.png)

Contents
Team: Jiacheng Ye*, Zhihui Xie*, Lin Zheng*, Jiahui Gao*, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong.
Affiliations: The University of Hong Kong, Huawei Noah’s Ark Lab
Introducing Dream 7B
In a joint effort with Huawei Noah’s Ark Lab, we release Dream 7B (Diffusion reasoning model), the most powerful open diffusion large language model to date.
In short, Dream 7B:
- consistently outperforms existing diffusion language models by a large margin;
- matches or exceeds top-tier Autoregressive (AR) language models of similar size on the general, math, and coding abilities;
- demonstrates strong planning ability and inference flexibility that naturally benefits from the diffusion modeling.
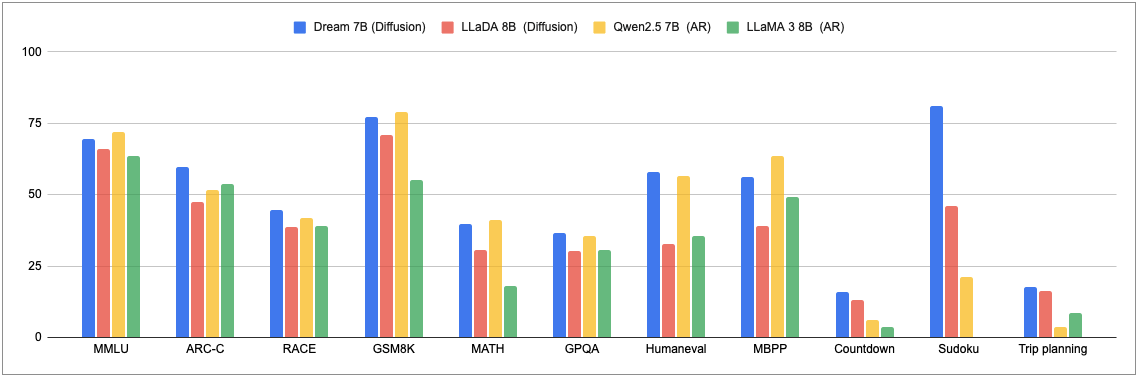 Figure: comparison of language models on general, math, coding, and planning tasks.
Figure: comparison of language models on general, math, coding, and planning tasks. 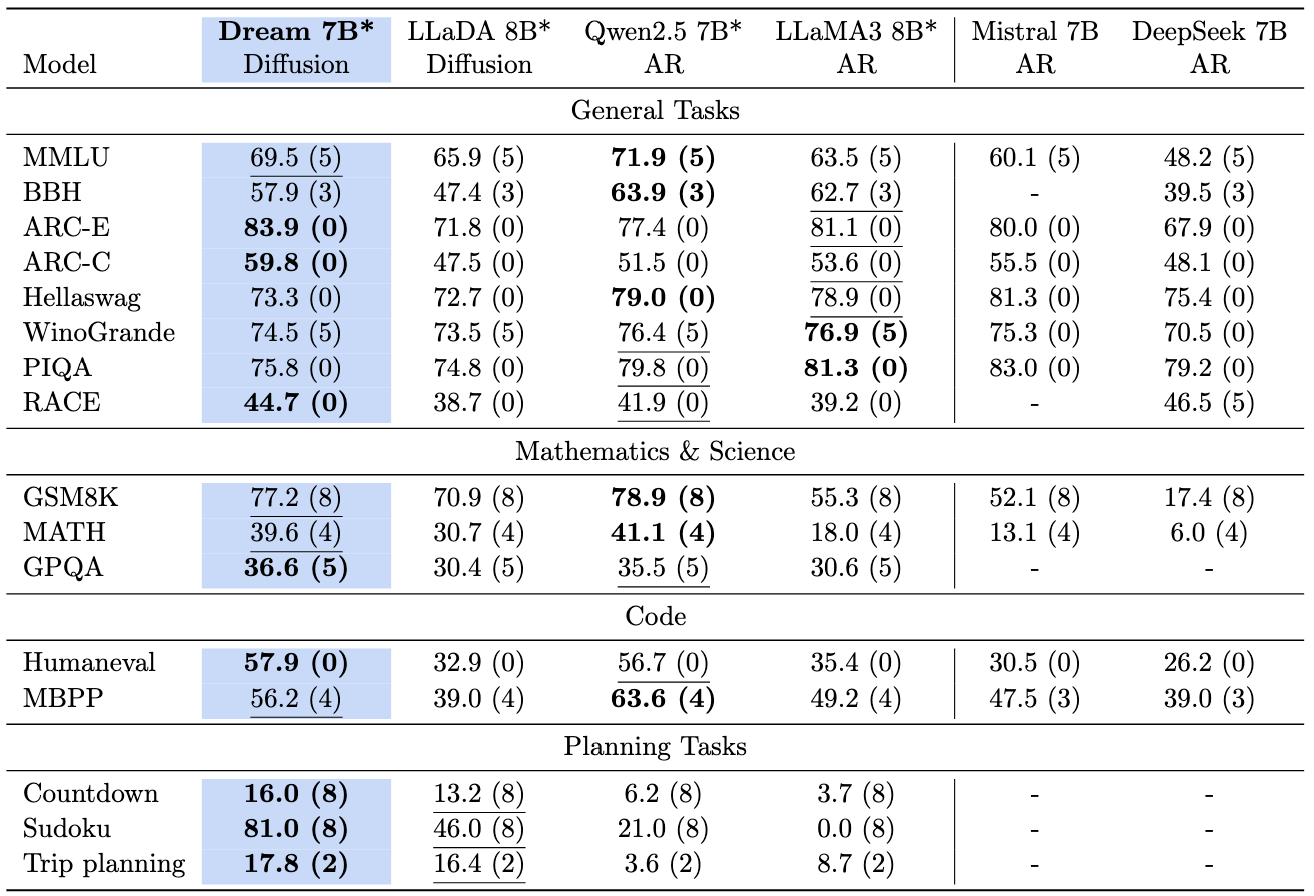 Figure: comparison of language models on standard evaluation benchmarks. * indicates Dream 7B, LLaDA 8B, Qwen2.5 7B and LLaMA3 8B are evaluated under the same protocol. The best results are bolded and the second best are underlined.
