.png)

Humanity is stained by the sins of C and no LLM can rewrite them away to Rust
18 Nov, 2025 programming_languages rust c transpilation
Recently, the google security blog put out an article on their experiences introducing Rust in Android, which amongst other things such as reporting an astounding 1000x reduction in memory vulnerabilities, gifted the world with the following beautiful graph:
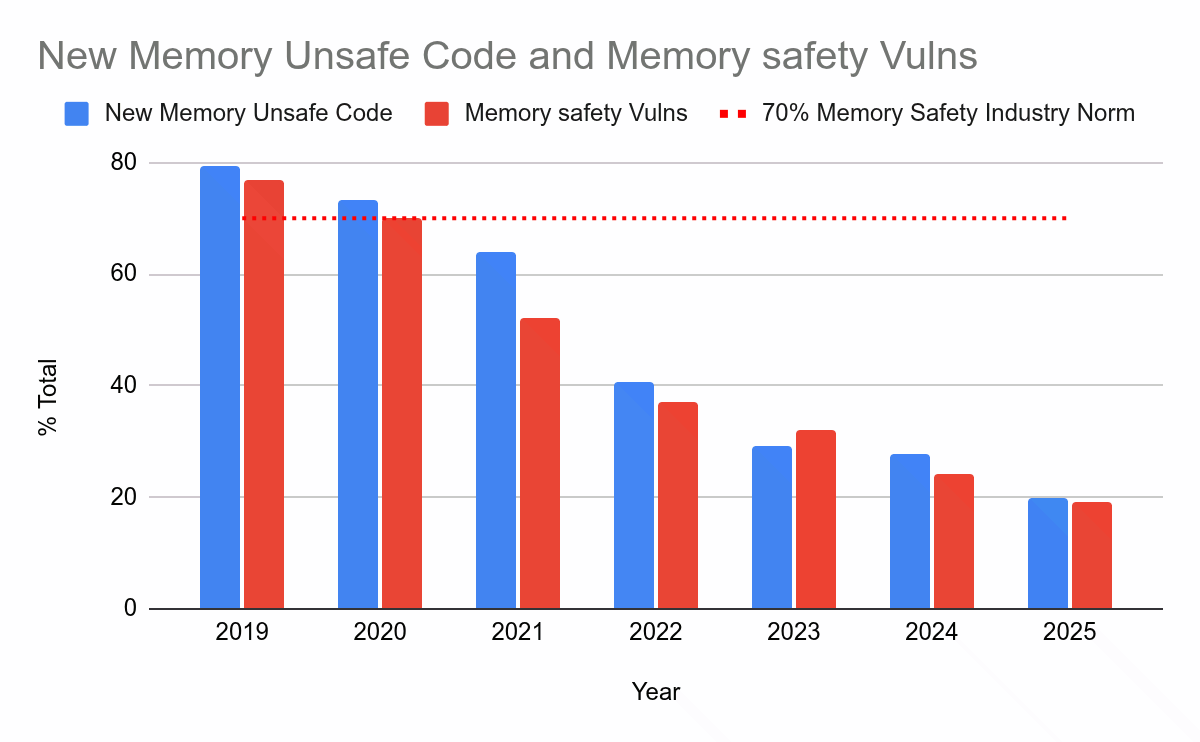
The trends here are indisputable. The facts are clear. Writing code in Rust. Just. Works. No more memory vulnerabilities, no more heisen bugs. It seems the dust has settled, and the verdict is out ---1 Rust has won.

Now, while Rust and similar memory safe languages have been firmly established as the language of choice for any new code and thereby eliminating any bugs, it is important to remember that the majority of all existing systems code is actually NOT written in Rust:
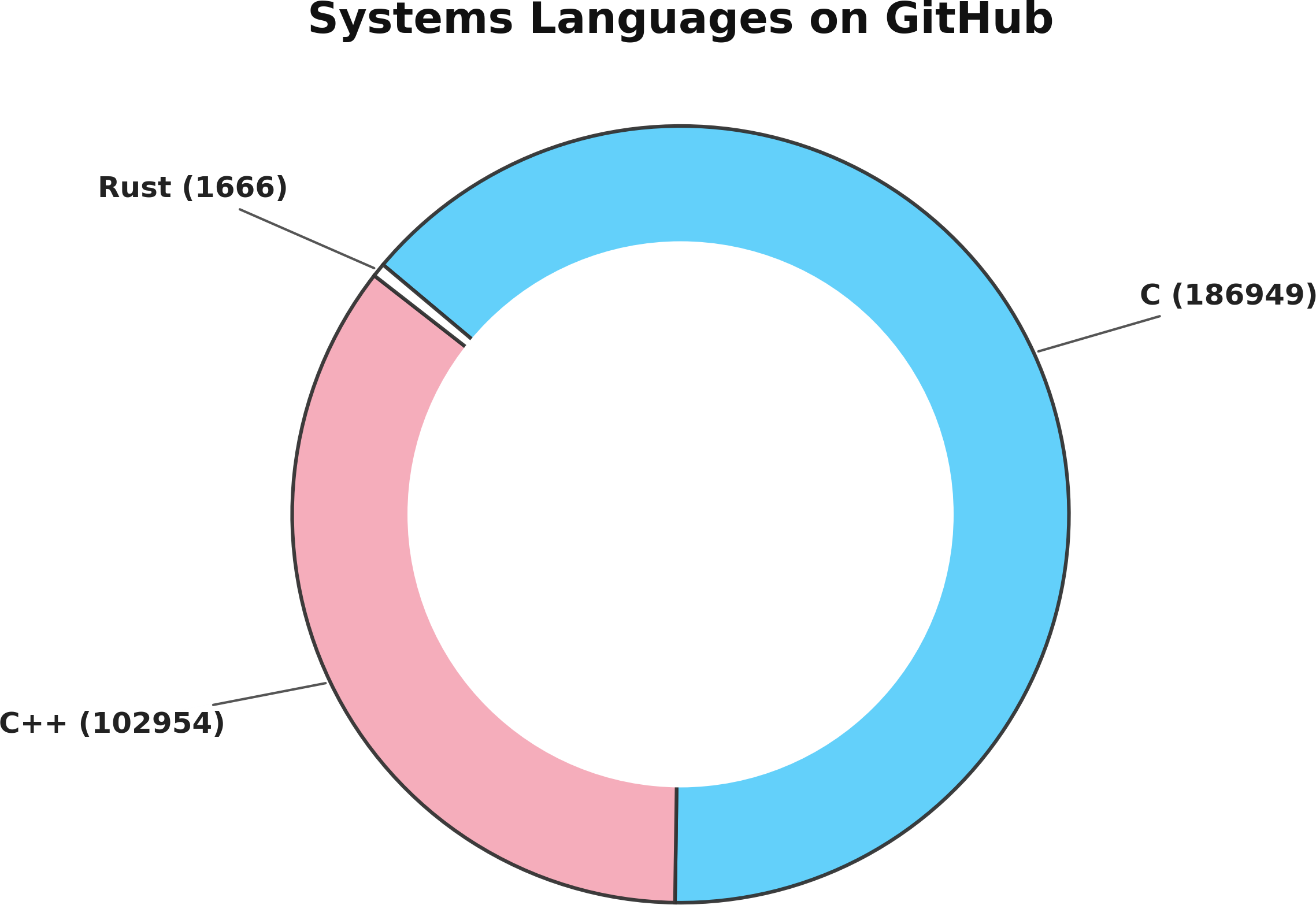
The above chart is simply an estimate taken from the number of repositories by languages using data from the GitHut public dataset, but it reflects a fact that is fairly uncontroversial: there's a metric ton of C code out in the wild. All of it wildly unsafe, and all of it rife with memory bugs just waiting to be exploited.
Rust may be paving the way for the future, but we have a whole lot of technical debt that ain't going away.
The lofty goals of C to Rust
This nicely brings us to the topic of today's blog post — spurned by this observation, there has been a growing interest within the Programming Languages research community to solve this problem: if Rust is so safe, let's write a transpiler2 to automatically take our unsafe C code and map it to safe Rust!
In fact, there's currently an entire DARPA grant about it: TRACTOR: translating all C to Rust, and this has naturally lead to an entire cottage industry of research into this translation and even companies:
