.png)

On 20 August 2024, the ActiveSG team was alerted to an unusual issue where two users reported seeing another user's information after logging into their accounts on the ActiveSG application.
We immediately declared a production incident and took prompt steps to triage, mitigate, and resolve the issue.
Our team resolved the incident on 24 August 2024, and a summary of the key events is below:
We were first notified of the issue reported by a user on 20th August 2024. We began investigations and implemented monitors to detect and alert us immediately if the problem reoccurs. We also implemented a mitigation on 21 August 2024 to prevent further reoccurrences.
We confirmed 3 cases of the issue and subsequently identified and reached out to another 20 potentially impacted users in our investigation. We confirmed that none of them reported data inaccuracies.
The root cause was not a security breach or an application-level bug in MyActiveSG+. Instead, it was caused by an obscure bug in RDS Proxy, an infrastructure component provided by Amazon Web Services (AWS) that we rely on.
These issues occurred on 15th August 2024, when our database was under extremely high load for 10 minutes.
Data retrieved from the database during the 10-minute window may have been returned incorrectly, causing the issue described above. This occurred sporadically, which explains the limited number of user reports.
As an added precaution, we reversed all critical changes to user data made during the 10-minute window.
The issue was immediately reported to AWS upon discovery. AWS investigated and determined it occurs only under specific conditions. AWS has since resolved the issue. You may read more about the specific conditions here.
We prepared this article to share openly about what happened, how we addressed it, and what we learned. This is part of our commitment to being transparent and improving how we handle production incidents.
RDS proxy is a tool that manages connections between applications and databases.
During our investigation, we found that requests through the RDS proxy had been mixed up under high load within a 10-minute window on 15 August 2024. This meant that during that small window of time, when a MyActiveSG+ user requested their data, the proxy occasionally sent data meant for another user instead.
During our investigation, we found that database requests for different application users sharing the same client connection could potentially receive responses relating to bind parameters sent in previous requests if the previous request encountered a connection borrow timeout.
After discovering this on 24 August 2024, we stopped using the RDS proxy in our system, and worked with AWS to fix the underlying issue. Our top priority throughout this incident was minimise impact on our users. Here’s how we worked towards that:
Triage
Upon receiving reports of this incident, we immediately diverted all engineering resources and enlisted organisation-wide support to scour through our logs for potential causes.
Engaged our internal security engineering team to conduct a security audit on our code to rule out internal errors.
Investigate
Developed and tested hypotheses around the clock and over several days to reproduce the problem.
Inform
Reached out directly to users to gather more details, assuring them that we took their concerns seriously.
Collaborated with SportSG on operational mitigations: we identified 20 potentially affected users and reached out to them; none of whom had reported observing any data inaccuracies.
Mitigate
Implemented alarms and safeguards to catch any recurrence of the issue, even without fully identifying the root cause at that time.
Increased infrastructure resources to prevent overloads on our services and correlated symptoms.
Triggered a forced log out for all users to secure their accounts.
Reversed all important user actions that had been performed during the affected 10-minute window.
Resolve
Removed the use of RDS proxy after confirming that it was the source of the bug.
Contacted AWS and demonstrated the existence of the bug, leading to a proper resolution of the bug.
Please find our technical post-mortem analysis below.
RDS Proxy is a connection pooler by AWS (akin to PgBouncer). Its main purpose is to minimise resources consumed when opening/closing DB connections.
On ActiveSG, we primarily use this service for the zero-downtime feature it provides during database failovers. Read this AWS article on how RDS Proxy prevents downtime from DNS propagation issues.
The extended query protocol is used whenever there are prepared statements. This protocol splits the processing of a database query into 3 steps: (1) parse, (2) bind, (3) execute within a stream of bytes.
The PostgreSQL Extended Query Protocol is used to send parameterised queries to the database. We use parameterised queries in ActiveSG as it helps to prevent SQL injection vulnerabilities.
On 20 August 2024, two users (User X and User Y) reported that one of them (User X) had seen the other user’s (User Y) information upon logging into the ActiveSG application. Specifically, the unintended information shown was facility booking details, masked NRIC, and mobile number. User X had made bookings which then appeared under User Y’s account.
In response, we immediately launched an investigation to triage the problem while our SportSG colleagues suspended their accounts to protect their information.
Our first priority was to rule out any potential security vulnerabilities in the authentication process. To ensure a comprehensive review, we:
Engaged our internal security team to conduct an in-depth review of our authentication mechanisms.
