.png)

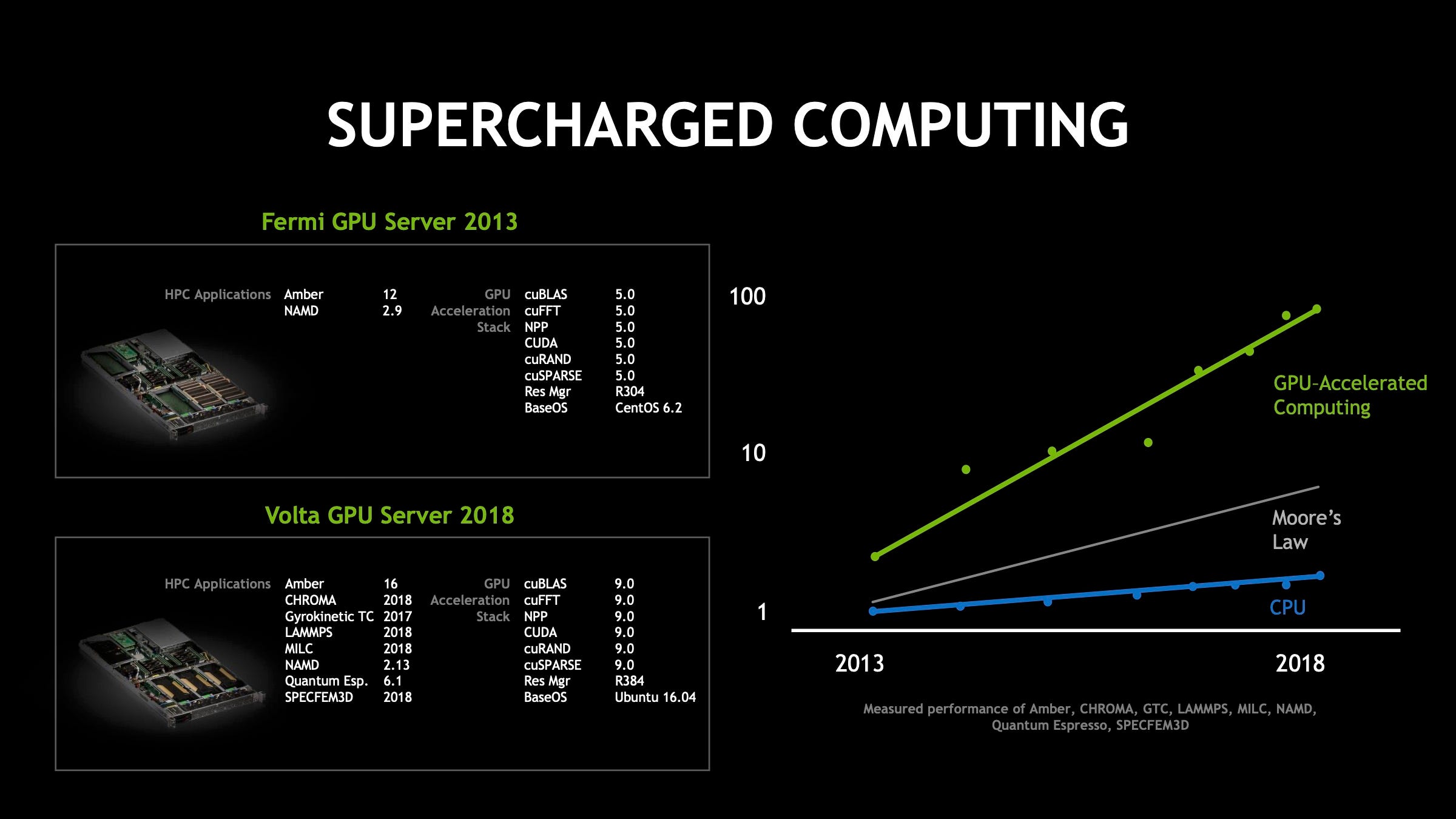
… the speed-up that we created in the last five years is 25 times while Moore's Law is ten times in five years. Moore's law the miracle of laws, the law that has enabled just about every single industry and progress of science and the progress of society, was compounded over time 10x every five years. Our GPUs have accelerated these molecular dynamics simulations 25x in the last five years. There's a new law going on it's a supercharged law. There's a new law going on and I think this is the future of computing …
Nvidia CEO Jensen Huang first referred to a ‘new law’ during his keynote presentation at Nvidia’s GTC conference in 2018.
