.png)

While getting back into exploration/intrinsic motivation projects last year, I decided to focus on NetHack as one of the main benchmarks I use due to its challenging nature and the fact that LLMs are still barely able to make a dent in it. As part of my due diligence as an RL researcher, I of course had to play some NetHack myself which rapidly morphed into a rabbit hole. After undoubtedly too many nights and weekends spent sifting through the NetHack Wiki, digging through r/nethack and reconfiguring my visual cortex to parse the finer shades of ASCII characters, my elven wizard Necrogueddon finally ascended with the Amulet of Yendor all the way to the Astral plane, resulting in Demigodhood for him and freedom for me to spend more time with my neglected cats and patient girlfriend.
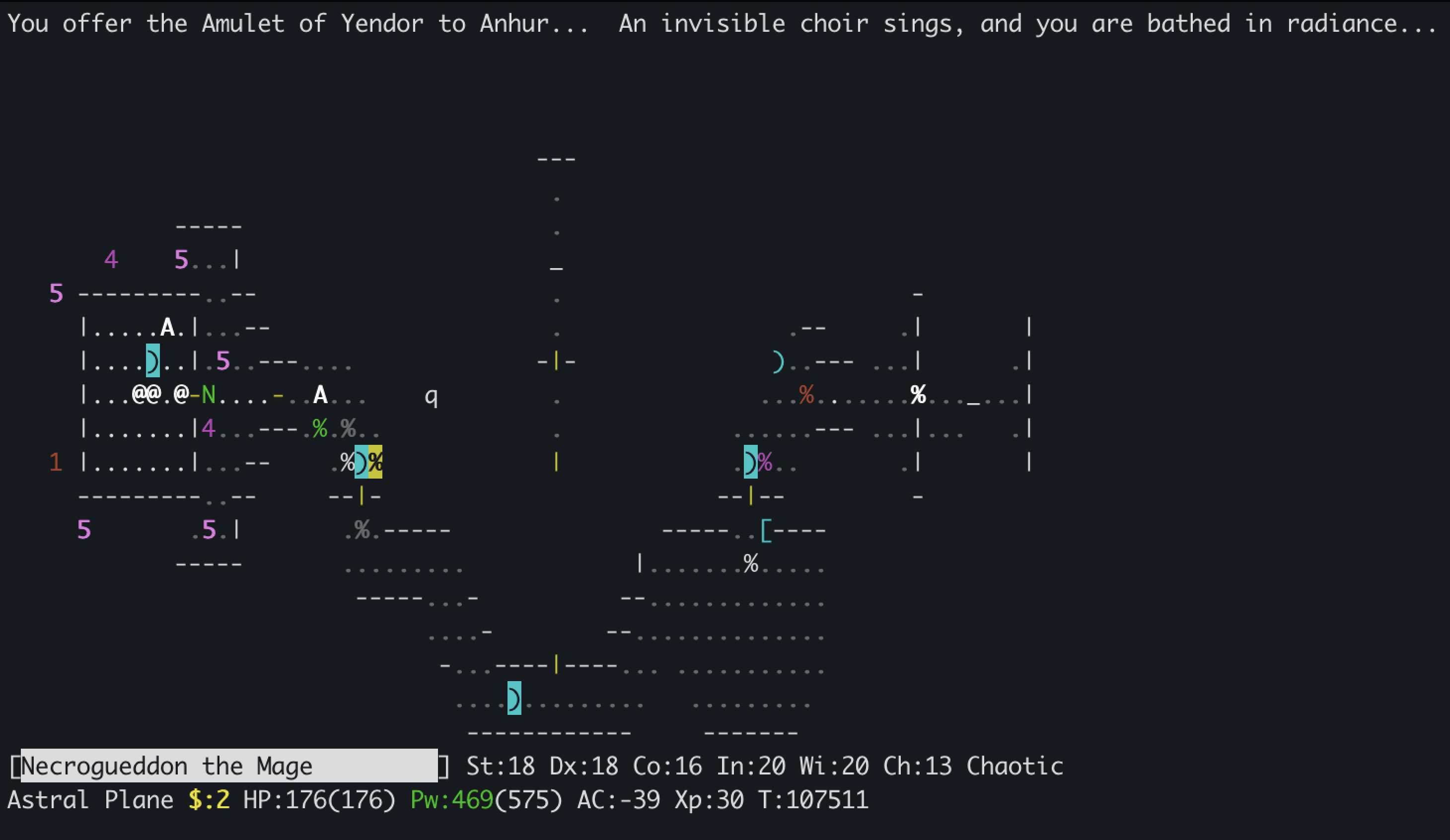
Playing this gave me a lot of insights into why the NetHack Learning Environment (NLE) remains one of the best and hardest benchmarks for RL and agentic AI, due to the breadth of capabilities that it requires to solve. While the excellent NLE paper gives a good taste of NetHack’s complexity, I thought it would be nice to share some of the additional challenges that became apparent in the course of playing, and how they relate to capabilities we desire our AI agents to have.
