.png)

When GitHub Copilot suggests your next line of code, does it matter whether your variables are named current_temperature or just x?
I ran an experiment to find out, testing 8 different AI models on 500 Python code samples across 7 naming styles. The results suggest that descriptive variable names do help AI code completion.
The Experiment
Each code sample was transformed into different naming conventions:
- Descriptive (process_user_input)
- Standard styles (snake_case, PascalCase, SCREAM_SNAKE_CASE)
- Minimal (calc_pay)
- Obfuscated (fn2)
Models ranging from 0.5B to 8B parameters completed 25 tokens for each sample. I measured exact matches, Levenshtein similarity (edit distance) and semantic correctness using an LLM judge.
Key Findings
Descriptive names performed best across all models:
- 34.2% exact match rate vs 16.6% for obfuscated names
- 0.786 Levenshtein similarity vs 0.666 for obfuscated names
- 0.874 semantic similarity vs 0.802 for obfuscated
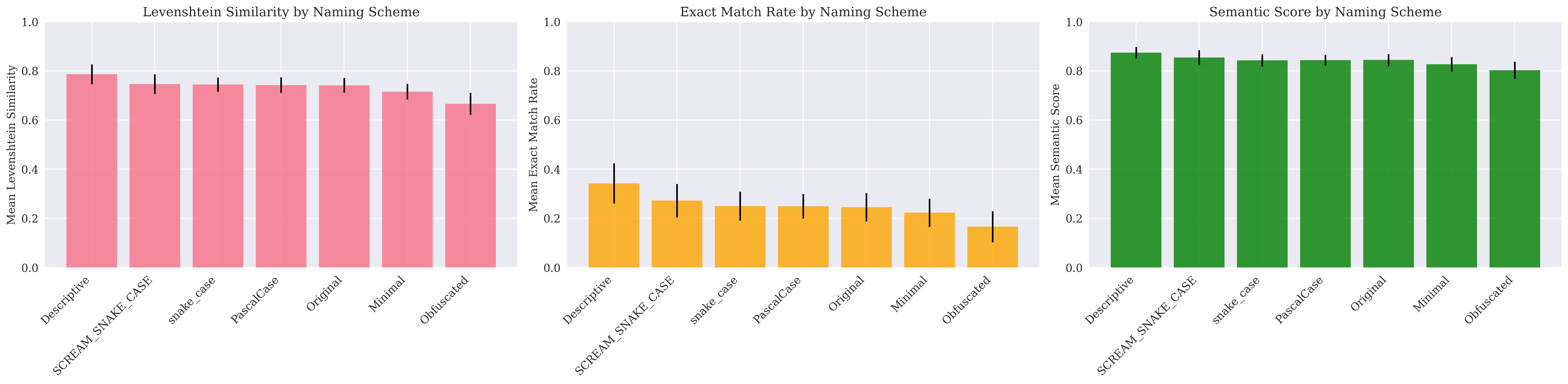
Performance across naming schemes shows consistent patterns
The ranking was consistent: descriptive > SCREAM_SNAKE_CASE > snake_case > PascalCase > minimal > obfuscated.
Descriptive names use 41% more tokens but achieve 8.9% better semantic performance, suggesting AI models prioritize clarity over compression.