It didn’t take long for this ‘new law’ to get a name. Tekla S Perry, writing in IEEE Spectrum, reported on the event with:
Move Over, Moore’s Law: Make Way for Huang’s Law
Graphics processors are on a supercharged development path that eclipses Moore’s Law, says Nvidia’s Jensen Huang …
Huang, who is CEO of Nvidia, didn’t call it Huang’s Law; I’m guessing he’ll leave that to others. After all, Gordon Moore wasn’t the one who gave Moore’s Law its now-famous moniker. …
But Huang did make sure nobody attending GTC missed the memo.
The name was picked up by others. Christopher Mim’s in the Wall Street Journal wrote in 2020 that:
Huang’s Law Is the New Moore’s Law, …
But a different law, potentially no less consequential for computing’s next half century, has arisen.
I call it Huang’s Law, after Nvidia Corp. chief executive and co-founder Jensen Huang. It describes how the silicon chips that power artificial intelligence more than double in performance every two years.
Mim’s article quantifies the improvement seen over the previous eight years, based on data supplied by Nvidia’s chief scientist Bill Dally, and - unlike Huang’s keynote - specifically highlights performance on AI related calculations:
Between November 2012 and this May, performance of Nvidia’s chips increased 317 times for an important class of AI calculations, says Bill Dally, chief scientist and senior vice president of research at Nvidia. On average, in other words, the performance of these chips more than doubled every year, a rate of progress that makes Moore’s Law pale in comparison.
The end of the article recognises that Huang’s Law might be a much shorter-lived phenomenon than its predecessor, whilst still being consequential.
It’s also possible that, like Moore’s Law before it, Huang’s Law will run out of steam. That could happen within a decade, says Steve Roddy, vice president of product marketing in Arm’s machine-learning group. But it could enable much in that relatively short time, from driverless cars to factories and homes that sense and respond to their environments.
Given the scale of interest (and investment in) in AI compute that might benefit from ‘Huang’s Law’ I’m a bit surprised that it hasn’t been subject to more discussion.
Perhaps that’s because some believe that it doesn’t exist. For example, in 2020 Joel Hruska in ExtremeTech wrote an article entitled There's No Such Thing as 'Huang's Law with three key challenges (my highlights):
Why Huang's Law Doesn't Exist
First, the existence of an independent Huang's Law is an illusion. … Huang’s Law can’t exist independently of Moore’s Law
Second, it's too early to make this kind of determination. … "Huang's Law" is all of 3-4 years old. Even if we use Dally's 2012 figure, it's just eight years old. It's a premature declaration.
Third, it's not clear that AI/ML improvement can continue to grow at its present rate, … Over the last few years, manufacturers have been very busy picking low-hanging fruit. Eventually, we're going to run out.
Hruska ends with:
I say we give it a decade. If Huang's Law is a real thing now, it'll still be a real thing in 2030. If it isn't, it never existed in the first place.
So who’s right? How valid are Hruska’s criticisms? What is Huang’s Law and is it a ‘real thing’? Or is it just ‘marketing fluff’ and a ‘new law’ that never existed in the first place?
In the rest of this post we’ll try to start to answer these questions - although it’s just possible to scratch the surface in a post like this. A sneak preview of one the conclusions though: Even if you don’t buy into the ‘law’ itself, serious consideration of the thinking behind it is valuable.
First, though, we need some context, and where better to start than with the most famous, and often most misunderstood, technology law of all: 'Moore’s Law’.

Most readers will be familiar with the (revised) version of Moore’s Law: that the number of transistors on microchips doubles every two years.
We looked at the true nature of Moore’s Law last year in Moore on Moore.
Moore on Moore

The definition of "Moore's Law" has come to refer to almost anything related to the semiconductor industry that when plotted on semi-log paper approximates a straight line.
We saw that Moore’s Law:
Is not a ‘natural law’.:
- It’s not really about the underlying physics or chemistry of the devices except that, of course, it’s the underlying physics and chemistry that ultimately constrain how small components can become.Does not predict exponential increases in computer performance.
- We’ve already seen that Moore didn’t predict doubling in performance every 18 months. More components on chips can lead to increases in performance but the relationship is complex and the end of Dennard Scaling around 2006 has meant that the rate of increase in performance has slowed even as Moore’s Law has continued.Is not just about shrinking component sizes
Has been used to create a timeline around which the semiconductor industry can organise itself.
