.png)

- Research
- Open access
- Published: 27 May 2025
Research Integrity and Peer Review volume 10, Article number: 8 (2025) Cite this article
-
594 Accesses
-
10 Altmetric
Abstract
Background
The proliferation of generative artificial intelligence (AI) has facilitated the creation and publication of fraudulent scientific articles, often in predatory journals. This study investigates the extent of AI-generated content in the Global International Journal of Innovative Research (GIJIR), where a fabricated article was falsely attributed to me.
Methods
The entire GIJIR website was crawled to collect article PDFs and metadata. Automated scripts were used to extract the number of probable in-text citations, DOIs, affiliations, and contact emails. A heuristic based on the number of in-text citations was employed to identify the probability of AI-generated content. A subset of articles was manually reviewed for AI indicators such as formulaic writing and missing empirical data. Turnitin’s AI detection tool was used as an additional indicator. The extracted data were compiled into a structured dataset, which was analyzed to examine human-authored and AI-generated articles.
Results
Of the 53 examined articles with the fewest in-text citations, at least 48 appeared to be AI-generated, while five showed signs of human involvement. Turnitin’s AI detection scores confirmed high probabilities of AI-generated content in most cases, with scores reaching 100% for multiple papers. The analysis also revealed fraudulent authorship attribution, with AI-generated articles falsely assigned to researchers from prestigious institutions. The journal appears to use AI-generated content both to inflate its standing through misattributed papers and to attract authors aiming to inflate their publication record.
Conclusions
The findings highlight the risks posed by AI-generated and misattributed research articles, which threaten the credibility of academic publishing. Ways to mitigate these issues include strengthening identity verification mechanisms for DOIs and ORCIDs, enhancing AI detection methods, and reforming research assessment practices. Without effective countermeasures, the unchecked growth of AI-generated content in scientific literature could severely undermine trust in scholarly communication.
Background
Generative artificial intelligence (AI), such as that offered by ChatGPT and Claude, is enabling unscrupulous publishers to generate and publish fake articles. In December 2023 an article titled “Global Business Strategies in the Digital Age” was published under my name and my primary affiliation in pp. 240–246 of the Global International Journal of Innovative Research (GIJIR), complete with a valid DOI (digital object identifier): https://doi.org/10.59613/global.v1i3.42. I became aware of the article when a colleague pointed it out to me, as it was neither created nor submitted by me. Its content is obviously AI-generated. The structure is formulaic, the claimed empirical evidence is missing, and the references, while real and influential, are not cited in the text. Furthermore, it contains several words that, according to an analysis by Stokel-Walker [1] and my experience, hint at AI-generated material: dynamic \(\times\) 4, explore \(\times\) 4, delve \(\times\) 3, leverage \(\times\) 2, intricate. Also, the Turnitin AI writing detection service reports a 100% AI generation score. (Although many generative AI detection services appear to have difficulty in detecting text generated by ChatGPT- 4.0, Turnitin has been reported to be generally accurate [2]). A few days after I discussed the article on X (formerly Twitter), I queried the Academia StackExchange forum, and I notified the other authors of GIJIR papers, the journal’s web pages were taken down causing the (temporary) disappearance of both fake and genuine research articles published in it. Currently, the journal is back online, only with the article misatributed to me removed. At the time of writing all DOIs are still registered, while the specific article’s landing page and PDF are also archived on the Internet Archive’s Wayback machine. The following sections present the methods and results of an explorative analysis of the GIJIR’s articles, an overview of the risks associated with the AI-generated papers, and an outline of possible ways to address them.
Methods
To obtain a better understanding of the GIJIR’s content and operations, the journal’s entire web site was downloaded, metadata from the article landing pages and PDFs were extracted, the obtained metadata were analyzed, and the text of a selected set of articles was examined manually. Also, potentially affected authors were notified to alert them regarding the possibility of their name’s fraudulent use and the journal’s questionable practices. The software developed for the analysis (Python, shell, and awk scripts) as well as the results tabulated in a Microsoft Excel document are made available in the supporting replication package [3].
