.png)

- 23 June 2025
- graphics
- kernel
- user experience
Introduction #
The DRM GPU scheduler is a shared Direct Rendering Manager (DRM) Linux Kernel level component used by a number of GPU drivers for managing job submissions from multiple rendering contexts to the hardware. Some of the basic functions it can provide are dependency resolving, timeout detection, and most importantly for this article, scheduling algorithms whose essential purpose is picking the next queued unit of work to execute once there is capacity on the GPU.
Different kernel drivers use the scheduler in slightly different ways - some simply need the dependency resolving and timeout detection part, while the actual scheduling happens in the proprietary firmware, while others rely on the scheduler’s algorithms for choosing what to run next. The latter ones is what the work described here is suggesting to improve.
More details about the other functionality provided by the scheduler, including some low level implementation details, are available in the generated kernel documentation repository.
Basic concepts and terminology #
Three DRM scheduler data structures (or objects) are relevant for this topic: the scheduler, scheduling entities and jobs.
First we have a scheduler itself, which usually corresponds with some hardware unit which can execute certain types of work. For example, the render engine can often be single hardware instance in a GPU and needs arbitration for multiple clients to be able to use it simultaneously.
Then there are scheduling entities, or in short entities, which broadly speaking correspond with userspace rendering contexts. Typically when an userspace client opens a render node, one such rendering context is created. Some drivers also allow userspace to create multiple contexts per open file.
Finally there are jobs which represent units of work submitted from userspace into the kernel. These are typically created as a result of userspace doing an ioctl(2) operation, which are specific to the driver in question.
Jobs are usually associated with entities and entities are then executed by schedulers. Each scheduler instance will have a list of runnable entities (entities with least one queued job) and when the GPU is available to execute something it will need to pick one of them.
Typically every userspace client will submit at least one such job per rendered frame and the desktop compositor may issue one or more to render the final screen image. Hence, on a busy graphical desktop, we can find dozens of active entities submitting multiple GPU jobs, sixty or more times per second.
The current scheduling algorithm #
In order to select the next entity to run, the scheduler defaults to the First In First Out (FIFO) mode of operation where selection criteria is the job submit time.
The FIFO algorithm in general has some well known disadvantages around the areas of fairness and latency, and also because selection criteria is based on job submit time, it couples the selection with the CPU scheduler, which is also not desirable because it creates an artifical coupling between different schedulers, different sets of tasks (CPU processes and GPU tasks), and different hardware blocks.
This is further amplified by the lack of guarantee that clients are submitting jobs with equal pacing (not all clients may be synchronised to the display refresh rate, or not all may be able to maintain it), the fact their per frame submissions may consist of unequal number of jobs, and last but not least the lack of preemption support. The latter is true both for the DRM scheduler itself, but also for many GPUs in their hardware capabilities.
Apart from uneven GPU time distribution, the end result of the FIFO algorithm picking the sub-optimal entity can be dropped frames and choppy rendering.
Round-robin backup algorithm #
Apart from the default FIFO scheduling algorithm, the scheduler also implements the round-robin (RR) strategy, which can be selected as an alternative at kernel boot time via a kernel argument. Round-robin, however, suffers from its own set of problems.
Whereas round-robin is typically considered a fair algorithm when used in systems with preemption support and ability to assign fixed execution quanta, in the context of GPU scheduling this fairness property does not hold. Here quanta are defined by userspace job submissions and, as mentioned before, the number of submitted jobs per rendered frame can also differ between different clients.
The final result can again be unfair distribution of GPU time and missed deadlines.
In fact, round-robin was the initial and only algorithm until FIFO was added to resolve some of these issue. More can be read in the relevant kernel commit.
Priority starvation issues #
Another issue in the current scheduler design are the priority queues and the strict priority order execution.
Priority queues serve the purpose of implementing support for entity priority, which usually maps to userspace constructs such as VK_EXT_global_priority and similar. If we look at the wording for this specific Vulkan extension, it is described like this:
The driver implementation *will attempt* to skew hardware resource allocation in favour of the higher-priority task. Therefore, higher-priority work *may retain similar* latency and throughput characteristics even if the system is congested with lower priority work.As emphasised, the wording is giving implementations leeway to not be entirely strict, while the current scheduler implementation only executes lower priorities when the higher priority queues are all empty. This over strictness can lead to complete starvation of the lower priorities.