- Moore’s Law ultimately became a self fulfilling prophesy, in part, as firms organised themselves in such a way as to deliver improvements in line with Moore’s predictions. Perhaps, then, more planning than luck!
and then:
If Moore’s Law is not a natural law, then what is it really about? We’ve already had a clue! Let’s go back to Gordon Moore.
Moore’s law is really about economics. My prediction was about the future direction of the semiconductor industry, and I have found that the industry is best understood through some of its underlying economics.
Gordon Moore
…
Trying to cut through this complexity, I think that one (very simplified) way of thinking about Moore’s Law is as the articulation of a virtuous cycle:
Creation of more sophisticated devices … leads to …
A bigger market for the devices … which in turn stimulates …
Investment in R&D and more sophisticated manufacturing … which in turn leads to …
Creation of more sophisticated devices …
Moore’s Law, and it’s prominence, helps us to understand some of the issues with technology ‘laws’ in general. Crucially, I’d argue that they sometimes aren’t ‘rules that will always be obeyed’ but rather useful ways of thinking about the world.
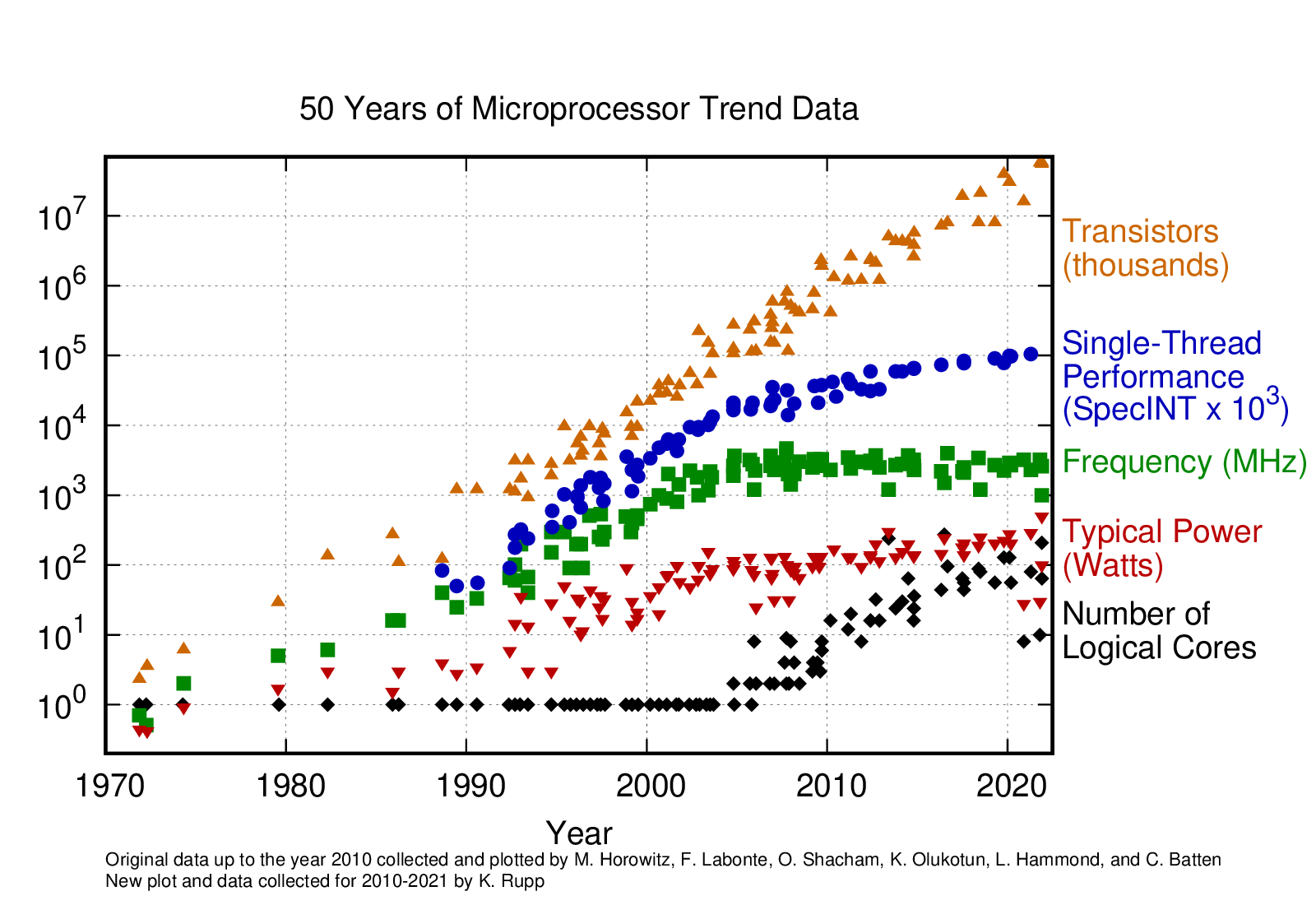
Before we move on it’s useful to emphasise one of the key points above: that Moore’s Law isn’t about performance. We can see from the graph below that one common measure of performance (Single Threaded - SpecINT) has fallen behind the exponential trend of Moore’s Law for more than a decade now.
