.png)


There are many things one needs to live a rich and fulfilled life (according to AI researchers). A good initialization [Mishkin and Matas, 2015], attention-based neural networks [Vaswani et al., 2017], and a good title for your research paper [Myself, just now], to name a few.
In this post, we discuss another piece of eternal wisdom from AI researchers: “less is more.” Specifically, how foundation models can be fine-tuned for new capabilities with small data, in many cases less than one-thousand samples, and often outperform the same model fine-tuned on larger datasets. Meditate on that for a moment (suggested pose in figure above).
And if you read until the end, I promise this will be my final post with “all you need” in the title! Let’s get cracking.
The current Generative AI boom was precipitated by the discovery of so-called neural scaling laws. In a seminal 2020 paper from OpenAI [Kaplan et al. 2020], researchers provide strong evidence that the performance of transformer-based language models increases as the training data size, the model capacity, and the compute used for training increase, with a predictive power-law relationship, and that this trend holds for at least seven orders-of-magnitude.
It would, however, be wrong to draw the inference from this work that more training data is always better. Importantly, the set up for fine-tuning models differs from training language models from scratch in that fine-tuned models are not trained from scratch. The foundation models we fine-tune, whether 7B, 70B, or 700B parameters, have been trained on trillions of tokens of language from the web.
This begs the question: how does the performance of a fine-tuned foundation model scale with respect to the size of the training data? In this post, we’ll examine some early—at least, by the standard of Generative AI—and influential work on this question in a paper called “LIMA: Less is More for Alignment” [Zhou et al., 2023]. We’ll go into more detail in the subsequent sections, but here’s a summary of the experiment:
The researchers take a medium-sized language model, which has been trained only for next-token prediction and not chat or multistep dialogue, and fine-tune all weights on a small dataset of 1,000 carefully curated samples. They then compare the responses from the fine-tuned model against baselines like GPT-4 using a set of test queries and both human and LLM judges to determine which model’s response is preferred.
One surprising finding is that responses from the model fine-tuned on small data are equivalent or preferred to those from GPT-4 43% of the time. Another surprising finding is that the model trained on 1k samples outperforms the same base model fine-tuned on 52k samples, showing that quality is more than quantity.
The carefully curated training set of 1,000 samples comprises data from:
Community forums (750)
Stack Exchange, STEM (200)
Stack Exchange, non-STEM (200)
WikiHow (200)
Pushshift Reddit dataset [Baumgartner et al., 2020] (150)
Hand-written by authors (250)
with the objectives of diversity, quality, approximating real user prompts, and having helpful completions with AI-assistant-like style.
The test set comprised 300 challenging and diverse prompts:
Pushshift Reddit dataset (70)
Hand-written by the authors (230)
The base model used for fine-tuning is Llama 65B, that is, the first version of this open-source model family from early 2023. At the time, it represented a state-of-the-art open source LLM but now could be considered a weak model of medium size.
The baseline models are Alpaca 65B (a fine-tuned Llama 65B from prior work, trained on 52k samples including for multiturn dialog), Google’s Bard, Anthropic’s Claude, and OpenAI’s DaVinci003 and GPT-4, all of which were close to or at the state-of-the-art in early 2023.
The fine-tuned the model for 15 epochs with supervised learning on all model weights and chose the final model via retroactive early-stopping, finding a checkpoint between the 5th-10th epochs with the highest score on a held-out evaluation set.
Importantly, the authors did not use any parameter-efficient fine-tuning methods like LoRA. Also, they did not use reinforcement learning (RLHF) or direct optimization (DPO) whether on preference- or reward-based data, unlike the baseline models.
The main experiment compared single prompt completions on the test set between their fine-tuned model and the baselines. Human judges were presented with a single prompt and a pair of responses produced from the fine-tuned model and a single baseline model, recording which response they preferred, if either. The same experiment was repeated using GPT-4 as a judge model with the same instructions given to the human annotators.
