.png)

Vision Language Models (VLMs) enable visual understanding alongside textual inputs. They are typically built by passing visual tokens from a pretrained vision encoder to a pretrained Large Language Model (LLM) through a projection layer. By leveraging the rich visual representations of the vision encoder and the world knowledge and reasoning capabilities of the LLM, VLMs can be useful for a wide range of applications, including accessibility assistants, UI navigation, robotics, and gaming.
VLM accuracy generally improves with higher input image resolution, creating a tradeoff between accuracy and efficiency. For many production use-cases, VLMs need to be both accurate and efficient to meet the low-latency demands of real-time applications and run on-device for privacy-preserving AI experiences.
In a paper accepted to CVPR 2025, Apple ML researchers recently shared a new technique to address this challenge: FastVLM, a new type of VLM that significantly improves accuracy-latency trade-offs with a simple design. Leveraging a hybrid architecture visual encoder designed for high-resolution images, FastVLM delivers accurate, fast, and efficient visual query processing, making it suitable for powering real-time applications on-device. The inference code, model checkpoints, and an iOS/macOS demo app based on MLX are available here.
Image Resolution and the Accuracy-Latency Tradeoff
Generally, VLM accuracy improves with higher image resolution, especially for tasks needing detailed understanding, such as document analysis, UI recognition, or answering natural language queries about images. For example, in Figure 1 below, we ask our VLM about the street sign visible in the image. On the left, the model receives a low-resolution image and cannot respond correctly. On the right, the VLM receives a high-resolution image and correctly identifies the traffic sign which is a “Do Not Enter”.
High resolution significantly increases time-to-first-token in VLMs. While using high-resolution images improves accuracy, it also reduces efficiency in two ways: 1) higher resolution images take longer for the vision encoder to process, and 2) the encoder creates more visual tokens, which increases the pre-filling time for the LLM. Both factors increase the time-to-first-token (TTFT), which is the sum of vision encoding time and LLM pre-filling time. As shown in Figure 2 below, both vision encoding and LLM pre-filling times grow as image resolution increases, and at high resolutions, vision encoder latency becomes the dominant bottleneck. To address this, our research introduces FastVLM, a new vision language model that significantly improves efficiency without sacrificing accuracy.
Latency Breakdown
For 1.5B VLM (fp16)
Hybrid Vision Encoders Deliver the Best Accuracy-Latency Tradeoff
To identify which architecture delivers the best accuracy-latency tradeoff, we systematically compared existing pre-trained vision encoders with an experiment in which everything (training data, recipe, LLM, etc.) was kept the same, and only the vision encoder was changed. In Figure 3 below, the x-axis shows TTFT, and the y-axis shows the average accuracy across different VLM tasks. We show two points for popular transformer-based encoders, ViT-L/14and SigLIP-SO400, pre-trained on image-text data at their native resolutions. We also show curves for ConvNeXT(fully convolutional encoder) and FastViT (a hybrid encoder combining convolutional and transformer blocks) at various resolutions. FastViT, which is based on two of our previous works (FastViT, ICCV 2023; and MobileCLIP, CVPR 2024), achieves the best accuracy-latency trade-off compared to other vision encoders—about 8 times smaller and 20 times faster than ViT-L/14.
Performance Comparison to FastViT
FastViTHD: An Optimal Vision Encoder for VLMs
While the FastViT hybrid backbone is a great choice for efficient VLMs, larger vision encoders are needed for improved accuracy on challenging tasks. Initially, we simply increased the size of each FastViT layer. However, this naive scaling made FastViT even less efficient than fully convolutional encoders at higher resolutions. To address this, we designed a new backbone, FastViTHD, specifically for high-resolution images. FastViTHD includes an extra stage compared to FastViT and is pre-trained using the MobileCLIP recipe to produce fewer but higher-quality visual tokens.
FastViTHD has better latency at high resolution images compared to FastViT, but to evaluate which is best in a VLM, we compared their performance when combined with LLMs of various sizes. We evaluated different pairs of (image resolution, LLM size), and three LLMs with 0.5B, 1.5B, and 7B parameters (corresponding to each curve in Figure 4 below) and pair it with vision backbone running at different resolutions.
