.png)

The current discourse around AI progress and a supposed “bubble” reminds me a lot of the early weeks of the Covid-19 pandemic. Long after the timing and scale of the coming global pandemic was obvious from extrapolating the exponential trends, politicians, journalists and most public commentators kept treating it as a remote possibility or a localized phenomenon.
Something similarly bizarre is happening with AI capabilities and further progress. People notice that while AI can now write programs, design websites, etc, it still often makes mistakes or goes in a wrong direction, and then they somehow jump to the conclusion that AI will never be able to do these tasks at human levels, or will only have a minor impact. When just a few years ago, having AI do these things was complete science fiction! Or they see two consecutive model releases and don’t notice much difference in their conversations, and they conclude that AI is plateauing and scaling is over.
METR
Accurately evaluating AI progress is hard, and commonly requires a combination of both AI expertise and subject matter understanding. Fortunately, there are entire organizations like METR whose sole purpose is to study AI capabilities! We can turn to their recent study "Measuring AI Ability to Complete Long Tasks", which measures the length of software engineering tasks models can autonomously perform:
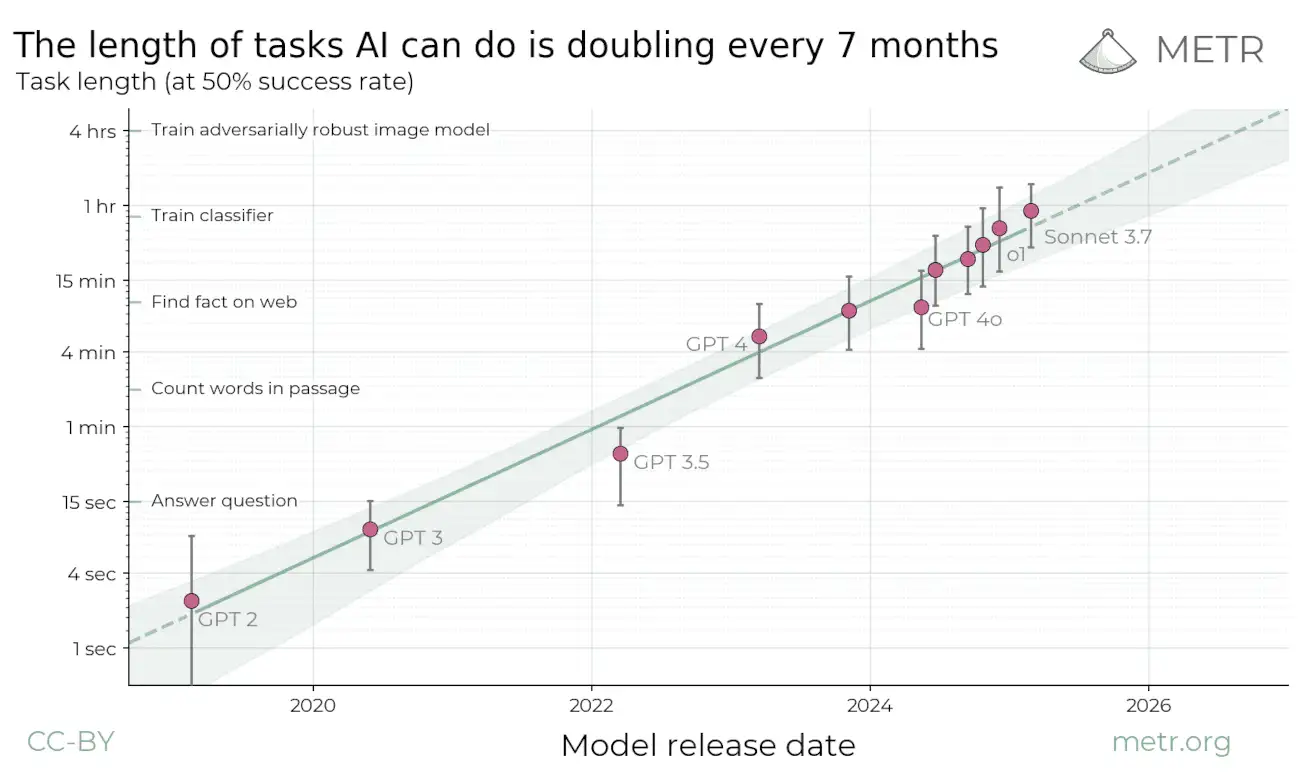
We can observe a clear exponential trend, with Sonnet 3.7 achieving the best performance by completing tasks up to an hour in length at 50% success rate.