1. Needle-in-a-haystack style credit assignment: One of the important subgoals of the game is gaining intrinsic resistances to various sources of harm such as poison, fire, or cold. This is done by eating the corpses of certain enemy monsters (for example, fire-breathing monsters can give fire resistance). However, gaining such a resistance is stochastic (with say 5-30% chance) and the only indication that a resistance has been acquired is some message such as “You feel momentarily warm” to indicate cold resistance or “You feel healthy.” to indicate poison resistance. Whether a resistance has been gained or not has a huge influence on the game - for example, many poisonous monsters are easy to defeat if the player has poison resistance, but deadly without. In RL terms, this means that the policy, value function or reward at a given timestep often depends on a single observation hundreds or thousands of timesteps prior. An agent must therefore learn to sift out and retain very rare but important signals from mountains of unimportant ones.
2. In-context exploration: Another important subgoal of the game consists of identifying the function of magical objects such as potions, scrolls, wands, rings, and amulets. Each of these objects is identified by their appearance (“a fizzy/golden/murky potion”, “a forked/runed/zinc wand”), but their effect is initially unknown. Additionally, objects can be blessed, cursed or neutral, and using a cursed item can often be a game-ending mistake. The player must therefore actively acquire information about the function and curse status of objects throughout the game. Although this can sometimes be done directly through identification scrolls or spells, these are rare, and more subtle ways are often required. For example, the player can drop an item on the ground and observe if their pet avoids it (meaning it is likely cursed), or they can throw a potion at a monster and observe its effect, or they can offer to sell an object to a shopkeeper and infer information about it based on the price that is offered. It is often the case that these various pieces of information disambiguate what the object can be to some degree, but do not uniquely identify it, which means an effective agent must track and continuously update its belief over what each object does, and combine different sources of information to fully identify them.
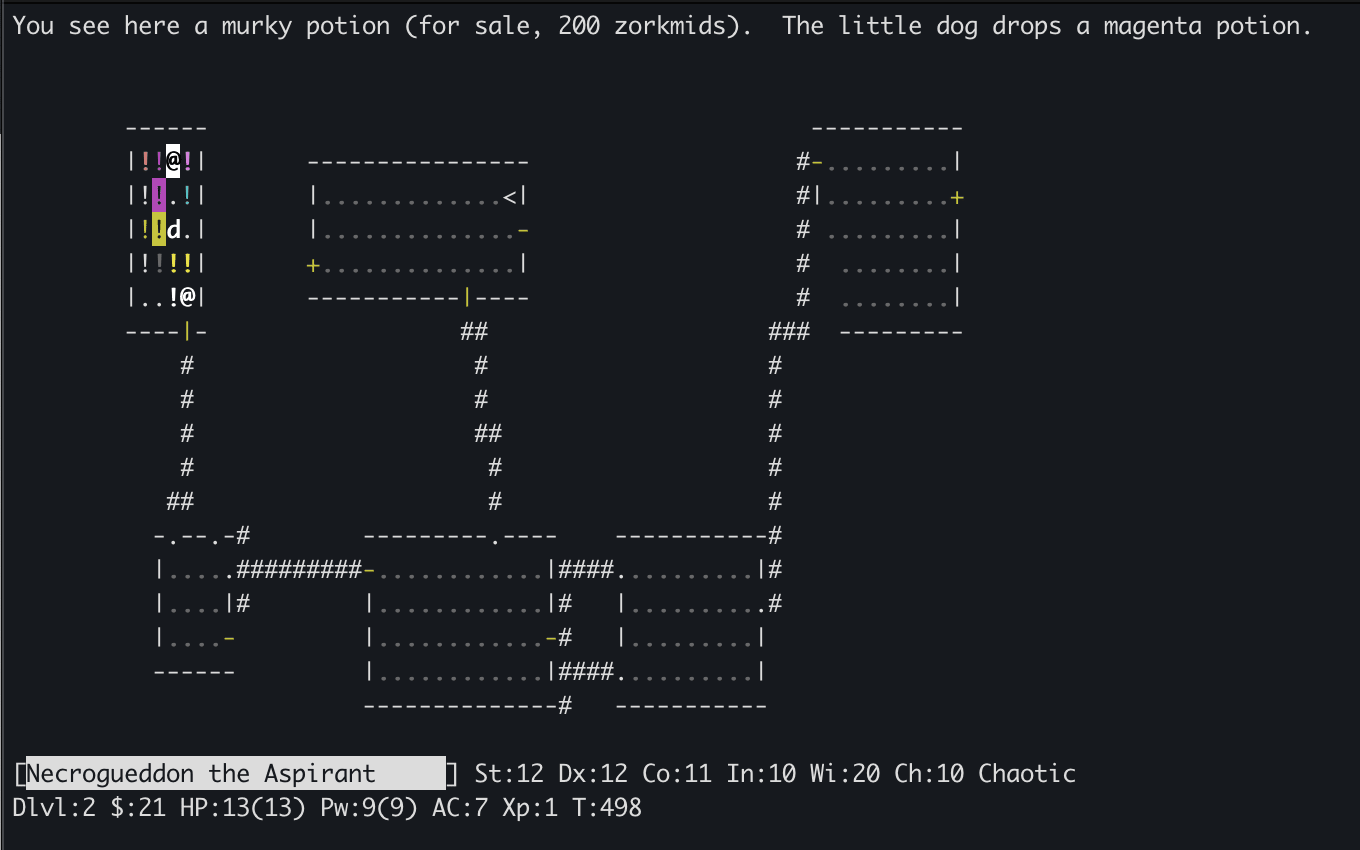