As shown in Figure 4, using very high resolution images with a small LLM is not always the optimal choice; sometimes it is better to switch the LLM to a larger one instead of increasing the resolution. For each case, we show the Pareto-optimal curve with dashed lines, which shows the optimal (image resolution, LLM size) for a given runtime budget (TTFT here). Comparing Pareto-optimal curves, FastVLM (based on FastViTHD) offers a much better accuracy-latency trade-off than the FastViT-based model. It can be up to 3x faster for the same accuracy. Note that we had already shown that FastViT is significantly better than purely transformer-based or convolutional-based encoders.
Pareto-Optimal Curve by Model Size
FastVLM: a New VLM Based on FastViTHD
FastViTHD is a hybrid convolutional-transformer architecture comprising a convolutional stem, three convolutional stages, and two subsequent stages of transformer blocks. Each stage is preceded by a patch embedding layer that reduces the spatial dimensions of the input tensor by a factor of two. Using FastViTHD as the vision encoder, we built FastVLM, with a simple Multi-Layer Perceptron (MLP) module to project visual tokens to the embedding space of LLM, as shown in Figure 5.
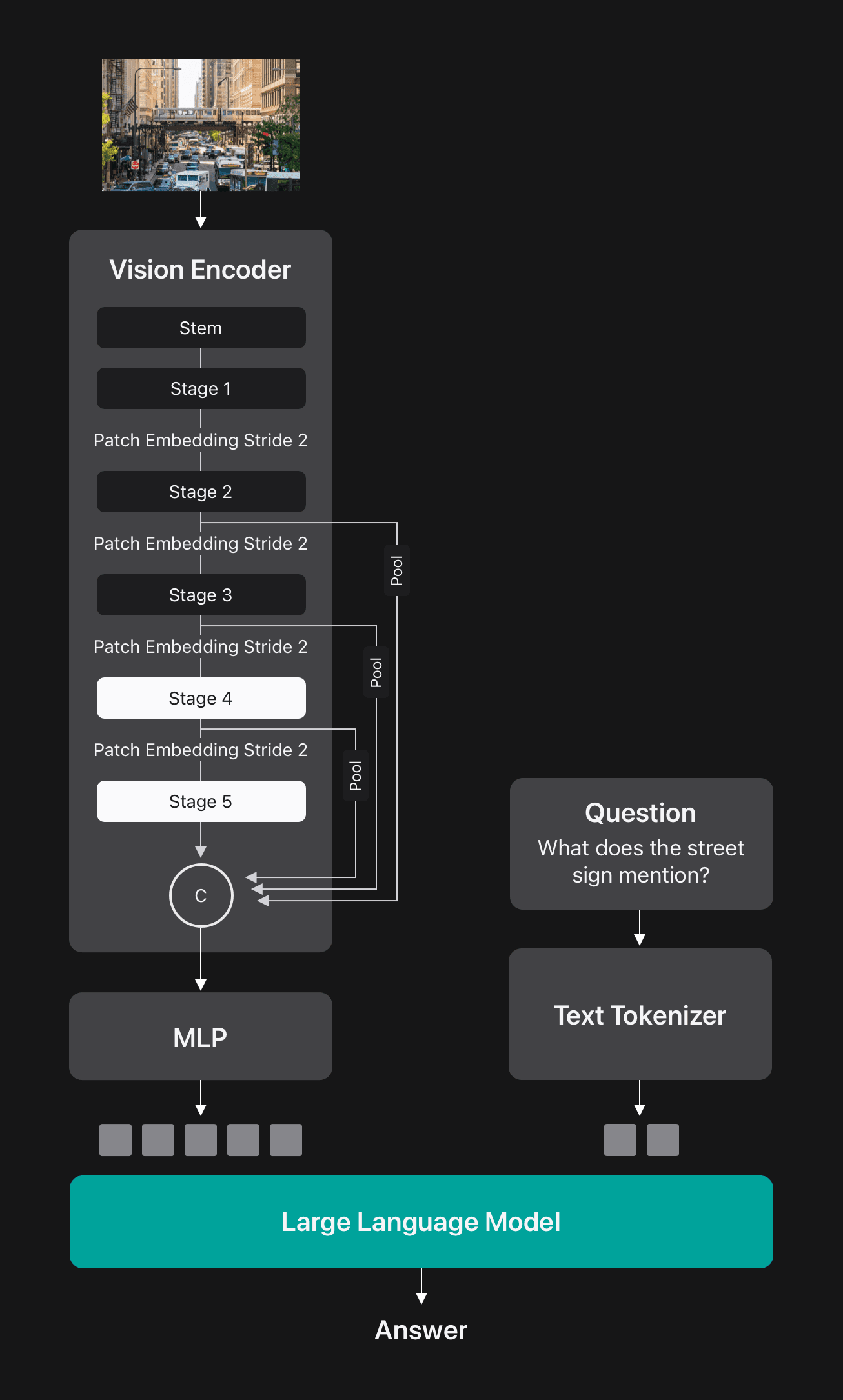
FastVLM Outperforms Token Pruning and Merging Methods
Prior research works in accelerating VLMs have employed complex merging or pruning techniques to reduce visual token counts to speed up LLM prefilling (and thus reduce the time to first token). As shown in Figure 6 below, FastVLM achieves higher overall accuracy across different visual token counts (corresponding to different input resolutions) compared to these approaches. This is due to the high-quality visual tokens from its FastViTHD encoder, and because FastVLM does not require complicated token pruning or merging, it is simpler to deploy.