Data were gathered on September 10th and 11th, 2024, on a computer running an Anaconda Python environment version 1.12.3 and Cygwin Bash version 5.2.15(3). The data extraction and transformation steps are illustrated in Fig. 1 as a UML (Unified Modelling Language) Activity Diagram. The journal site global-us.mellbaou.com was completely crawled with the wget command to obtain the article PDFs. Article metadata were retrieved separately using a Unix shell script get-metadata.sh. Citations and contact emails were extracted from the article PDF files with two separate scripts: extract-citations-emails.py and apply-to-pdfs.sh. Two other scripts (extract-doi-affiliations.py and extract-all-doi-affiliations.sh) were employed to extract article DOIs and author affiliations from the metadata HTML files. The two result sets were joined based on the journal’s article number key and used to create a first version of the article-details Microsoft Excel file. A list of contact author emails and URLs was created with the script emails-to-csv.awk, and then used to inform article authors regarding the findings.
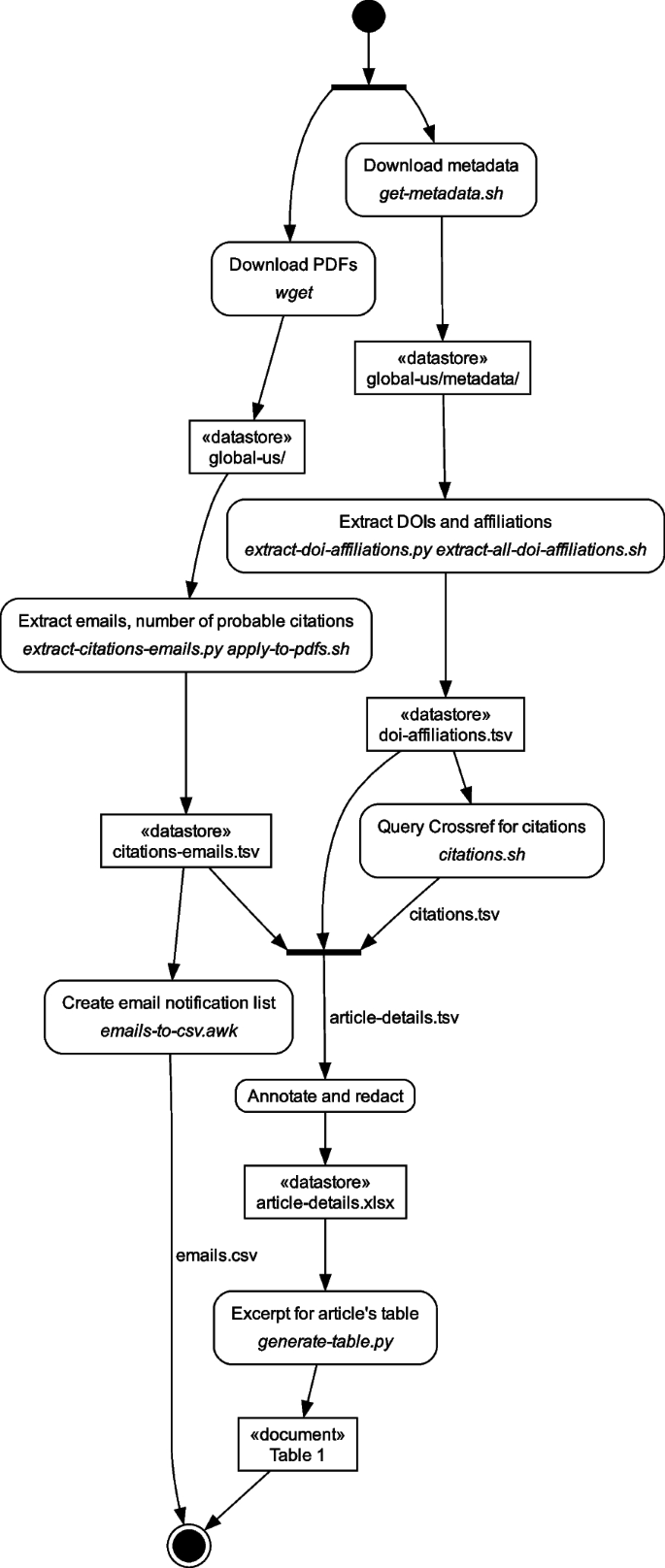
Data extraction and transformation steps
The journal seems to publish both AI-generated and humanauthored papers. A heuristic for identifying AI-generated articles similar to the one discovered involves tracking in-text bibliographic citations written in the journal’s author-date (APA) style, such as “(Ahmad Razak, 2012)” or “Rosli et al (2024)”, which appear in the (probably human-authored) article https://doi.org/10.59613/global.v2i6.187. In the GIJIR articles, a lack of in-text citations appears to be a strong indication of an AI-generated article. This is probably related to the difficulty ChatGPT has in generating correct citations [4]. Such citations can be detected by counting probable in-text citation delimiters (brackets and braces) appearing in the document before the article’s References section.
