.png)

Engineering LLMs into Reliable Field Extraction Systems
A common industry question is whether flagship models like ChatGPT, Claude, or Gemini can process insurance documents out of the box. In practice, LLMs are building blocks that require significant engineering to become production-grade field extraction systems.
For this discussion, we’ll focus on one specific problem: quickly and accurately extracting critical fields from any quantity, shape, or form of insurance submissions.
Breaking Down the Field Extraction Process
Schema extractions fall into two main categories:
- Single Entity - extracted once per submission, capturing overall risk details. Examples: general liability, product liability, cyber insurance.
- List-Entity Extractions - extracted repeatedly for each item in scope. Examples: property schedules, vehicle lists.
Naturally, single-entity extractions are simpler: given a fixed schema, we review each document and fill in the most accurate value for each field. When multiple values appear for a single filed, the AI’s job is to select the correct one.
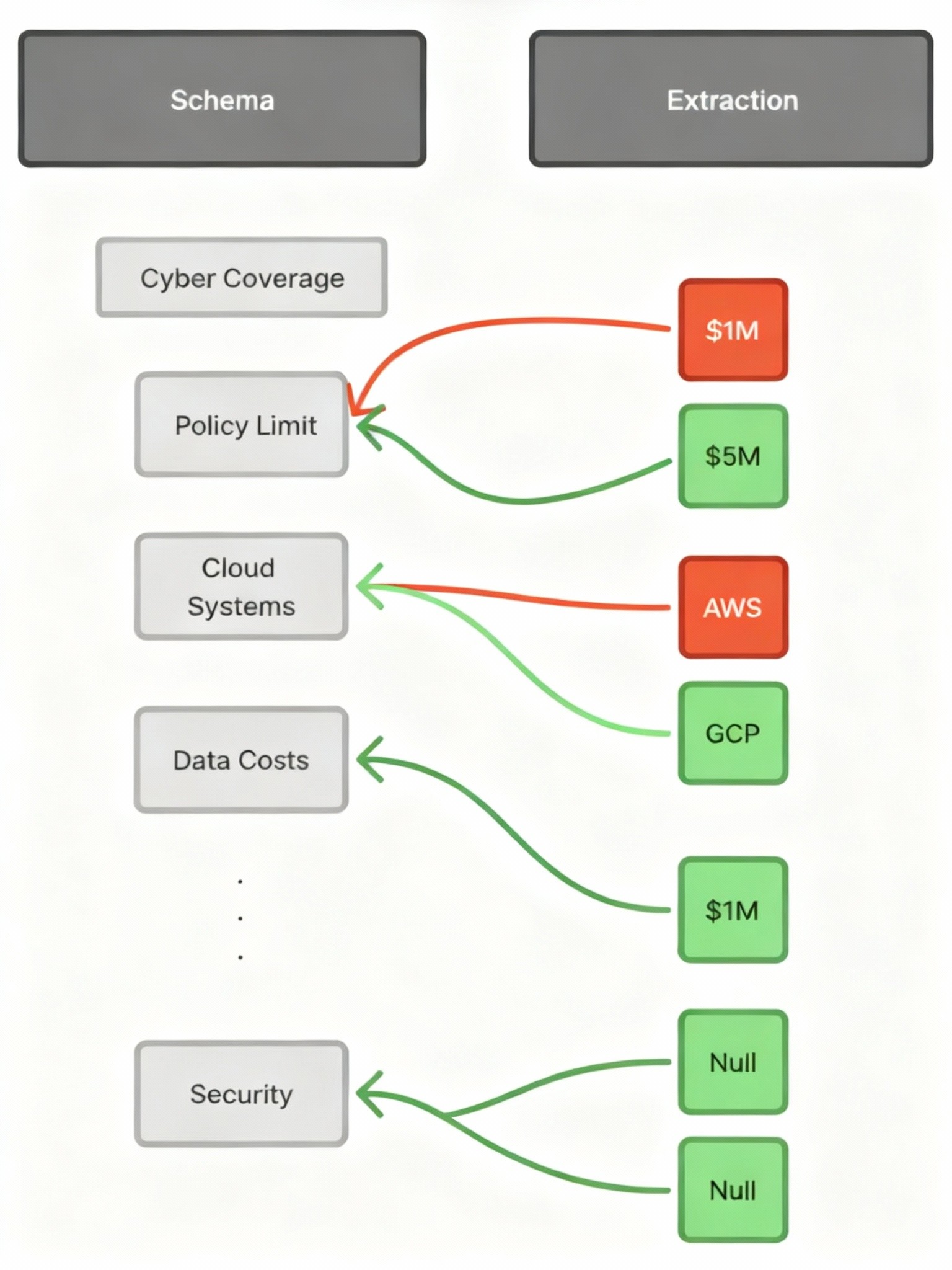
List extractions, on the other hand, aren’t trivial. In the real world, an underwriter gets a mess: emails, statements of values, and random docs. We throw that same chaos at the AI and expect it to reach the same conclusions a good underwriter would, but 10x faster, and with more precision and consistency than a human could manage.