Collaborated with our identity provider, sgID, to validate our authentication system and review their logs for abnormalities.
Involved technical experts in OGP to validate the implementation, configuration, and infrastructure used in our application.
After thorough analysis, we were confident that the error did not occur at the application level.
At the time, with only a single report, we also considered the possibility of account sharing, given past instances where users had shared their accounts. To address this, we initiated a parallel investigation and promptly arranged meetings with the two affected users.
While reaching out to the affected users, we continued our investigations and noticed the following AWS RDS database error logs that indicated an issue related to the PostgreSQL Extended Query Protocol.
The extended query protocol was used for our queries when we ran unnamed prepared statements — the default way to execute queries in our application.
Error logs that we saw:
bind message supplies 3 parameters, but prepared statement requires 1 bind message supplies 1 parameters, but prepared statement requires 3Specifically, we suspected that query parameters were being incorrectly bound due to some race condition during the bind phase.
A race condition could cause a parameter mismatch between queries, where a prepared statement expecting X parameters to inadvertently receive Y parameters, throwing the error message shown above.
For prepared statements with the same number of parameters, the subsequent request could be served without an error being thrown, even if it received the parameters from the previous request.
The result? Queries could return incorrect user data.
Imagine the following prepared statement:
SELECT * FROM “User” WHERE "User"."uin" = $1;If the parameters were incorrectly bound, it could result in users receiving another user’s data. Here is an illustration of what we deduced the bind phase mix-up to be like at the time:
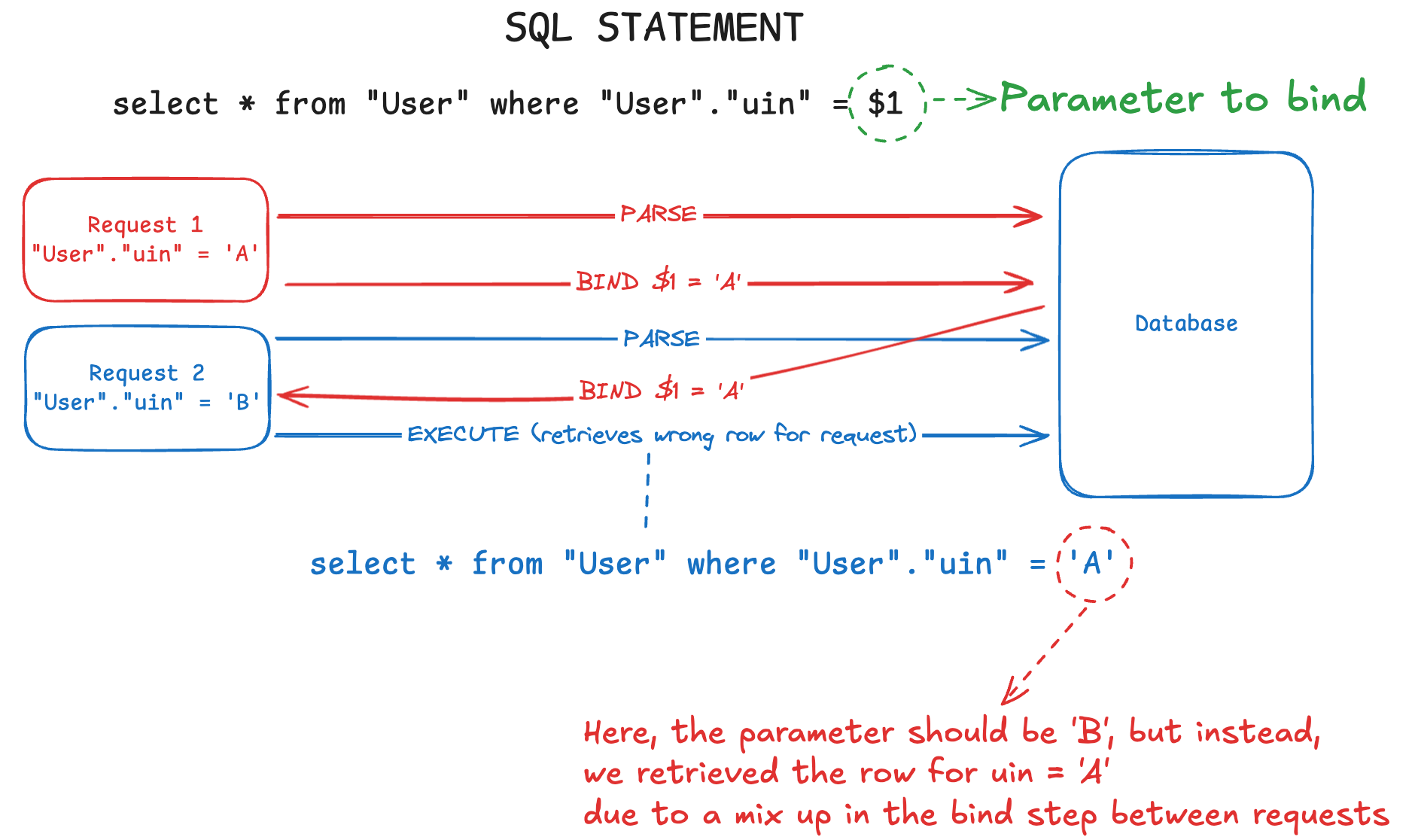
In our case, we hypothesised that query parameters could get mixed up during the login flow as we were retrieving user data to establish their session. This resulted in users logging into the wrong account.