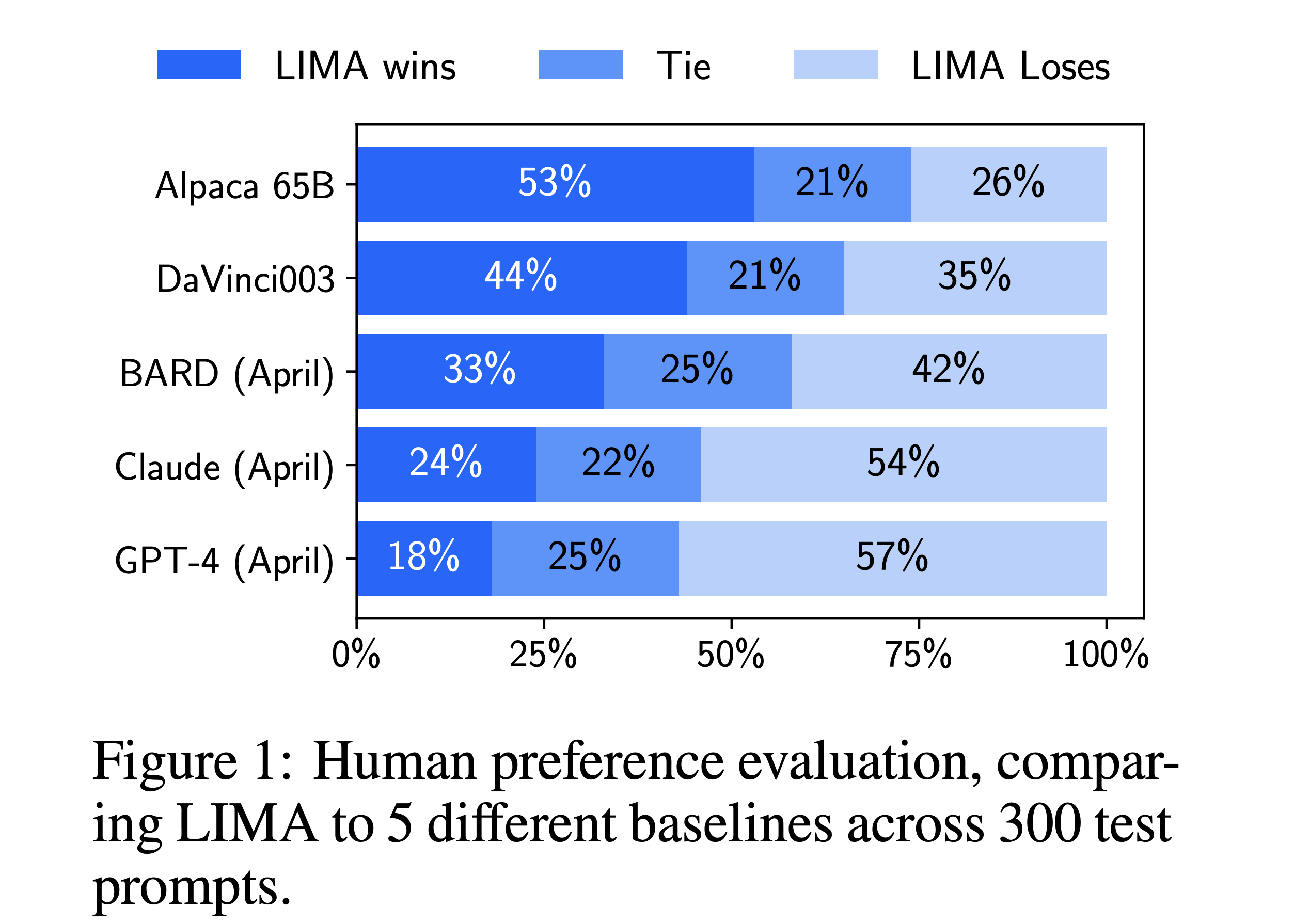
Figure 1 from the paper contains the results for the experiment measuring human preferences on the authors’ fine-tuned model, LIMA, versus the baselines. We can see that for all baselines, save Claude and GPT-4, a majority of the responses from LIMA are either equivalent or strictly preferred. Surprisingly, a nontrivial number of responses from LIMA are equivalent or preferred to those from Claude and GPT-4. And this is from a model fine-tuned on a mere 1000 samples!
The results are largely the same when using GPT-4 as the judge (Figure 2, not shown).
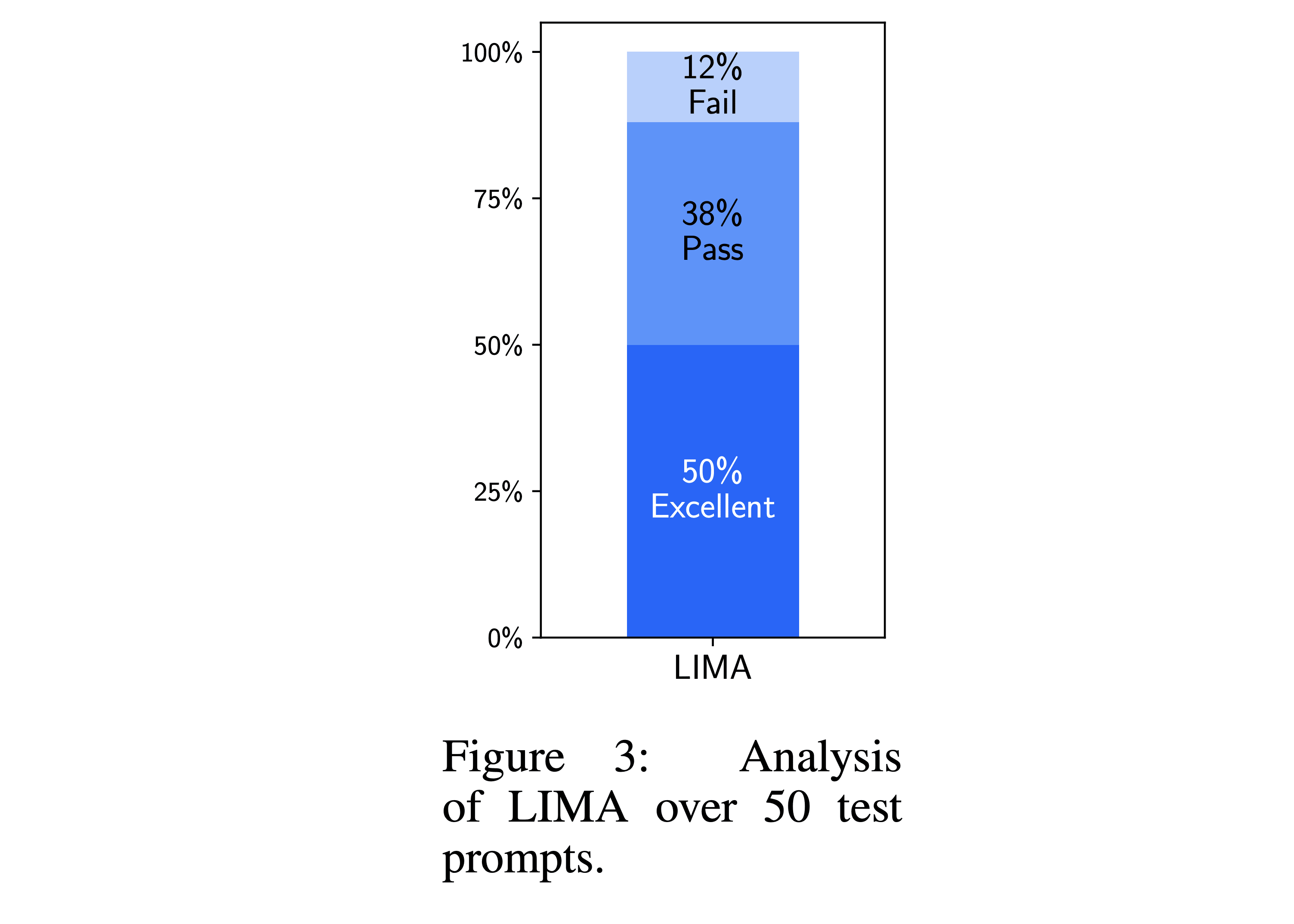
Figure 3 shows the results from, in a sense, measuring LIMA against itself. Human annotators were asked whether the responses from LIMA over 50 test prompts were “excellent”, “passable”, or “fails”. Only 12% of the responses were rejected by the human annotators.
Ablation studies, which we mention in passing, show that diversity is much more important than quantity for fine-tuning, with drastically diminished marginal return in scaling up the training size.
What is the significance of these results and can we draw from them sweeping life-altering conclusions?
It is unwise to extrapolate the findings from this paper alone. The training dataset wasn’t constructed for a narrow capability, as in the “LoRA Land” work discussed in last week’s post, but rather for more general-purpose alignment on a variety of tasks. Second, the experiments were performed on a 65B parameter base model, which does not fit our definition from last week’s post of a small model.
Nonetheless, more recent works, including “LIMO: Less is More for Reasoning” [Ye et al., 2025] make similar findings in a broader range of contexts, suggesting that this is a general principle that carries across tasks and scales. (And don’t forget that pretraining has become much grander in