- Translating C to Safer Rust by Emre et al.
- Ownership guided C to Rust translation by Zhang et al.
- In Rust We Trust – A Transpiler from Unsafe C to Safer Rust by Ling et al.
- Immunant: "migrating critical C/C++ to safer, modern alternatives such as Rust"
Initial works were purely symbolic, but more recently researchers have been having increasing success using LLMs, and these are just a few that turned up on a cursory search of google scholar, but as an active PL researcher, I've seen countless such manuscripts pass my desk, and I imagine dozens more are in the works.
So, all in all, the future looks bright, right? All code in the future will be in bug-free memory safe Rust, and all the old buggy unsafe C code will be automatically rewritten to Rust and humanity will be saved…
…or so I would say, save for one small problem — the problem of translating C to Rust as a problem is fundamentally ill-formed. It is not even wrong.
In the rest of this blog post, I'll give you a high level overview of why this is the case and what we can do.
State of the art: C2Rust
I want to start of this post by focusing on the current state of the art technique for translating C to Rust — Immunant's C2Rust tool (they have an online demo) — and the foundation for most of the research in this area.
C2Rust, at a high level, takes a C program, and rewrites it using syntactic rules into a form of Rust.
So the idea is that you'd take some C code, that might look like follows:
and if you apply C2Rust to it, you'll get the following idioma—
…err maybe not so idiomatic code, but hey, at the very least, in this case, the resulting program is pure safe Rust, and we get all of Rust's blazing fast memory-safety guarantees. No more garbage C in our code!