AI-generation was determined mainly through a manual examination of two sets of papers for corresponding signs. For the GIJIR journal these signs include formulaic content, as well as lack of empirical data, citations, tables, and figures. The first manually examined set consisted of the 53 papers (up to rank 50 in terms of the number of citation delimiters) with the fewest such delimiters. The second set consisted of ten papers at the bottom of the heuristic’s ranking. Furthermore, a systematically selected subset of these papers was submitted to the Turnitin web-based service for AI scoring on September 24th, 2024. This set comprised one paper in every ten from the first set and one paper every two from the second one (excluding one article that lacked a DOI).
The Microsoft Excel document provided in the replication package, was derived from the automatically generated article-details.tsv file by hand-curating it as follows.
-
1.
Four duplicate entries with wrongly extracted multiple contact emails were removed (articles 172 and 248).
-
2.
Contact emails were partially redacted to comply with personal data protection regulations.
-
3.
A subset of documents was examined manually and with Turnitin to determine AI content as detailed in the previous paragraphs.
-
4.
Email domains were extracted from emails and listed in a separate column.
-
5.
A column with undeliverable emails was added and hand-filled based on failed delivery reports regarding the sent notification emails. The “Y” designation was used for failed email deliveries due to faulty email addresses, and the “OOSS” was used for failures that occurred when a recipient’s mailbox had run out of storage space.
-
6.
Affiliations of authors of publications that were unlikely to have been submitted by them (mainly evidenced by wrong contact emails) were marked in bold.
-
7.
The web sites of the above authors were located with a Google search for their name and affiliation. These were visited to obtain their actual email address (for notifying them) and their academic status (for substantiating a lack of a motive for such a publication).
-
8.
Notes regarding email communications and other provenance details were added to document the preceding actions.
All articles are available in the replication package’s global-us/global-us.mellbaou.com/index.php/global/article/download folder. Individual articles can be located through the article number, which appears after the DOI’s last period. For example, https://doi.org/10.59613/global.v2i1.70 corresponds to article 70. The single folder appearing below the folder named after the article’s number contains a single numbered PDF file. The file lacks a.PDF suffix, so in popular user interfaces it cannot be opened by double-clicking on it. Instead, it can be dragged and dropped into a PDF reader or it can be opened explicitly from the viewer by allowing the selection of all file types.
Results
The GIJIR, where the fake article under my name was published, has a valid ISSN (International Standard Serial Number — 2994 - 8312), is indexed by Google Scholar, and its articles receive Crossref [5] DOIs. According to its publishers, it is an open access journal, but its ISSN does not appear in the Directory of Open Access Journals (DOAJ) [6]. The content of the articles published in it, its charging of a $500 article processing charge, and the fact that it has been accused of listing individuals as editorial board members without their consent [7], suggest that it is a predatory journal [8]. Crossref API (application programming interface) queries on the article’s DOI prefix (10.59613) and then the publisher’s Crossref member-id (39059) show that the GIJIR publisher is “Yayasan Banu Samsudin”, located in “Lombok Tengah, Nusa Tenggara Barat, Indonesia”. A further query through the Crossref API for works published with the same DOI prefix, shows that the publisher is behind eleven titles in total, including “The Journal of Academic Science”, “Journal of Knowledge and Collaboration”, and “Journal of Social Science and Education Research”.