Figure: comparison of language models on standard evaluation benchmarks. * indicates Dream 7B, LLaDA 8B, Qwen2.5 7B and LLaMA3 8B are evaluated under the same protocol. The best results are bolded and the second best are underlined. We release the weights of the base and instruct models in:
- Base model: Dream-org/Dream-v0-Base-7B
- SFT model: Dream-org/Dream-v0-Instruct-7B
- Codebase: GitHub
Why Diffusion for Text Generation?
The rapid advancement of large language models (LLMs) has revolutionized artificial intelligence, transforming numerous applications across industries. Currently, autoregressive (AR) models dominate the landscape of text generation, with virtually all leading LLMs (e.g., GPT-4, DeepSeek, Claude) relying on this same sequential left-to-right architecture. While these models have demonstrated remarkable capabilities, a fundamental question emerges: what architectural paradigms might define the next generation of LLMs? This question becomes increasingly relevant as we observe certain limitations in AR models at scale, including challenges with complex reasoning, long-term planning, and maintaining coherence across extended contexts. These limitations are particularly crucial for emerging applications such as embodied AI, autonomous agents, and long-horizon decision-making systems, where sustained reasoning and contextual understanding are essential for success.
Discrete diffusion models (DMs) have gained attention as a promising alternative for sequence generation since their introduction to the text domain . Unlike AR models that generate tokens sequentially, discrete DMs dynamically refine the full sequence in parallel starting from a fully noised state. This fundamental architectural difference unlocks several significant advantages:
- Bidirectional contextual modeling enables richer integration of information from both directions, substantially enhancing global coherence across the generated text.
- Flexible controllable generation capabilities arise naturally through the iterative refinement process.
- Potential for fundamental sampling acceleration through novel architectures and training objectives that enable efficient direct mapping from noise to data .
Recently, significant advancements have highlighted diffusion’s growing potential in language tasks. DiffuLLaMA and LLaDA scaled diffusion language models to 7B parameters, while Mercury Coder, as a commercial implementation, has demonstrated remarkable inference efficiency in code generation. This rapid progress, combined with the inherent architectural advantages of diffusion language modeling, positions these models as a promising direction for overcoming the fundamental limitations of autoregressive approaches.
Training
Dream 7B builds upon our team’s prior efforthttps://ikekonglp.github.io/dreams.html in the diffusion language model area, drawing from RDM’s theoretical foundation and DiffuLLaMA’s adaptation strategy. We adopt a mask diffusion paradigm with the model architecture shown below. Our training data spans from text to math and code, mainly sourced from Dolma v1.7, OpenCoder, and DCLM-Baseline, with several pre-processing and curation pipelines. Following a carefully designed training process, we pretrain Dream 7B using a mixture of the aforementioned corpus, totaling 580 billion tokens. The pretraining was done on 96 NVIDIA H800 GPUs for 256 hours. The pretraining process went smoothly overall, with occasional node anomalies, and we did not experience any unrecoverable loss spikes.
