.png)



Most of you have interacted with a large language model (LLM) by now, or what we call AI these days. They’ve come a long way from being seen as hallucinating, incompetent chatbots to useful tools to have today. You’re likely using an LLM from one of the Big 3 (OpenAI, Anthropic, Google), and a local LLM will likely not replace that either, but it does give you more options in privacy and control.
Local LLMs have historically lagged behind frontier models by a large extent, but OpenAI and Qwen releasing capable open-weight models makes the case that these are perfect for everyday tasks. This article serves to be accessible to as many people as possible on what’s the easiest way to run a local LLM, other options of doing so, and why you should do it in the first place.
But Why?
- Privacy, of course.
- Completely offline, unless you give access to internet via some MCP.
- Free? Besides the unnoticeable inference power cost.
- Possibly, a faster option than frontier LLMs.
- Use the local API in your favorite tools; VSCode etc.
- Ability to host the LLM for your whole local network.
- Can be fine-tuned for specific purposes.
- Accessible to everyone.
Requirements to self-host LLMs
Talk about accessible and requirements in the same breath, heh. Naturally, bigger models will require beefier setups, but there are still many capable models you can run well, depending on your system specs. The rule of thumb is that the model size should be less than your RAM, with plenty left for the system to not hang.
It’s not a requirement, but having a GPU is highly recommended so you can enjoy fast token generation (the text output you get) and a modern CPU for faster prompt processing. Mac users with an M-chipset and PC users with a dedicated GPU (Nvidia RTX especially) will benefit the most.
Good to know
You can skip this section if it feels too technical but these things are good to know in general:
- The G.O.A.T. for LLM inference is llama.cpp, an open-source project by Georgi Gerganov. The majority of local LLM tools are wrappers of this that deal with the initial config themselves.
- Local LLMs that we run on consumer machines are usually “quantized” from their original size. The original gpt-oss-20b requires 48 GB of RAM, but the quantized model we’ll use only needs 14.27 GB while giving similar performance.
- Quantization makes LLMs accessible for everyone, even if you don’t have a GPU, just run a model according to your specs. 4-bit precision models are the sweet spot and most tools will default to these.
- A quantized 4-bit 7b model will generally perform better than a 8-bit 3b model. The ‘b’ in these models stands for the billions of parameters used for training them.
- Since models suck at answering things they don’t have the data for, you’d want to run the model with the highest parameters you reasonably can for the best results.
Most tools will recommend what models you can run for your specs so you don’t need to worry too much about the technical jargon, default settings run just fine.
Popular options to run local LLMs
We have a lot of options available today but I’ll particularly talk about Ollama and LMStudio while briefly listing other options too.
Ollama
Ollama is a popular open-source choice with a simple and clean interface similar to ChatGPT. It’s how I and many others got into self-hosting LLMs before migrating to better tools. You install it, select a model from the drop-down, and boom, done.

After the model is downloaded, it will load itself while handling all the configurations in the backend. You’re ready to start talking to your very own locally hosted LLM with full privacy. This is especially useful if you get tired of redacting private information when talking to a frontier model by the Big 3.
The thing to like and hate about Ollama is its simplicity, it’s way too simple without any room for configurations unless you want to use it via CLI which defeats the point of this article. One QOL thing to particularly dislike is its inability to select which models appear in the dropdown.