Our GPUs have accelerated these molecular dynamics simulations 25x in the last five years.
In contrast to Moore’s Law - by definition, both in Jensen Huang’s original 2018 GTC keynote and later statements from Nvidia and elsewhere - Huang’s Law definitely is about performance.
And, whilst that keynote reference to a ‘new law’ didn’t directly refer to Machine Learning (ML) performance, in 2025 it’s ML performance that gets the most focus.
But whilst Huang’s Law describes improvements in compute performance available for use in ML algorithms it excludes (with one caveat, which we’ll discuss later) benefits from improvements in those ML algorithms themselves.
Mary Meeker’s 2025 AI trends presentation has provides an excellent overview of the rapid progress made in the development and deployment of ML models over the last few years. This presentation includes a slide that breaks down the combined impact of ‘Compute scaling’ (I’d call this growth in compute) - some of which is as a result of Huang’s Law and some of which is due to more hardware being deployed - and ‘Algorithmic progress’.
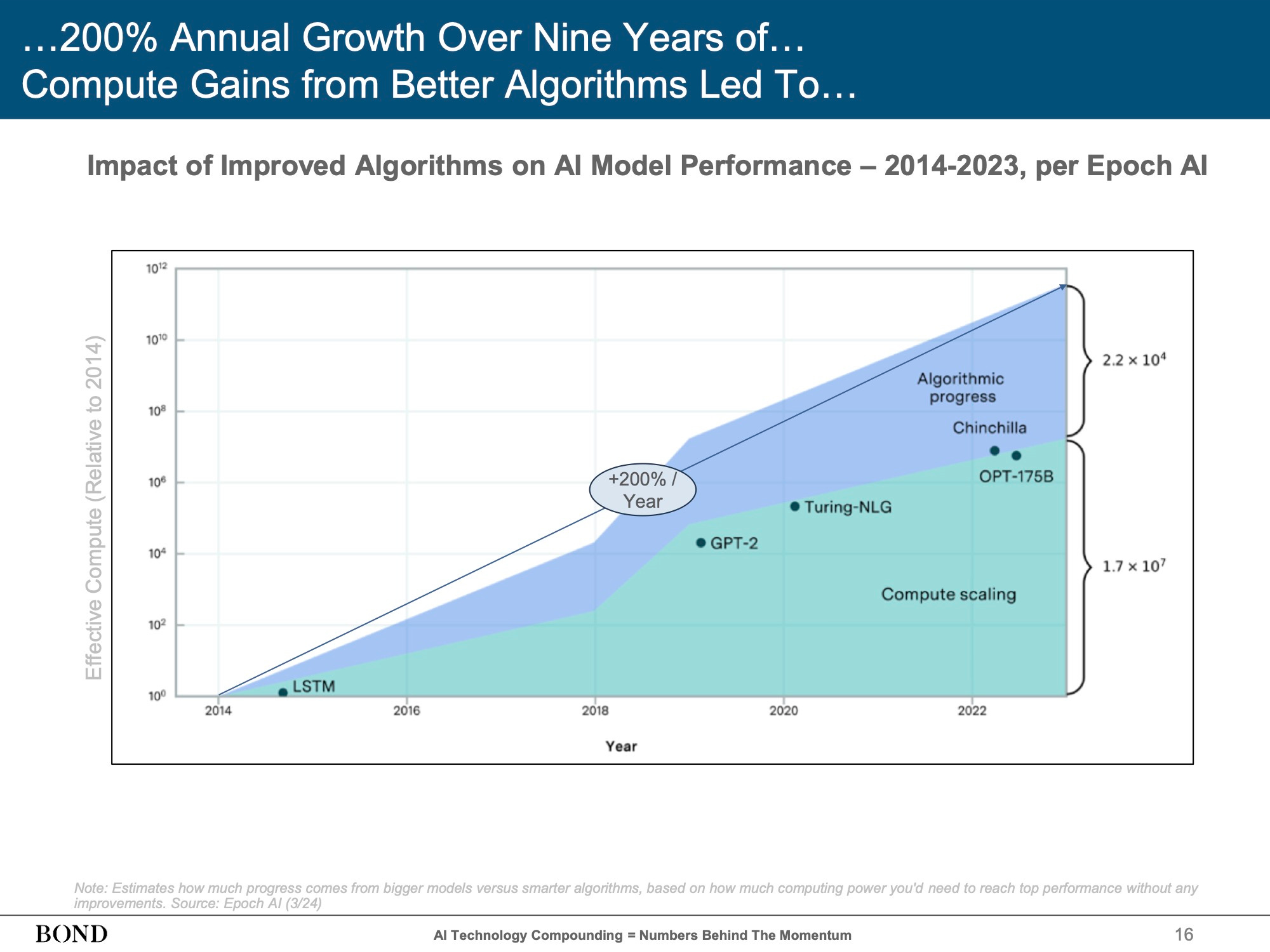
Work done by OpenAI confirms this. In 2020, roughly the time that the earliest discussion of Huang’s Law was getting underway, OpenAI published an article with a backing paper, quantifying the reduction in compute required for AlexNet, one of the most significant early ML programs, in the seven years since that program was first run. The conclusion:
We observed an efficiency doubling time of 16 months
So what has contributed to Huang’s Law?
To see this it’s first useful to set out some ML hardware performance data. For that we can turn to Epoch AI who say that (over the period 2008 to 2025):