Using the same example above, here is an illustration of how the sessions could have been established incorrectly:
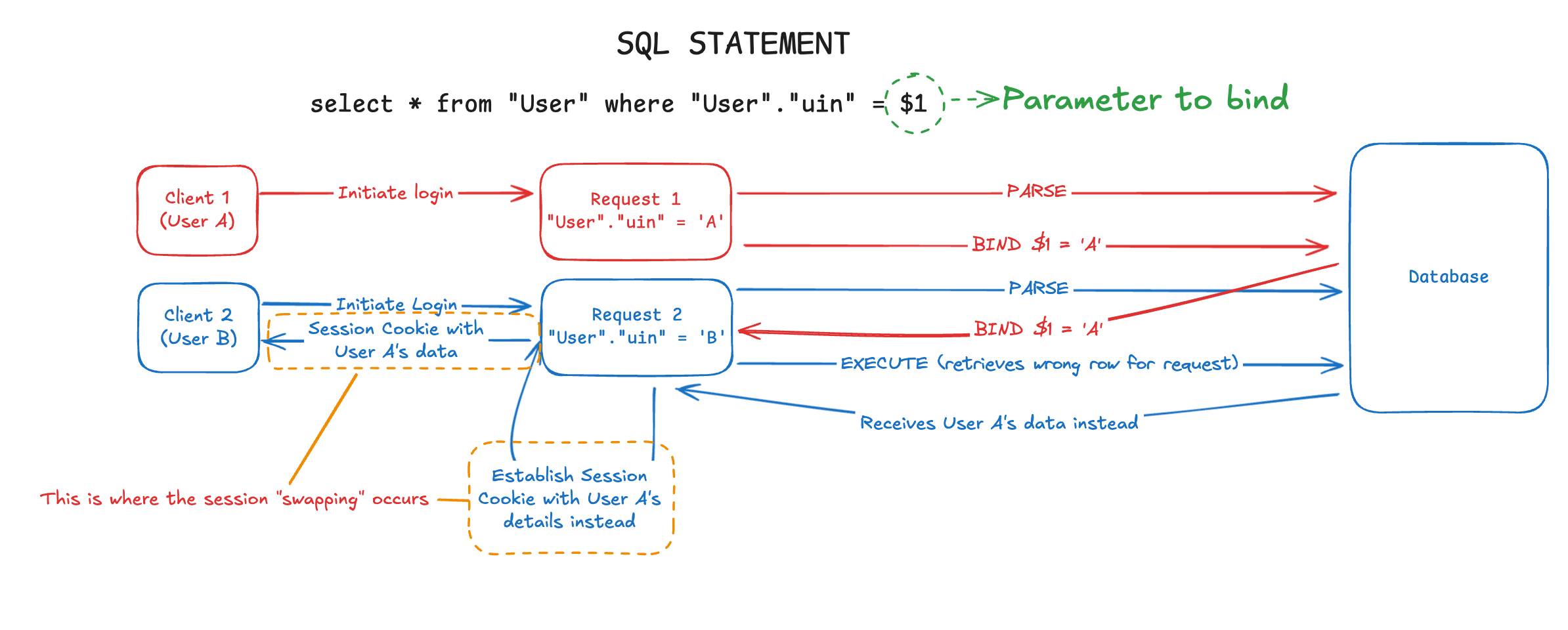
Here we notice that Client 2 (User B) received User A’s details as the established session
We immediately configured alarms to alert us if the error logs were detected again. While the issue did not reoccur, we could subsequently verify that the alarms we implemented were indeed effective in catching instances of incorrect logins.
