.png)

Part 1 of this series is here, and looks at the reason inference time compute is so important, but also why optimizing for that is a lot of work. This part looks at the results we obtained running models on Amazon Bedrock against CRMArena.
We chose CRMArena because at Neurometric we are focused on real world benchmarks, and CRMArena was synthetically generated by Salesforce to mimic real world CRM data. It consists of several tasks. For purposes of this post, we tested on “activity priority,” “lead routing,” and “name identity disambiguation.” We tested on several versions of models including LLama, Qwen, GPT-OSS, Deepseek and Amazon’s own Nova models. For each model, we ran 3 inference time compute algorithms: Chain of Thought, Best-of-N majority vote, and Best-of-N weighted vote.
There are two core findings from our research that are relevant to AI systems designers.
Different ITC algorithms perform differently on different models.
The performance on different CRMArena tasks varies significantly by ITC algorithm.
The takeaway is that ITC algorithm selection matters as much as model selection, and is dynamically impacted by model selection. In other words, don’t choose a model to solve your problem, choose a model+algorithm combo. Or, to make it even more simple, don’t choose an AI model, choose an AI system.
Note: this initial analysis is just looking at performance on the task. We will post more soon that factors in cost, latency, and other issues that also could be considered performance based variables.
Let’s start by looking at the performance on the activity priority task.
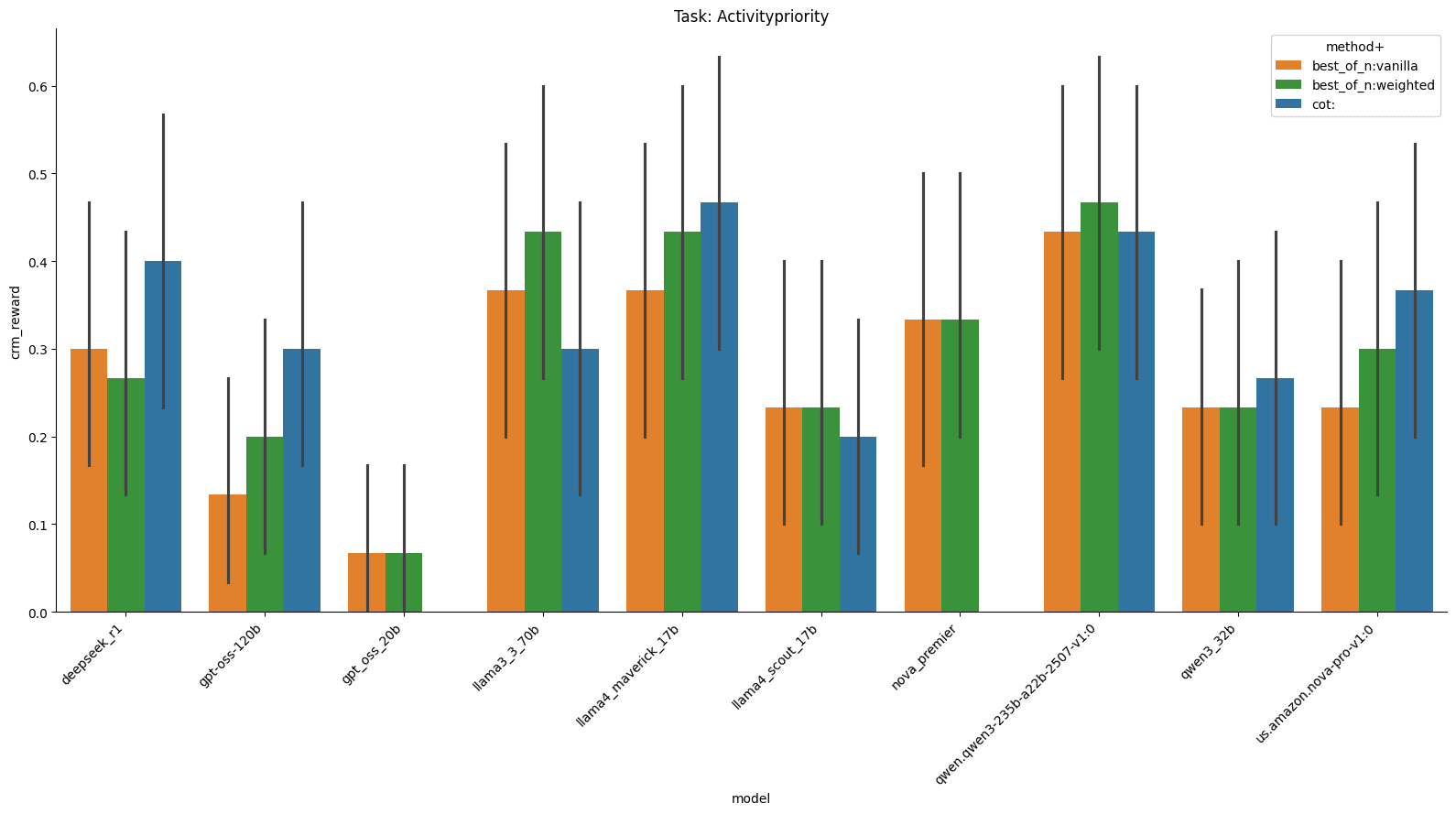
What’s interesting here is that CoT is the best algorithm on most of these but on Llama 3 70B, Best of N weighted performs better. It also wins on Qwen3 235B.
