.png)


It’s no secret that large language models are trained on massive amounts of data - many trillions of tokens. Even the largest robot datasets are quite far from this; in a year, Physical Intelligence collected about 10,000 hours worth of robot data to train their first foundation model, PI0. This is something Andra Keay writes about on substack: the huge question of the “robot data gap.”
A quick read of this would indicate it will take tens to hundreds of thousands of years to get this much data; but fortunately, there are a lot of ways we might be able to speed that process up, including:
Scaling robot fleets
Using simulation data
Using human video data
Which, combined together, actually paint a fairly rosy picture — with a large robot fleet, our Robot GPT could at the very least have enough data to train on. But the resources necessary will clearly be out of reach for any academic lab, and will likely require a fairly substantial investment.
Let’s take a closer look.
I think in some ways these numbers are a bit optimistic in some ways. Let’s do this ourselves. First, we’ll simplify. Assume we have a robot that can collect 1 (valuable) token per frame at 10 frames per second. We make this assumption because, largely, robot tokens are not as valuable as LLM tokens - the information Qwen or Llama is trained on is very semantically rich, whereas robot frames often have a lot of redundant information. To put it another way: machine learning works best the closer you are to an independent and identically distributed (iid) dataset; neither web data nor robot data is iid, but robot data is far less iid than web data.
Okay, now let’s assume the robot collects its data all day, every day, forever. A year has 365.25 days × 24 hours × 3600 seconds = 31,557,600 seconds total; at 10 fps, to get to 2 trillion tokens, we need 6,377 years worth of data (rounding up).
Now, that’s assuming it runs 24/7, and is getting useful data every second of every day, which seems wildly implausible. Let’s say we 10x it, and then round up a bit more - call it 70,000 robot-years to get to our 2 trillion (useful) token llama2 dataset.
Far too long for our lone robot. But our robot isn’t alone. Prof. Ken Goldberg talks about a few ways to close this massive data gap. From Andra Keay’s blog:
Goldberg proposed four methods to close the data gap: simulation, video data, human teleoperation, and real-world production data. He stressed the importance of reliability and adaptability in robotics, advocating for a balanced approach that integrates data with traditional engineering practices."
Let’s take a look.

There are a lot of robots in the world. Hundreds of thousands of AMRs are shipped every year, although these probably don’t produce the most useful data — most are deployed in samey factories and warehouses. Still, some are predicting this number will reach the low millions by 2030; there will genuinely be a lot of robots out there in the world. And there were over four million industrial robots — fixed-base arms — operating in factories all over the world in 2023.
There is probably a huge market for robot dogs; Boston Dynamics had sold over a thousand robots as of late 2023. The market for robot dogs will only continue to grow; there’s serious interest in robot dogs as pets and companions, as police, and for inspections and so on. Then there are the drones: there are 1 million+ drones registered in the United States alone. Skydio, the largest US drone manufacturer, has built over 40,000 of them. And that’s not to mention burgeoning areas like service robotics and eldercare. I could go on, and on, but basically: we, collectively, have a ton of robots out there doing stuff right now.
The problem is that they’re producing very little useful data.
As I have covered in the past, the most important thing for scaling robot learning is that robots need to be performing a wide diversity of tasks in a wide range of environments. Most deployed robots are doing the same task, over and over again, in the same environment. So the pool of useful robots for learning “robot GPT” is going to be quite a bit lower — even laboratory environments almost certainly don’t cut it, being too simplified and clean.
However, there do exist companies building robots which are at least intended to do more. So let’s take a closer look just at humanoids.
There are probably hundreds to low thousands of humanoid robots in the world today. Tesla plans to build thousands more on its own. Hyundai has similarly expressed interest in tens of thousands of Boston Dynamics robots. Six Chinese robot makers, including Unitree and Agibot, have expressed plans to produce a thousand robots in 2025.
Managing a fleet of 1000 robots, running for a year, collecting lots of interesting, meaningfully-diverse data, is likely a billion-dollar project, but it could be done. And that gets us a very large chunk of the way towards our goal. And, note that even though it’s a billion dollar project, there exist two American humanoid companies which could potentially afford it: Figure and Tesla.