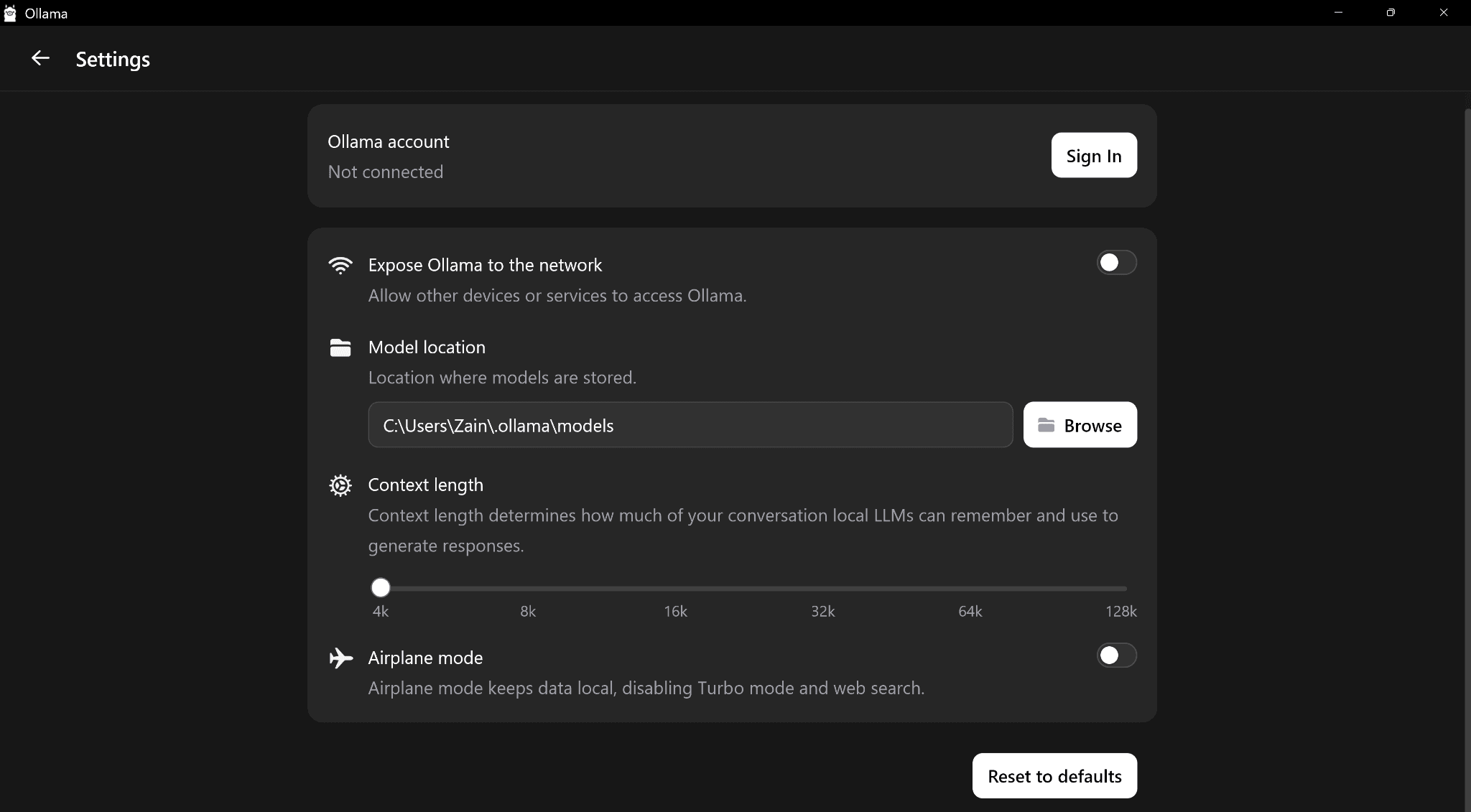
I also faced low token generation speed on Ollama compared to other tools but I’m sure this is a me-issue due to upgrading CPU while running the same old boot drive. Still, its interface leaves much to be desired but it’s understandable that they want to keep everything as simple as possible.