At this point in the investigation, we identified two priorities for us to work on:
Reach out to the users who reported the issue for further investigation.
Dive deeper into the plausibility of the database incorrectly binding parameters.
The next day, a third user reported experiencing the same issue during the 10 minutes on 15 August 2024, confirming that the problem was not an isolated incident. This ruled out account sharing as a possibility and strengthened our focus on the parameter mix-up hypothesis.
Consequently, we implemented additional mitigations to prevent any further compromises:
Authentication Safeguards
We introduced additional validations in the authentication middleware to detect and prevent potential incorrect binding of parameters in database queries.
For example, we introduced a check that blocked logins if the user’s identifier returned from sgID did not match the one in the database. This was crucial in preventing users from being incorrectly authenticated as one another.
Database Over-Provisioning
While deep diving into the logs, we observed that our database was under extremely high load (due to an unrelated inefficient SQL query) at the specific times mentioned in the reported cases. During the 10 minutes when users reported logging in as one another, our database metrics recorded 100% CPU utilisation.
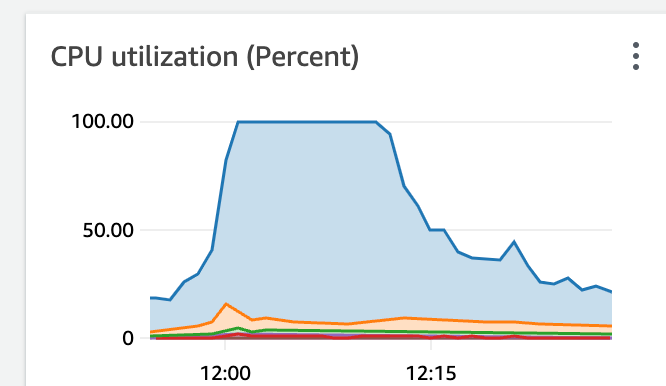
Suspecting that the high load might have contributed to the issue, we decided to over-provision the database and increase its capacity to reduce the likelihood of the CPU reaching 100% utilisation. Additionally, we lowered the thresholds for our alarms and monitors to trigger earlier.
Once the additional mitigations had been implemented, we turned our attention to reproducing the issue and validating that query parameters were being incorrectly bound.
While we continued our attempts to reproduce the issue, we also contacted AWS support regarding the possibility that RDS may have been returning incorrect results during our incident.
We delved further into understanding the state of the database during the 10-minute window when users had reported the issue and found that, on top of a high database CPU load, we had maxed out the number of connections to our database.
Thus, we hypothesised that the following conditions needed to be met:
The database must be overloaded to reach 100% CPU utilisation.
The database must remain operational enough to serve some requests, despite being on the brink of failure.
Concurrent requests must contain the same number of parameters to avoid triggering bind message errors so that the database would return results rather than throwing an error.
Note: We subsequently learned from AWS that these conditions were not sufficient to reproduce the issue, please refer to the "Clarifications and Root Cause Analysis with AWS" section to learn more.
Separately, we needed a method to identify cases where the database returned results intended for a different query.
Our team conducted load tests with various configurations to replicate the conditions. On 22 August 2024, 48 hours after the issue was reported, we successfully reproduced the error.
Our approach was to first generate a unique ID on the application layer, create a SQL statement with this ID as a parameter, and compare the result returned with the generated ID.