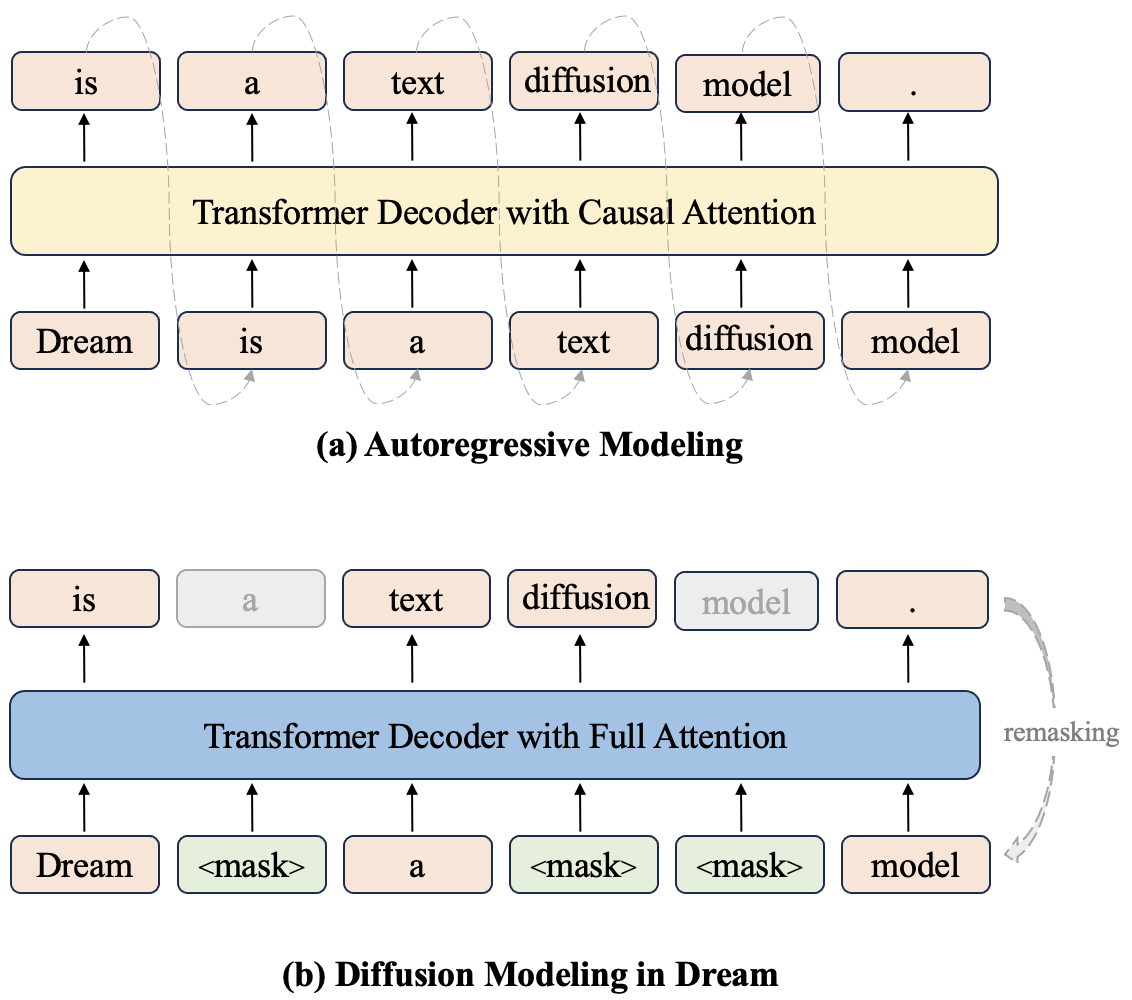 Figure: comparison of autoregressive modeling and diffusion modeling in Dream. Dream predicts all the masked tokens in a shifted manner, allowing for maximumly architectural alignment and weight initialization with AR models.
Figure: comparison of autoregressive modeling and diffusion modeling in Dream. Dream predicts all the masked tokens in a shifted manner, allowing for maximumly architectural alignment and weight initialization with AR models. We extensively studied the design choices on the 1B level and identified many valuable components, such as weight initialization from AR models (e.g., Qwen2.5 and LLaMA3) and a context-adaptive token-level noise rescheduling, which enables the effective training of Dream 7B.
AR initialization
Building on our previous work DiffuLLaMA, we discovered that using the weights from the existing autoregressive (AR) model serves as a non-trivial initialization for the diffusion language model. We find this design is more effective than training the diffusion language model from scratch, particularly during the early stages of training, as illustrated in the figure below.