The computational performance of machine learning hardware has doubled every 2.5 years.
Measured in 16-bit floating point operations, ML hardware performance has increased at a rate of 32% per year, doubling every 2.5 years…
Which is materially behind the statement of Huang’s Law in the Wall Street Journal - more than doubles every year. Of course this isn’t the full story.
EPOCH AI provide a colourful graph though that illustrates the progression of this performance (in orange) but also charts other operations including 32-bit Floating Point (FP32) and what it labels as ‘TF32 (19-bit)’ and ‘Tensor-FP16/BF16’ (we’ll come to these in a moment). Each dot here represents a piece of hardware used for Machine Learning (ML) and the vertical scale is the number of ‘Floating Point Operations per Second’ (FLOPS).
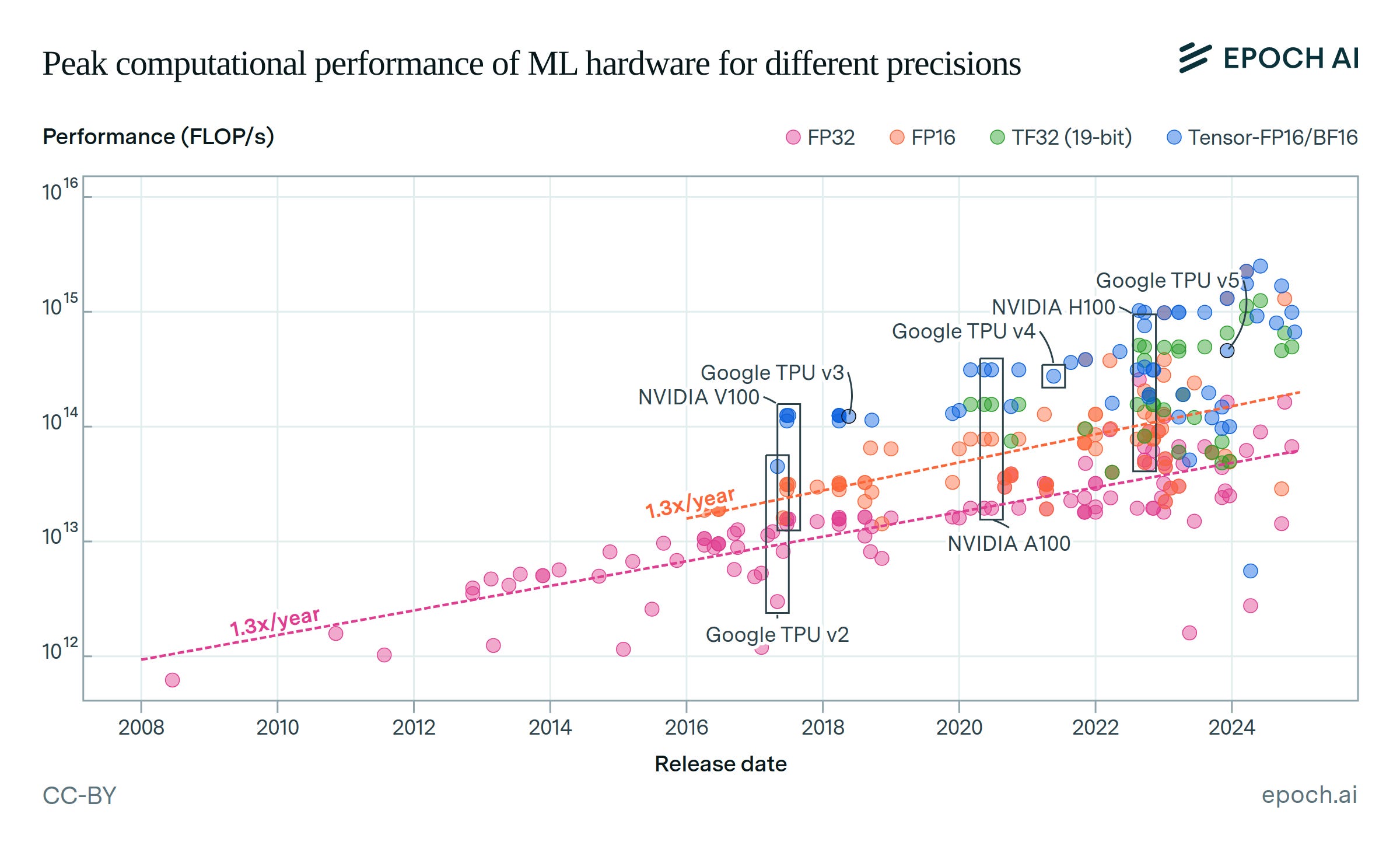
The first thing to observe is that the earlier hardware (starting in 2008) included only had ‘FP32’ precision - in pink - calculations. The first ‘FP16’ hardware only appeared in 2016 followed by ‘Tensor-FP16/BF16’ - in blue- in 2017 and ‘TF32’ - in green - in 2020.
Each of the changes to first provide FP16 and then Tensor-FP16/BF16 delivers a step change in the number of operations per second and each has made an important contribution to Huang’s Law.
What’s happening here?
Reduction in precision - FP32 to FP16
ML researchers have discovered that their algorithms don’t need the full precision that 32-bit Floating Point operations deliver. Using operations with lower precision such as FP16 has several potential benefits:
Hardware designers need fewer transistors for each ‘multiply’ or ‘add’ hardware unit and so can cram more of these units onto each chip of a given size made with a given process technology. They can also remove the hardware that implements higher precision (eg 64-bit) arithmetic to create more room for the lower precision hardware.
Fewer transistors means less heat generated by each unit for a given clock speed and so hardware can potentially run with higher clock speeds for greater performance.
Lower precision formats need less memory and can make better use of constrained memory bandwidth.
Floating Point Operations Designed for Speed
The next change is to move to floating point formats that are designed for higher performance.
TF32 (for TensorFloat 32) is:
… a computational format that is specifically designed for use with TensorCore on Nvidia’s Ampere architecture GPUs. …
On A100, using TF32 for matrix multiplication can provide 8x faster performance than using FP32 CUDA Core on V100. Note that TF32 is only a intermediate computation format when using TensorCore.
and finally:
Lower Precisions Operations Running on Tensor Cores
Tensor-FP16/BF16 represents the performance of lower precision formats (FP16 and BF16) but running on Tensor Cores.
In fact we can go further than using lower precision floating point operations running on Tensor Cores: we can even sometimes use 8-bit integer operations for even more performance.
Even this, though, isn’t the full picture …
It’s now finally time to ‘draw back the curtain’ on the make-up of Huang’s Law as a whole and for that we can again turn to Nvidia’s Chief Scientist Bill Dally who has a terrific - and regularly updated - presentation on the topic. One slide neatly captures the overall progression and its components.
