.png)

see the final frame here.
When we started noticing patterns in our agent logs back in May 2025, something caught our attention. Users were asking agents for comprehensive, multi-step tasks, expecting depth, but they were getting surface-level answers or context window errors instead. More interesting: the agents were trying to help, spontaneously inventing filesystem-like syntax to navigate data they couldn't actually access properly.
That observation kicked off the Deep Dive project. Not because deep research is trendy (though OpenAI, Anthropic, and Google all launched their versions this year), but because we saw a fundamental gap between what agents needed to do real work and what infrastructure existed to support them.
The problem: depth requires different infrastructure
Quick answers are easy. An agent can search your docs, find relevant chunks, and synthesize a response in seconds. But comprehensive work requires something fundamentally different.
Think about how you tackle a complex investigation spanning multiple systems. You don't just search once and synthesize. You explore different angles. You follow leads from internal docs to your data warehouse to external sources. You identify gaps, dig deeper, change direction based on what you find. You work for hours, not seconds.
Traditional agents fail at this because they're built on infrastructure designed for speed, not depth. Semantic search works brilliantly for finding known information, but it breaks down when you need to explore structure, navigate relationships, or conduct multi-step investigations across different systems.
We realized that to build an agent that could truly go deep across all your data (proprietary company sources, data warehouses, the web, custom integrations), we needed to solve seven infrastructure problems that nobody else was addressing together.
1. Data Source File System: teaching agents to navigate
In April 2025, we noticed agents in our logs were spontaneously creating syntax like file:front/src/some-file-name.tsx and path:/notion/engineering/weekly-updates. They were trying to reference resources by inventing file paths, even though no filesystem existed.
This was a hint. Agents weren't just searching for meaning. They were trying to navigate structure. When you need "the TeamOS section of last week's team meeting notes," you're not searching semantically. You know there's a meetings database, you know there are weekly entries, you know where to look.
We built synthetic filesystems that map disparate data sources (Slack channels, Notion databases, GitHub repos, Google Sheets) into navigable Unix-like structures. Five simple commands: list, find, cat, search, locate_in_tree. Just like Unix, but operating across your entire company knowledge base.
The breakthrough wasn't the filesystem itself. It was recognizing that agents need both navigation and search. Navigation builds contextual understanding. Search finds specific information within that context. Together, they mirror how humans actually work with information.
Read more about it here.
2. Warehouses: structured data at scale
Most custom agents operate on narrow scopes: a handful of documents, maybe a specific Notion database. We needed the opposite. Deep Dive required access to everything, including the structured data living in your data warehouses.
Not just reading from databases. True exploration. An agent investigating business performance shouldn't be limited to documents about revenue. It should query Snowflake directly, join tables, analyze trends, then correlate findings with strategy docs and competitive intelligence from the web.
We built warehouse tools that let agents discover available tables (800+ tables, thousands of columns in some customer environments), understand their schemas, and write SQL queries on the fly. Combined with the filesystem tools, agents can now operate at unprecedented scope while maintaining the ability to go arbitrarily deep in any direction.
This combination is the key differentiator from traditional deep research tools. Most of them search the web. We connect to your entire data infrastructure. Large scope plus ability to go deep.
Every workspace has different needs. Some teams need Salesforce access. Others need GitHub. Others need custom internal APIs through MCP (Model Context Protocol).
Traditional agents require manual configuration: you build an agent, you wire up its specific tools, you deploy it. But Deep Dive needed to be genuinely generic. It shouldn't care what tools exist in your workspace. It should discover them, understand them, and use them as needed.
Toolsets solve this. When Deep Dive starts working, it queries available toolsets in the workspace, discovers what tools are available, and incorporates them dynamically. No manual setup. No per-workspace customization.
This makes Deep Dive fundamentally adaptable. As you add new data sources, new MCP servers, new integrations, Deep Dive automatically gains those capabilities. It's the closest we've come to a truly general-purpose work agent.
4. Sub-agent coordination: expanding context and compute
Here's where the architecture gets interesting. Complex work isn't a single linear process. It's parallel exploration across multiple angles, each requiring focused attention and its own context.
The fundamental challenge: context windows are finite. Even with 200K token limits, a comprehensive investigation can't fit everything in one conversation. Sub-agents solve this by giving each sub-problem its own dedicated context window.
Explore our Frame to see how it works.