Importantly, the pairing of appearance to function is randomized each game: in one game, healing potions might be fizzy and sickness potions murky, while in another game these might be reversed. Mastering NetHack thus requires exploration at multiple levels: learning about features that are common across all episodes (such as what a potion of healing or sickness do), as well as features specific to each episode (such as what a potion of healing or sickness look like in this episode). This is essentially the problem of Contextual MDPs, in which we have studied exploration before, albeit in much simpler settings. I personally view Contextual MDPs as one of the current frontiers of exploration research, as they behave quite differently from the classical singleton MDPs. NetHack is an environment where they naturally occur, although the question of how to disentangle cross-episode exploration and within-episode exploration occurs in many other places as well. Embodied AI tasks such as mobile rearrangement are such an example: each episode corresponds to a different indoor scene, which share certain dynamics (doors and drawers can be opened, walls cannot be crossed) but not others (the placement of rooms and contents of containers is different each episode). Recommendation systems are another, where each episode corresponds to a different user and some degree of information-gathering must be redone each time.
3. Leveraging offline textual knowledge: Many players, myself included, make use of the NetHack Wiki to guide their playing. This is an extensive resource which includes helpful information on nearly every aspect of the game: the uses of different objects, spell effects, monster characteristics and how to defeat them, strengths and weaknesses of different character classes, strategies for crossing particularly difficult levels, and so on. On many occasions while playing, I would encounter a monster I had never seen and promptly looked it up in the wiki to see the best strategy for dealing with it—this is one of the nice things about NetHack’s turn-based nature: you can stop and think as long as you like before taking the next action. It’s hard to estimate how much time using the Wiki saves, but I did see some posts by purists on r/nethack who had been playing “unspoiled” (meaning they did not read the Wiki or other textual resources) for 15+ years and had yet to ascend. Which is not surprising, given the near-unlimited ways of perishing and NetHack’s cheeky permadeath feature, meaning once you die, you can’t reload saved games and have to restart from scratch.