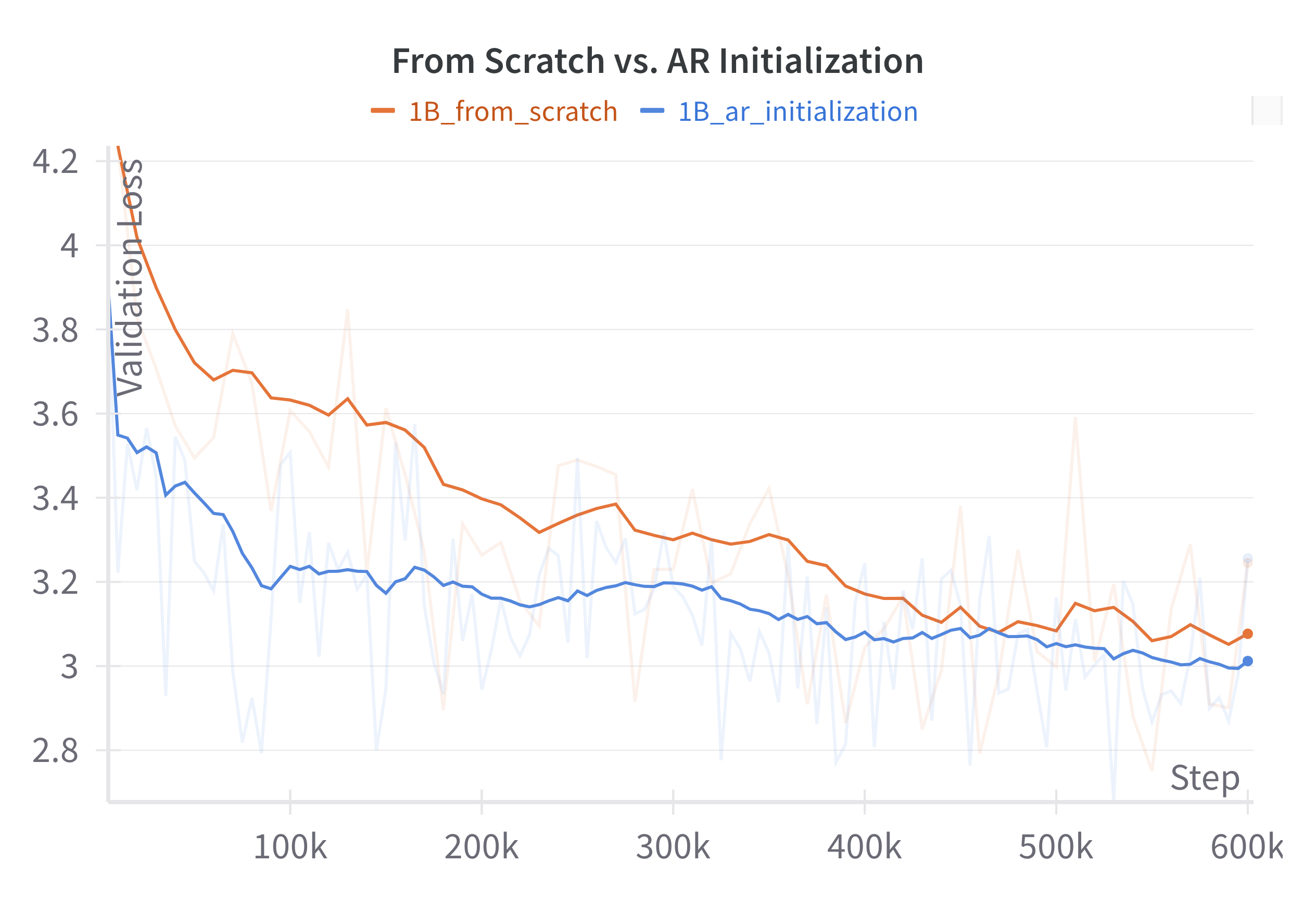 Figure: loss comparison of the from-scratch and AR-initialization with LLaMA3.2 1B training on the Dream 1B models with 200B tokens. AR initialization also experiences a high loss at the beginning due to the transition from causal attention to full attention; however, this loss remains lower compared to training from scratch throughout the training.
Figure: loss comparison of the from-scratch and AR-initialization with LLaMA3.2 1B training on the Dream 1B models with 200B tokens. AR initialization also experiences a high loss at the beginning due to the transition from causal attention to full attention; however, this loss remains lower compared to training from scratch throughout the training. Dream 7B is finally initialized with weights from Qwen2.5 7B. During the training process, we find the learning rate to be especially important. If it’s set too high, it can quickly wash away the left-to-right knowledge in the initial weights, providing little help in the diffusion training, while if it’s set too low, it can hinder diffusion training. We meticulously selected this parameter along with the other training parameters.
Thanks to the existing left-to-right knowledge in the AR model, the diffusion model’s any-order learning can be accelerated, significantly reducing the tokens and computation required for pretraining.
Context-adaptive Token-level Noise Rescheduling
The selection of each token in a sequence depends on its context, yet we observed that previous diffusion training approaches fail to adequately account for this aspect. Specifically, in conventional discrete diffusion training, a timestep t is sampled to determine the sentence-level noise level, after which the model performs denoising. However, since the learning ultimately operates at the token level, the actual noise level for each token does not strictly align with t due to the application of discrete noise. This resulted in ineffective learning of tokens with varying levels of contextual information.