However, at this point Sonnet 3.7 is 7 months old, coincidentally the same as the doubling rate claimed by METR in their study. Can we use this to verify if METR's findings hold up?
Yes! In fact, METR themselves keep an up-to-date plot on their study website:
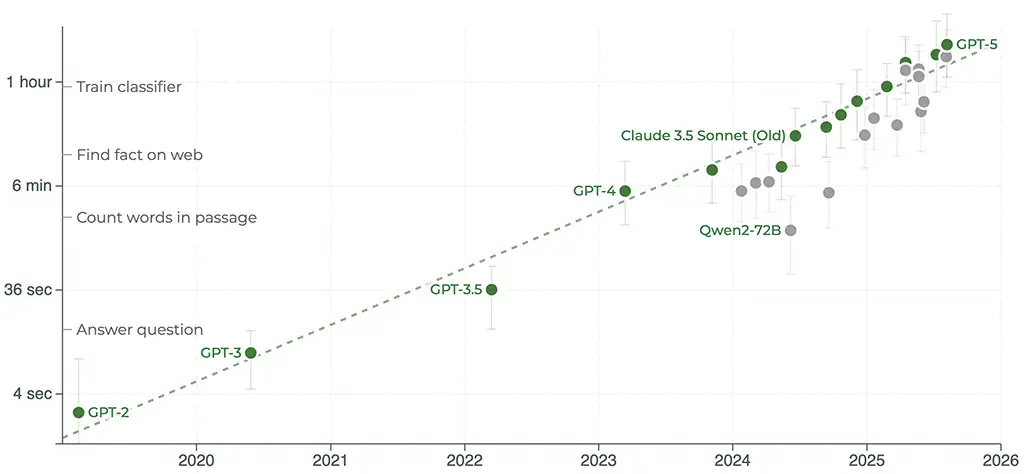
We can see the addition of recent models such as Grok 4, Opus 4.1, and GPT-5 at the top right of the graph. Not only did the prediction hold up, these recent models are actually slightly above trend, now performing tasks of more than 2 hours!
GDPval
A reasonable objection might be that we can't generalize from performance on software engineering tasks to the wider economy - after all, these are the tasks engineers at AI labs are bound to be most familiar with, creating some overfitting to the test set, so to speak.
Fortunately, we can turn to a different study, the recent GDPval by OpenAI - measuring model performance in 44 (!) occupations across 9 industries:

The evaluation tasks are sourced from experienced industry professionals (avg. 14 years' experience), 30 tasks per occupation for a total of 1320 tasks. Grading is performed by blinded comparison of human and model-generated solutions, allowing for both clear preferences and ties.
Again we can observe a similar trend, with the latest GPT-5 already astonishingly close to human performance:
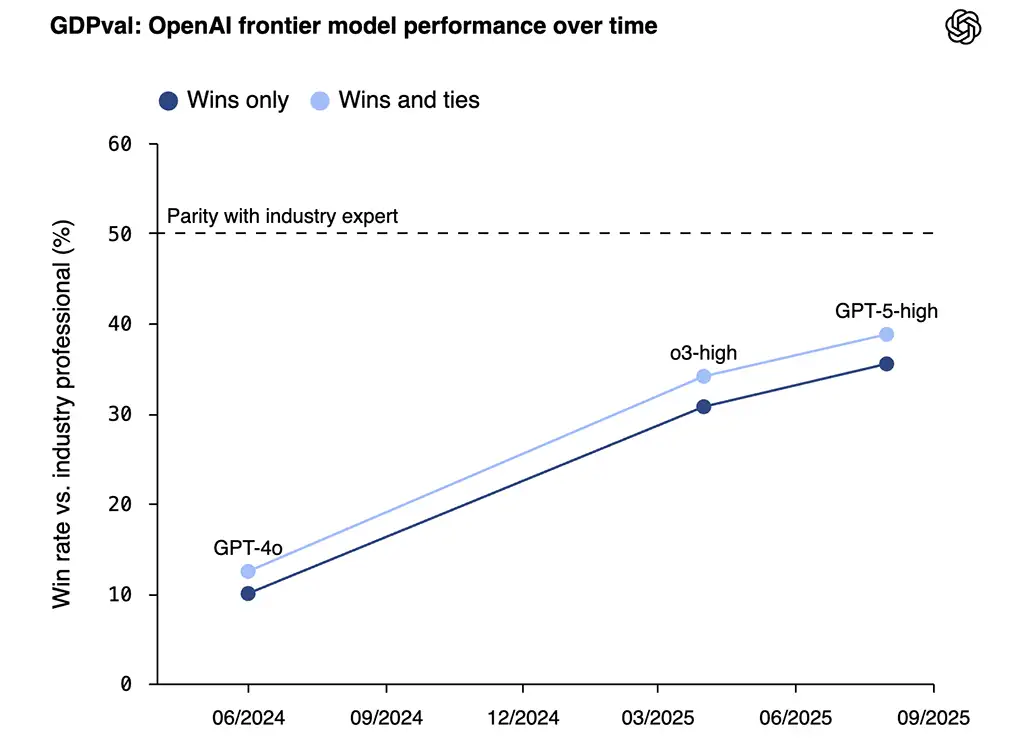