More broadly, developing ways to leverage the wiki to improve NetHack agents also serves as a nice distillation of the larger goal of training AI systems with a combination of direct experience and accumulated cultural knowledge. Humans do not learn tabula rasa and instead leverage a vast amount of cultural knowledge during learning, which can be seen as a way to share experience across individuals and generations, often in a highly compressed form through language. I suspect the combination of cultural knowledge + RL will become increasingly popular in the coming years, and to me appears key in areas such as automated scientific discovery, which requires both absorbing existing human knowledge (as LLMs do) but additionally discovering new information past the frontier of what is known. I’ll probably write more about this another time—for now, back to NetHack.
4. Combinatorial Complexity and Generalization: I had heard that NetHack was complex, but this didn’t really sink in until I played the game past a certain point. There are many mechanics to the game which I think need to be mastered and recombined as needed in order to win consistently. This relates to the procedurally generated nature of the game: each episode corresponds to a random combination of object generations, monster placements and different level variants, which in turn requires using different combinations of strategies at each episode. The number of possible combinations of strategies is extremely large, hence I think successful agents will need to generalize to novel combinations at test time.
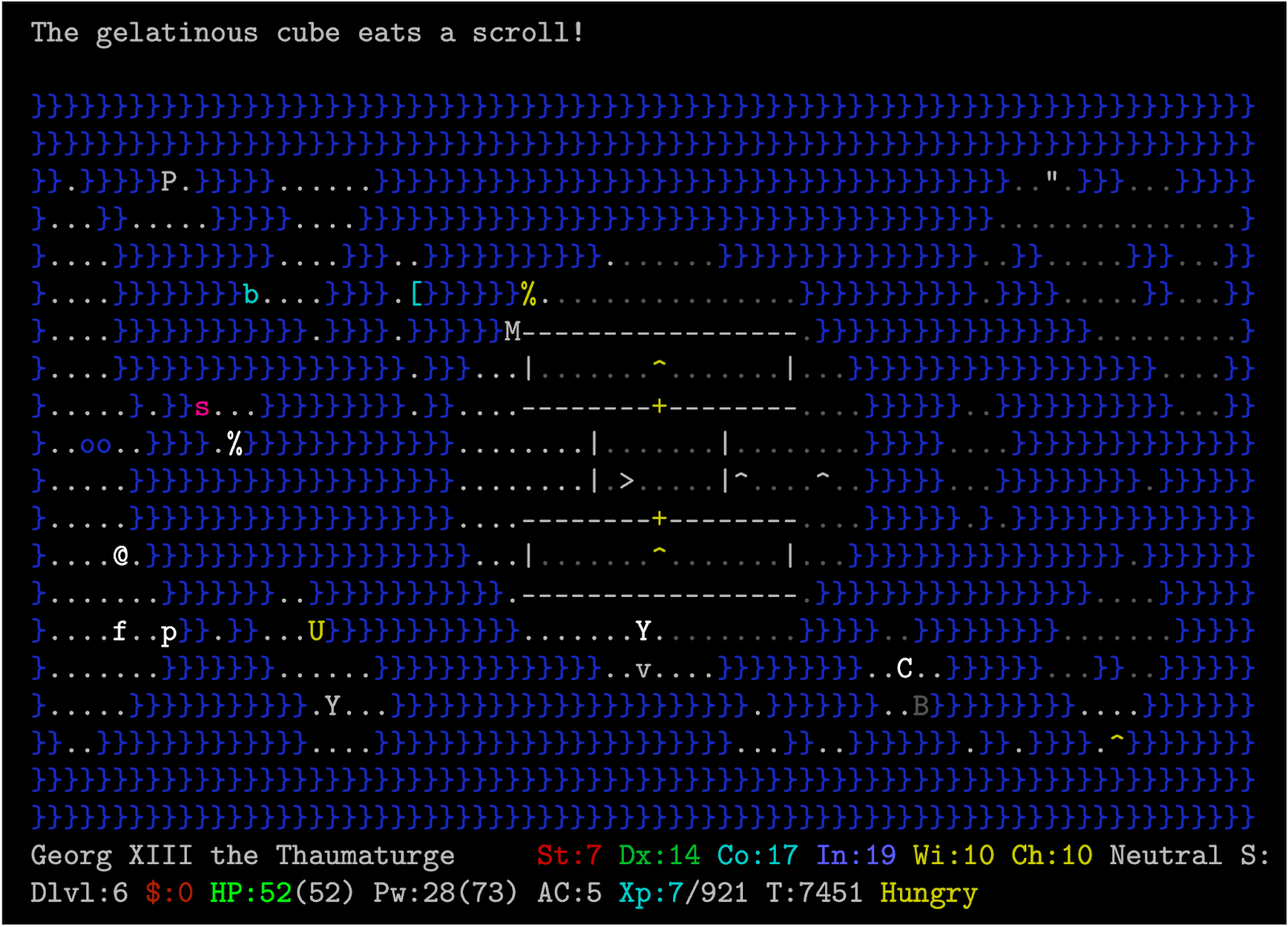
Let me take the example of Medusa’s Island, a special level in which the agent needs to cross a body of monster-infested water in order to reach the staircase to the next level. During one game, my character found a ring of levitation in the early levels. Upon reaching Medusa’s Island, I simply needed to put it on, float above the water while the krakens and eels below watched hungrily but helplessly, kill Medusa and waltz on to my next YASD a few levels below (in this case, poisoning myself by eating an overripe storm giant corpse which I thought was still fresh…). The next time I played however, there were no rings of levitation to be found. Other strategies did not work either: I did not have wands or spells of cold which could freeze the water so I could cross on foot, and even though I had some scrolls which create boulders, I did not have enough to create a long enough bridge to enable crossing. However, I did conveniently happen to have both a ring of polymorph control and a wand of polymorph! So, I turned myself into a white dragon and flapped over the krakens and eels, turning them into frozen fish for good measure with my icy breath.
