.png)

Today, we are excited to release FLUX.1 Kontext, a suite of generative flow matching models that allows you to generate and edit images. Unlike existing text-to-image models, the FLUX.1 Kontext family performs in-context image generation, allowing you to prompt with both text and images, and seamlessly extract and modify visual concepts to produce new, coherent renderings.

Consistent, context-aware text-and-image generation and editing .
YOUR IMAGES. YOUR WORDS. YOUR WORLD.
FLUX.1 Kontext marks a significant expansion of classic text-to-image models by unifying instant text-based image editing and text-to-image generation. As a multimodal flow model, it combines state-of-the-art character consistency, context understanding and local editing capabilities with strong text-to-image synthesis.
Improved Text-to-Image Capabilities
Whether for ideation, drafting, conceptual design, or just for fun - text-to-image remains a crucial component of today's image generation. The FLUX.1 Kontext models deliver state-of-the-art image generation results with strong prompt following, photorealistic rendering, and competitive typography—all at inference speeds up to 8x faster than current leading models (e.g. GPT-Image).
Play. Create. Manipulate…
FLUX.1 Kontext models go beyond text-to-image. Unlike previous flow models that only allow for pure text based generation, FLUX.1 Kontext models also understand and can create from existing images. With FLUX.1 Kontext you can modify an input image via simple text instructions, enabling flexible and instant image editing - no need for finetuning or complex editing workflows. The core capabilities of the the FLUX.1 Kontext suite are:
- Character consistency: Preserve unique elements of an image, such as a reference character or object in a picture, across multiple scenes and environments.
- Local editing: Make targeted modifications of specific elements in an image without affecting the rest.
- Style Reference: Generate novel scenes while preserving unique styles from a reference image, directed by text prompts.
- Interactive Speed: Minimal latency for both image generation and editing.
…and Iterate: modify step by step
Flux.1 Kontext allows you to iteratively add more instructions and build on previous edits, refining your creation step-by-step with minimal latency, while preserving image quality and character consistency.
The FLUX.1 Kontext [pro] Models
As part of the FLUX.1 Kontext suite we bring two new in-context image models to the BFL API.
- FLUX.1 Kontext [pro] - A pioneer for fast, iterative image editing
A single model that delivers local editing, generative in-context modifications and classic text-to-image generation in signature FLUX.1 quality. FLUX.1 Kontext [pro] handles both text and reference images as inputs, seamlessly enabling targeted, local edits in specific image regions and complex transformations of entire scenes. Operating up to an order of magnitude faster than previous state-of-the art models, FLUX.1 Kontext [pro] is a pioneer for iterative editing, since it’s the first model that allows users to build upon previous edits through multiple turns, while maintaining characters, identities, styles, and distinctive features consistent across different scenes and viewpoints.