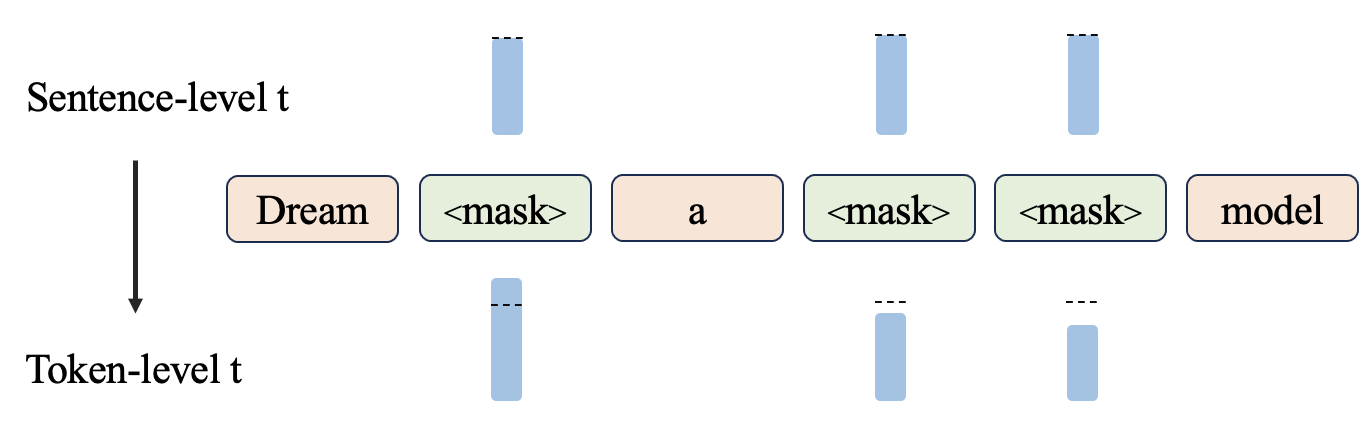 Figure: illustration of the context-adaptive token-level noise rescheduling mechanism. Dream re-decides a token-level timestep t for each mask token by measuring its context informationness.
Figure: illustration of the context-adaptive token-level noise rescheduling mechanism. Dream re-decides a token-level timestep t for each mask token by measuring its context informationness. To address this, we introduce a context-adaptive token-level noise rescheduling mechanism that dynamically reassigns the noise level for each token based on the corrupted context after noise injection. This mechanism provides more fine-grained and precise guidance for the learning process of individual tokens.
Planning Ability
In our previous work, we demonstrated that text diffusion exhibits superior planning capabilities in the small-scale, task-specific context. However, it remains uncertain whether a general, scaled diffusion model possesses similar abilities. Now, with Dream 7B, we can better answer this question.
We evaluated Dream on the Countdown and Sudoku tasks from , where we can flexibly control the planning difficulty. Our comparison included Dream 7B alongside LLaDA 8B, Qwen2.5 7B, and LLaMA3 8B, together with the latest Deepseek V3 671B (0324) for reference. All models were assessed in a few-shot setting without any training on these tasks.
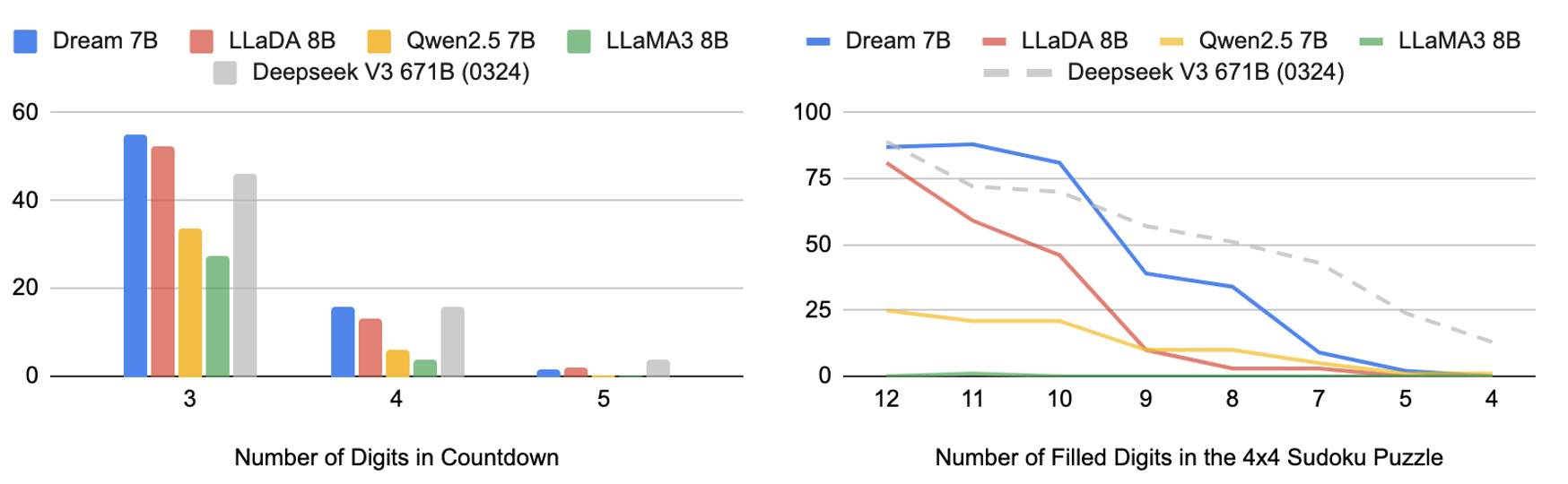 Figure: results on Countdown and Sudoku when varying planning difficulty.