In this chart on lead routing, we see that Best-of-N consistently beats CoT on almost every model we tested except Deepseek, but has a particularly strong impact on GPT-OSS-120b and DeepSeek-r1..
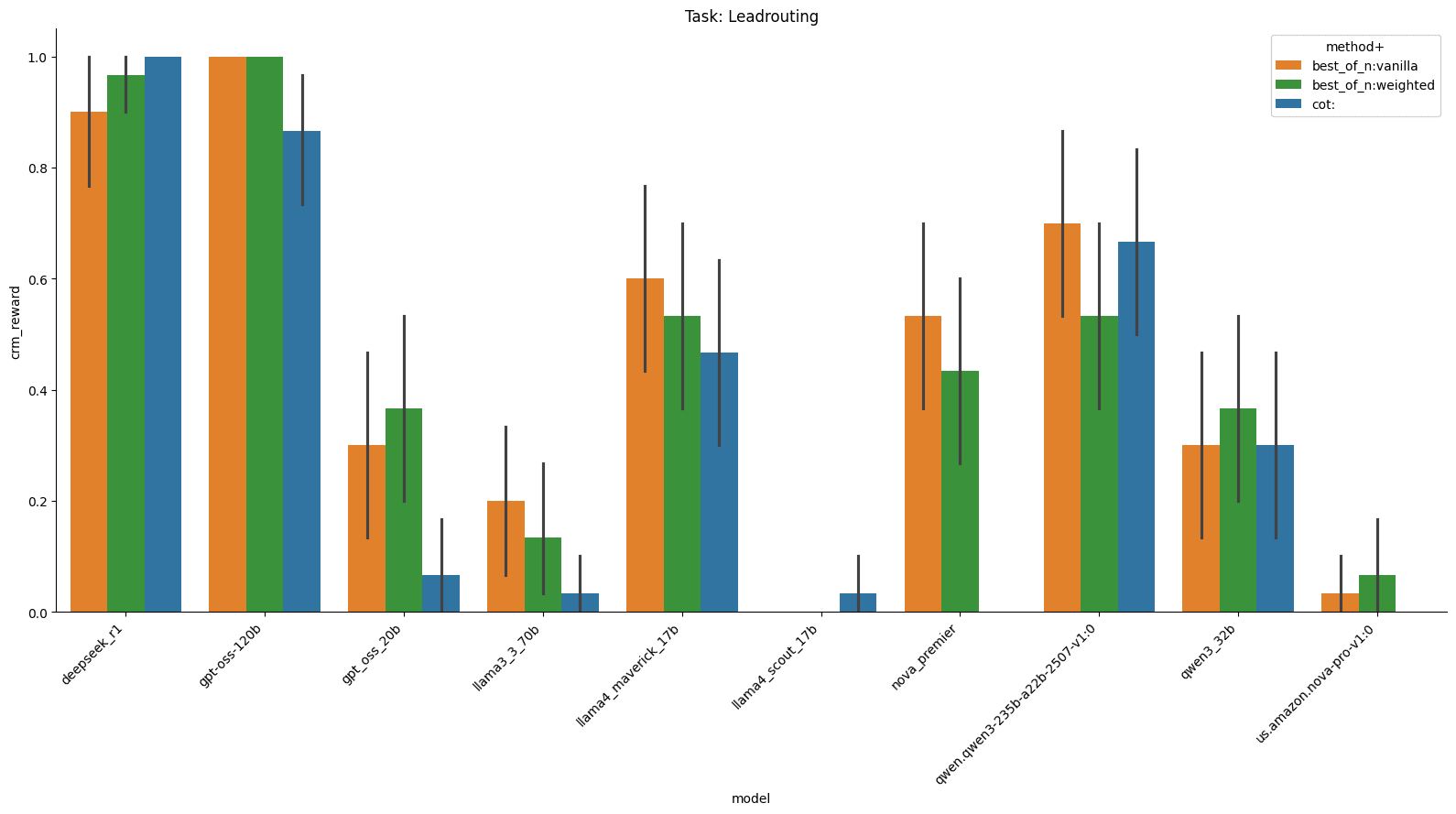
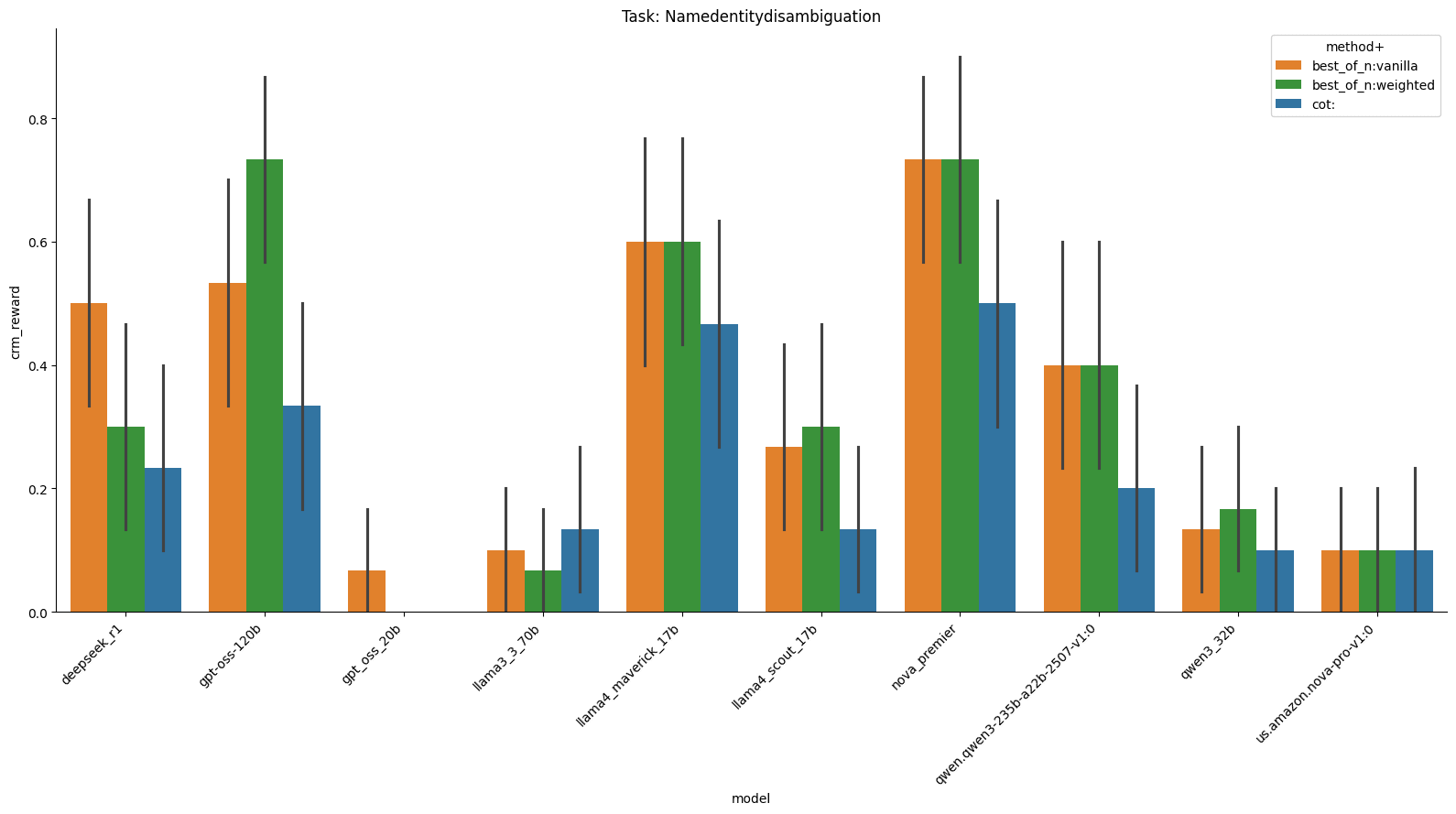
For name identity disambiguation, we see that Best-of-N weighted typically outperforms everything else.