- FLUX.1 Kontext [max] - Maximum Performance at High SpeedOur new experimental model greatly improves prompt adherence and typography generation, and high consistency for editing. All these without compromise on speed.
FLUX.1 Kontext [max] and FLUX.1 Kontext [pro] are available at KreaAI, Freepik, Lightricks, OpenArt and LeonardoAI and via our infrastructure partners FAL, Replicate, Runware, DataCrunch, TogetherAI and ComfyOrg. We received support for preference data collection by OpenArt and KreaAI.
FLUX.1 Kontext [dev] available in Private Beta
We deeply believe that open research and weight sharing are fundamental to safe technological innovation. We developed an open-weight variant, FLUX.1 Kontext [dev] - a lightweight 12B diffusion transformer suitable for customization and compatible with previous FLUX.1 [dev] inference code. We open FLUX.1 Kontext [dev] in a private beta release, for research usage and safety testing. Please contact us at [email protected] if you’re interested. Upon public release FLUX.1 Kontext [dev] will be distributed through our partners FAL, Replicate, Runware, DataCrunch and TogetherAI.
Performance Evaluation
To validate the performance of our FLUX.1 Kontext models we conducted an extensive performance evaluation that we release in a tech report[link to tech report]. Here we give a short summary: to evaluate our models, we compile KontextBench, a benchmark for text-to-image generation and image-to-image generation from crowd-sourced real-world use cases. We will release this benchmark in the future.
![We show evaluation results across six in-context image generation tasks. FLUX.1 Kontext [pro] consistently ranks among the top performers across all tasks, achieving the highest scores in Text Editing and Character Preservation](https://cdn.sanity.io/images/gsvmb6gz/production/14b5fef2009f608b69d226d4fd52fb9de723b8fc-3024x2529.png?fit=max&auto=format)
We show evaluation results across six in-context image generation tasks. FLUX.1 Kontext [pro] consistently ranks among the top performers across all tasks, achieving the highest scores in Text Editing and Character Preservation
We evaluate image-to-image models, including our FLUX.1 Kontext models across six KontextBench tasks. FLUX.1 Kontext [pro] consistently ranks among the top performers across all tasks, achieving the highest scores in text editing and character preservation (see Figure above) while consistently outperforming competing state-of-the-art models in inference speed (see Figure below)
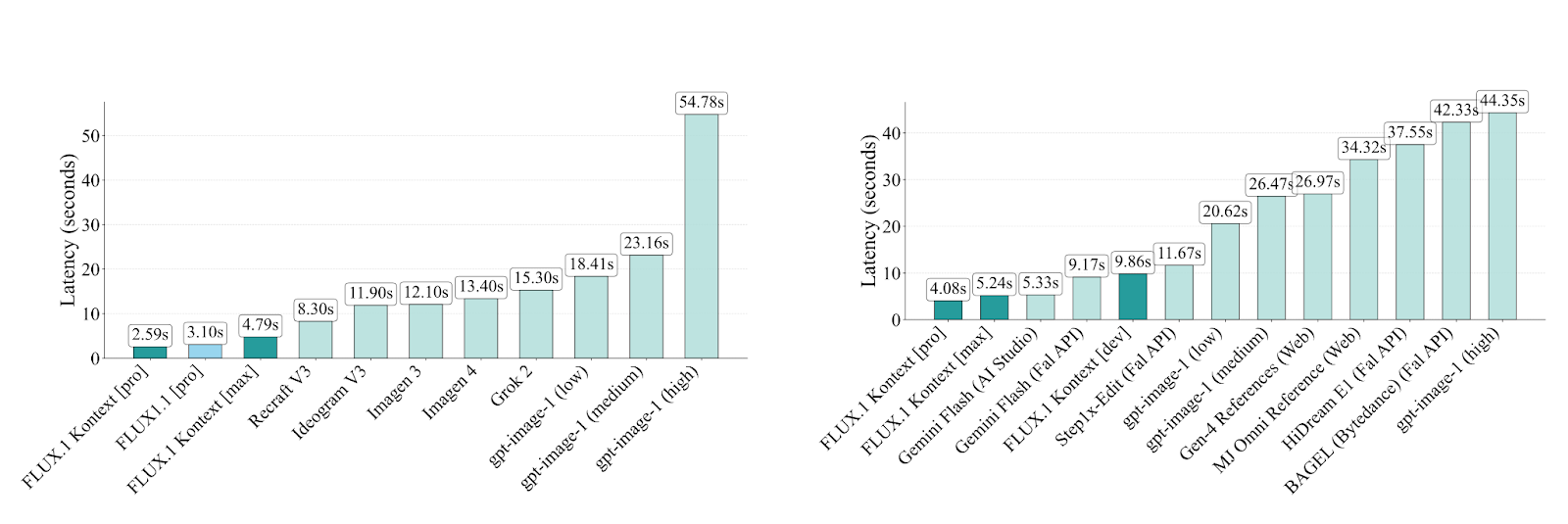
FLUX.1 Kontext models consistently achieve lower latencies than competing state-of-the-art models for both text-to-image generation (left) and image-editing (right)
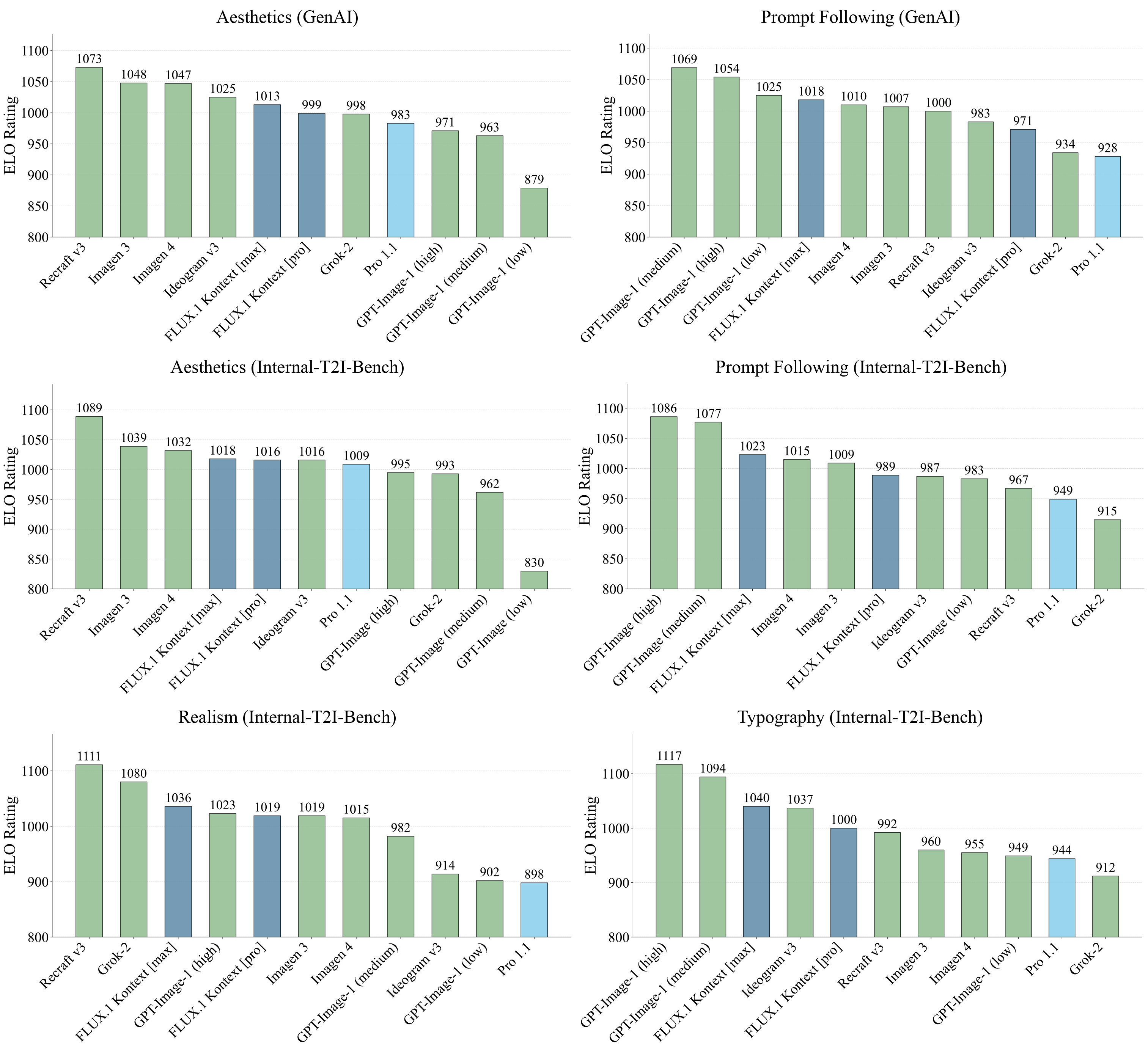
We evaluate FLUX.1 Kontext on text-to-image benchmarks across multiple quality dimensions. FLUX.1 Kontext models demonstrate competitive performance across aesthetics, prompt following, typography, and realism benchmarks.