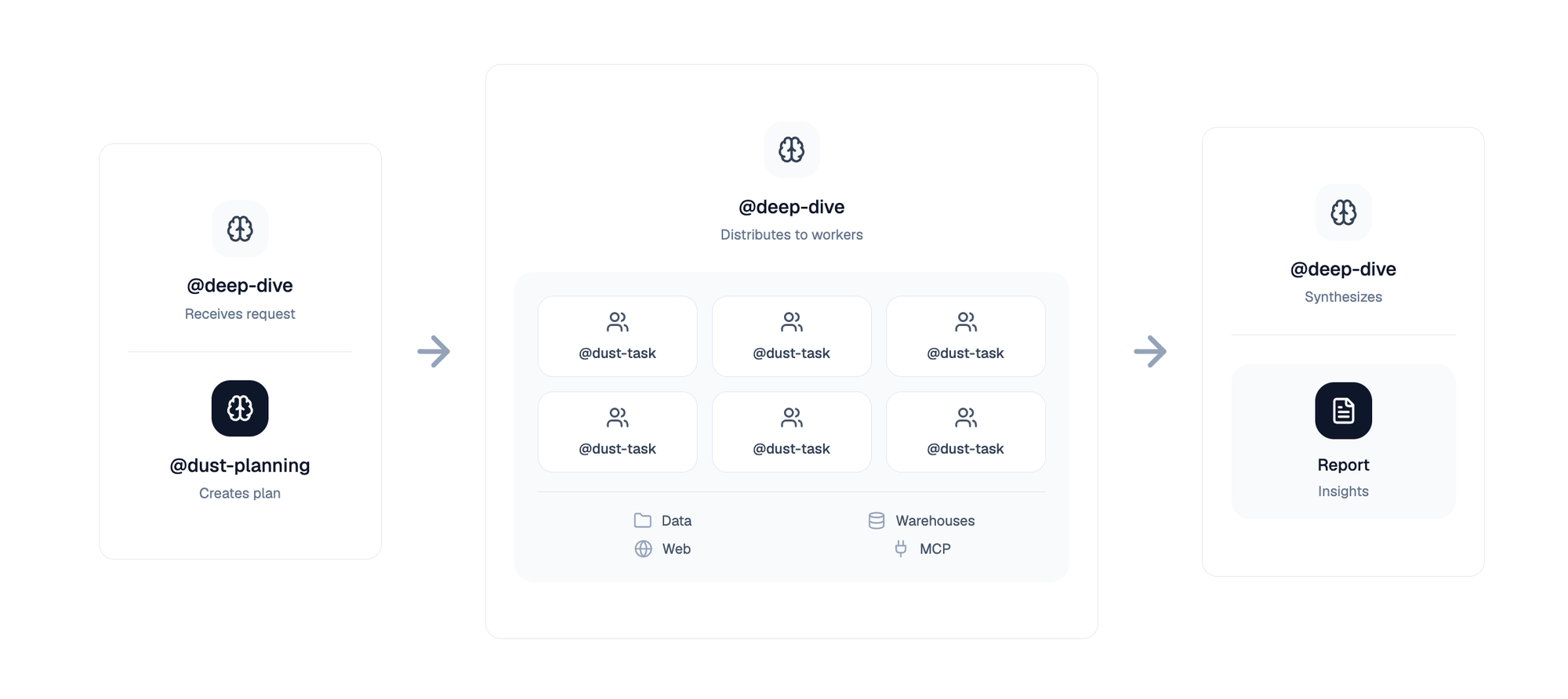
We built Deep Dive as a three-agent system:
@deep-dive acts as the coordinator. It classifies request complexity, decomposes tasks into atomic subtasks, and orchestrates up to 6 concurrent sub-agents using parallel tool calling. Think of it as a project lead delegating focused work streams to specialists.
@dust-planning is the strategic reviewer. When tasks are complex enough, the main agent consults the planning agent to validate its approach. The planning agent has no data access (deliberately), forcing it to provide high-level strategic guidance rather than prescriptive details based on potentially outdated knowledge. It runs with maximum reasoning effort, dedicating substantial compute to thinking through the strategic decomposition before responding.
@dust-task agents are the specialized workers. Each receives a focused prompt, executes independently with full access to data tools, and produces information-dense reports optimized for agent consumption rather than human formatting. Crucially, each sub-agent gets its own fresh context window, meaning it can browse dozens of pages, query multiple databases, and explore company data without competing for space with other parallel investigations.
This architecture fundamentally expands what's possible. Instead of one agent with one context window trying to do everything, you get multiple agents working in parallel, each with dedicated context for their specific sub-problem. This enables investigations requiring 10-30+ minutes of execution while maintaining quality at each step. The system is built on Temporal workflows for durability, meaning work can survive deployments and infrastructure issues without losing progress.
The result: longer time horizons, massively more compute deployed on the problem, and the ability to tackle truly comprehensive tasks that would be impossible within a single context window.
5. Native reasoning: keeping the thread
The rise of reasoning models (OpenAI's o1/o3 and now GPT-5, Anthropic's extended thinking, DeepSeek R1) opened up new possibilities for Deep Dive. These models don't just answer questions. They think through problems systematically, exploring approaches, evaluating trade-offs, and building coherent plans before acting.