To summarize, in this example two different strategies were required to cross a given level on two different episodes, due to different random generations of objects in previous levels (in the first episode, a ring of levitation, in the second, a ring of polymorph control and wand of polymorph), and the game is full of such instances. On top of this, levels can occur in different orders and versions. This suggests a need for compositional generalization, since the exact combination of strategies needed at test time is unlikely to have been seen during a single training episode, although the different constituent strategies will likely have occurred in different training episodes.
5. Hierarchy and Long-horizon Decision-Making: Hierarchy is one of those things that many AI researchers agree is necessary for long-horizon tasks, but it hasn’t really taken off - nearly all of the currently used RL methods are flat. I think this is due to insufficient benchmarks: Atari, Mujoco/DMC, Doom and other classic RL benchmarks have relatively short horizons and dense rewards, and are solvable by flat policies. However, while playing NetHack I noticed there were at least 3 levels of hierarchy that guided my playing, which suggests to me that it is a good benchmark for hierarchical RL, and I hope that it will encourage more work in this area. The different levels of hierarchy that I saw were the following:
At the highest level are very temporally extended goals or behaviors of the sort described in the standard strategy document of the NetHack wiki, which span thousands of timesteps. These consist of things like gaining different resistances, completing dungeon branches, obtaining different pieces of equipment and artifacts, acquiring a certain experience level or armor, completing special levels and defeating various bosses. The order in which these goals should be attempted is highly dependent on the current status of the character: for example, one should only attempt certain dungeon branches or levels once the character is sufficiently strong, some monsters can only be defeated with the help of certain equipment items (for example, a reflective item is often necessary to survive dragon breath, having an item granting magic resistance is needed to avoid instadeath from certain monsters casting death spells), and so on.