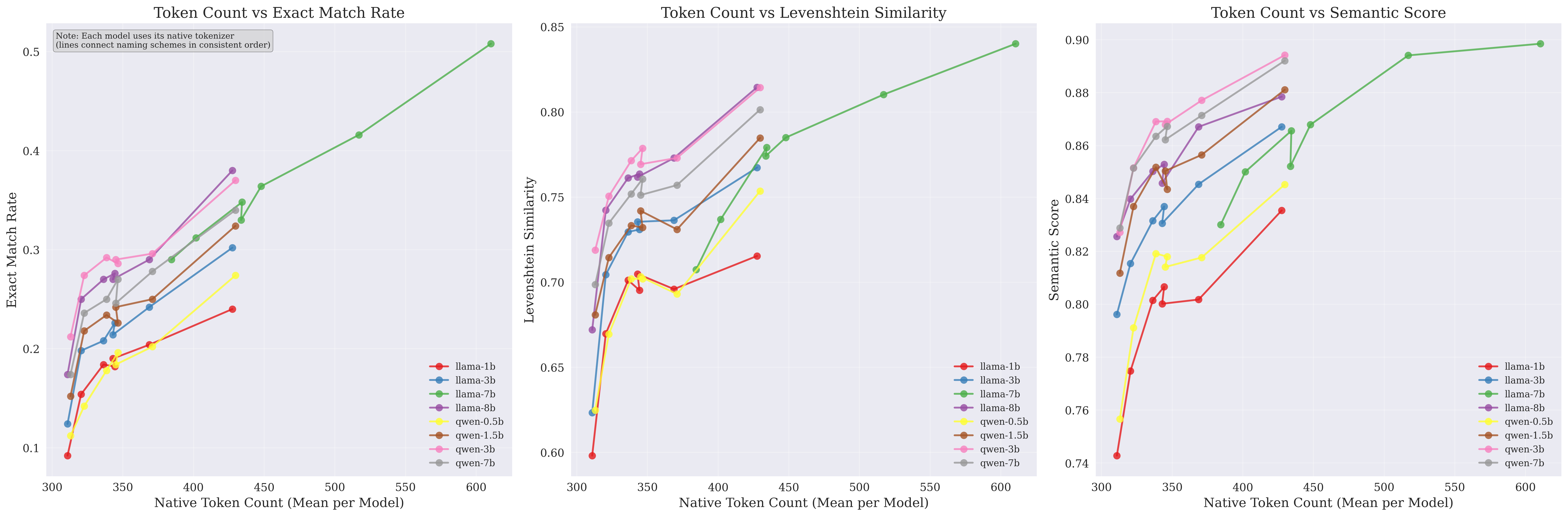
Despite using more tokens, descriptive names achieve better performance
For Developers
If you're using AI coding tools, descriptive variable names appear to provide better completions. The improvement is measurable.
This aligns with existing guidance for human readability - it turns out clear names benefit AI systems too.
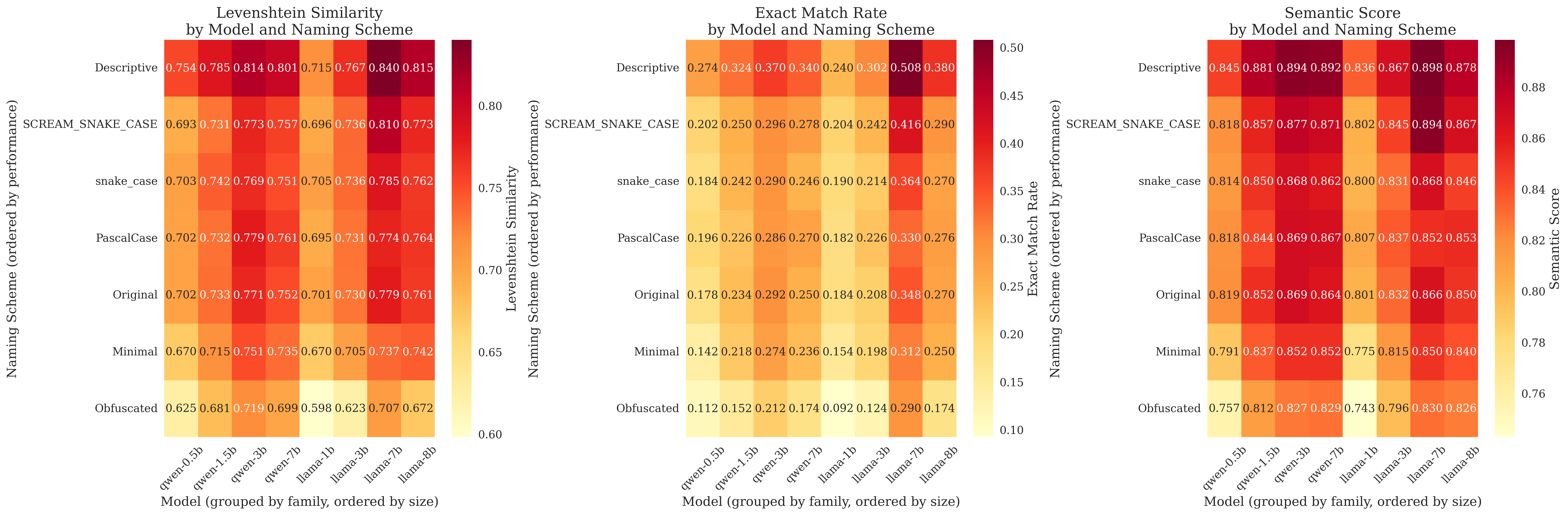
Cross-model consistency shows these patterns hold across different architectures
Full paper: Variable Naming Impact on AI Code Completion: An Empirical Study