The challenge then is deciding which items are genuinely different and which are duplicate references to the same thing. For example, “123 Main Street” in one file and “123 Main St., Suite 2” in another may refer to the same property. What starts as “merge the duplicates” quickly becomes determining which entries represent the same entity, which are distinct, and then reconciling any conflicting details.
Consider an example where three separate extractions ultimately collapse into one. Each began as its record, with overlapping but inconsistent details. Some fields have different values for the same attribute, others are missing data, and some contain conflicting entries. The diagram below shows how these fields align, diverge, and are ultimately reconciled into a single unified record:
.png)
Why Properties are Harder than Vehicles or People
Property extractions add another layer of complexity. The goal is a list of distinct properties, but there’s no universal identifier. The AI must determine they’re the same property, reconcile conflicting data, and preserve the most accurate details. Addresses come closest to this universal identifier, though a single address might have up to ten properties—one file lists them without titles, another calls one “Building B” in one file and “Building A” in another—each with different and potentially conflicting values.
Let’s explore a solution for this particular property list extraction problem.
The Puzzle of Property Matching
To begin, what makes single-entity extractions easier than list-entity extractions?
Universal identifiers.
What is the significance of this? The point of a universal identifier is to guarantee that two entities don’t overlap. Two cars with different license plates are, by definition, different cars. The same idea applies to property merging.
While properties lack a true universal identifier since multiple properties may belong to the same address, we can treat the address as a proxy. If two properties have different addresses, we can be confident they’re distinct.
%20(2).png)
We can make the following observation:
If each address contains only distinct properties within it, then combining the property sets across addresses will still yield a set of distinct properties.
Because addresses are independent under this assumption, we can process each address in parallel, knowing they’re disjoint. Parallelization improves speed, but it only solves part of the problem. The real complexity lies within each address.
The Real challenge: Duplicates at the Same Address
The harder problem is ensuring that within each address, the properties are truly distinct. Given a set tied to the same address, how do we decide which are the same and which are different?
One approach is to compare key fields. For example, if one property has a Business Personal Property (BPP) value of $50K and another shows $100K, that’s strong evidence they’re different even if the address matches. But this raises questions:
- Thresholds: How far apart must values be before we treat them as different?
- Field weighting: Should some fields, like Total Insured Value (TIV), carry more weight than others?
- Mixed signals: What if one field diverges sharply while another matches exactly?
Human error complicates things further. A TIV of $10M vs. $100M might look like a major discrepancy, but could simply be a data entry mistake. And sometimes, two records with near-identical values still describe different properties, such as identical warehouses at the same industrial park.
The core challenge is that without a universal identifier, “same or different” demands more than field comparison. It needs a framework that interprets discrepancies, weighs field importance, and accounts for human error.
Closing Thoughts
From building AI systems for submission data extraction at major P&C carriers and MGAs, one clear lesson emerges: the first 80–90% of an extraction system develops relatively quickly. However, the final 10–20%—resolving edge cases, reconciling conflicting information, and handling human error—proves exponentially more challenging.
Acknowledgments
Article written by Jeffrey Xie