Below is a high-level diagram of the logic:
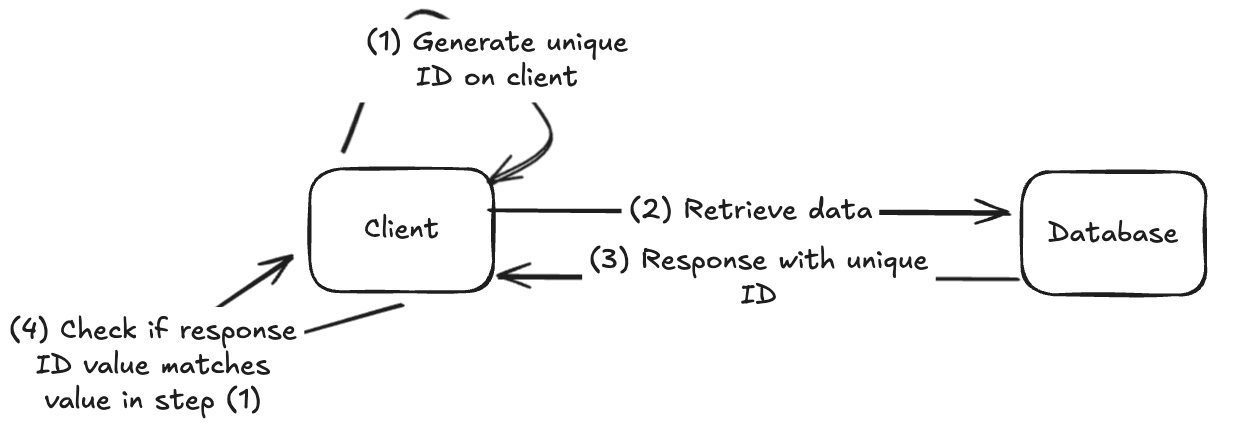
This logic would then be exposed on a route that our load test clients would call.
Code sample for example /test endpoint (using JavaScript, Nano ID, and Kysely)
The following code illustrates how we generated and validated unique IDs:
test() { // Assume that 'GuKhUJ6RmVDNaTjvvl2Ez' was random ID generated. const randomId = nanoid() const res = await db .selectFrom('Table') .where((eb) => eb.or([ eb(sql.lit(`true`), '=', sql.lit(`true`)), // On hindsight we realised this condition wasn't necessary eb(sql.val(randomId), '=', sql.val(randomId)), ]), ) // When wrapped in sql.val, the random ID is substituted in as // a parameter to the prepared statement. // (This means that it is injected in as part of the bind step.) .select(sql.val(randomId).as('parameterizedId')) // When wrapped in sql.lit, the random ID is substituted into // the prepared statement as a literal. // (This means that it is injected in as part of the parse step.) .select(sql.lit(randomId).as('literalId')) .execute() // If any of the returned values do not match the originally generated ID, // (GuKhUJ6RmVDNaTjvvl2Ez), we log an error. if ( res.parameterizedId !== randomId || res.literalId !== randomId || res.parameterizedId !== res.literalId ) { console.error('> MISMATCH!', JSON.stringify(res), randomId) } }For a randomId of GuKhUJ6RmVDNaTjvvl2Ez, the generated SQL statement becomes:
SELECT $1 AS "parameterizedId", 'GuKhUJ6RmVDNaTjvvl2Ez' AS "literalId" FROM "Table" WHERE ( 'true' = 'true' OR $2 = $3 );The expected behaviour is that parameters $1, $2, and $3 would all equal GuKhUJ6RmVDNaTjvvl2Ez for a single query.
Furthermore, to rule out the possibility of issues with the underlying JavaScript PostgreSQL library we used, we patched the library to log the SQL statement just before it was sent to the network. With this injected logging statement, we were able to definitively ascertain that the library was working as intended and that the statement was being sent with the correct parameters.
"SELECT $1 as \\"parameterizedId\\", 'GuKhUJ6RmVDNaTjvvl2Ez' as \\"literalId\\" from \\"Table\\" where ('true' = 'true' or $2 = $3)" | parameters: ["GuKhUJ6RmVDNaTjvvl2Ez","GuKhUJ6RmVDNaTjvvl2Ez","GuKhUJ6RmVDNaTjvvl2Ez"]Although the parse and bind statements were correctly sent by the library, we detected log messages indicating that we had received two distinct values (hV4WYXUsU4Nk_IA5ElB-X and 3nBLvrsTHiyg7oMcJYb3J) in the response returned from the database. Neither of which were equal to the ID sent to the database.
"> MISMATCH! {"parameterizedId":"hV4WYXUsU4Nk_IA5ElB-X","literalId":"3nBLvrsTHiyg7oMcJYb3J"} GuKhUJ6RmVDNaTjvvl2Ez"At this point, we deduced that it was possible for parameters to be incorrectly bound to a different request and verified our hypothesis.
As we had successfully reproduced the issue, we immediately reached out to the AWS team again to update them on our latest findings.
We suspected that the issue could be related to RDS proxy as similar issues had been encountered on another database connection pooler, PgBouncer.