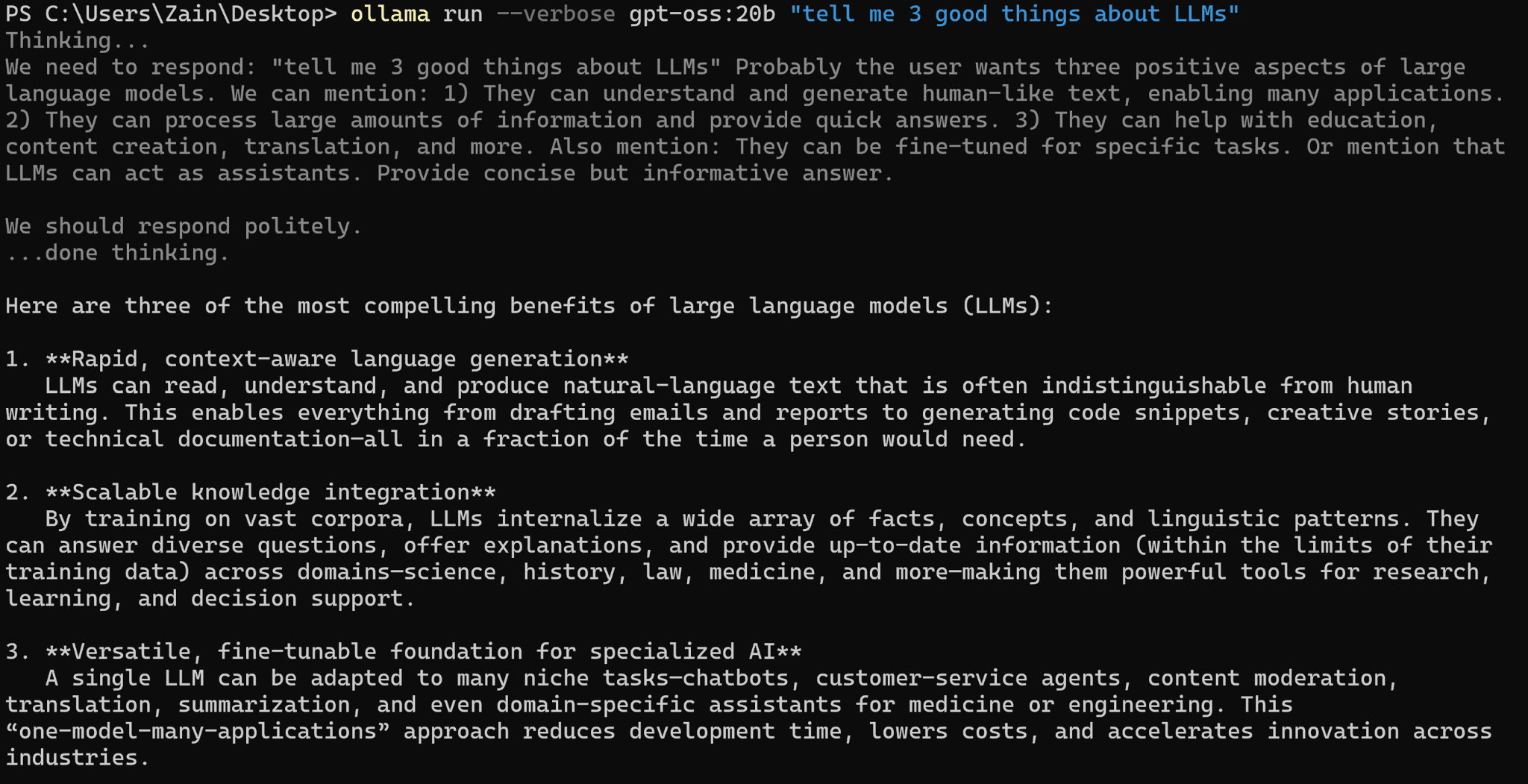
I had to use the CLI since the app doesn’t show the token speed but 35.77 tokens is like 27 words per second (my result with LMstudio is quadruple this). So this result is clearly wrong, I just haven’t been able to fix it with a reinstall, and don’t have the will to do either since other tools have a better interface.
You likely won’t have this issue, so I can recommend Ollama as a great, simple platform to get started with local LLMs. It’s open-source, so you can even build it yourself via Docker.