left: input image; middle: edit from input: “tilt her head towards the camera”, right: “make her laugh”

left: input image; middle: edit from input: “change the ‘YOU HAD ME AT BEER’ to ‘YOU HAD ME AT CONTEXT’”, right: “change the setting to a night club”
Failure Cases:
FLUX.1 Kontext exhibits some limitations in its current implementation. Excessive multi-turn editing sessions can introduce visual artifacts that degrade image quality. The model occasionally fails to follow instructions accurately, ignoring specific prompt requirements in rare cases. World knowledge remains limited, affecting the model's ability to generate contextually accurate content. Additionally, the distillation process can introduce visual artifacts that impact output fidelity.

Illustration of a FLUX.1 Kontext failure case: After six iterative edits, the generation is visually degraded and contains visible artifacts.
A FLUX API Demo: Introducing The BFL Playground
Since launch, we have been consistently asked to make our models easier to test and demo. Today, we are introducing the FLUX Playground: A streamlined interface for testing our most advanced FLUX models without technical integration.
The Playground allows developers and teams to validate use cases, demonstrate capabilities to stakeholders, and experiment with advanced image generation in real-time. Whether evaluating technical feasibility or showcasing results to decision-makers, the Playground provides immediate access to assess FLUX's capabilities before moving to full API implementation.
At BFL, our mission is to build the most advanced models and infrastructure for media generation.The Playground serves as an entry point to the BFL API, designed to accelerate the path from evaluation to production deployment. It is available, today, at https://playground.bfl.ai/.
We're just getting started.If you want to join us on our mission, we are actively hiring talented individuals across multiple roles. Apply here.