Table 1 contains an excerpt of key analyzed articles. Articles are listed in the order of probable in-text citations. For each article the Table lists its in-text citation rank (ITC Rank), the number of detected in-text citations (ITC), the suffix of its DOI (DOI Suf. — all DOIs begin with “10.59613/global.”), the manual assessment of whether the article was AI generated (MAI — M stands for AI with probably manual interventions), the corresponding Turnitin score (TAI), the email address domain of the article’s (claimed) first author, and the corresponding affiliation.
The manual examination of the 53 papers with the fewest in-text citation delimiters shows at least 48 are probably mostly AI-generated, while another five show signs of human involvement. The five papers selected as one out every ten from the 53 ones and submitted to Turnitin received generative AI detection scores of 97%, 3 \(\times\) 100%, and 82%. At the bottom of the citation delimiters ranking, ten manually examined papers seem all to have been human authored. From that set of ten papers, one paper every two was also submitted to Turnitin, which gave to all a score of less than 20%. (Turnitin does not report exact scores lower than 20%.)
One can hypothesize that generative AI is used in the journal’s papers for two purposes, both helping the publisher profit from the real authors’ desire to publish in a scientific journal.
First, to create completely fake articles ostensibly by authors affiliated with well-known universities, probably to lend credence to the journal, as is also done with the bootlegging and rebranding of existing papers [9]. This is substantiated by the fact that the practice was prevalent at the journal’s launch. The first five published articles of volume 1 issue 1 (https://doi.org/10.59613/global.v1i1.1 to https://doi.org/10.59613/global.v1i1.5) are of this type. Furthermore, such articles were published only until volume 2 issue 1 (the last article appears to be https://doi.org/10.59613/global.v2i1.70). By that time the journal had published 52 out of its 220 articles. That the articles from well-known universities were not submitted by their authors is evidenced by wrong or Gmail contact emails and by at least two authors who had died several years before the articles under their name were published: Christodoulos A. Floudas [10] for https://doi.org/10.59613/global.v1i2.21 and Georges Guiochon [11] for https://doi.org/10.59613/global.v2i1.70. All authors in this category appear to be tenured professors, so there is also a lack of a motive to publish an article containing blatantly fake scientific research. The authors’ affiliations in this category include Washington University (with a Harvard author email address), Texas A&M, University of California at Berkeley, USC’s Keck School of Medicine, HEC Montreal, University of Shanghai, George Mason University School of Medicine, DePaul University, University of Alabama, Penn State, University of Tennessee, and Athens University of Economics and Business. The publication of wrong author emails was probably employed to reduce the chance of readers contacting the authors regarding those articles.
The second likely purpose for publishing AI-generated papers is to create publications for padding the CVs of their authors. In contrast to the articles of the first category, most of the author contact emails of these articles appear to be correct and accessible. Matching findings by Kurt [12] regarding predatory journal authors, many appear to be based in a developing world country and at least one seemed unaware of the journal’s nature. Specifically, the operation seems to be targeting or be used by Indonesian authors. Out of the 220 contact emails, apart from 113 Gmail addresses, 78 use the Indonesian academic domain “.ac.id”. Furthermore, according to one of the article authors who responded to the email notifications, the journal’s editors may be attracting authors with canned articles preemptively published by the editors, asking them to appear as a corresponding author.
Discussion
The creation and publication AI-generated scientific papers, as was done by the GIJIR, damages the scientific discourse in multiple ways. Consequently, publishers and the scientific community must find and deploy methods to limit such practices.
Problems from AI-generated papers
An understanding of the problems associated with the GIJIR’s practices is facilitated by dividing its articles into three categories, according to whether the article is AI-generated or not and whether the article was published by its named author or whether the article’s author was wrongly attributed. Thus, the categories are: misattributed AI-generated articles (e.g. https://doi.org/10.59613/global.v1i2.21), correctly attributed AI-generated articles (e.g. https://doi.org/10.59613/global.v1i2.12), and correctly attributed human-written articles (e.g. https://doi.org/10.59613/global.v2i9.283). Predatory journal articles in the last category have been extensively studied [13], so the corresponding risks will not be further elaborated.
