.png)

The LLM unstructured text pipeline that I write about is everywhere. In it, you have a prompt, you have text data (PDFs, user input, spreadsheet rows), you iterate through each one and get structured output like summaries, classifications, or extracted information.
Last week, one explained to me their data pipeline—which was a very standard version of this—AND another person told me about a tool their organization deployed that lets users do this without any coding.
Point made! I think I can stop writing about this pattern. So this is, instead, about a handful of other text-processing tricks I use LLMs for as part of data pipelines.
Most of these you could fold into your unstructured text pipeline; a couple work alongside tools like regular expressions or semantic clustering. They’re all variations on the same principle: if it’s a repetitive text processing task that’s easy-to-explain and doesn’t require a ton of judgement, you can write that into your data pipeline and have an LLM do it for you.
The problem: Your pipeline processes data that’s fairly standardized, but column names and formats may vary between datasets.
The trick: Describe what you’re looking for to an LLM, give it information about the dataset (column names, the first few rows, information on how many values are missing and what the most common values are—basically, whatever you’d give a human analyst), and have it populate a JSON file mapping your standard field names to what this specific dataset calls them. Use that JSON in the rest of your pipeline.
Real example: In my comment analyzer for regulations.gov bulk data, column names are usually the same, but not always. Because of this, I have an automated step that figures out the mapping: in this case, I just give it the first five rows, because that seems to work. The alternative would be maintaining an exhaustive list of every variation and either hard-coding them all or using pattern matching to anticipate future changes, or else doing this manually each time.
When to use it: When you have semi-standardized data with naming variations. You can run this with user validation (showing them the mapping and letting them confirm or correct it) or without—but if it’s without, I think you should build in some automated validation that you found the right columns (like checking that the data types make sense), which will still be easier than trying to do column identification without the LLM.
The problem: You need to classify text, but the relevant classification buckets you’re looking for, like what themes are present in the data, are different for each dataset.
The trick: Give the LLM a prompt describing what you’re looking for, plus a random sample of your text. It synthesizes the themes faster than you could, determining what buckets to classify the text into and writing the exact prompts. Your pipeline then takes this output and uses it to populate both the prompt text and the Pydantic class structure, so the LLM can only choose from the themes it identified, not make up new ones.
Real example: For my public comment analysis, the arguments people make of course vary by regulation. I let the LLM read a sample, identify the main arguments according to a very specific set of rules, and write the prompts and values that will be used to classify all the comments.
When to use it: When classification categories aren’t predetermined—this could be themes in comments, types of errors in logs, categories of customer feedback, or any other situation where the buckets themselves need to be discovered from the data. Depending on the use case, you might let users validate the LLM’s choices about buckets or prompts if they want something different.
The problem: You have too much data to send each document to an LLM, maybe because of cost or processing time, but you still want to extract things that would be tedious to hard-code manually.
The trick: Sample from your documents and use an LLM to extract what you’re looking for. Deduplicate the results, optionally set a threshold (like “appears in at least 2% of documents”), then use string matching or regular expressions to find those items in your full dataset.
Real example: Processing resumes at scale—extracting programming languages, frameworks, tools. The LLM tells you what’s in the data without you spending hours building and maintaining lists. You can also model the likelihood that additional sampling would find new items, and monitor over time to catch new terms appearing in resumes.
When to use it: This works for terms that aren’t one-offs in the documents you’re analyzing. For instance, programming languages like “Python” appear the same way across many resumes, so once you’ve identified them with the LLM, you can use pattern matching to find them everywhere else. But it won’t work as well for things with too many possible values—like college names or job titles. So for certain types of entities (names, places, organizations), you’d need a different approach—like a smaller model specifically designed for entity recognition, like GLiNER, possibly fine-tuned with labeled examples you got from the LLM.

The problem: You need to match items between two datasets, but exact matching won’t work and lexical matching, or comparing how similar strings are based on the actual characters or words, isn’t smart enough.
The trick: Do a first pass with lexical matching and heuristics like date proximity or other filtering rules to get close matches. For anything below your confidence threshold, pass the top candidates to an LLM to make the final call.