LMStudio
LMStudio is a much better way to run LLMs on your desktops with a rich interface and various QOL features for a chat interface. Similar to Ollama, it’s easy to set up. You install it, select a model to download, and you’re good to go.
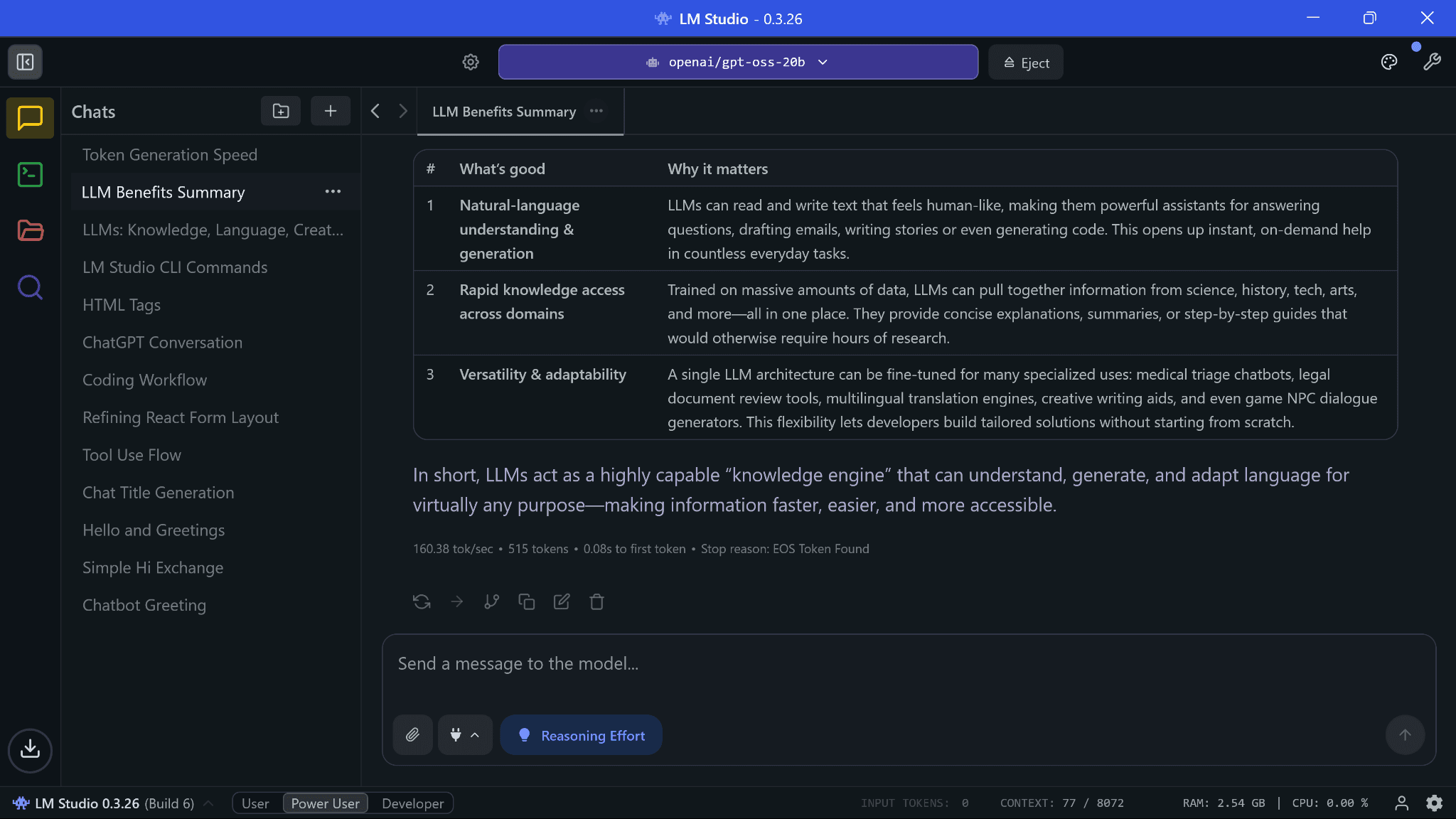
That token generation speed is insane; it’s faster than using Claude (via API), which is my daily driver. Claude is hugely popular, so it often returns server overload at peak times or takes more time than expected for simple requests. Considering that, this speed was a pleasant surprise but this does depend on your hardware.