Note: I’m going to assume we’re agnostic to how these robots are getting their tokens. Maybe it’s teleop; maybe it’s a model-based controller in a factory, using GPT-4 or Gemini or something for scene understanding. As long as we’re getting interesting, diverse data — successes and failures alike — I think we’re fine.
I’ve written at length about using simulation data to train general purpose robot policies; in short, it’s a very promising direction for building general-purpose robotic systems with a decreased amount of real-world data.
Bringing robot skills from simulation to the real world

Robotics data generation is really difficult and remains a hugely unsolved problem. For general-purpose home robots, data needs to be plentiful, sure, but that data also needs to be diverse along useful axes: you want to be performing the same task on different objects in a wide variety of different environments.
However, I personally believe we probably can’t just use simulation data on its own, so as a guideline for how much robot data we need, we’ll look at the paper “Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation,” by Maddukuri et al., from the NVIDIA GEAR lab and friends [1].
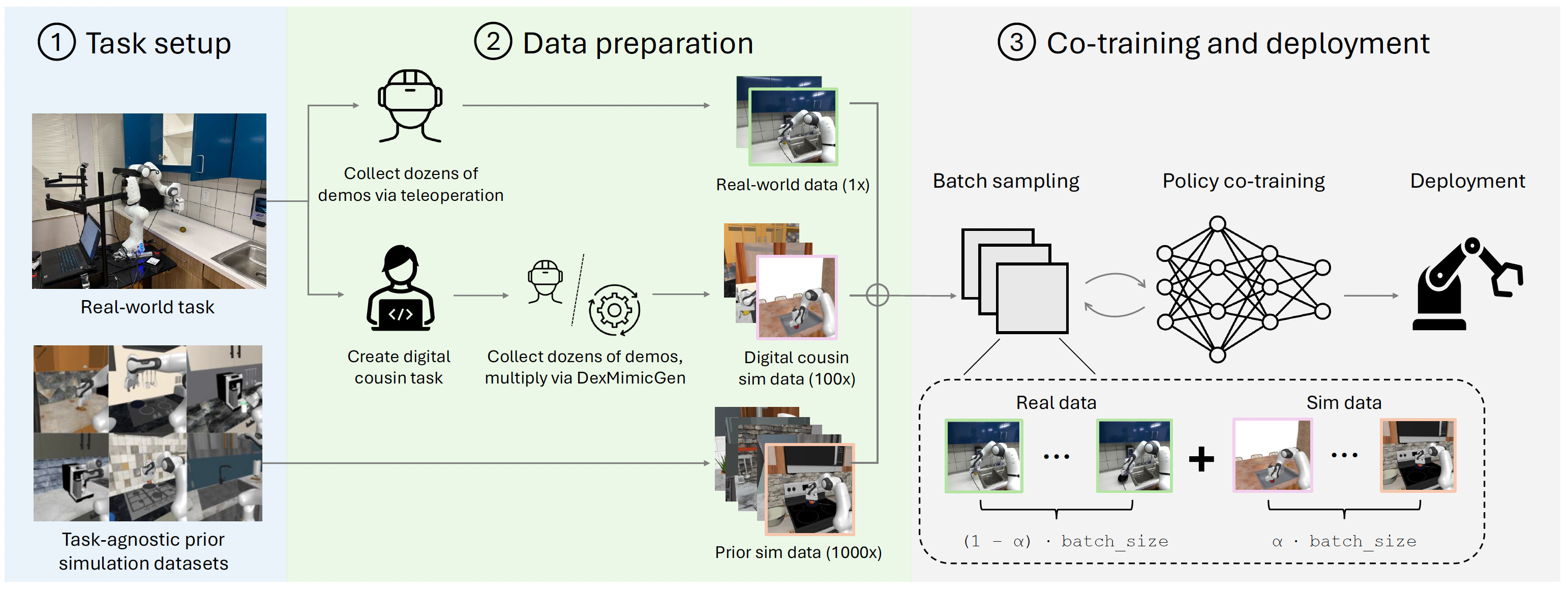
In this paper, they collect 10 demonstrations per task, and use these 10 demonstrations + some “digital cousins” — similar, useful simulation environments — together with various other simulation data they had lying around. For their humanoid robot, they use 10 real demonstrations to get 1,000 simulation demonstrations, so let’s assume that’s our ratio. So, we can decrease our data needs by a factor of maybe 100x using simulation data:
70,000 years / 100 = 700 years
Okay, that’s still a lot of time, but we’re getting closer. In fact, if we assume this scaling holds with the 1,000 robots from the previous section, we’re down to below 1 year!