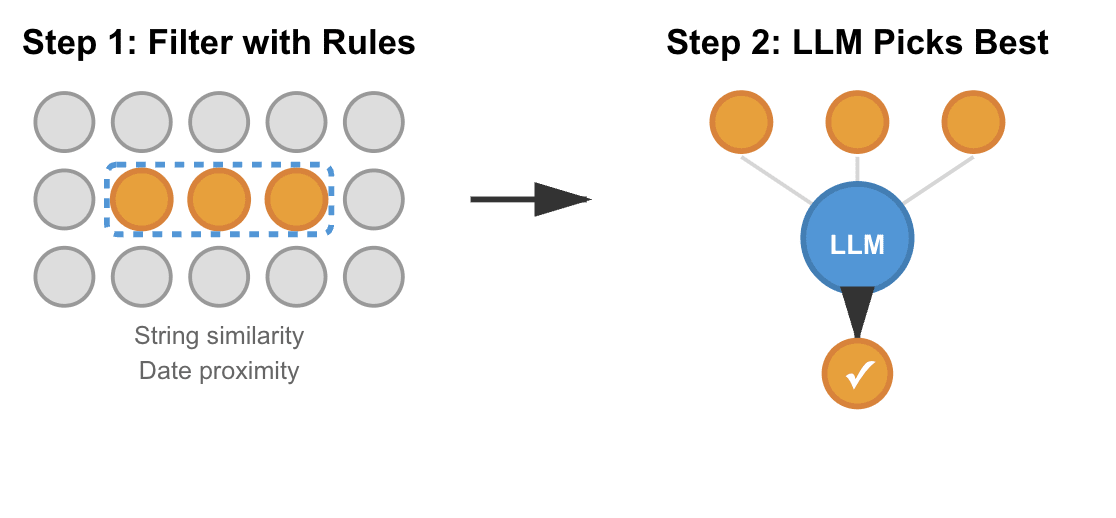
Real example: In my congressional hearing matcher, I’m matching YouTube videos to their Congress.gov records. For instance, “Health Subcommittee Markup of 23 Bills” versus “23 Pieces of Legislation” use completely different words but refer to the same event. Lexical matching and date filtering narrow it down, then the LLM adjudicates unclear cases via a more nuanced matching process.
When to use it: When you’re matching things where the relationship isn’t captured by business rules. This is a variation of the standard text pipeline, but I’m including it because the possible outputs do vary for each ‘document’: your lexical/business rule process limits the options that the LLM can return.
The problem: You’ve done semantic clustering on your text data, but the clusters are just numbers or unlabeled groups.
The trick: After clustering, pass representative examples and the list of the most common or most-distinguishing words or phrases from each cluster to an LLM and have it generate human-readable labels that capture what the cluster is about.
Real example: In my Schedule F comment analysis, I clustered semantically similar comments together. Then I pass the LLM samples and common words from each cluster and it describes them. This is faster than reading through clusters myself, and especially useful when your clusters may change over time with new data.
When to use it: After any clustering or grouping where you need human-interpretable labels. The LLM is doing synthesis work you’d otherwise do manually.
These tricks all follow the same logic: they’re tasks you can give clear instructions for, and they’re not inherently complicated—but they’d still take you time to do manually. An LLM can do them quickly and frequently well enough, and you can add in a human validation step if you want.
I’m especially interested in LLM/non-LLM hybrid patterns like #3. The hybrid approach splits the work: the LLM samples your documents and extracts terms, then you use those terms with regular expressions to search your full dataset. You get the LLM’s ability to identify what’s actually in your data without manually building lists, combined with speed and transparency for the bulk processing.
This structure also builds in error tolerance. If your LLM sample occasionally misses “Ruby,” you’ll probably see it in the next sample batch. You can also check completeness by comparing your found terms with your samples—and because you can model the likelihood of finding new terms by continuing to sample more, you can also quantify your sampling coverage. It’s also an example of using the LLM to label data for use with smaller models—similar to using LLMs to extract entities and use those labels to test or fine-tune your entity model, except in this case your “model” is just the presence or absence of each word.
Working with different kinds of text data pipelines makes these patterns easier to see. The more you do it, the faster you recognize when you need a new one.