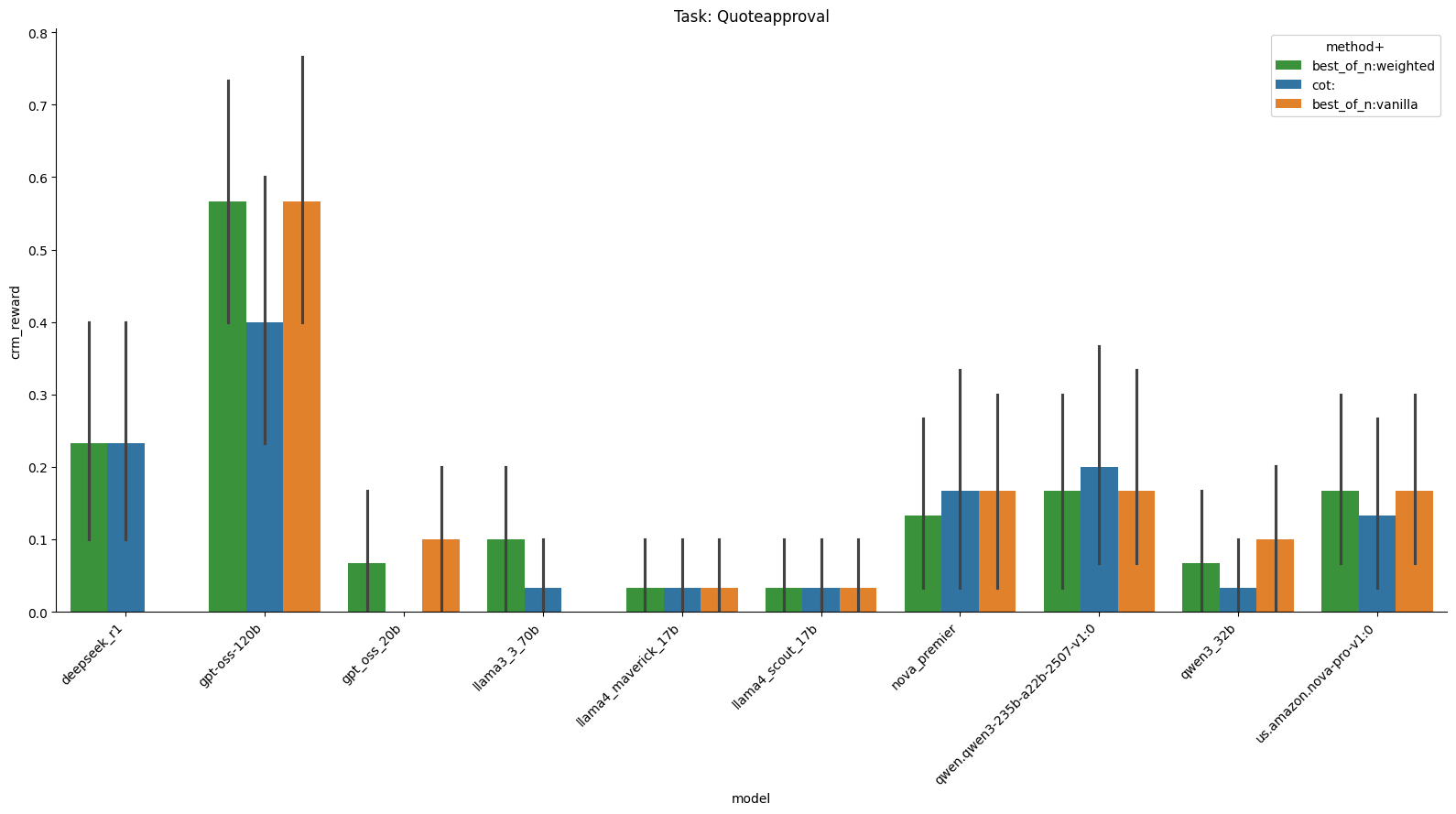
When it comes to quote approval, only GPT-oss 120b really performs well on this task.