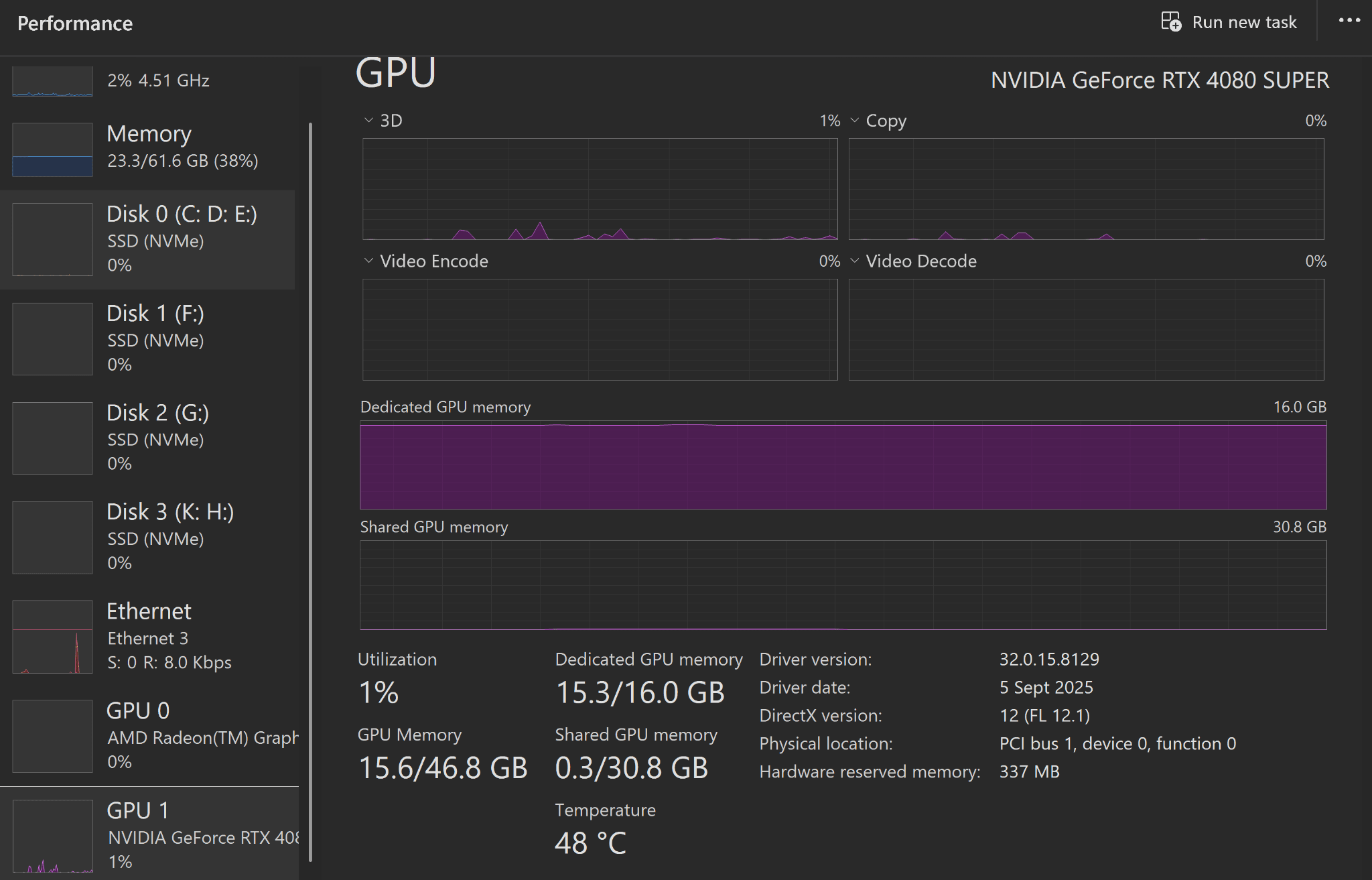
Another cool thing about self-hosting LLMs is that they’re not running any compute unless you use them. They’re loaded into memory but there’s no GPU usage besides the display output. But I have personally set LMStudio to eject the model if it’s unused for an hour so applications heavily reliant on GPU usage (video editing, Blender etc.) don’t crash.