Personally, though, I doubt we can get that much scaling from simulation indefinitely. Simulation data tends to be good for certain things; like reinforcement learning, it’s not a panacea. So I am inclined to be a bit more conservative with how much it can reduce our data needs.
But we’re not done.
It’s possible to teach robots just from human data. Check out this impressive video from Tesla (source):
This, of course, is far from the only piece of work in this space. Work like EgoZero teaches robot skills human demonstrations collected while users were wearing Aria glasses. I tend to agree with Shreyas Gite on X, who thinks we’ll see an increasing number of robot foundation models that treat human data as just another modality to learn from. Works like Humanoid Policy ~ Human Policy train on both humanoid robot and human data [2]. DreamGen can train its world model on robot task data as well [3]. We can use [2] as a reference here; here’s the relevant table:

So, call it a 10x ratio of human video data to humanoid robot data.
So lets bring this together. I’ll assume 1,000 robots, 10 years of simulation data for every year of robot data, and another 10 years of human data.
70,000 years / 1000 robots / 10 sim-years per robot year / 10 video-years per robot year = 0.7 years
This would be a billion-dollar project, but it seems pretty feasible to me. Go ahead and tweak the numbers yourself; you may be more inclined to stick with my initial estimate of 1000x as much simulated as real data, for example.
If all that pans out — if we have a massive, 1000 robot fleet, with corresponding compute resources and human teleoperators collecting data, it seems actually pretty feasible to get to the 2 trillion tokens you’d need to train a “robot llama2” in just a few years.
Now, as I said at the beginning, I’m making a ton of assumptions here:
We need sufficient interesting data, which means lots of task diversity. That’s actually very hard to get, and it’s part of why I emphasized real robot deployments earlier in this writeup — I think laboratory settings will not cut it. But I also think industrial settings are unlikely to thrive.
I’m pretty bearish on how useful individual robot trajectories will be; if you’re more optimistic, data collection will scale far faster. Remember, I was assuming 10 tokens per second. Each image will be at least hundreds of tokens in reality — I’m just assuming they’re not useful. Maybe I’m wrong.
I’m assuming that different data modalities “stack,” i.e. that simulation data and human data are accomplishing fundamentally different things, and so the benefits of diverse human data and diverse robot data can both apply to the task of accelerating training of a general robot foundation model. It’s possible this is false; what if we need fundamentally more robot data because the “hard part” of robotics turns out to be physically modeling complex interactions between a robot’s gripper and its environment?
In general, though, I think the numbers paint a mostly optimistic picture — it’s not out of the question that any number of companies could get to many trillions of tokens of robot data. A consortium of companies, or a government-directed “Manhattan Project” for AI, almost certainly could get there in a matter of years. The biggest issue will be pooling all of this data in one place and actually putting it to good use.
If you liked this post, please subscribe for more content on robotics and AI. And please leave a comment with your thoughts: agree, disagree, or just want to quibble with my made-up math.
And if you want to learn about what this data actually needs to look like, and why I keep talking about data diversity, you can check out my previous post:
[1] Maddukuri, A., Jiang, Z., Chen, L. Y., Nasiriany, S., Xie, Y., Fang, Y., ... & Zhu, Y. (2025). Sim-and-real co-training: A simple recipe for vision-based robotic manipulation. arXiv preprint arXiv:2503.24361.
[2] Qiu, R. Z., Yang, S., Cheng, X., Chawla, C., Li, J., He, T., ... & Wang, X. (2025). Humanoid Policy~ Human Policy. arXiv preprint arXiv:2503.13441.
[3] Jang, J., Ye, S., Lin, Z., Xiang, J., Bjorck, J., Fang, Y., ... & Fan, L. (2025). DreamGen: Unlocking Generalization in Robot Learning through Neural Trajectories. arXiv preprint arXiv:2505.12705.
![Theory of Self-Reproducing Automata [pdf]](https://news.najib.digital/site/assets/img/broken.gif)