For both types of machine-generated articles, generative AI [14] lowers the bar of producing them, making it easy to concoct entire articles in a few minutes, all for the price of a $20 subscription to ChatGPT or an equivalent service. In a simple experiment, a 67-word pair of prompts to ChatGPT (model 4o) asking for an article in one of the GIJIR’s many topics was all that was required to obtain a 1900-word article — of similar length to the one published under in GIJIR under my name. The prompts and responses are available in the supporting material and online. As the generated articles are not exact copies of others, they are difficult to identify with existing plagiarism detection tools based on text similarity, while automatically recognizing their AI provenance [2, 15] will likely become an uphill struggle as generative AI tools become more sophisticated and therefore produce output that will be increasingly difficult to detect.
Furthermore, machine-generated articles pollute the scientific communication landscape with trite platitudes, potentially incorrect facts [16], biased or discriminatory text ([17], p. 33), and often incorrect citations [18]. This material gets picked up by non-selective search engines, such as Google Scholar and can thus get cited in other publications. At least eight of the GIJIR’s journal’s articles have received a citation; an AI-generated article (https://doi.org/10.59613/global.v1i1.2) has been cited in conference proceedings published by Springer Nature [19]; more have been cited in what appear to be predatory venues. The openly available AI-generated papers may be even used for training future AI models, potentially leading to model collapses. This term refers to the finding [20] that haphazardly training LLMs (large language models) with LLM-generated content is an irreversible process that results in faulty models lacking the tails of the original content distribution.
In addition, for fraudulently attributed articles, the ease of their production means that they can be churned out in a large volume, without needing to resort to the more cumbersome method of populating fake journals by bootlegging and modifying existing material [9]. This will impede processes for detecting them and rooting them out. Moreover, because such articles are obviously AI-generated without appropriate acknowledgments and of an inferior quality, their authors and affiliated organizations suffer the reputational risk of appearing to publish drivel or to use generative AI in a fraudulent and unethical manner contrary to established policies ([17], p. 34). Adding insult to injury, if the articles get removed from the publication record, the authors will have the corresponding retractions associated with their names.
Fraudulently attributed articles can also damage their ostensible authors’ reputations. I became aware of the fake article when a colleague asked me to summarize it for our MBA’s promotional newsletter. His request was based only on the article’s enticing title and relevance to the programme. He found the article through a Google Scholar search; currently the article appears as the first result in a query for “Spinellis business”, as can be seen in the replication package’s file spinellis business - Google Scholar.pdf. The linked article is a copy appearing on the Semantic Scholar [21] web site, demonstrating the insidious entrenchment possibilities of such fake articles.
I replied to the colleague’s request pointing that the article was AI-generated drivel. Had the colleague read the article without realising it was misattributed to me, he might had drawn embarrassingly negative conclusions regarding my scientific integrity and abilities. Such a conclusion would not be hastily derived for me given my established research and publication record, which is known by my colleagues. However, academics at the beginning of their career applying to schools that do not know their work might not be similarly lucky.
Moreover, correctly attributed AI-generated articles can be employed en masse by unethical authors to inflate their publication record, saving them the trouble and expense of procuring them from a paper mill [22]. Also, through them unscrupulous editors can easily entice large populations of misinformed authors into adding their name to an existing publication targeted to their interests and paying for their publication. Once such articles are published, they mislead organizations that use them uncritically for hiring and promotion.
Finally, the confusing mix of the three article types under the roof of one journal impairs the investigation of scientific misconduct associated with such publications and provides plausible deniability regarding the journal’s credentials to the authors publishing through the predatory publisher.
The solution landscape
Addressing the problems introduced by the generative AI production of scientific works is not easy. Setting up guardrails in large language models [23] to prevent their use for such purposes is tricky, because the generation of corresponding manuscripts overlaps with the legitimate use case of aiding scientific research. Requiring model developers to release detection tools for their models’ generated text [15] is likely to be ineffective, due to the existence of open-source models that can be easily adjusted and run even on a laptop. These models also limit the applicability of any future guardrails. It will be more effective to address the two uses of AI-generated articles through a correspondingly targeted double pronged approach.
