.png)

In the early days of LLM applications, RAG (Retrieval Augmented Generation) was a lifeline. It helped simulate memory before large context windows were feasible. In the early days of LLM-native RAG, I built Vault, a popular open-source RAG system, and consulted for hyper-growth AI companies like ManyChat and MyStylus to help optimize their retrieval systems.
I’m now actively advocating against RAG for autonomous coding agents.
Why? Because quality matters.
If you're optimizing for cost, RAG can be useful. If you're building a $20/month tool and trying to minimize token usage, and profit off of inference, by all means chunk your repo, embed it, do some cosine similarity, maybe throw in a reranker step and fetch the top matches. Cursor, Windsurf, and others have taken this route and built real businesses.
But if you're optimizing for quality, if you're trying to build something that codes like a senior engineer, RAG is a blackhole that will drain your resources, time, and degrade reasoning.
“The hardest questions and queries in a codebase require several hops. Vanilla retrieval only works for one hop.”
Aman Sanger, co-founder of Cursor
In my consulting practice, I’ve helped hyper growth AI companies improve their RAG pipelines in a metrics-oriented way, leading to hundreds of thousands of dollars in increased monthly revenue. I’ve written a number of articles sharing the process.
But I’ll be the first to tell you, RAG is a black hole. You can sink endless resources, time, and talent into it for marginal improvements. And this makes sense if your product actually needs RAG.
But for autonomous coding agents, RAG is a MASSIVE DISTRACTION, both for your team AND for the agent itself.
“Most of the industry never actually did it that well… 99% of RAG implementations never did any chunking or never measured in a rigorous way… and now it’s already past the point where RAG is sufficient.”
Quinn Slack, CEO of Sourcegraph (Cody)
The RAG narrative is oddly insidious, a mind virus if you will. It’s almost like people got RAG in their heads in 2022 and now shoehorn RAG into everything with the expectation that it will make things better. On the contrary, it’s a massive risk that will DIVERT your models, diluting their judgement with a swamp of chunked snippets.
I was in a call with a prospective enterprise client. They were going through a procurement process, evaluating different coding agents to see which made the most sense for their engineering teams. This was a serious company, with thousands of engineers, yet their decision making process was remarkably naive. It’s almost like they wanted a checklist of capabilities, and RAG was a big sticking point for them. When I asked them why they wanted RAG so bad, they just said “I don’t know, isn’t it good for big codebases?”
When a senior engineer joins a team and opens a large monorepo, they don’t read isolated code snippets. They scan folder structure, explore files, look at imports, read more files.
That’s the mental model your coding agents need to replicate, not a schizophrenic mind-map of hyperdimensionally clustered snippets of code.
Cline is one of the most expensive coding agents on the market. But it reads code like a human: walking folder trees, analyzing imports, parsing ASTs, reasoning about where to go next. Cline is context-heavy, it’s agentic, it’s expensive. It’s the cost of intelligence. Retrieval is passive; agency is active.
“It’s difficult to build a system that automatically determines what context is relevant instantly… and [RAG] likely requires a lot of integrations that you must maintain forever.”
Ty Dunn, founder of Continue
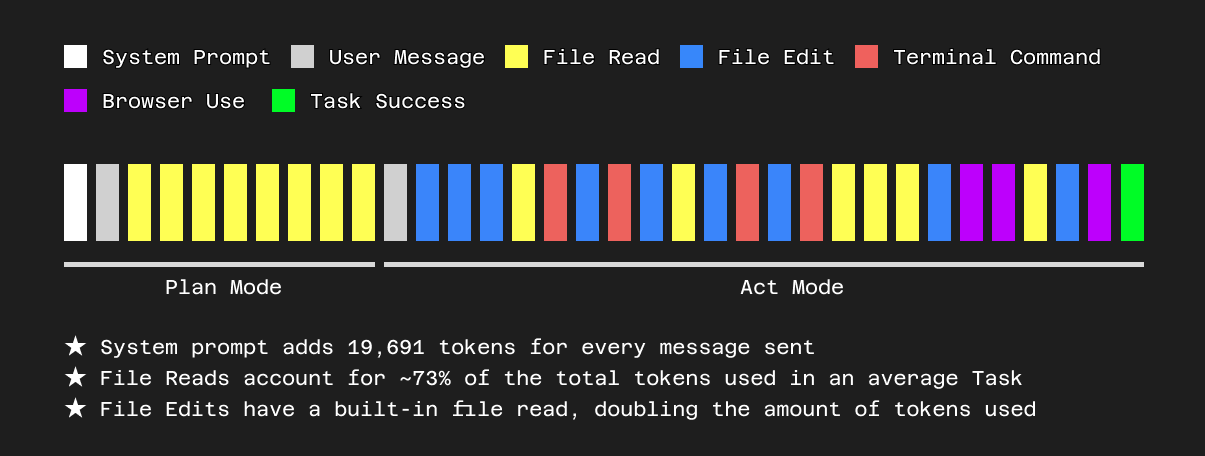
With Claude Sonnet 3.5, 3.7, and now 4.0, context size and reasoning isn’t the bottleneck anymore. Context quality is.
So at Cline, we gave our agent all the tools a real engineer would have, and let it explore.
“Forget RAG. [New architectures like MCP] enable more autonomous, context-aware, and efficient workflows.”
Shridhar Belagatti, writing on Cline’s agentic memory systems
There are still places RAG shines—support bots, document Q&A, general memory. But if you’re serious about building a high-performance autonomous coding agent, I recommend you zoom out, and approach the problem in a totally different way.
Instead of building systems that you will have to maintain forever, and will cloud your agent’s judgement, start by eliminating as much as possible. Remove all scaffolds. Get out of the flagship model’s way.
Build memory. Build tools. Give your agents the affordances real engineers use. And let them work like humans do.
We’re finally at a point where they can so let them.


