company.
- It’s expected that the candidate will give a breath of 2-3 techniques before jumping into the State of the Art (SOTA) methods in this particular field, what are the tradeoffs in between them, how would they change their approach to fit the particular problem at hand.
- It’s expected that the candidate might not be the strongest when it comes to specific considerations outside their area of expertise.
Here are some example ML system design mock interview replays from our collection:
How should you approach joining an ML engineering team in big tech?
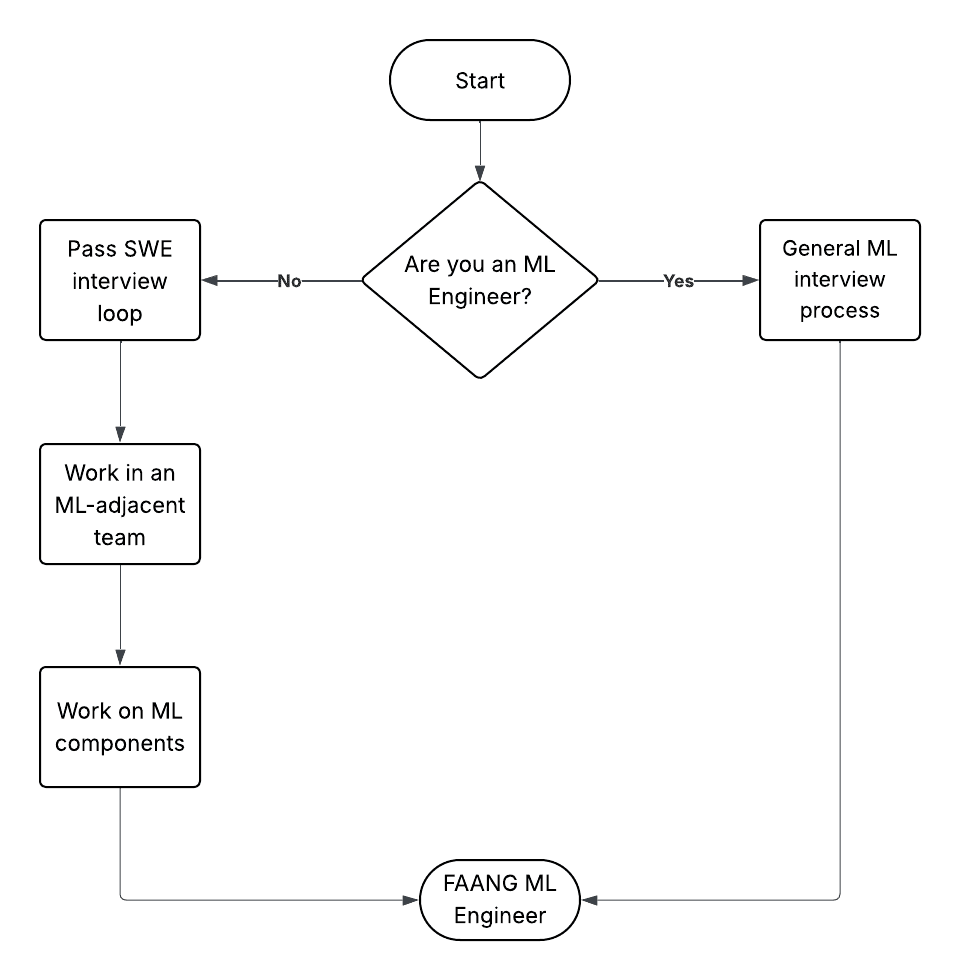
While there’s no fixed path to an ML role in Big tech, what I’m sharing here is a common path to being in an ML role in Big tech for non ML engineers, while getting paid along the way 🙂
Step 1: Leverage your existing skills to get into Big Tech Big tech has lots of support to upskill yourselves, including support for learning ML. If you’re a non ML engineer looking to switch into ML and Big tech, I suggest focusing on switching into Big tech first, then leveraging the resources inside the company to learn ML.
Step 2: Work in an ML-adjacent team Irrespective of your current focus areas, there are teams which work on ML which can leverage your skills.
Examples:
- Skilled in writing SQL pipelines? - There are teams which apply ML to primarily offline use cases, like integrity or reporting.
- Skilled in Android? - There are teams working on hotword detection on Android devices, or on next word prediction.
Step 3: Take ownership of ML components of projects over time This can start with taking ownership of one of the aspects mentioned earlier, like A/B testing, or a simple retrain of an existing model.
Pro tip: Leverage your manager to open ML opportunities for you.
Step 4: Explore! Switch teams to gather broad experience across multiple ML teams I’ve personally worked on ML on Google apps, Google Search, Ads Traffic quality and Facebook Trust and SafetyWith each switch, you get a chance to choose your degree of ML expertise, and the focus on the team in application vs Research.