scale, diversity, and training methodology since early 2023.) The authors call this general principle the Superficial Alignment Hypothesis, by which a model’s knowledge and capabilities are essentially all learnt during the pre-training phase, and fine-tuning only works to select a subdistribution from these.
Some observations I’d like to make before we wrap up: I strongly recommend matching the fine-tuning model capacity to the dataset size, and if the dataset contains a measly 1000 samples, you should use some flavor of parameter efficient fine-tuning like LoRA. Also, there are orthogonal advances in foundation models that compound the benefits of fine-tuning small models, for instance, scaling test-time compute.
While LIMA addressed the question of fine-tuning on small data and the role of diversity vs quantity, it did not address an important problem: we need to have the data to do fine-tuning in the first place! If our samples can’t be procured from existing open-source sources, as is the case for most AI problems in industry, how can we generate, curate, and evaluate a custom fine-tuning dataset without masses of human labor?
This was actually one of the primary motivations for us to develop the Oumi Platform. With our automation surrounding data synthesis, fine-tuning, evaluation, and iteration, we can develop custom AI for you in hours, not months. If this sounds of interest, register for our Early Access Program using this link: https://oumi.ai/contact
As Always, Stay Hungry and Happy Hacking! 🧑💻🤖🚀
Stefan Webb, Lead Developer Relations Engineer, Oumi
Kaplan et al. Scaling Laws for Neural Language Models. 2020
Mishkin and Matas. All You Need is a Good Init. 2015.
Vaswani et al. Attention is All You Need. 2017
Zhou et al. LIMA: Less Is More for Alignment. 2023
Baumgartner et al. The Pushshift Reddit Dataset. 2020
Ye et al. LIMO: Less is More for Reasoning. 2025