You might object that this plot looks like it might be levelling off, but this is probably mostly an artefact of GPT-5 being very consumer-focused. Fortunately for us, OpenAI also included other models in the evaluation, and we can see that Claude Opus 4.1 (released earlier than GPT-5) performs significantly better - ahead of the trend from the previous graph, and already almost matching industry expert (!) performance:
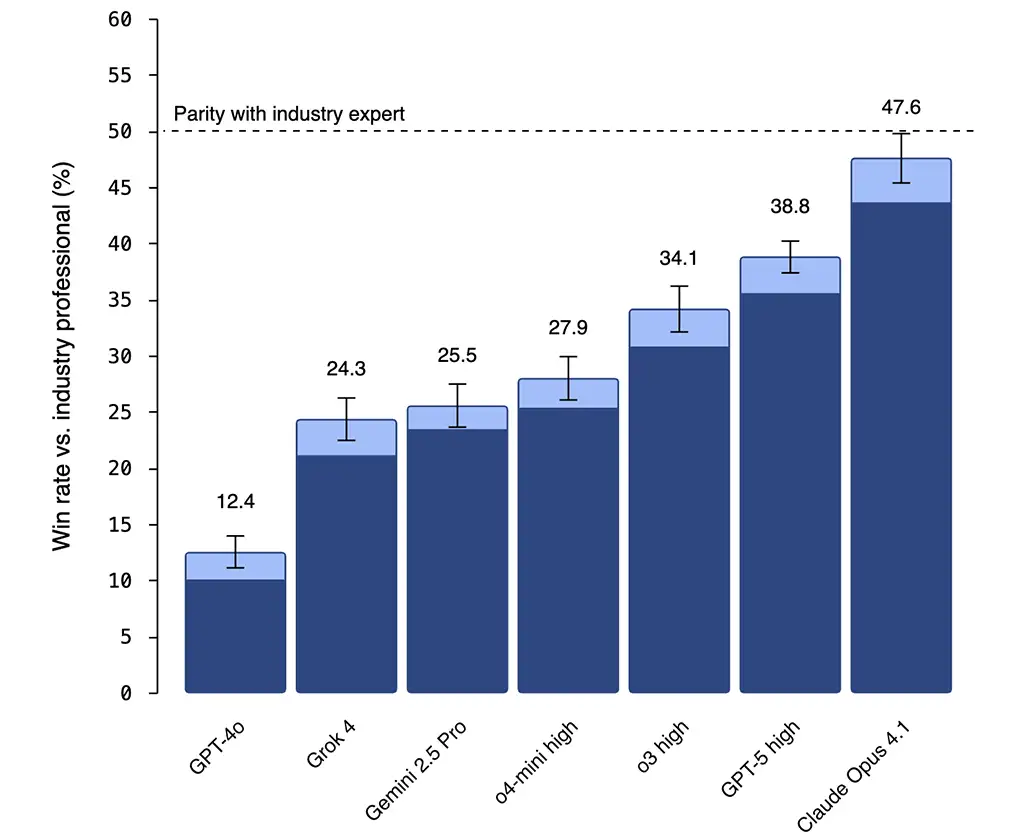
I want to especially commend OpenAI here for releasing an eval that shows a model from another lab outperforming their own model - this is a good sign of integrity and caring about beneficial AI outcomes!
Outlook
Given consistent trends of exponential performance improvements over many years and across many industries, it would be extremely surprising if these improvements suddenly stopped. Instead, even a relatively conservative extrapolation of these trends suggests that 2026 will be a pivotal year for the widespread integration of AI into the economy:
- Models will be able to autonomously work for full days (8 working hours) by mid-2026.
- At least one model will match the performance of human experts across many industries before the end of 2026.
- By the end of 2027, models will frequently outperform experts on many tasks.
It may sound overly simplistic, but making predictions by extrapolating straight lines on graphs is likely to give you a better model of the future than most "experts" - even better than most actual domain experts!
For a more concrete picture of what this future would look like I recommend Epoch AI's 2030 report and in particular the in-depth AI 2027 project.