For Deep Dive, this matters enormously. When coordinating 10-30+ minutes of research across multiple sub-agents, maintaining coherence becomes challenging. The agent needs to remember what it has already investigated, why it chose certain directions, what hypotheses it is testing, and how new findings connect to earlier discoveries.
Reasoning models excel at this. Their extended thinking maintains strategic coherence across dozens of tool calls. They're better at decomposing complex tasks into logical subtasks. They recognize when they need to adjust their research plan based on what they've learned. In practice, we see dramatically better planning and more coherent final synthesis when using reasoning models for complex investigations.
The integration challenge: Supporting native reasoning required significant changes to our infrastructure. We previously used "ad-hoc" reasoning with delimiter-based approaches (XML tags marking thinking blocks). Native reasoning uses the models' built-in capabilities, where reasoning is managed through structured responses.
The key challenge was re-thinking our internal data model to support these new APIs and enable passing intermediate reasoning steps back to the model at each step. Without this, models "reason again from scratch" at every tool call, losing the thread of their previous thinking.
The result is that Deep Dive (and of course, all Dust agents) can now run with reasoning models from multiple providers. The models maintain strategic coherence across long sessions. Users can select effort levels (short, medium, long) to control how much reasoning budget to allocate. For complex investigations requiring careful planning and synthesis, native reasoning makes the difference between scattered findings and coherent research. And because we built the infrastructure to support native reasoning as a first-class capability, new reasoning models work out of the box.
6. Context engineering: finite windows, infinite work
Long-running investigations face a fundamental constraint: context windows are finite, and comprehensive work hits walls quickly. A few large web pages, some database query results, several documents - suddenly you're out of space, and the agent starts forgetting what it learned earlier.
We built two complementary systems to solve this.
Tool output pruning: preserving the thread
The core problem: when agents perform complex multi-step work with parallel tool calls and large outputs, they overflow their context window. Our previous approach was crude - drop entire message pairs when space ran out. The agent would lose all memory of previous work, causing what we called "The Amnesia."
Explore our Frame to see how it works
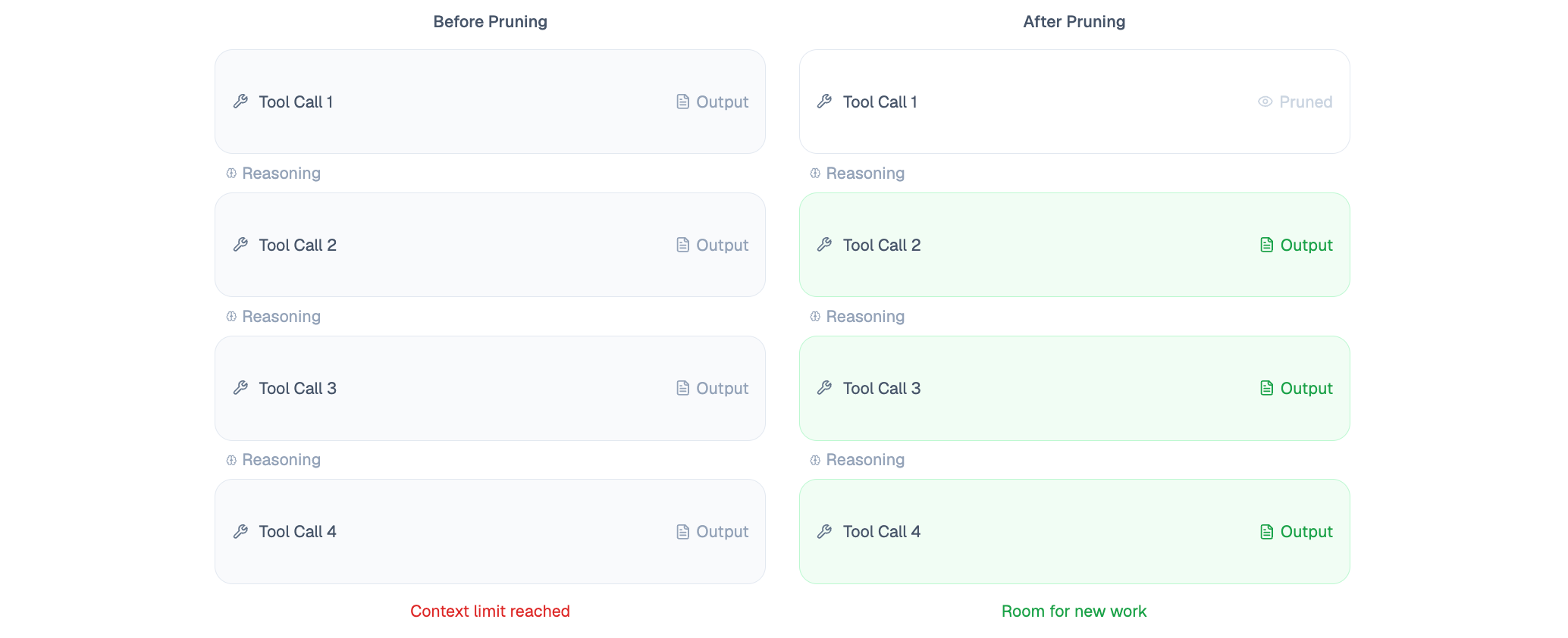
Tool output pruning takes a smarter approach. Instead of dropping entire interactions, we selectively prune tool outputs by replacing their content with <dust_system>This tool output is no longer available</dust_system>. The tool call itself remains visible, so the model still sees what it did, just not the full results.