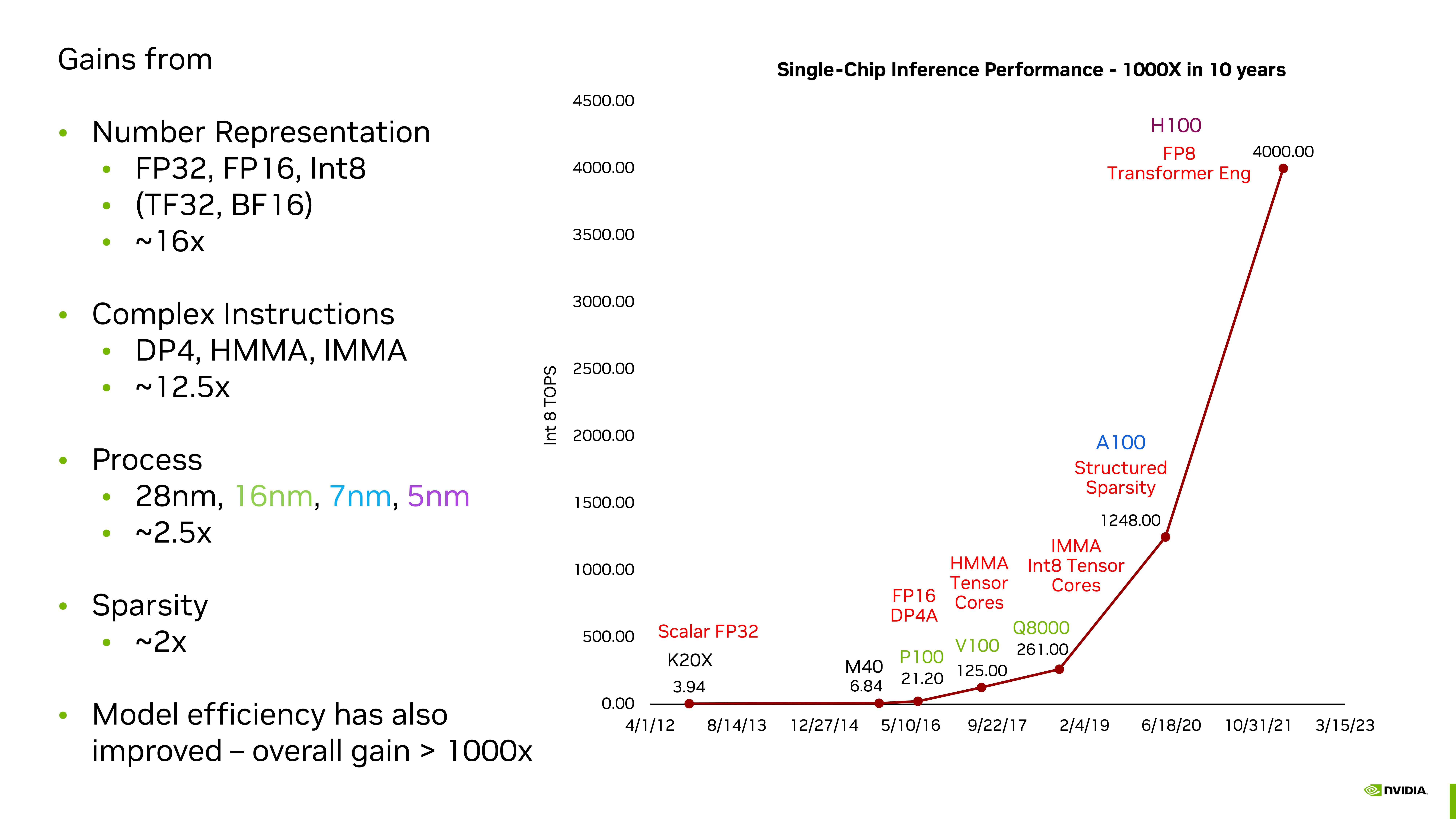
Dally specifies the contributors to Huang’s Law in four categories with their respective (inference) performance impacts:
Number Representation: As we’ve already seen with the shift from FP32 to lower precision, tensor and Integer operations has delivered: 16x
Complex Instructions: This is the use of complex machine instructions :12x
Process: This is the classic ‘Moore’s Law’ progression : around 2.5x
Sparsity Reducing the number of calculations by removing those that have a limited impact on the end result : around 2x
Combining together these factors gives an improvement of : 1000x in 11 years that’s more than 1.8x per annum over 2012 to 2023. That’s not far off Huang’s original 1.9x per annum implied in his 2018 GTC keynote but a bit below the WSJ’s ‘more than doubles every year’.