Fraudulently attributed articles can be limited through technical means by tightening the DOI and ORCID (Open Researcher and Contributor ID) processes. Such tightened processes could be implemented across the board or, alternatively, the subset of identifiers obtained under a stricter regime could be enhanced with visible “verified provenance” attributes. In brief, the tightened processes could help ensure that ORCIDs are issued exclusively to individuals whose identity has been reliably confirmed, that only the authors associated with an ORCID can bind a paper’s DOI to them, and that ORCID affiliations are indeed genuine.
The association of ORCIDs with real (reliably identified) persons can be enforced through the use of identity verification services. The secure binding between article DOIs and author ORCIDs can be implemented through ORCID’s authentication and authorization mechanisms [24] in conjunction with digital signatures and certificates associated with the author’s ORCID and tied to the paper’s DOI. For example, when authors submit a paper, the publisher may require them to use their ORCID credentials to authorize the binding of the paper’s DOI to their ORCID.
The secure association of affiliations with author ORCIDs can be implemented through a small extension to the Research Organization Registry (ROR) that will allow organizations to securely vouch for author affiliations. This can be done e.g. through machine-readable lists or policy statements placed on the organizations’ primary web site or through records signed with keys made available via the internet’s Domain Name System (DNS), as is the case with DKIM (DomainKeys Identified Mail) email signatures [25]. The implementation of such a scheme will require the cooperation of publishers, research organizations, and diverse registrars. While this is a challenging task, there is precedent for success, as demonstrated by the research community’s widespread adoption of ORCIDs, DOIs, and ROR identifiers. This has been based on the cooperation of publishers with ORICD and DOI registrars and of research organizations with the ROR registrar.
Limiting the publication of correctly attributed AI-generated articles is more difficult. The problems and their possible solutions overlap with those of paper mills — networks that sell to researchers authorships and low quality manuscripts [26]. Despite the ease with which AI can generate content that at a superficial level looks like a scientific research manuscript, I believe that paper mills will continue to exist offering additional services that unscrupulous individual authors who are not specialized in the dark arts of fake research production cannot easily match: fake raw data, tables, images, charts, peer reviews, and citations. Solutions for addressing the problem include closer examination of the articles’ raw data and images [27], increasing the journals’ transparency regarding the peer review process [9], collaborating to understand and battle paper mills [28], and steering the assessments for hiring, promoting, and funding researchers away from paper-counting toward evaluating the content of the performed research [29,30,31]. Adopting more substantive research assessment methods may be difficult [32], especially in settings where there is a lack of the required knowledge, trust, and social capital. In such cases mature universities, research centers, and learned societies can help by organizing and disseminating the required know-how, for the benefit of humanity.
Limitations
The study’s identification of AI-generated papers relies on heuristic methods, such as the absence of in-text citations, manual assessment regarding the absence of empirical data and similar signs, as well as the opaque models employed by Turnitin. All these may lead to false positives or negatives. Additionally, the classification of articles involves subjective human judgment, introducing potential bias and inconsistency. The analysis is based on a non-random subset of articles (those with the fewest and most probable citations), which may not fully represent the entire journal’s content. While the output of all automated processes was manually examined for errors, faults in the employed programs cannot be entirely ruled out. Furthermore, the investigation is limited to a single journal (GIJIR), leaving open the question regarding the extent to which similar patterns occur across other predatory or fraudulent journals. While a replication package is provided, the combination of manual data curation and subjective assessments may hinder others to fully reproduce the findings, while changes to Turnitin functionality and the journal’s website could further challenge future verification efforts.
Conclusion
The study presents an alarming case of AI-generated and fraudulently misattributed articles in the GIJIR. The case demonstrates how the fraudulent use of generative AI undermines scientific integrity and discourse. The analysis of GIJIR’s content, uncovered systematic patterns of deception, where AI-generated articles are either falsely attributed to reputable scholars to boost the journal’s standing or published by authors to artificially inflate their publication records. Addressing the problem will require a multi-faceted approach, including stricter identity verification for authors, enhanced detection of AI-generated content, peer review transparency, and shifts in research evaluation practices to focus on evaluating actual scientific contribution rather than quantitative metrics. Without proactive measures, the unchecked proliferation of AI-generated research content could erode trust in scholarly publishing, damage reputations, mislead institutions, and ultimately degrade the credibility of scientific discourse. Future work can systematically examine the extent of the described practices and also explore the working context and motivations of authors engaging in them.