Performance Comparison
FastVLM and Dynamic Tiling
As noted earlier, VLM accuracy increases with input resolution, particularly for tasks requiring understanding fine-grain details. Dynamic tiling (for example, in AnyRes) is a popular way to handle very high-resolution images. This approach divides an image into smaller tiles, processes each tile separately through the vision encoder, and then sends all tokens to the LLM, as in Figure 7 shown below.
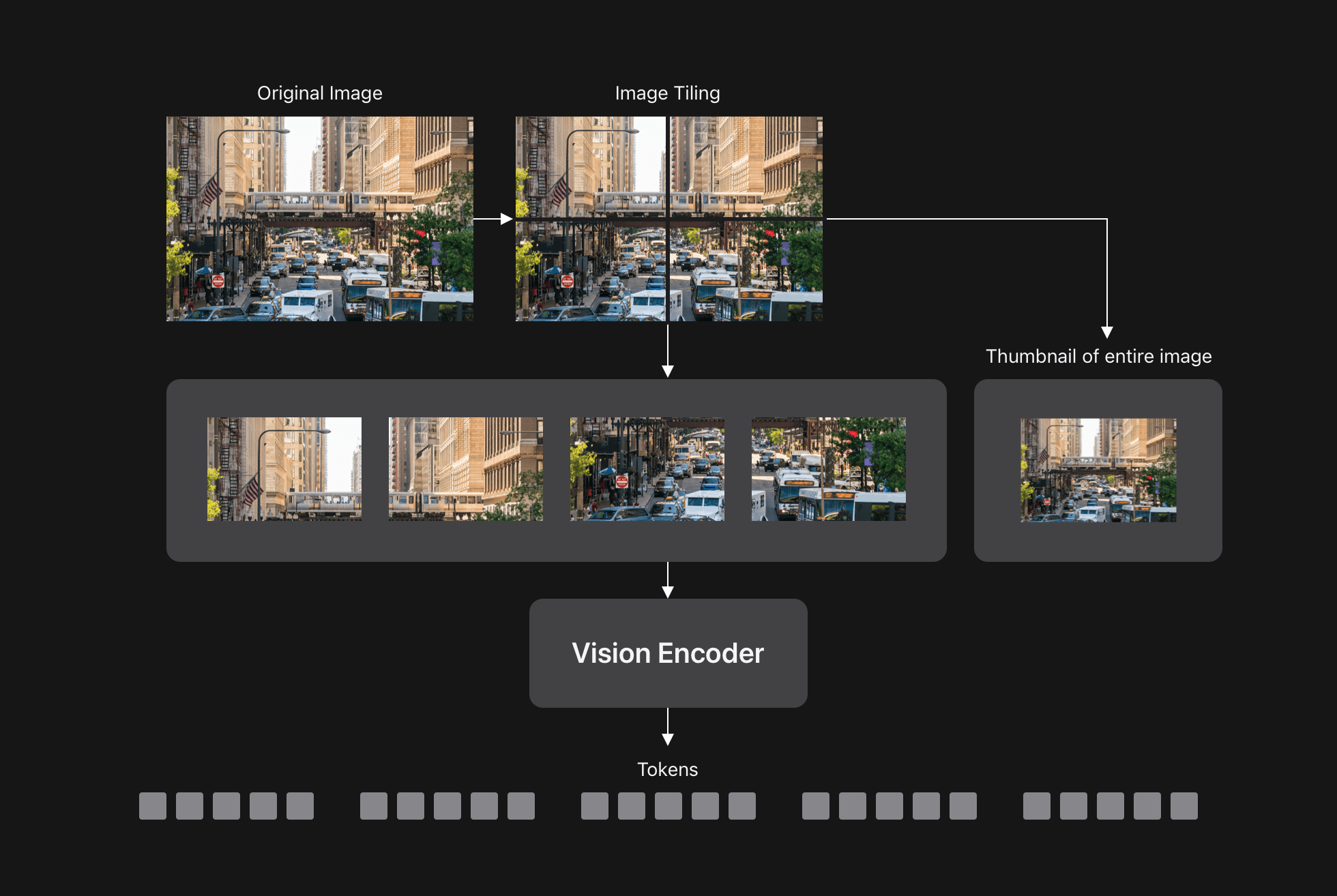
Since FastVLM naturally handles high-resolution images, we explored if combining FastVLM with dynamic tiling improves its accuracy-latency tradeoff. Figure 8 below shows that FastVLM without tiling (blue curve) achieves a better accuracy-latency trade-off compared to dynamic tiling (pink points), up to very high image resolutions, at which point combing FastVLM and AnyRes can be beneficial.
Tiling Effect on Performance
FastVLM is Faster and More Accurate Than Popular VLMs of the Same Size
Finally, we compared FastVLM with other popular VLMs. In Figure 9 below, we show two curves for FastVLM: one with AnyRes (to achieve the highest accuracy) and one without tiling (for the best accuracy-latency tradeoff), each tested with three different LLM sizes. FastVLM is significantly faster and more accurate than popular models of the same size as indicated by the arrows: it is 85x faster than LLava-OneVision(0.5B LLM), 5.2x faster than SmolVLM(~0.5B LLM), and 21x faster than Cambrian-1(7B LLM).
Performance Comparison by Model Size