Now, the possibly bad thing about LMStudio…it’s closed source. You would think that advocating for privacy, local LLMs, and then using a closed-source interface doesn’t make sense, and you would be partially right to think so. Thankfully, there are plenty of open-source LLM interfaces available now which I mention in the next section. They’re not as rich as LMStudio but if you want to go the extra mile of safety, they’re the best alternative.
I did look at what data LMStudio collects, and according to their privacy policy, it’s your system specs to provide accurate updates for runtimes and “anonymized” activity for how you use their model search. Nothing else, apparently. But for what it’s worth, there’s no network activity from LMStudio during chats until you open the model search so it does check out:
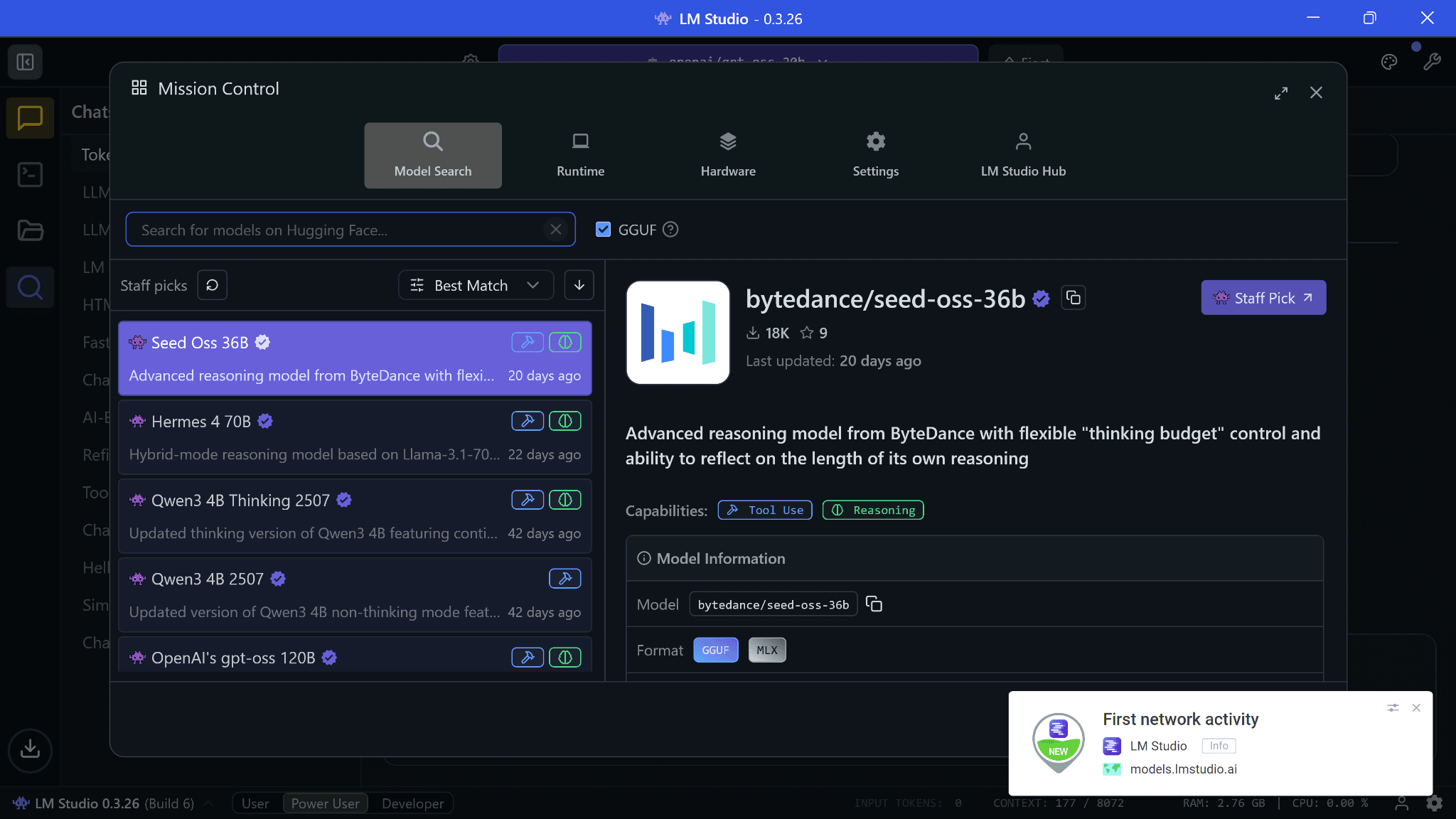
You can always disable internet access via firewall for LMStudio, but runtimes and models semi-regularly receive updates for optimizations so you may be missing out a bit. That said, I did use a packet sniffer and feel satisfied enough to recommend the app.
LMStudio by default tries to provide the best configuration without any chance of your system hanging but a little tip is that you want to have your GPU do the most work for the fastest outputs. Ideally, the model you select should fit whole in your GPU’s RAM so there’s no offloading to the CPU. Hence, max the GPU offload setting whenever possible.
Other options
If the above options don’t feel right, you still have many open-source alternatives. Some of these may require building the interface via Docker or having other prerequisites like Python, Node, etc.
- OpenWebUI with llama.cpp
- OpenWebUI with ollama
- GPT4ALL (76.7k stars)
- AnythingLLM (49k stars)
- LocalAI (35.4k stars)
- Koboldcpp (8.2k stars)
Recommended models
The easiest way to answer this is to download whatever models seem compatible to you. LMStudio by default shows quantized 4-bit versions of models your machine can run. Pick from any of them and you’ll be getting similar performance to the original model but with consumer hardware instead.
Look out for: GPT-oss from OpenAI, Gemma3 by Google, Qwen3 by AliBaba Cloud, Distilled models from DeepSeek, Magistral Small by Mistral, and Phi4 by Microsoft.
Task-specific models also exist: Qwen3-Coder, Devstral for coding, and Mathstral for STEM-related tasks. If there’s any task in your mind (searching, research, OCR, dealing with images etc.), a specific model for it likely exists already.
Those without GPUs can try out even smaller versions of bigger models like Gemma 3-1b or Gemma 3-4b, TinyLLama, Mistral 7b etc.