Data availability
The datasets generated and analysed during the current study are available in the Zenodo repository, https://doi.org/10.5281/zenodo.13745075.
Abbreviations
Artificial intelligence
APA:American Psychological Association
API:Application programming interface
DKIM:DomainKeys Identified Mail
DNS:Domain Name System
DOAJ:Directory of Open Access Journals
DOI:Digital object identifier
GIJIR:Global International Journal of Innovative Research
ISSN:International Standard Serial Number
LLM:Large language model
ORCID:Open Researcher and Contributor ID
ROR:Research Organization Registry
UML:Unified Modelling Language
References
Stokel-Walker C. Chatbot Invasion. Sci Am. 2024;331(1):16. https://doi.org/10.1038/scientificamerican072024-7bvpuvjnkzbj8iqrkgmtlr.
Walters WH. The Effectiveness of Software Designed to Detect AI-Generated Writing: A Comparison of 16 AI Text Detectors. Open Inf Sci. 2023;7(1). https://doi.org/10.1515/opis-2022-0158.
Spinellis D. False Authorship Methods and Materials Package. 2024. https://doi.org/10.5281/zenodo.13745075.
Walters WH, Wilder EI. Fabrication and Errors in the Bibliographic Citations Generated by ChatGPT. Sci Rep. 2023;13(1). https://doi.org/10.1038/s41598-023-41032-5.
Lammey R. CrossRef Text and Data Mining Services. Insights UKSG J. 2015;28(2):62–8. https://doi.org/10.1629/uksg.233.
Morrison H. Directory of Open Access Journals (DOAJ). Charleston Advis. 2017;18(3):25–8.
Hacioglu U. Unmasking Deception: Exposing the Predatory Practices of the “Global International Journal of Innovative Research”. Int J Bus Ecosyst Strateg. 2023;5(4). https://doi.org/10.36096/ijbes.v5i4.469.
Beall J. Predatory Publishers are Corrupting Open Access. Nature. 2012;489(7415):179. https://doi.org/10.1038/489179a.
Siler K, Vincent-Lamarre P, Sugimoto CR, Lariviére V. Predatory Publishers’ Latest Scam: Bootlegged and Rebranded Papers. Nature. 2021;598(7882):563–5. https://doi.org/10.1038/d41586-021-02906-8.
Sammons J, Christodoulos A. Floudas Obituary. Chem Eng News. 2016;94(34):40.
Adlard ER. In Memoriam: Professor Georges Guiochon (Sept 6th 1931-Oct 21st 2014). Chromatographia. 2014;78(1–2):1. https://doi.org/10.1007/s10337-014-2810-x.
Kurt S. Why do Authors Publish in Predatory Journals? Learned Publ. 2018;31(2):141–7. https://doi.org/10.1002/leap.1150.
Mertkan S, Onurkan Aliusta G, Suphi N. Knowledge Production on Predatory Publishing: A Systematic Review. Learned Publ. 2021;34(3):407–13. https://doi.org/10.1002/leap.1380.
Stokel-Walker C, Van Noorden R. What ChatGPT and Generative AI Mean for Science. Nature. 2023;614(7947):214–6. https://doi.org/10.1038/d41586-023-00340-6.
Knott A, Pedreschi D, Chatila R, Chakraborti T, Leavy S, Baeza-Yates R, et al. Generative AI Models Should Include Detection Mechanisms as a Condition for Public Release. Ethics Inf Technol. 2023;25(4). https://doi.org/10.1007/s10676-023-09728-4.
Ji Z, Lee N, Frieske R, Yu T, Su D, Xu Y, et al. Survey of Hallucination in Natural Language Generation. ACM Comput Surv. 2023;55(12):1–38. https://doi.org/10.1145/3571730.