Figure: results on Countdown and Sudoku when varying planning difficulty. It is evident that Dream outperforms other similar-sized baseline models. Remarkably, both diffusion models significantly surpass the two AR models and, at times, even the latest DeepSeek V3, despite its orders of magnitude more parameters. The intuition behind is that diffusion language models are more effective for solving problems with multiple constraints or for achieving specific objectives.
Here are some examples of Qwen 2.5 7B and Dream 7B in three planning tasks:
 Figure: generation examples from Qwen2.5 7B and Dream 7B.
Figure: generation examples from Qwen2.5 7B and Dream 7B. Inference Flexibility
Diffusion models offer more flexible inference compared to AR models in the following two main aspects.
Arbitrary Order
Diffusion models are not constrained to sequential (e.g., left-to-right) generation, enabling outputs to be synthesized in arbitrary orders—this allows for more diverse user queries.
- Completion
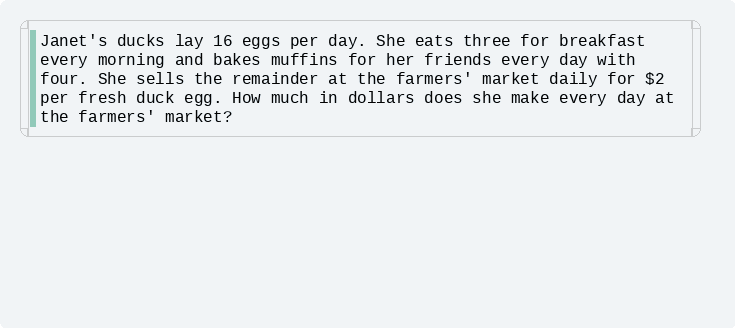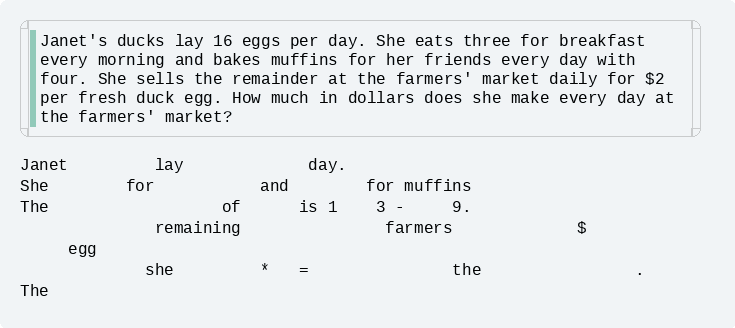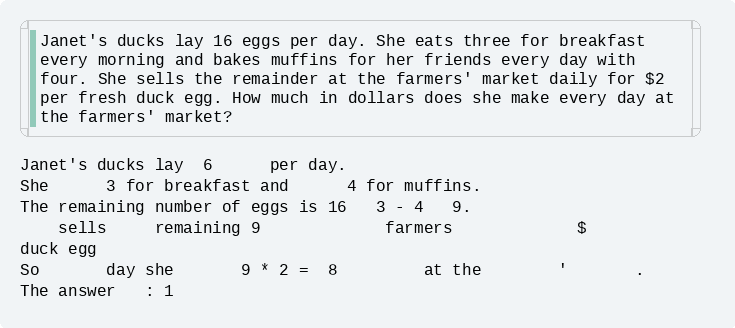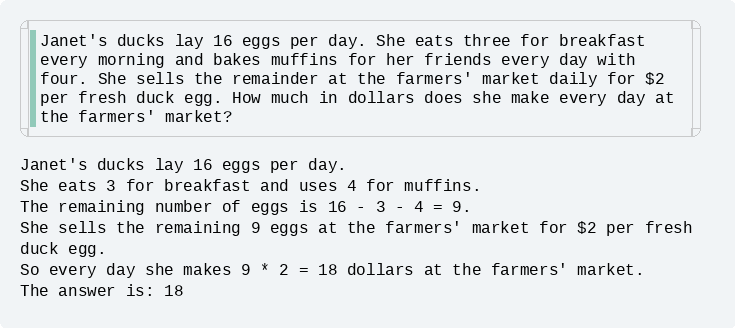 Figure: a completion example of Dream-7B-instruct.