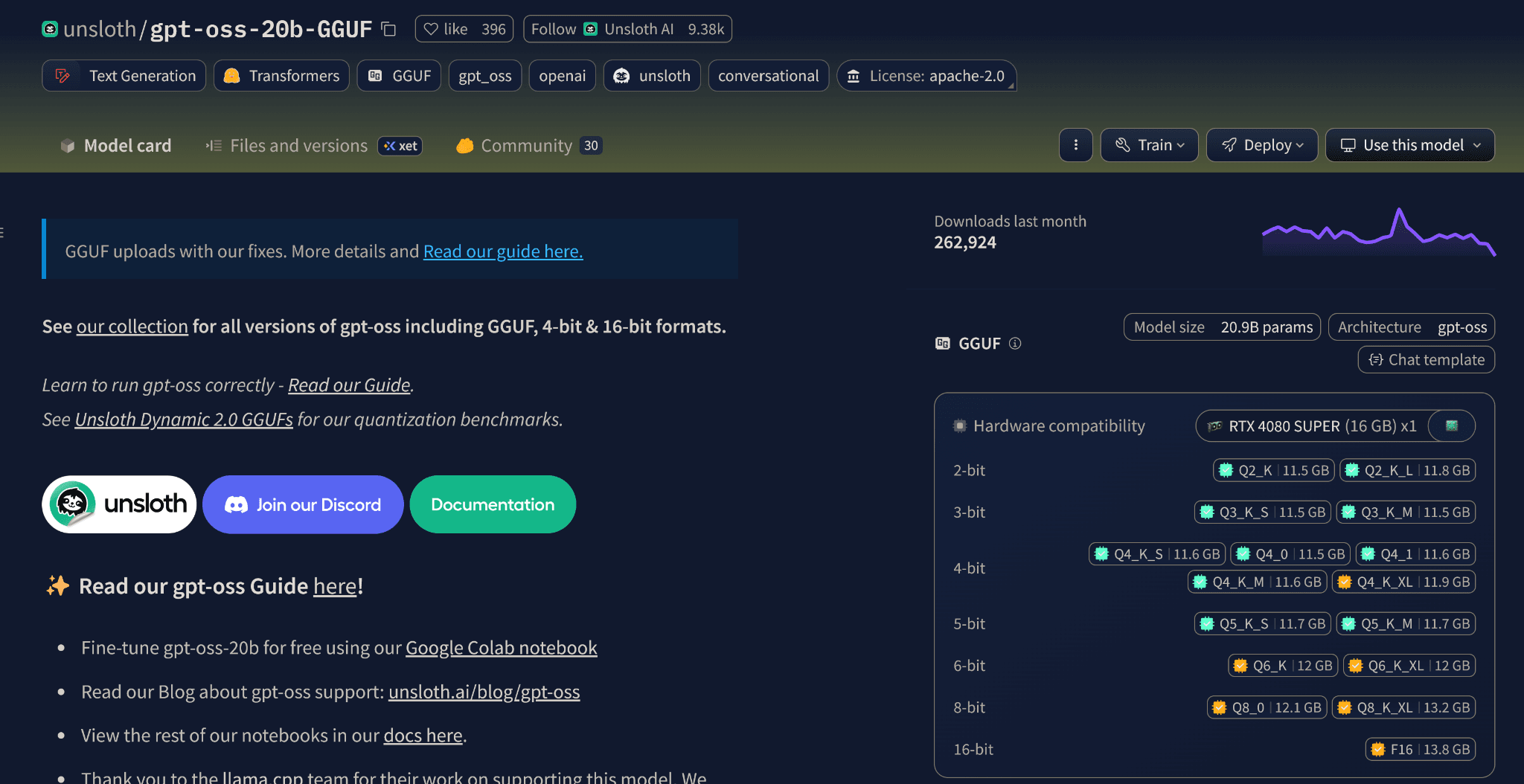
HuggingFace has an option to add your hardware details. After doing so, it highlights all the quantizations of that model you can likely run. Your goal should be to choose a model that your machine can comfortably run in "Q4_K_M" quantization, which offers a good balance of quality, speed, and size. If you want to know what these letters mean, this is a good article.
Conclusion
I’m hoping this proved a good introduction to start running local LLMs. I tried to keep things simple so everyone can have private access to their own locally-hosted LLM. If you enjoyed this, you may want to subscribe to our newsletter where I share trending articles and news in the developers and designers space. Here are some recent newsletters as of today’s publication date: [1], [2], [3].