At a lower level are common behaviors such as attacking, exploring, escaping, interacting with shopkeepers, reorganizing inventory, and identifying objects. These behaviors are common throughout the game and span from dozens to hundreds of time steps. These also need to be adapted based on new observations: for example, one might be visiting a shop when a monster appears that needs to be dispatched, after which shopping can continue (shopkeepers in NetHack are not very helpful and don’t mind if you die in their shop, they will then just loot your possessions and add it to their inventory).
At the lowest level are individual actions (often single keystrokes), which consist of the action space available to the RL agent. This level involves tactics such as staying out of reach of a monster while casting spells or maneuvering into a hallway to fight a group of monsters one by one, and often requires spatial reasoning.
In short, I think NetHack is one of the few benchmarks where hierarchy has the potential to provide a significant benefit—I would say the other is MineCraft, which is maybe comparable in terms of complexity and has the added challenge of perception, but is also slow and more challenging engineering-wise to run. This isn’t to say that hierarchy is only useful for niche problems—I think it’s likely an essential requirement for advanced agentic systems, and the fact that lots of existing RL benchmarks are solvable without it is more a reflection of their simplicity than anything else. We have some work starting to explore this, and I hope to see more work in hierarchical RL.
Concluding Thoughts: Playing the game to completion was quite eye-opening for me in terms of the game complexity and the challenges it poses to AI agents. I think this remains a great benchmark for RL and AI more generally: while LLMs are no doubt a part of the solution (particularly for transferring offline textual knowledge into the acting agent, i.e. point #3 above), I would also be very surprised if simply scaling them will solve this task. The reason for this is that they are fundamentally trained to imitate rather than seek out novel information and learn from their past experience, which is the core of agentic behavior. The limitation of LLMs on this task has been very nicely illustrated by the BALROG benchmark, where even the most recent LLMs/VLMs barely make progress—and this is despite NetHack being somewhat “LLM-friendly” in the sense that its observations have a strong textual component.
Separately from its use as an RL benchmark, I found NetHack to be a lot of fun once I got used to the ASCII visuals. The upside of having primitive graphics is that the game can be much deeper and more complex, since graphics rendering is no longer a constraint and lots of information is communicated through text—the limiting factor then becomes the imagination of the designers. I’ve alluded to some of the interesting mechanics above, but there are many more: there is a whole system of alchemy where you can mix potions to create others, polymorph spells can be cast on objects (including magical ones) to create others, you can also polymorph yourself into various monsters and inherit their abilities (including laying eggs - which can then hatch and become your minion children), you can write your own scrolls and enchant your weapons and inventory, there is a whole set of unique magical artifacts you can collect, etc. I particularly enjoyed playing the wizard - although they are weak in the early game, if they survive past a certain point and get access to more advanced magic, a whole level of complexity and fun gets unlocked. As part of my deep dive I read James Craddock’s book Dungeon Hacks, which goes into the history of roguelikes and how they grew from a combination of D&D and early Unix culture (apparently Ken Thompson, original creator of Unix and later Turing award winner, was a big fan of NetHack’s precursor Rogue and even spent time hacking the permadeath feature to enable reloading saved games). Being open source, NetHack is actually the work of many contributors who designed different levels, characters and quests, which explains in part its sprawling diversity. It is also sprinkled with nerdy fantasy/literary/Unix references which are fun to discover. All this to say, if you’re working with the NLE and want to build some intuitions about the game (which is very helpful for diagnostics), the game can actually be quite fun given some time.
As a final thought, I quite agree with the above flowchart that Tim Rocktäschel and Heinrich Küttler shared a while back. While NetHack is complex in comparison to other RL benchmarks, it still contains only a tiny fraction of the complexity of the real world (its source code is 4.2MB, which provides an upper bound on its Kolmogorov complexity). As long as we can’t reliably solve this game for which we can easily collect lifetimes worth of data, have access to detailed textual resources (and even the underlying source code), and large-scale datasets of human gameplay, I think AGI remains a ways off.