Dwivedi YK, Kshetri N, Hughes L, Slade EL, Jeyaraj A, Kar AK, et al. Opinion Paper: “So what if ChatGPT wrote it?’’ Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. Int J Inf Manag. 2023;71:102642. https://doi.org/10.1016/j.ijinfomgt.2023.102642.
Mugaanyi J, Cai L, Cheng S, Lu C, Huang J. Evaluation of Large Language Model Performance and Reliability for Citations and References in Scholarly Writing: Cross-Disciplinary Study. J Med Internet Res. 2024;26:e52935. https://doi.org/10.2196/52935.
Idowu A. The Unequal World of Migrant Domestic Workers in the Middle East: The Paradoxical Role of Technology. In: Chigona W, Kabanda S, Seymour LF, editors. In International Conference on Implications of Information and Digital Technologies for Development. ICT4D 2024. IFIP Advances in Information and Communication Technology, vol 708. Cham: Springer Nature Switzerland; 2024. pp. 152–66.
Shumailov I, Shumaylov Z, Zhao Y, Papernot N, Anderson R, Gal Y. AI Models Collapse when Trained on Recursively Generated Data. Nature. 2024;631(8022):755–9. https://doi.org/10.1038/s41586-024-07566-y.
Fricke S. Semantic Scholar. J Med Libr Assoc. 2018;106(1). https://doi.org/10.5195/jmla.2018.280.
Else H, Van Noorden R. The Fight Against Fake-Paper Factories that Churn out Sham Science. Nature. 2021;591(7851):516–9. https://doi.org/10.1038/d41586-021-00733-5.
Rebedea T, Dinu R, Sreedhar MN, Parisien C, Cohen J. NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Kerrville: Association for Computational Linguistics; 2023. pp. 431–45.
Lopez J, Oppliger R, Pernul G. Authentication and Authorization Infrastructures (AAIs): A Comparative Survey. Comput Secur. 2004;23(7):578–90. https://doi.org/10.1016/j.cose.2004.06.013.
Allman E, Callas J, Delany M, Libbey M, Fenton J, Thomas M. DomainKeys Identified Mail (DKIM) Signatures. 2007. 4871. http://www.ietf.org/rfc/rfc4871.txt. Accessed 1 Oct 2024.
Abalkina A, Aquarius R, Bik E, Bimler D, Bishop D, Byrne J, et al. ‘Stamp out Paper Mills’ - Science Sleuths on how to Fight Fake Research. Nature. 2025;637(8048):1047–50. https://doi.org/10.1038/d41586-025-00212-1.
Christopher J. The Raw Truth About Paper Mills. FEBS Lett. 2021;595(13):1751–7. https://doi.org/10.1002/1873-3468.14143.
Sanderson K. Science’s fake-paper Problem: High-Profile Effort will Tackle Paper Mills. Nature. 2024;626(7997):17–8. https://doi.org/10.1038/d41586-024-00159-9.
DORA Signatories. San Francisco Declaration on Research Assessment. 2012. https://sfdora.org/read/. Accessed 22 Sep 2024.
Schmid SL. Five Years Post-DORA: Promoting Best Practices for Research Assessment. Mol Biol Cell. 2017;28(22):2941–4. https://doi.org/10.1091/mbc.e17-08-0534.
European University Association. European University Association CoARA Action Plan (2023–2027). 2024. https://doi.org/10.5281/zenodo.13969869.
Hatch A, Curry S. Changing how we Evaluate Research is Difficult, but not Impossible. eLife. 2020;9. https://doi.org/10.7554/elife.58654.
Acknowledgements
The author thanks Panos Louridas and the reviewers for their constructive comments on earlier versions of this manuscript.
Funding
This work has received funding from the European Union’s Horizon Europe research and innovation programme under grant agreement No. 101070599 (SecOPERA project).
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The author declares that he has no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article
Cite this article
Spinellis, D. False authorship: an explorative case study around an AI-generated article published under my name. Res Integr Peer Rev 10, 8 (2025). https://doi.org/10.1186/s41073-025-00165-z
Received: 06 October 2024
Accepted: 16 April 2025
Published: 27 May 2025
DOI: https://doi.org/10.1186/s41073-025-00165-z