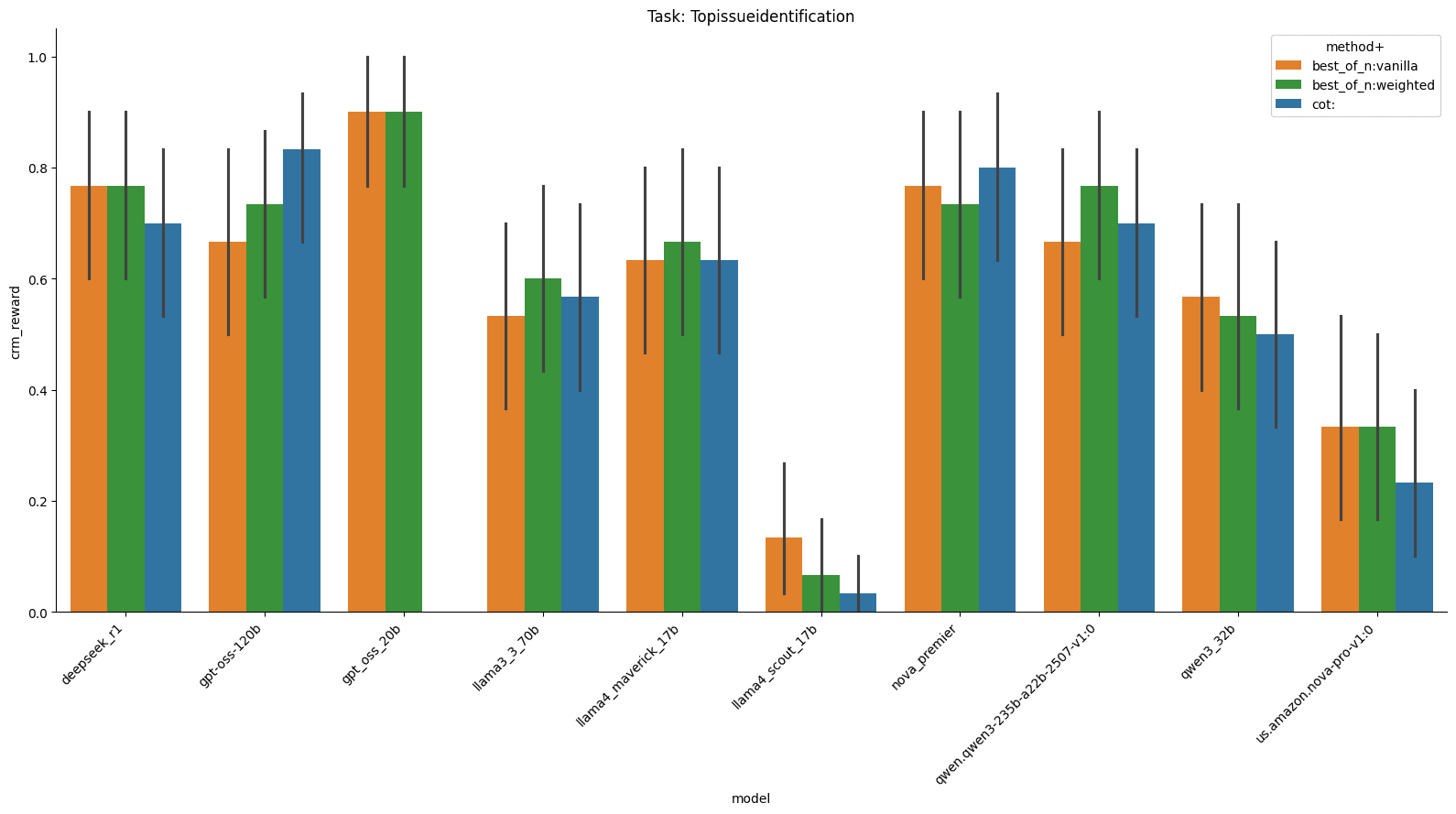
On top issue identification, almost everything works well except Llama 4 Scout 17b
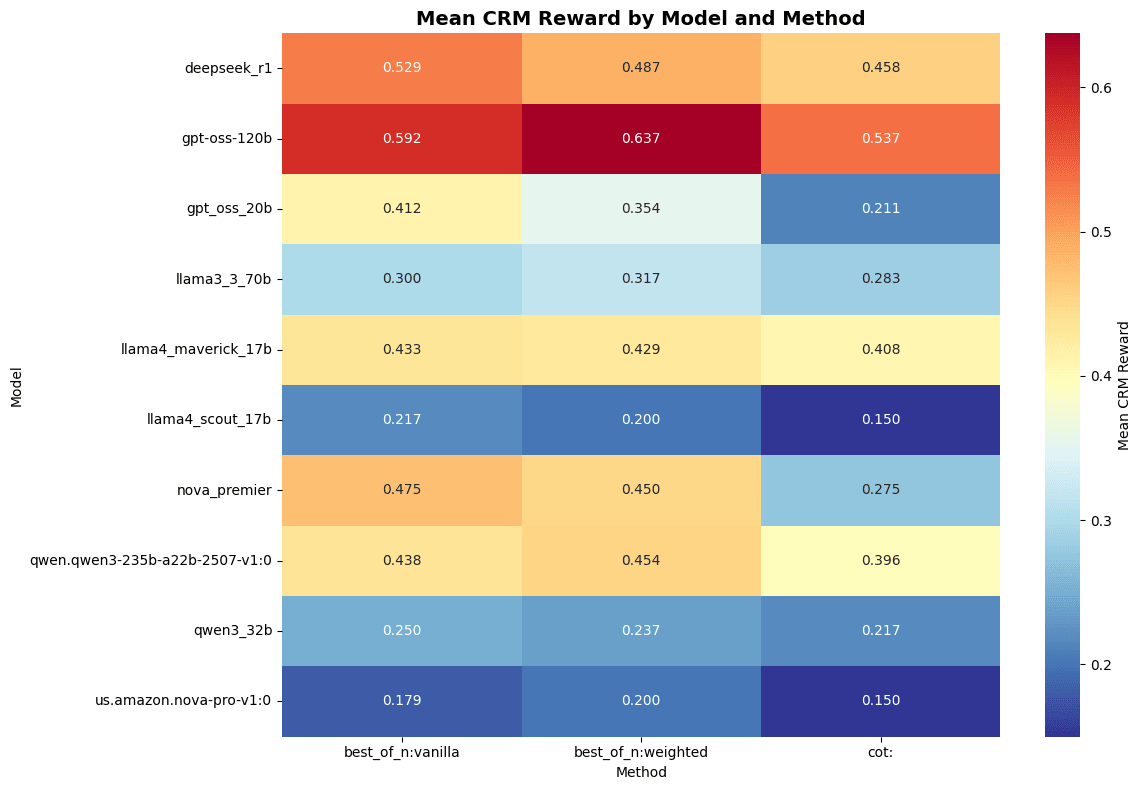
Now lets move away from task specific data and look at the mean CRM reward by model and method (red colors are better).
We’ve double check all this but, I will say these runs are complicated and many factors affect them so if we find any errors we will update this post.
The lesson here is that the market is going to have to move from models, or even simple model routing, to more complicated systems orchestration to map AI workloads to inference configurations that work best to optimize for the variables that matter to your business.
In part 3, we will discuss next steps and further research. If you have ideas or things you would like us to try, or want to collaborate on this, let us know.