Figure: a completion example of Dream-7B-instruct. - Infilling
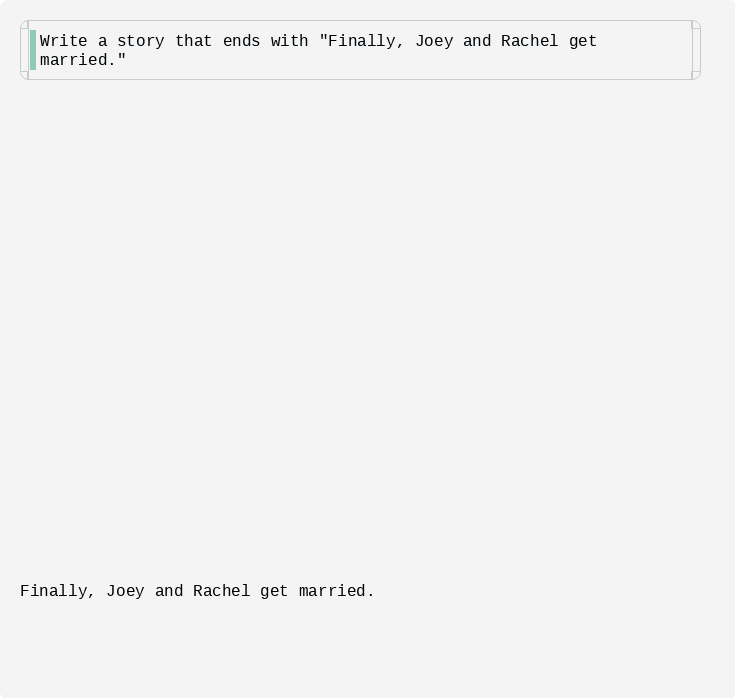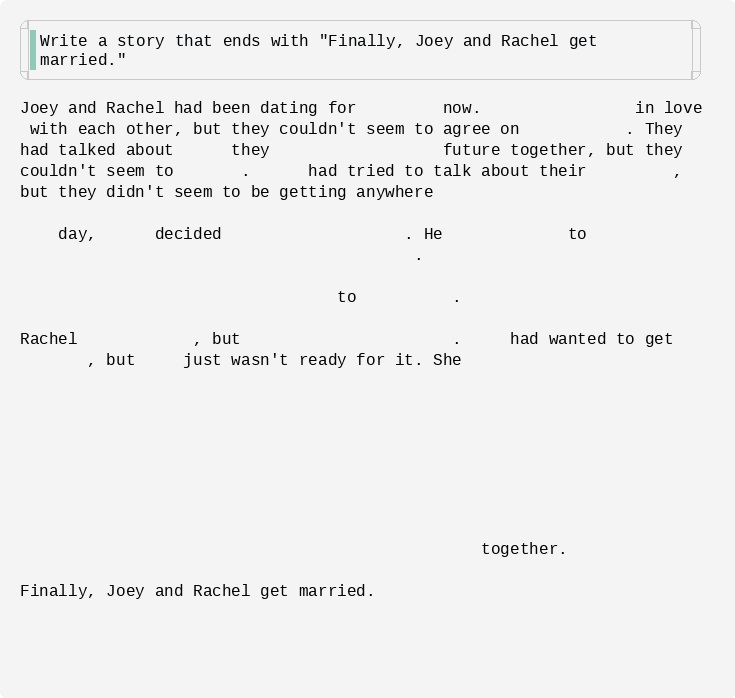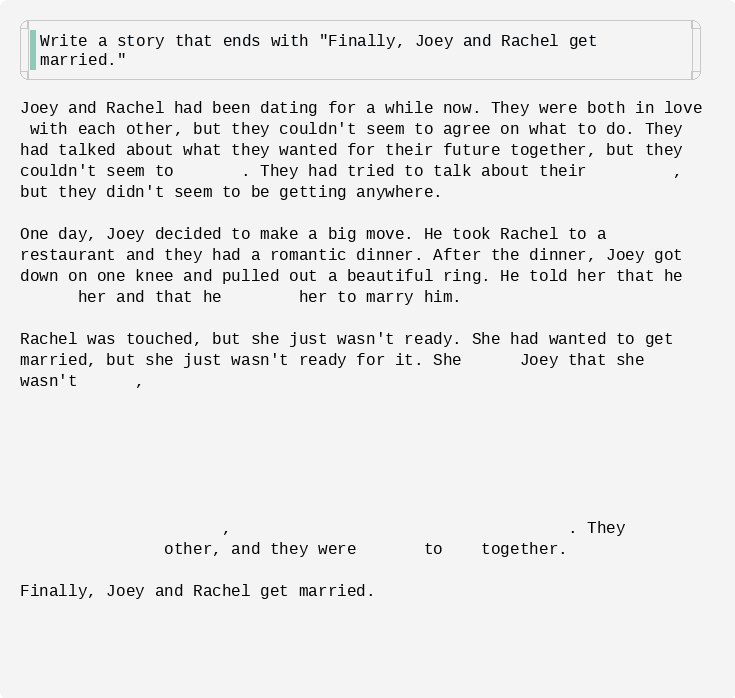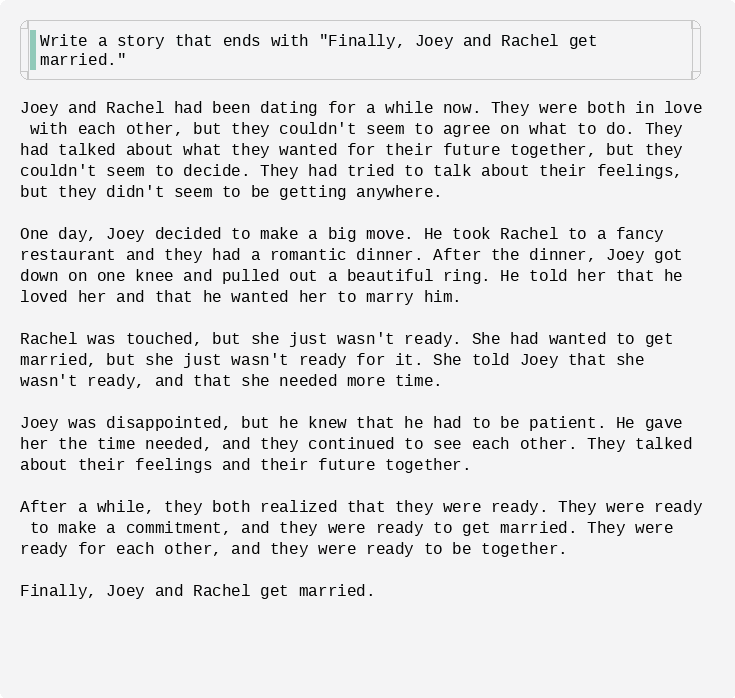 Figure: an infilling example of Dream-7B-instruct with an exact ending sentence.
Figure: an infilling example of Dream-7B-instruct with an exact ending sentence. -
Controlling the decoding behavior
Different queries may have preferences for the order in which the responses are generated. One can also adjust the decoding hyperparameters to control the decoding behavior, shifting it from more left-to-right like an AR model to more random-order generation.
Quality-speed Trade-off
In the above cases, we show one token is generated per step. However, the number of generated tokens per step (controlled by diffusion steps) can be adjusted dynamically, providing a tunable trade-off between speed and quality: fewer steps yield faster but coarser results, while more steps produce higher-quality outputs at greater computational cost. This introduces an additional dimension for inference-time scaling that complements rather than replaces techniques like long chain-of-thought reasoning employed in large language models such as o1 and r1. This adjustable computation-quality tradeoff represents a unique advantage over traditional AR frameworks.