To further show the on-device efficiency of FastVLM, we released an iOS/macOS demo app based on MLX. Figure 10 shows examples of FastVLM running locally on an iPhone GPU. FastVLM’s near real-time performance can enable new on-device features and experiences.
Conclusion
By combining visual and textual understanding, VLMs can power a range of useful applications. Because the accuracy of these models generally corresponds to the resolution of input images, there has often been a performance tradeoff between accuracy and efficiency, which has limited the value of VLMs for applications that require both high accuracy and great efficiency.
FastVLM addresses this tradeoff by leveraging a hybrid-architecture vision encoder built for high-resolution images, FastViTHD. With a simple design, FastVLM outperforms prior approaches in both accuracy and efficiency, enabling on-device visual query processing suitable for real-time on-device applications.
Apple researchers are advancing AI and ML through fundamental research, and to support the broader research community and help accelerate progress in this field, we share much of our research through publications and engagement at conferences. This week, the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), will take place in Nashville, Tennessee. Apple is proud to once again participate in this important event for the…
Scaling the input image resolution is essential for enhancing the performance of Vision Language Models (VLMs), particularly in text-rich image understanding tasks. However, popular visual encoders such as ViTs become inefficient at high resolutions due to the large number of tokens and high encoding latency. At different operational resolutions, the vision encoder of a VLM can be optimized along two axes: reducing encoding latency and minimizing…