Fair(er) algorithm #
To solve both the issue of the weak scheduling algorithm and the issue of priority starvation we tried an algorithm inspired by the Linux kernel’s original Completely Fair Scheduler (CFS).
With this algorithm the next entity to run will be the one with least virtual GPU time spent so far, where virtual GPU time is calculated from the the real GPU time scaled by a factor based on the entity priority.
Since the scheduler already manages a rbtree of entities, sorted by the job submit timestamp, we were able to simply replace that timestamp with the calculated virtual GPU time.
When an entity has nothing more to run it gets removed from the tree and we store the delta between its virtual GPU time and the top of the queue. And when the entity re-enters the tree with a fresh submission, this delta is used to give it a new relative position considering the current head of the queue.
Because the scheduler does not currently track GPU time spent per entity this is something that we needed to add to make this possible. It however did not pose a significant challenge, apart having a slight weakness with the up to date utilisation potentially lagging slightly behind the actual numbers due some DRM scheduler internal design choices. But that is a different and wider topic which is out of the intended scope for this write-up.
The virtual GPU time selection criteria largely decouples the scheduling decisions from job submission times, to an extent from submission patterns too, and allows for more fair GPU time distribution. With a caveat that it is still not entirely fair because, as mentioned before, neither the DRM scheduler nor many GPUs support preemption, which would be required for more fairness.
Solving the priority starvation #
Because priority is now consolidated into a single entity selection criteria we were also able to remove the per priority queues and eliminate priority based starvation. All entities are now in a single run queue, sorted by the virtual GPU time, and the relative distribution of GPU time between entities of different priorities is controlled by the scaling factor which converts the real GPU time into virtual GPU time.
Code base simplification #
Another benefit of being able to remove per priority run queues is a code base simplification. Going further than that, if we are able to establish that the fair scheduling algorithm has no regressions compared to FIFO and RR, we can also remove those two which further consolidates the scheduler. So far no regressions have indeed been identified.
Real world examples #
As an first example we set up three demanding graphical clients, one of which was set to run with low priority (VK_QUEUE_GLOBAL_PRIORITY_LOW_EXT).
One client is the Unigine Heaven benchmark which is simulating a game, while the other two are two instances of the deferredmultisampling Vulkan demo from Sascha Willems, modified to support running with the user specified global priority. Those two are simulating very heavy GPU load running simultaneouosly with the game.
All tests are run on a Valve Steam Deck OLED with an AMD integrated GPU.
First we try the current FIFO based scheduler and we monitor the GPU utilisation using the gputop tool. We can observe two things:
- That the distribution of GPU time between the normal priority clients is not equal.
- That the low priority client is not getting any GPU time.