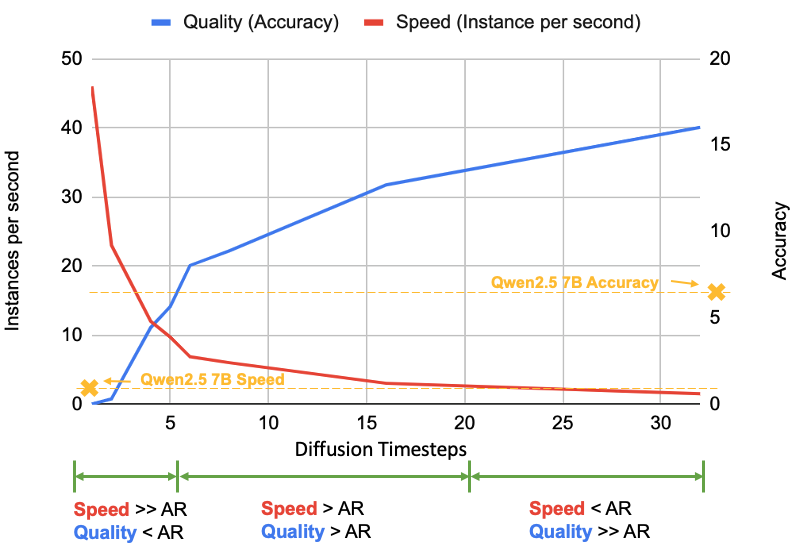 Figure: quality-speed comparison on the Countdown task for Dream 7B and Qwen2.5 7B. By adjusting the diffusion timesteps, the performance of Dream can be flexibly tuned for either speed or quality.
Figure: quality-speed comparison on the Countdown task for Dream 7B and Qwen2.5 7B. By adjusting the diffusion timesteps, the performance of Dream can be flexibly tuned for either speed or quality. Supervised Fine-tuning
As a preliminary step in post-training diffusion language models, we perform supervised fine-tuning to align Dream with user instructions. Specifically, we curate a dataset with 1.8M pairs from Tulu 3 and SmolLM2, fine-tuning Dream for three epochs. The results highlight Dream’s potential to match autoregressive models in performance. Looking forward, we plan to explore more advanced post-training recipes for diffusion language models.
 Figure: supervised fine-tuning results.
Figure: supervised fine-tuning results. Conclusion
We introduce Dream, a new family of efficient, scalable, and flexible diffusion language models with carefully selected training recipes. It performs comparably to the best autoregressive models of similar size in general, mathematical, and coding tasks while especially showcasing advanced planning abilities and flexible inference capabilities.



