.png)

Purpose-built for speed, quality, cost, and scale.
Join Over 1.8 Million Developers and Teams
Designed for Inference. Not Adapted for It.
Inference is where AI goes to work.
Our custom LPU™ is built for this phase—developed in the U.S. with a resilient supply chain for consistent performance at scale.
It powers GroqCloud™, a full-stack platform for fast, affordable, production-ready inference.
Watch the Demo

Jonathan RossCEO & Founder
Run More. Spend Less. No Compromise.
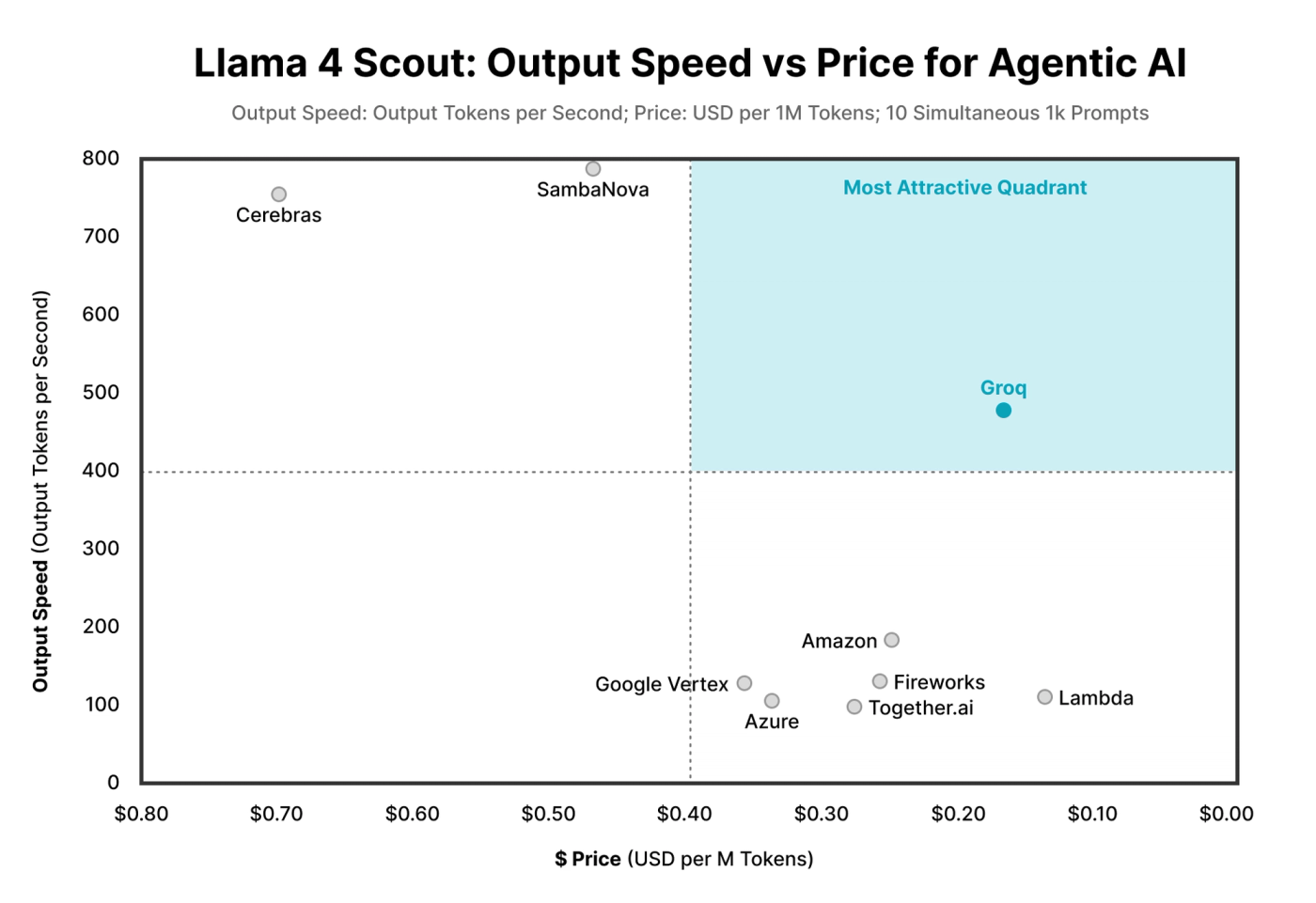
Independent 3rd party benchmarks from ArtificialAnalysis.ai
Unmatched Price Performance
Groq provides the lowest cost per token, even as usage grows, without sacrificing speed, quality, or control.

Independent 3rd party benchmarks from ArtificialAnalysis.ai
Speed at any Scale
Other inference slows down when the real work starts. Groq has sub-millisecond latency that stays consistent across traffic, regions, and workloads.

Model Quality You Can Trust
Groq’s architecture is built to preserve model quality at every size—from compact and voice models to large-scale MoEs—consistently and at production scale.