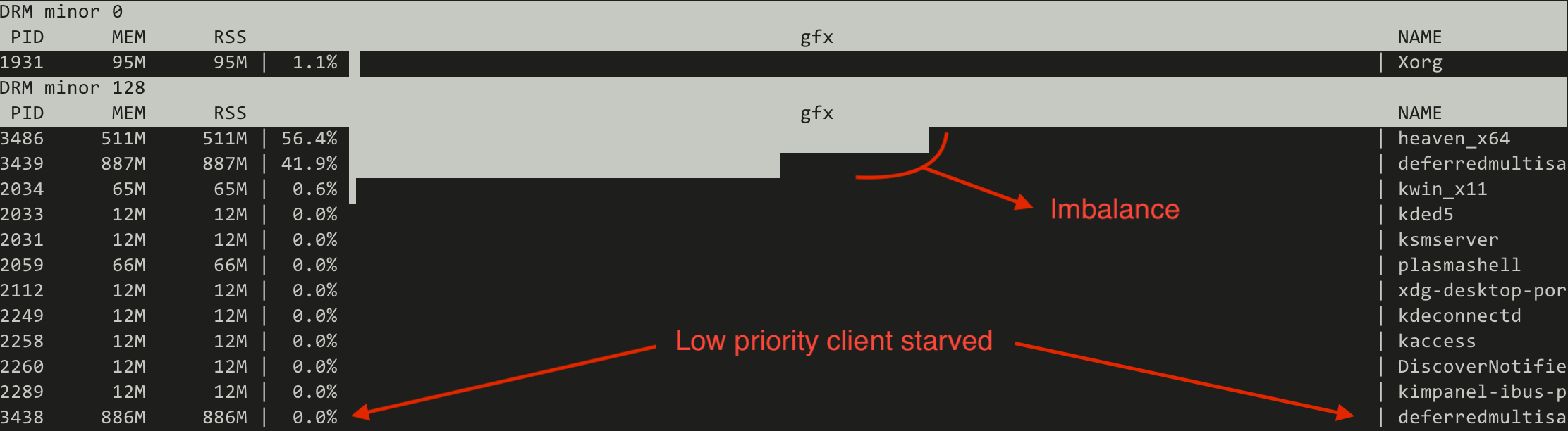
Switching to the CFS inspired (fair) scheduler the situation changes drastically:
- GPU time distribution between normal priority clients is much closer together.
- Low priority client is not starved, but receiving a small share of the GPU.

Note that the absolute numbers are not static but represent a trend.
This proves that the new algorithm can make the low priority useful for running heavy GPU tasks in the background, similar to what can be done on the CPU side of things using the nice(1) process priorities.
Synthetic tests #
Apart from experimenting with real world workloads, another functionality we implemented in the scope of this work is a collection of simulated workloads implemented as kernel unit tests based on the recently merged DRM scheduler mock scheduler unit test framework. The idea behind those is to make it easy for developers to check for scheduling regressions when modifying the code, without the need to set up sometimes complicated testing environments.
Let us look at a few examples on how the new scheduler compares with FIFO when using those simulated workloads.
First an easy, albeit exaggerated, illustration of priority starvation improvements.
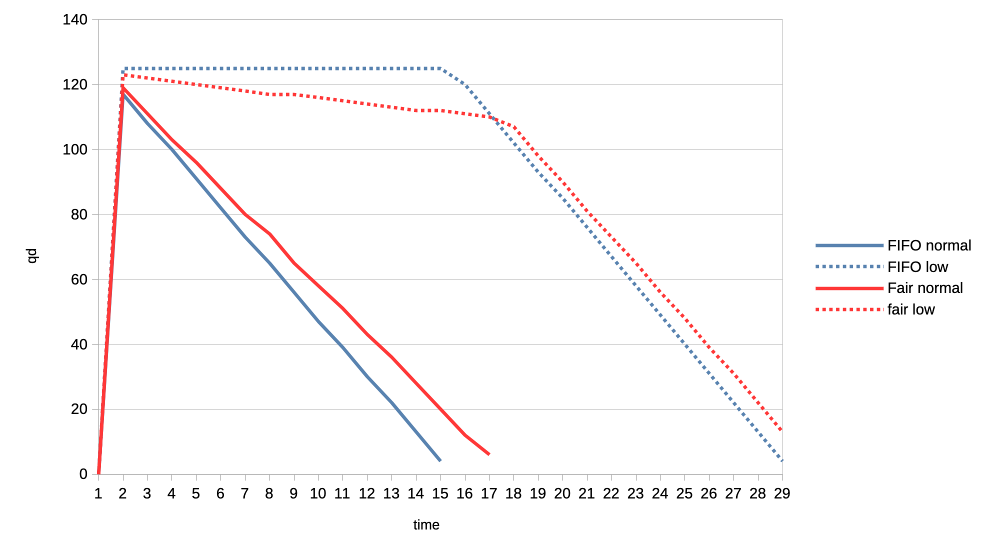
Here we have a normal priority client and a low priority client submitting many jobs asynchronously (only waiting for the submission to finish after having submitted the last job). We look at the number of outstanding jobs (queue depth - qd) on the Y axis and the passage of time on the X axis. With the FIFO scheduler (blue) we see that the low priority client is not making any progress whatsoever, all until the all submission of the normal client have been completed. Switching to the CFS inspired scheduler (red) this improves dramatically and we can see the low priority client making slow but steady progress from the start.