It’s interesting to see how little Moore’s Law has contributed to these improvements: only 1/40 of 1000-fold improvement here has been categorised as due to process improvements.
Some brief comments on the two contributors that we haven’t mentioned yet:
Complex Instructions
Going against the conventional wisdom, Complex Instruction Set Computer (CISC) architectures provide better performance than RISC designs. Quoting Dally again:
It turns out, you don't want RISC. You want complex instructions to do a lot of work to amortize the cost of that instruction.
And so the next factor of 12.5 came from adding complex instructions. We went from an FMA [Fused Multiply-Add], which is the biggest instruction we had in Kepler, to a four-element dot product, DP4, in our Pascal generation. And then our matrix multiply instructions, HMMA for Half-precision Matrix Multiply Accumulate, and IMMA for 8-bit Integer Matrix Multiply Accumulate.
And that basically amortized out a bunch of the overhead, gave us another 12.5x.
Sparsity
Here is Nvidia on Sparsity at the time of the introduction of the Ampere architecture in 2020:
What Is Sparsity in AI?
In AI inference and machine learning, sparsity refers to a matrix of numbers that includes many zeros or values that will not significantly impact a calculation. …
The goal is to reduce the mounds of matrix multiplication deep learning requires, shortening the time to good results.
The NVIDIA Ampere architecture introduces third-generation Tensor Cores in NVIDIA A100 GPUs that take advantage of the fine-grained sparsity in network weights. They offer up to 2x the maximum throughput of dense math without sacrificing accuracy of the matrix multiply-accumulate jobs at the heart of deep learning.
It’s also useful to note two factors that are not explicitly included in Dally’s exposition:
Hardware and Software Implementation Improvements
Refinements in the implementation of hardware and software over time are to be expected. Engineers discover new approaches and remove shortcuts used to get initial designs to market quickly.
What’s new though is that firms are even using ML to improve these implementations.
What if AI could learn to design these circuits? In PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning, we demonstrate that not only can AI learn to design these circuits from scratch, but AI-designed circuits are also smaller and faster than those designed by state-of-the-art electronic design automation (EDA) tools. The latest NVIDIA Hopper GPU architecture has nearly 13,000 instances of AI-designed circuits.
Hardware Scale
Dally focuses on Single Chip Inference Performance but - as for Moore’s Law - those chips keep getting bigger and Nvidia and others are connecting more and more chips together.
Dally’s assessment doesn’t include the impact of the scale at which ML hardware is deployed though. As datacenters get bigger there are opportunities to remove bottlenecks at the system and datacenter level.
There is a huge amount more to say on Huang’s Law - we’ve barely scratched the surface - and the progression of ML performance over time. With this data, though, I think we can already draw some conclusions.
First on Hruska’s criticisms above:
First, the existence of an independent Huang's Law is an illusion: It’s clear that Huang’s Law depends - but only in part - on Moore’s Law. Performance improvements would have been slower without the benefit of Moore’s Law but we would still have seen dramatic improvements.
Second, it's too early to make this kind of determination: We’ve seen eleven years of improvements now so I think it’s time to give some credit to 2018 Jensen!
Third, it's not clear that AI/ML improvement can continue to grow at its present rate … It’s undoubtedly the case that a lot of ‘low hanging’ fruit - such as moving to lower precision number formats - has been picked by now and will not be repeated and that Huang’s Law will not have the longevity of Moore’s Law. However, the end of Moore’s Law has been predicted for a long time and researchers keep discovering new ways of extending it. We can agree that the future of Huang’s Law isn’t clear, but that doesn’t mean that we won’t see continuing improvements.
Given all this perhaps there is a weaker form of Huang’s Law:
We can expect improvements in the performance of Machine Learning hardware at a faster rate than Moore’s Law but that rate of improvement, initially more than doubling every two years, is expected to reduce over time.
And in any event I think it’s reasonable to say that …
Huang’s Law emphatically is a useful tool to help understand the progression of computing over the next decade or so. Even if you don’t buy into the ‘law’ itself, serious consideration of the thinking behind it is valuable.
Betting against ‘Moore’s Law’ has been a losing strategy for decades. Perhaps ‘I fought the law and law won’ should be the anthem for AI developers.