We use two pruning strategies:
Current interaction pruning handles the "Big Loop" problem - when the current task generates so many tool calls that even the active interaction won't fit. We progressively prune the earliest tool outputs until everything fits.
Historical interaction pruning solves "The Amnesia" - removing tool outputs from past interactions when running out of context. The agent can still see what it previously produced (like a long report it just wrote), but intermediate tool results from earlier interactions are pruned to make room.
This maintains reasoning continuity, and also allows the user to follow up without the agent forgetting about the document it just wrote.
Offloaded tool use: taming noisy outputs
Tool outputs can be massive and noisy. Web pages arrive with navigation menus, ads, and formatting artifacts. Warehouse queries return thousands of rows. A single tool call can consume 200k+ tokens, leaving no room for anything else.
Explore our Frame to see how it works

Offloaded tool use solves this by treating large tool outputs as files rather than inline content. When some tools produce substantial output, we:
- Store the full result as a file attachment
- Generate a compact representation (a few lines for CSVs, an AI-generated summary for web pages)
- Present only the compact version in the agent's context
The agent sees the snippet by default, but gains full filesystem access to the underlying data. It can read the entire file, search through it using semantic search, apply regex patterns to filter content, or paginate through specific sections using offset and limit parameters.
This transforms how agents work with data. Instead of drowning in a 30,000-token web page, the agent sees a reasonable summary and can strategically decide what to examine in detail. Instead of processing 5,000 rows of query results inline, it sees the first 10 rows and schema, then searches or filters as needed.
The result: agents can invoke dozens of data-heavy tools without overwhelming their context. Web browsing becomes practical at scale. Warehouse queries can return full result sets that agents explore interactively rather than trying to fit everything in context upfront.
The result: 10-30+ minute investigations
Together, these techniques fundamentally change what's possible. Deep Dive can now run investigations requiring hundreds of tool calls, browsing many web pages, querying multiple databases, and exploring extensive company data - all while maintaining coherence across the entire session.
The system is built to be pragmatic. We chose tool output pruning over compression schemes because it's simple, effective, fast, and handles the vast majority of cases. When combined with offloaded browsing and sub-agent coordination (where each sub-agent gets its own fresh context), we've created an infrastructure that genuinely supports depth.
This is what enables 10-30+ minute work sessions. Not just longer timeouts, but proper context engineering that lets agents go deep without losing the thread.
7. Handoff: composable depth
Once we built Deep Dive, we faced an interesting challenge. We had this powerful agent that could coordinate sub-agents, query warehouses, and navigate complex data structures. But how could we make it available as a capability for other agents?
More specifically: how could @dust (our general-purpose assistant) leverage Deep Dive's research capabilities when needed? How could customers build custom agents that, when faced with complex questions, could delegate to Deep Dive while maintaining their own domain-specific context?
The answer was handoff.
Handoff is conceptually different from the sub-agent coordination we use internally in Deep Dive. When Deep Dive spawns @dust-task sub-agents, they run in background conversations and return results. Handoff is about transferring control: one agent recognizes it needs longer-horizon work and hands the entire conversation over to Deep Dive.
How it works: The calling agent invokes a "Go Deep" tool. Instead of spawning a background conversation, this creates a new agent message in the same conversation. Deep Dive takes over and responds directly to the user.
We also maintain instruction awareness. When an agent hands off to Deep Dive, we automatically pass the calling agent's instructions along. Deep Dive receives the calling agent's full prompt, so it understands the specialized context of the agent that called it.
This means Deep Dive understands what the calling agent was trying to do. A customer support agent might have instructions about how to handle support queries, escalation protocols, and company-specific policies. When it hands off to Deep Dive for complex research, Deep Dive receives all that context and can provide research that respects those constraints.
The result: Every agent can now leverage Deep Dive's infrastructure. @dust has the Go Deep tool enabled by default. Custom agents built by customers can add it through the agent builder. Domain-specific agents maintain their specialization while gaining access to comprehensive research capabilities when needed.