Second example is about fairness where two clients are of equal priority:
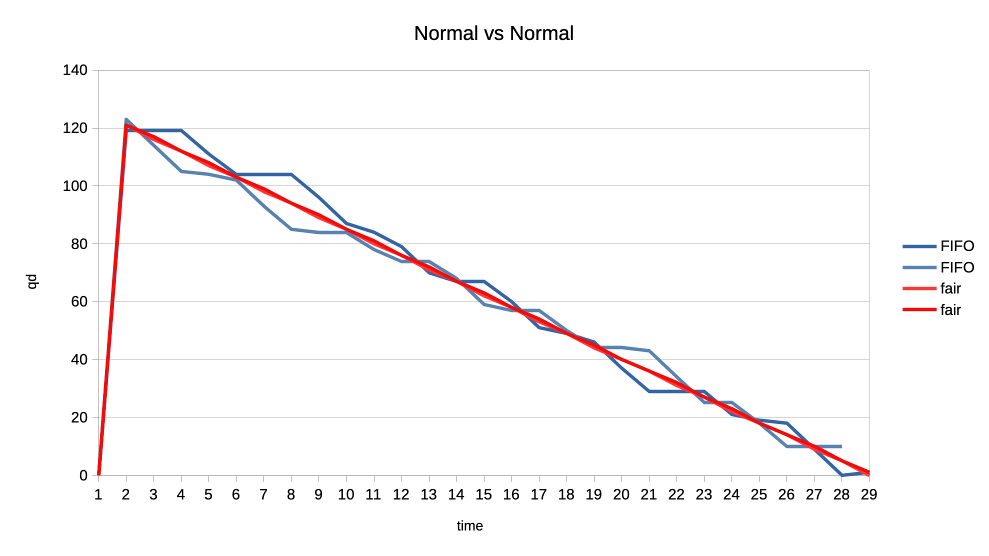
Here the interesting observation is that the new scheduler graphed lines are much more straight. This means that the GPU time distribution is more equal, or fair, because the selection criteria is decoupled from the job submission time but based on each client’s GPU time utilisation.
For the final set of test workloads we will look at the rate of progress (aka frames per second, or fps) between different clients.
In both cases we have one client representing a heavy graphical load, and one representing an interactive, lightweight client. They are running in parallel but we will only look at the interactive client in the graphs. Because the goal is to look at what frame rate the interactive client can achieve when competing for the GPU. In other words we use that as a proxy for assessing user experience of using the desktop while there is simultaneous heavy GPU usage from another client.
The interactive client is set up to spend 1ms of GPU time in every 10ms period, resulting in an effective GPU load of 10%.
First test is with a heavy client wanting to utilise 75% of the GPU by submitting three 2.5ms jobs back to back, repeating that cycle every 10ms.
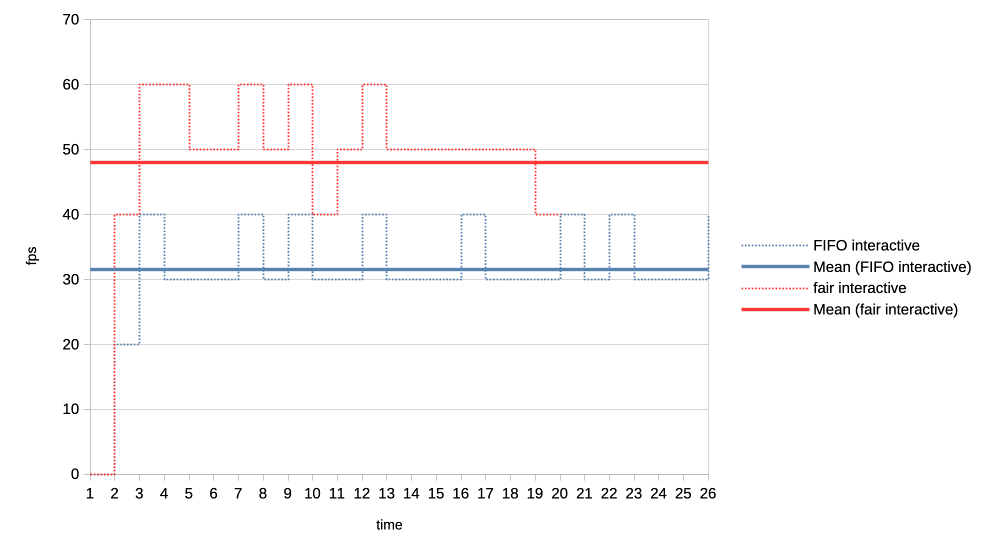
We can see that the average frame rate the interactive client achieves with the new scheduler is much higher than under the current FIFO algorithm.