To confirm our suspicion, we repeated the above experiment 10 times:
Five runs were conducted when our application was connected to the database through RDS proxy
Five runs were conducted when our application was directly connected to the RDS database
The results of the tests are as follows:
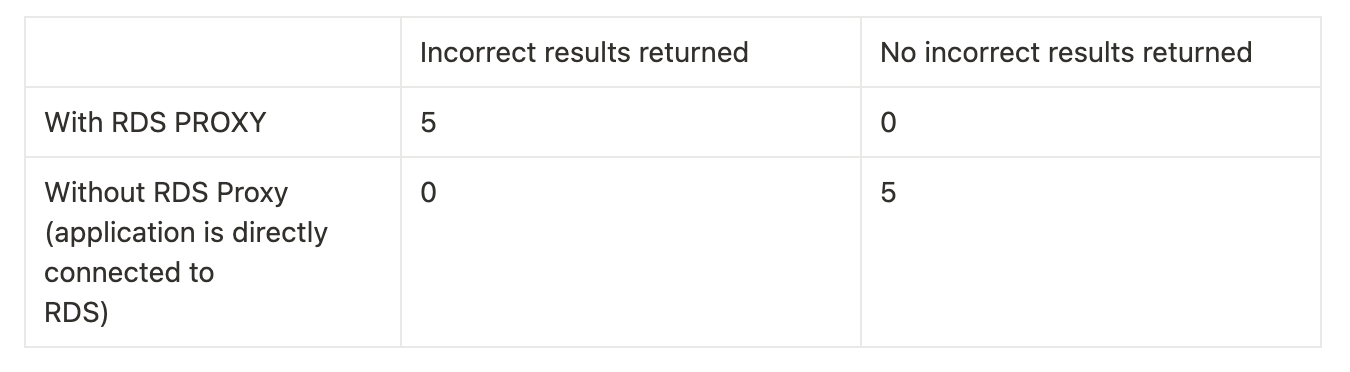
As such, we were confident that removing RDS proxy would prevent the parameters from being mixed up and temporarily remove its use as an additional mitigation.
After reproducing the issue, we reached out to the AWS team again to share our findings. We produced two scripts and provided them to the AWS team so that they could reproduce the issue.
The two scripts are open-source and linked below:
They have since resolved the underlying conditions for this bug, and it is no longer reproducible. We have also resumed usage of RDS Proxy.
Earlier, we had hypothesized that the bug occurs when CPU load reaches 100% but the database still successfully returns some results. During a post-incident follow-up with AWS, they shared the root cause and clarified the implications and necessary conditions of the bug we experienced.
The client must use client-side connection pooling.
The application must be using PostgreSQL extended protocol.
There must be prolonged periods of high DB CPU utilization and a number of DB connections close to the limit.
The high DB CPU utilisation must result in a ConnectionBorrowTimeout error.
The client or driver did not close the connection upon receiving this error.
Requests serving different application users must go through the same client connection.
If 1-6 occurs, then a subsequent database request sharing the same client connection could potentially receive responses relating to bind parameters sent in previous requests.
If two consecutive prepared statements have identical parameter counts and types but different parameter values, then the second statement can incorrectly use the first statement's parameters without raising an error.
AWS confirmed that they addressed this issue in the Asia Pacific (Singapore) Region by September 12, 2024, and resolved it in all AWS Regions by October 2, 2024.
A key takeaway from this incident was how it was easy to dismiss root causes because of their improbability. During the initial hours while the team was hypothesising what could have gone wrong with the system to result in such symptoms, the possibility that the database had returned wrong results was raised. However, it was almost immediately dismissed because of their improbability. The hypothesis was only re-looked into after all other leads had been exhausted.
We are grateful to our users for reporting these issues. Without their diligence, this issue could have gone undetected. Their timely report allowed us to contain the issue within a day, reproduce the behaviour within 48 hours and fully resolve it within a week.
Thanks to the collective efforts of our users, engineering colleagues, the SportSG operations team, and the AWS team, we were able to limit the impact to just three affected users and prevent further cascading consequences.
Authored by Austin, Dexter, Xian Xiang, Kishore, Blake, Sebastian, and Petrina on behalf of the ActiveSG team.
![One Company Poisoned the Planet [video]](https://www.youtube.com/img/desktop/supported_browsers/edgium.png)