The only place where it falls down is when the C programs happen to make use of pointers3:
In such programs, owing to the lack of lifetime and aliasing information, C2Rust can't produce code using references, and instead must fall back to pointers and unsafe Rust:
This gives us the context of most of the research in this area — for C programs that make use of pointers, can we automatically refactor it to generate safe Rust? For example, by translating pointers to lifetimes:
This turns out to be a hard problem, and a variety of approaches have cropped up trying to get better at it.
Idiomatic C is not Idiomatic Rust
I think there's a more fundamental problem at the heart of translating C to Rust — idiomatic C code is not idiomatic Rust, and in fact, idiomatic code in each language actually looks quite different.
For example, consider iterating over a linked list in C. We might right code like follows:
Sweet and simple; I even threw in some for-loop twiddling to do the loop iteration.
If we plug this in to C2Rust, then we get the following delight:
It's not exactly too ugly (at least in this case), but it is unsafe and so we don't get all of Rust's fancy guarantees. This code is as unsafe and trashy as the C code we started with.
If a Rust developer were writing this from scratch, then the idiomatic Rust way of doing this wouldn't even bring up an explicit loop at all, and instead use the iterator interface (assuming the List interface supports it):
Now this might seem like small beans to you, so what if the generated code is a little more ugly than the platonic ideal by an expert, but I believe that's fundamentally missing the point.
Rust is effective at reducing memory bugs specifically because it allows users to write higher level abstractions (such as iter) that allow users to use the type system to preserve safety guarantees.
If we want to translate C code to Rust, then it's not enough to just perform a find-and-replace transformation of int to libc::c_int, etc., but it is imperative that we translate the underlying programming patterns (iterating over a list) to corresponding abstractions at the Rust level (using the iter interface). Sadly, this brings us on to a deeper issue at the heart of C to Rust efforts: there is no notion of correctness.
What does it even mean to translate C to Rust?
Let's say we wrote a rule to translate for loops into iterator loops. So a C program like:
would get translated into idiomatic Rust that looks like:
Looks good right? it feels correct right?
…but why is it correct? can you justify this translation? These are fundamentally two different languages, so there's no easy empirical tests we can do to check they are equivalent – both snippets will compile to different binaries.
As it turns out, this is non-trivial problem. For two reasons:
- Proving this formally requires constructing relations between different language semantics.
- Rust does not have a formal semantics (yet).
…wait. …let me repeat that. Rust does not have a formal semantics4. We literally have no means of asserting why this translation even is correct other than vibes. And while vibes may be good enough for your weekend vibe-coding shitty SaaS app, for a tool to be run in anger over a large codebase, vibes just ain't going to cut it.
Now, thankfully there are a lot of researchers hard at work on the Rustbelt project working on making such a semantics, and we may have something usable in the next decade, but even if the second issue is solved, we are left facing the first problem: establishing the correctness of this rewrite inherently relies on a rather nuanced inter-language argument.
This may seem surprising. I mean looking at those two snippets as a human it intuitively feels like they represent the same computation, right?
If we dig into this intuitive feeling a bit, we'll realise that our brains are doing a fair bit of work to actually make that equivalence hold, because the semantics of both programs is quite different.
For the C program, we allocate an int on the stack and our code iteratively increments the value at this stack address until it reaches 10 and then we break the loop.
In the Rust program, we instead create a std::Range<i32>, call the Iter::into_iter() method on it, and then repeatedly call .next on that until it returns None.
In this case both programs perform the same computation, but the C program inherently has quite different guarantees - for one, it ensures that the index of iteration is just another variable on the stack, with its own address, and can be manipulated as any other variable.
This discrepancy becomes relevant if for example the body of the loop actually uses this fact:
In the case of the Rust code, its interface fundamentally does not allow this pattern – the variable i in rust is temporary, and its value is updated by drawing from an Iter object, not by changing a value on the stack.
For the example I showed above, it just happened that this translation was valid because the assumptions that the loop body was making did not rely on any of the specific additional guarantees that C provided.
This brings us to the crux of the problem:
C programs encode an abstract computation in the programmer’s mind that is a subset of what is specified in the code. Preserving all of C’s semantics will inherently produce unsafe Rust, because arbitrary C code is fundamentally unsafe.
This is fundamentally an underspecified problem, and it's made much worse by the fact that again, we don't even have the formal foundations to justify why what we're doing is correct. It is not even wrong.
Looking forward
Okay, so, hopefully that gives you a high level overview of the state of C to Rust and hopefully I've given you a rough idea as to why, as it stands, currently this direction has some fundamental open problems.
I want to leave off on a slightly more positive note. I do believe that the work that is being done into translating C to Rust is important, and there are some useful outcomes of even the work that has been done so far. There's a lot of interesting problems and subproblems that pop up in this context, and while the larger problem maybe underspecified, there are several works that carve off smaller more manageable areas for which they can reason a bit more rigorously.
Humanity is stained with the sins of C, and there isn't an LLM on earth that can magically save us from the consequences of our own bad actions.