For the second test we made the heavy GPU load client even more demanding by making it want to completely monopolise the GPU. It is now submitting four 50ms jobs back to back, and only backing off for 1us before repeating the loop.
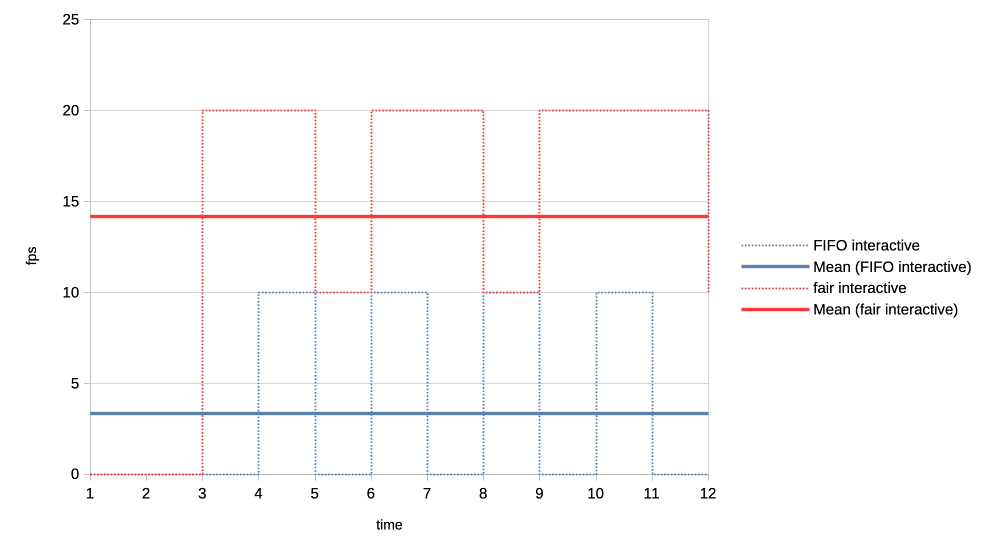
Again the new scheduler is able to give significantly more GPU time to the interactive client compared to what FIFO is able to do.
Conclusions #
From all the above it appears that the experiment was successful. We were able to simplify the code base, solve the priority starvation and improve scheduling fairness and GPU time allocation for interactive clients. No scheduling regressions have been identified to date.
The complete patch series implementing these changes is available at.
Potential for further refinements #
Because this work has simplified the scheduler code base and introduced entity GPU time tracking, it also opens up the possibilities for future experimenting with other modern algorithms. One example could be an EEVDF inspired scheduler, given that algorithm has recently improved upon the kernel’s CPU scheduler and is looking potentially promising for it is combining fairness and latency in one algorithm.
Connection with the DRM scheduling cgroup controller proposal #
Another interesting angle is that, as this work implements scheduling based on virtual GPU time, which as a reminder is calculated by scaling the real time by a factor based on entity priority, it can be tied really elegantly to the previously proposed DRM scheduling cgroup controller.
There we had group weights already which can now be used when scaling the virtual time and lead to a simple but effective cgroup controller. This has already been prototyped, but more on that in a following blog post.
References #
- Previous: DRM scheduling cgroup controller



